1.简要描述一下python爬虫的工作原理,并介绍几个常用的python爬虫库。
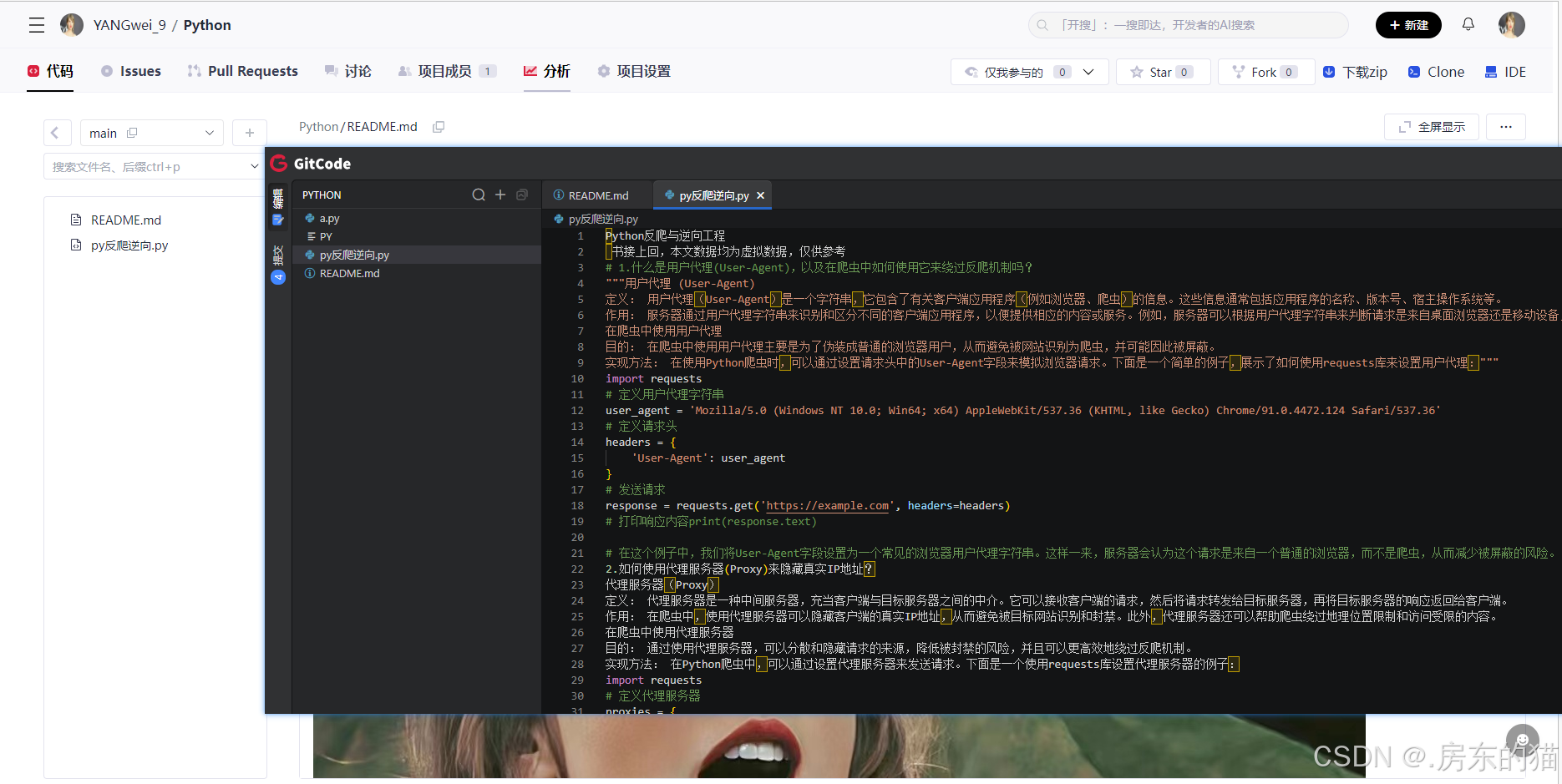
python爬虫的工作原理
常用的python爬虫库
2.scrapy 框架的基本结构和工作流程是怎样的?
scrapy 框架的基本结构
- 项目结构:scrapy项目包含多个文件和目录,如
spiders(存放爬虫代码)、items(定义数据结构)、pipelines(处理提取的数据)、settings(项目配置)等。 - spiders:定义爬虫的核心部分,负责发送请求和解析响应。
- items:定义数据结构,用于存储爬取的数据。
- pipelines:处理提取的数据,可以进行清洗、验证和存储等操作。
- middlewares:中间件,用于处理请求和响应的过程,类似于过滤器。
scrapy 工作流程
- 启动爬虫:scrapy启动后,加载配置和爬虫类。
- 发送请求:爬虫类发送初始请求(通常是start_urls列表中的url)。
- 解析响应:收到响应后,调用爬虫类中的解析方法(如
parse),提取数据和生成新的请求。 - 生成新的请求:解析方法可以生成新的请求,这些请求会被放入调度器中,等待执行。
- 处理数据:提取到的数据会被传递到pipelines进行进一步处理,如清洗和存储。
scrapy 示例
下面是一个简单的scrapy爬虫示例,它爬取一个示例网站的标题和链接。
-
创建scrapy项目:
scrapy startproject example -
定义数据结构(
example/items.py):import scrapy class exampleitem(scrapy.item): title = scrapy.field() link = scrapy.field() -
创建爬虫类(
example/spiders/example_spider.py):import scrapy from example.items import exampleitem class examplespider(scrapy.spider): name = "example" start_urls = ['http://example.com'] def parse(self, response): for item in response.css('div.item'): example_item = exampleitem() example_item['title'] = item.css('a.title::text').get() example_item['link'] = item.css('a::attr(href)').get() yield example_item -
配置pipelines(
example/settings.py):item_pipelines = { 'example.pipelines.examplepipeline': 300, } -
定义pipelines(
example/pipelines.py):class examplepipeline: def process_item(self, item, spider): # 这里可以进行数据清洗和存储 print(f"title: {item['title']}, link: {item['link']}") return item -
运行爬虫:
scrapy crawl example
这个爬虫会访问http://example.com,提取每个div.item中的标题和链接,并将其输出。
3.如何处理爬虫中遇到的反爬机制,如captcha和ip封锁?有哪些常用的解决方法?
处理反爬机制
-
captcha(验证码)
- 解决方法:
- 手动解决:当爬虫遇到captcha时,暂停并通知人工解决。这种方法不适合大规模爬取。
- 使用第三方服务:一些服务提供自动解码captcha的功能,如2captcha、anti-captcha等。这些服务通常需要付费,并且可能并不完全可靠。
- 图像识别:使用机器学习和图像识别技术训练模型来自动识别captcha,但这种方法需要大量的数据和计算资源,且效果因captcha复杂度而异。
- 绕过captcha:通过模拟正常用户行为(如慢速爬取、添加浏览器头等)减少触发captcha的机会。
- 解决方法:
-
ip封锁
- 解决方法:
- 使用代理:通过使用代理服务器更换ip地址,常见的有免费代理、付费代理和代理池。付费代理通常更稳定可靠。
- 分布式爬取:将爬虫部署到多个服务器上,分散爬取任务,减少单个ip的访问频率。
- 请求间隔:在每次请求之间添加随机延迟,模拟人类用户的访问行为。
- 使用vpn:更换vpn节点的ip地址,绕过ip封锁。
- 解决方法:
-
模拟正常用户行为
- 使用浏览器模拟工具:如selenium,可以模拟浏览器的正常操作行为,处理javascript渲染和交互。
- 设置请求头:模仿真实浏览器的请求头,如user-agent、referer、accept-language等,避免被识别为爬虫。
- 请求频率控制:避免短时间内大量请求,减少被封锁的风险。
示例:使用selenium处理captcha和代理
-
安装selenium和相关驱动:
pip install selenium -
使用selenium和代理来爬取网页:
from selenium import webdriver from selenium.webdriver.common.by import by from selenium.webdriver.common.keys import keys from selenium.webdriver.chrome.service import service from webdriver_manager.chrome import chromedrivermanager # 设置代理 options = webdriver.chromeoptions() options.add_argument('--proxy-server=http://your_proxy:your_port') # 初始化webdriver driver = webdriver.chrome(service=service(chromedrivermanager().install()), options=options) # 访问目标网页 driver.get('http://example.com') # 查找元素并交互 search_box = driver.find_element(by.name, 'q') search_box.send_keys('scrapy' + keys.return) # 处理captcha(如果有) # 需要人工解决或使用第三方服务 # 关闭浏览器 driver.quit()
这个示例展示了如何使用selenium和代理来访问网页,并模拟用户的搜索行为。
4.如何使用beautifulsoup解析html,并提取特定的元素或数据?请给出一个简单的示例。
beautifulsoup是一个非常强大的python库,可以用来解析和提取html或xml文档中的数据。
安装beautifulsoup
首先,确保你已经安装了beautifulsoup和requests库:
pip install beautifulsoup4 requests
使用beautifulsoup解析html并提取数据
以下是一个简单的示例,演示如何使用beautifulsoup从一个网页中提取标题和链接。
-
导入库:
import requests from bs4 import beautifulsoup -
发送http请求:
url = 'http://example.com' response = requests.get(url) -
解析html:
soup = beautifulsoup(response.content, 'html.parser') -
提取特定元素: 例如,提取所有标题和链接:
for item in soup.find_all('a'): title = item.get_text() link = item.get('href') print(f'title: {title}, link: {link}')
完整的示例代码
下面是一个完整的示例,演示如何使用beautifulsoup从一个示例网页中提取所有<a>标签的文本和链接。
import requests
from bs4 import beautifulsoup
# 发送http请求
url = 'http://example.com'
response = requests.get(url)
# 解析html
soup = beautifulsoup(response.content, 'html.parser')
# 提取所有<a>标签的文本和链接
for item in soup.find_all('a'):
title = item.get_text()
link = item.get('href')
print(f'title: {title}, link: {link}')
解释
5.解释什么是爬虫中的“深度优先搜索”和“广度优先搜索”,以及它们在什么情况下各自适用?
深度优先搜索(dfs)
定义: 深度优先搜索是一种遍历或搜索树或图的算法,从起始节点开始,一直沿着一个分支走到底,再回溯到上一个节点继续搜索下一个分支,直到遍历完所有节点。
特点:
- 递归:通常用递归实现,或者使用栈来模拟递归过程。
- 内存占用低:在有大量分支的情况下,内存占用比广度优先搜索低。
- 适合目标较深的情况:如果目标节点距离起始节点较深,dfs能更快找到目标。
适用场景:
- 需要遍历所有节点的情况,如生成树、迷宫搜索。
- 目标节点较深,且分支较多时。
广度优先搜索(bfs)
定义: 广度优先搜索是一种遍历或搜索树或图的算法,从起始节点开始,先访问离起始节点最近的节点,然后逐层向外扩展,直到遍历完所有节点。
特点:
- 队列实现:通常使用队列实现。
- 内存占用高:在有大量分支的情况下,内存占用比深度优先搜索高。
- 最短路径:能找到从起始节点到目标节点的最短路径。
适用场景:
- 需要找到最短路径的情况,如网络路由、社交网络分析。
- 目标节点距离起始节点较近,且分支较少时。
示例
以下是分别使用dfs和bfs实现网页爬虫的简单示例:
dfs 爬虫示例
import requests
from bs4 import beautifulsoup
def dfs_crawl(url, visited):
if url in visited:
return
visited.add(url)
response = requests.get(url)
soup = beautifulsoup(response.content, 'html.parser')
print(f'crawled: {url}')
for link in soup.find_all('a', href=true):
next_url = link['href']
if next_url.startswith('http'):
dfs_crawl(next_url, visited)
start_url = 'http://example.com'
visited = set()
dfs_crawl(start_url, visited)
bfs 爬虫示例
import requests
from bs4 import beautifulsoup
from collections import deque
def bfs_crawl(start_url):
visited = set()
queue = deque([start_url])
while queue:
url = queue.popleft()
if url in visited:
continue
visited.add(url)
response = requests.get(url)
soup = beautifulsoup(response.content, 'html.parser')
print(f'crawled: {url}')
for link in soup.find_all('a', href=true):
next_url = link['href']
if next_url.startswith('http') and next_url not in visited:
queue.append(next_url)
start_url = 'http://example.com'
bfs_crawl(start_url)
解释
6.在进行大规模数据爬取时,如何处理数据存储和管理?你会选择哪种存储方式,为什么?
数据存储和管理
在进行大规模数据爬取时,数据的存储和管理是一个关键问题。我们需要考虑数据的规模、访问频率、结构化程度以及数据的持久性等因素。
常见的存储方式
-
文件存储
- 文本文件(如csv、json):适合小规模和结构化数据。
- 优点:易于使用和共享,适合快速测试和开发。
- 缺点:不适合大规模数据,搜索和查询效率低。
- 二进制文件:适合存储图片、视频等二进制数据。
- 优点:适合存储非结构化数据。
- 缺点:不适合存储结构化数据,查询和管理困难。
- 文本文件(如csv、json):适合小规模和结构化数据。
-
关系型数据库(如mysql、postgresql)
- 优点:支持复杂查询、事务处理和数据完整性约束,适合结构化数据。
- 缺点:对于非结构化数据和大规模数据存储,性能可能不足。
-
nosql数据库(如mongodb、cassandra)
- 文档型数据库(如mongodb):适合半结构化和非结构化数据。
- 优点:灵活的模式,适合大规模数据存储和高并发访问。
- 缺点:不支持复杂事务,数据一致性保障较弱。
- 列存储数据库(如cassandra):适合大规模和高吞吐量的数据存储。
- 优点:高可扩展性,适合分布式存储和查询。
- 缺点:查询灵活性较低,学习曲线较陡。
- 文档型数据库(如mongodb):适合半结构化和非结构化数据。
-
数据仓库(如amazon redshift、google bigquery)
- 优点:适合大规模数据分析和批处理,支持复杂查询和聚合操作。
- 缺点:实时性较差,适合离线数据处理和分析。
-
分布式文件系统(如hdfs)
- 优点:适合大规模数据存储和处理,支持分布式计算框架(如hadoop、spark)。
- 缺点:管理复杂,查询和处理需要专门的工具和框架。
存储选择的考虑因素
- 数据规模:如果数据量较小,可以选择文件存储;如果数据量很大,建议使用分布式存储系统或数据仓库。
- 数据结构:结构化数据适合关系型数据库;半结构化和非结构化数据适合nosql数据库或文件存储。
- 访问频率:高频访问和高并发场景下,nosql数据库和分布式文件系统表现更好。
- 数据一致性:关系型数据库提供强一致性保障,适合对数据一致性要求高的场景。
- 查询需求:如果需要复杂查询和数据分析,选择支持sql的存储系统,如关系型数据库或数据仓库。
示例:使用mongodb存储爬取的数据
-
安装mongodb python驱动:
pip install pymongo -
存储数据到mongodb的示例代码:
import requests from bs4 import beautifulsoup from pymongo import mongoclient # 连接到mongodb client = mongoclient('localhost', 27017) db = client['web_crawler'] collection = db['example_data'] # 发送http请求 url = 'http://example.com' response = requests.get(url) # 解析html soup = beautifulsoup(response.content, 'html.parser') # 提取数据并存储到mongodb for item in soup.find_all('a'): data = { 'title': item.get_text(), 'link': item.get('href') } collection.insert_one(data) print("data stored in mongodb")
解释
总结
7.在爬取动态加载内容的网页时,你会使用哪些技术和工具来获取所需数据?
动态加载内容的网页
动态加载内容的网页通常是指使用javascript动态生成或加载内容的网页。这些内容在初始加载时并不包含在html源代码中,而是通过异步请求(如ajax)从服务器获取并在浏览器中渲染。
常用的技术和工具
-
selenium
- 简介:selenium是一个用于自动化浏览器操作的工具,可以模拟用户在浏览器中的操作,如点击、输入等。适合处理需要javascript渲染的网页。
- 优点:可以处理复杂的用户交互和javascript渲染。
- 缺点:速度较慢,资源消耗较大。
-
playwright
- 简介:playwright是一个现代化的浏览器自动化工具,支持多种浏览器(如chromium、firefox、webkit),功能强大且易用。
- 优点:支持多浏览器自动化,功能强大,适合处理复杂网页。
- 缺点:需要更多的学习和配置时间。
-
headless browsers(无头浏览器)
- 简介:无头浏览器是指没有图形界面的浏览器,适用于自动化任务和脚本化网页交互。常用的无头浏览器有puppeteer(用于控制chromium)和phantomjs。
- 优点:性能较高,适合大规模爬取。
- 缺点:可能需要更多的配置和调试。
-
network requests(网络请求)
- 简介:有时可以通过分析浏览器的网络请求,直接发送相同的请求获取数据。这种方法绕过了javascript渲染,直接获取服务器返回的json或其他格式的数据。
- 优点:速度快,资源消耗少。
- 缺点:需要分析和构造正确的请求,有时会遇到反爬机制。
示例:使用selenium爬取动态内容
以下是使用selenium爬取动态加载内容的示例代码:
-
安装selenium和浏览器驱动:
pip install selenium -
使用selenium爬取动态内容:
from selenium import webdriver from selenium.webdriver.common.by import by from selenium.webdriver.chrome.service import service from webdriver_manager.chrome import chromedrivermanager import time # 初始化selenium webdriver driver = webdriver.chrome(service=service(chromedrivermanager().install())) # 访问目标网页 url = 'http://example.com' driver.get(url) # 等待页面加载完成 time.sleep(5) # 可以根据页面加载时间调整 # 提取动态加载的内容 items = driver.find_elements(by.css_selector, 'div.item') for item in items: title = item.find_element(by.css_selector, 'a.title').text link = item.find_element(by.css_selector, 'a').get_attribute('href') print(f'title: {title}, link: {link}') # 关闭浏览器 driver.quit()
示例:使用playwright爬取动态内容
-
安装playwright:
pip install playwright playwright install -
使用playwright爬取动态内容:
from playwright.sync_api import sync_playwright with sync_playwright() as p: # 启动浏览器 browser = p.chromium.launch(headless=false) page = browser.new_page() # 访问目标网页 url = 'http://example.com' page.goto(url) # 等待页面加载完成 page.wait_for_timeout(5000) # 可以根据页面加载时间调整 # 提取动态加载的内容 items = page.query_selector_all('div.item') for item in items: title = item.query_selector('a.title').inner_text() link = item.query_selector('a').get_attribute('href') print(f'title: {title}, link: {link}') # 关闭浏览器 browser.close()
示例:通过网络请求直接获取数据
有时可以通过分析浏览器的网络请求,直接发送相同的请求获取数据:
-
分析网络请求,找到获取数据的api。
-
使用requests库发送请求并获取数据:
import requests url = 'http://example.com/api/data' params = { 'param1': 'value1', 'param2': 'value2', } response = requests.get(url, params=params) data = response.json() for item in data['items']: title = item['title'] link = item['link'] print(f'title: {title}, link: {link}')
总结
8.在设计一个爬虫时,如何确保它的效率和稳定性?你会采取哪些措施来优化爬虫性能?
确保爬虫的效率和稳定性
-
并发与异步处理:
- 并发:通过多线程或多进程来并发处理多个请求,可以显著提高爬取速度。
- 异步处理:使用异步编程(如python的asyncio)来处理i/o密集型任务,可以进一步提高效率。
-
使用合适的库和工具:
- scrapy:一个强大的爬虫框架,提供了很多内置功能来处理并发请求、数据存储和错误处理。
- aiohttp:一个异步http客户端库,适合与asyncio一起使用,处理高并发请求。
- twisted:一个事件驱动的网络引擎,适合构建高并发网络应用。
-
请求速率控制:
- 限速:设置请求间隔,避免过快发送请求导致被封禁。
- 随机延迟:在请求间隔中加入随机延迟,模拟人类行为,减少被识别为爬虫的风险。
-
错误处理和重试机制:
- 异常捕获:捕获并处理请求中的各种异常,如超时、连接错误等。
- 重试机制:对失败的请求进行重试,确保数据完整性。
-
分布式爬虫:
- 分布式架构:将爬虫任务分布到多个节点上,提高爬取速度和覆盖范围。
- 消息队列:使用消息队列(如rabbitmq、kafka)来协调和管理爬虫任务。
-
缓存和去重:
- 缓存:对已经爬取过的页面进行缓存,减少重复请求。
- 去重:使用数据结构(如布隆过滤器)来记录已经爬取的url,避免重复爬取。
-
代理和ip轮换:
- 代理池:使用代理池来轮换ip地址,避免被封禁。
- 定期更换ip:定期更换ip,模拟不同用户访问,减少被封禁的风险。
示例:使用scrapy进行并发爬取
-
安装scrapy:
pip install scrapy -
创建scrapy项目:
scrapy startproject example cd example scrapy genspider example_spider example.com -
编辑
example_spider.py:import scrapy class examplespider(scrapy.spider): name = 'example_spider' start_urls = ['http://example.com'] def parse(self, response): for item in response.css('a'): yield { 'title': item.css('::text').get(), 'link': item.css('::attr(href)').get() } -
配置并发和限速: 在
settings.py中进行配置:# 限制并发请求数量 concurrent_requests = 16 # 设置请求间隔(秒) download_delay = 1 # 启用随机延迟 randomize_download_delay = true # 启用重试机制 retry_enabled = true retry_times = 3 -
运行scrapy爬虫:
scrapy crawl example_spider
示例:使用aiohttp进行异步爬取
-
安装aiohttp:
pip install aiohttp -
使用aiohttp进行异步爬取:
import aiohttp import asyncio from bs4 import beautifulsoup async def fetch(session, url): async with session.get(url) as response: return await response.text() async def main(): urls = ['http://example.com/page1', 'http://example.com/page2'] async with aiohttp.clientsession() as session: tasks = [fetch(session, url) for url in urls] responses = await asyncio.gather(*tasks) for response in responses: soup = beautifulsoup(response, 'html.parser') for item in soup.find_all('a'): title = item.get_text() link = item.get('href') print(f'title: {title}, link: {link}') asyncio.run(main())
总结
9.如何处理爬虫过程中遇到的反爬机制,如机器人检测和ip封禁?你会采取哪些措施来规避这些问题?
反爬机制及应对措施
-
机器人检测
- 说明:很多网站使用机器人检测来区分正常用户和爬虫,常见的检测方法包括检查请求头、行为模式和captcha等。
应对措施:
-
伪装请求头:模拟正常用户请求,添加合适的请求头,如user-agent、referer、accept-language等。
headers = { 'user-agent': 'mozilla/5.0 (windows nt 10.0; win64; x64) applewebkit/537.36 (khtml, like gecko) chrome/91.0.4472.124 safari/537.36', 'referer': 'http://example.com', 'accept-language': 'en-us,en;q=0.9', } response = requests.get(url, headers=headers) -
模拟用户行为:通过随机延迟、模拟点击和滚动等方式模拟人类用户行为。
import time from random import uniform time.sleep(uniform(1, 3)) # 随机延迟1到3秒 -
处理captcha:使用第三方服务或手动解决captcha,或者使用机器学习技术识别简单的captcha。
-
ip封禁
- 说明:如果某个ip地址发送请求过于频繁,可能会被封禁。
应对措施:
-
使用代理:通过代理服务器发送请求,可以隐藏真实ip地址,并避免被封禁。
proxies = { 'http': 'http://proxy_ip:proxy_port', 'https': 'https://proxy_ip:proxy_port', } response = requests.get(url, proxies=proxies) -
轮换ip:使用代理池,定期更换ip,避免使用同一个ip频繁访问同一网站。
import random proxy_list = ['http://proxy1', 'http://proxy2', 'http://proxy3'] proxy = {'http': random.choice(proxy_list)} response = requests.get(url, proxies=proxy) -
分布式爬虫:将爬虫任务分布到多个节点,每个节点使用不同的ip地址,降低单个ip被封禁的风险。
-
速率限制
- 说明:很多网站会限制单位时间内的请求数量。
应对措施:
-
限速:设置请求间隔,避免过快发送请求。
import time def fetch(url): time.sleep(2) # 请求间隔2秒 response = requests.get(url) return response -
随机延迟:在请求间隔中加入随机延迟,模拟人类行为。
import time from random import uniform def fetch(url): time.sleep(uniform(1, 3)) # 随机延迟1到3秒 response = requests.get(url) return response
-
检测爬虫模式
- 说明:一些网站会检测用户的行为模式,识别出爬虫行为。
应对措施:
- 混淆访问模式:改变访问顺序和频率,模拟真实用户行为。
- 模拟用户交互:使用selenium等工具模拟用户点击、滚动、输入等操作。
from selenium import webdriver from selenium.webdriver.common.by import by from selenium.webdriver.chrome.service import service from webdriver_manager.chrome import chromedrivermanager driver = webdriver.chrome(service=service(chromedrivermanager().install())) driver.get('http://example.com') # 模拟点击和滚动 element = driver.find_element(by.css_selector, 'a.link') element.click() driver.execute_script('window.scrollto(0, document.body.scrollheight);')
示例:综合应对措施
下面是一个综合使用上述应对措施的爬虫示例:
import requests
from random import uniform, choice
import time
def fetch(url, headers, proxies):
time.sleep(uniform(1, 3)) # 随机延迟
response = requests.get(url, headers=headers, proxies=proxies)
return response
# 设置请求头
headers = {
'user-agent': 'mozilla/5.0 (windows nt 10.0; win64; x64) applewebkit/537.36 (khtml, like gecko) chrome/91.0.4472.124 safari/537.36',
'referer': 'http://example.com',
'accept-language': 'en-us,en;q=0.9',
}
# 设置代理池
proxy_list = ['http://proxy1', 'http://proxy2', 'http://proxy3']
url = 'http://example.com'
proxies = {'http': choice(proxy_list)}
response = fetch(url, headers, proxies)
print(response.text)
总结
10.如何处理爬虫过程中遇到的数据质量问题,如重复数据、缺失数据和错误数据?你会采取哪些措施来确保数据的准确性和完整性?
处理数据质量问题及措施
-
重复数据
- 问题:在爬取过程中可能会因为请求重复或页面结构变化导致数据重复。
- 应对措施:
- 数据去重:使用数据结构(如集合或数据库的唯一性约束)来存储已经爬取过的数据,避免重复获取。
- 指纹(fingerprint)技术:对数据进行哈希或其他摘要算法处理,生成唯一标识符,用于识别和去重重复数据。
示例代码(使用python的集合进行数据去重):
seen_urls = set() # 在爬取过程中 for url in urls_to_crawl: if url not in seen_urls: # 爬取数据的操作 seen_urls.add(url) -
缺失数据
- 问题:有时网页结构变化或请求失败可能导致数据缺失。
- 应对措施:
- 错误处理和重试:对于请求失败的情况,实现重试机制,确保数据的完整性。
- 数据验证:在解析数据前进行有效性验证,确保必要字段的存在。
- 日志记录:记录缺失数据和失败请求,便于后续分析和修复。
示例代码(使用python的异常处理和重试机制):
import requests from requests.exceptions import requestexception max_retries = 3 def fetch_data(url): retries = 0 while retries < max_retries: try: response = requests.get(url) response.raise_for_status() return response.text except requestexception as e: print(f"request failed: {e}") retries += 1 time.sleep(2) # 等待一段时间后重试 return none -
错误数据
- 问题:有时网页内容可能因为格式错误、编码问题或反爬虫策略而导致数据错误。
- 应对措施:
- 数据清洗和预处理:对爬取的数据进行清洗和预处理,去除不合规的数据。
- 异常处理:捕获和处理解析数据时可能遇到的异常,避免程序崩溃。
- 人工审核:对关键数据进行人工审核,确保数据的准确性和可信度。
示例代码(使用python的异常处理和数据清洗):
try: # 解析数据的操作 parsed_data = parse_data(raw_data) except exception as e: print(f"error parsing data: {e}") parsed_data = none # 数据清洗示例(去除空白字符) clean_data = data.strip() if data else none
示例:综合应对措施
下面是一个综合使用上述应对措施的爬虫示例:
import requests
from hashlib import sha256
seen_urls = set()
def fetch_data(url):
if url in seen_urls:
return none
try:
response = requests.get(url)
response.raise_for_status()
seen_urls.add(url)
return response.text
except requests.exceptions.requestexception as e:
print(f"request failed: {e}")
return none
def parse_data(html_content):
# 解析数据的操作
# 示例:提取标题和链接
titles = []
links = []
# ... (解析逻辑)
return titles, links
# 主程序
url = 'http://example.com'
html_content = fetch_data(url)
if html_content:
titles, links = parse_data(html_content)
for title, link in zip(titles, links):
print(f"title: {title}, link: {link}")
else:
print("failed to fetch data.")
总结
11.在爬虫过程中,如何处理页面结构变化导致的解析失败问题?你会采取什么方法来应对这种情况?
处理页面结构变化及应对方法
-
问题分析:
- 页面结构变化:网站更新或维护导致html结构、css选择器或数据位置发生变化,导致之前编写的解析代码失效。
-
应对方法:
- 定期更新选择器:定期检查和更新css选择器或xpath表达式,以适应页面结构的变化。
- 灵活的解析策略:采用灵活的解析策略,例如优先使用唯一标识符或属性进行数据提取,而不是依赖于固定的页面结构。
- 异常处理和回退策略:在解析数据时,实现异常处理机制,如果某个数据项无法正常解析,则回退到备用策略或记录异常信息以后续分析和修复。
示例应对方法:
-
定期更新选择器:
import requests from bs4 import beautifulsoup def fetch_data(url): response = requests.get(url) return response.text def parse_data(html_content): soup = beautifulsoup(html_content, 'html.parser') # 更新选择器,注意页面结构变化 title = soup.select_one('h1.title').text description = soup.select_one('div.description').text return title, description url = 'http://example.com' html_content = fetch_data(url) if html_content: title, description = parse_data(html_content) print(f"title: {title}") print(f"description: {description}") -
灵活的解析策略:
import requests from bs4 import beautifulsoup def fetch_data(url): response = requests.get(url) return response.text def parse_data(html_content): soup = beautifulsoup(html_content, 'html.parser') # 使用备用选择器或属性提取数据 title = soup.find('h1', class_='title').text if soup.find('h1', class_='title') else '' description = soup.find('div', id='description').text if soup.find('div', id='description') else '' return title, description url = 'http://example.com' html_content = fetch_data(url) if html_content: title, description = parse_data(html_content) print(f"title: {title}") print(f"description: {description}") -
异常处理和回退策略:
import requests from bs4 import beautifulsoup def fetch_data(url): try: response = requests.get(url) response.raise_for_status() return response.text except requests.exceptions.requestexception as e: print(f"request failed: {e}") return none def parse_data(html_content): try: soup = beautifulsoup(html_content, 'html.parser') title = soup.select_one('h1.title').text description = soup.select_one('div.description').text return title, description except attributeerror as e: print(f"error parsing data: {e}") return none, none url = 'http://example.com' html_content = fetch_data(url) if html_content: title, description = parse_data(html_content) if title and description: print(f"title: {title}") print(f"description: {description}") else: print("failed to parse data.")
进一步应对页面结构变化的方法
-
使用正则表达式进行文本匹配:
- 在某些情况下,页面的数据可能不是通过html标签提供的,而是在javascript生成的动态内容或其他方式。使用正则表达式可以在页面源代码中直接搜索和提取需要的信息。
import re html_content = '<div>title: hello world</div>' pattern = r'title: (.*)' match = re.search(pattern, html_content) if match: title = match.group(1) print(f"title: {title}")
- 在某些情况下,页面的数据可能不是通过html标签提供的,而是在javascript生成的动态内容或其他方式。使用正则表达式可以在页面源代码中直接搜索和提取需要的信息。
-
使用api替代页面解析:
- 有些网站可能提供api来获取数据,而不是通过网页提供。如果可行,可以直接使用api获取数据,这种方式通常更稳定且减少了对页面结构变化的依赖。
-
监控和报警机制:
- 实现监控和报警机制,定期检查爬取结果和页面结构变化,及时发现问题并采取措施处理。
-
使用headless浏览器技术:
- 对于javascript渲染的页面或需要模拟用户操作的情况,可以考虑使用headless浏览器(如selenium + chrome webdriver)来获取渲染后的页面内容,确保数据的完整性和正确性。
示例:使用正则表达式进行文本匹配
import re
import requests
def fetch_data(url):
response = requests.get(url)
return response.text
def extract_title_with_regex(html_content):
pattern = r'<h1 class="title">(.*)</h1>'
match = re.search(pattern, html_content)
if match:
return match.group(1)
else:
return none
url = 'http://example.com'
html_content = fetch_data(url)
if html_content:
title = extract_title_with_regex(html_content)
if title:
print(f"title: {title}")
else:
print("failed to extract title using regex.")
else:
print("failed to fetch data.")
总结
12.对于如何处理爬虫过程中可能遇到的验证码识别问题有什么了解或想法呢?
-
问题分析:
- 验证码存在的原因:网站为了防止机器人访问和数据抓取,通常会设置验证码来验证用户身份或行为。
- 识别验证码的挑战:验证码通常以图片或文字形式呈现,需要程序自动识别,这是一项技术上的挑战。
-
应对方法:
- 使用第三方验证码识别服务:有些第三方平台提供了验证码识别的api服务,可以集成到爬虫程序中使用。
- 机器学习和图像处理:使用机器学习算法和图像处理技术来识别验证码,如图像识别、字符分割和模式匹配等。
- 人工干预和手动输入:对于无法自动识别的验证码,可以通过人工干预,手动输入验证码,然后继续爬取操作。
使用第三方验证码识别服务示例:
使用第三方服务的示例可以是通过调用其api来实现验证码的识别。以下是一个简单的示例代码:
import requests
def solve_captcha(image_url, api_key):
captcha_url = f'http://captcha-service.com/solve?url={image_url}&apikey={api_key}'
response = requests.get(captcha_url)
if response.status_code == 200:
captcha_text = response.json().get('captcha_text')
return captcha_text
else:
return none
# 调用示例
captcha_text = solve_captcha('http://example.com/captcha.jpg', 'your_api_key')
if captcha_text:
print(f"solved captcha: {captcha_text}")
else:
print("failed to solve captcha.")
使用机器学习和图像处理的示例:
使用机器学习和图像处理技术来识别验证码,通常需要先收集训练数据,然后使用适当的算法进行模型训练和测试。以下是一个简化的示例:
import cv2
import pytesseract
from pil import image
import requests
from io import bytesio
def solve_captcha(image_url):
response = requests.get(image_url)
img = image.open(bytesio(response.content))
img = cv2.cvtcolor(np.array(img), cv2.color_rgb2bgr)
# 假设验证码在图片上的位置 (x, y, w, h)
cropped_img = img[y:y+h, x:x+w]
# 使用tesseract进行ocr识别
captcha_text = pytesseract.image_to_string(cropped_img)
return captcha_text
# 调用示例
captcha_text = solve_captcha('http://example.com/captcha.jpg')
print(f"solved captcha: {captcha_text}")
手动输入验证码的示例:
对于无法自动识别的验证码,最后的应对方法是人工干预,手动输入验证码,然后继续爬取操作。这通常需要程序停止执行,等待用户输入验证码,并在输入后继续执行爬取任务。
总结
13.处理反爬虫策略时,通常会采取哪些方法来确保爬虫的持续运行和数据的稳定获取?请举例说明。
处理反爬虫策略的方法
-
使用合适的请求头:
- 问题分析:网站通常通过 user-agent、referer 等 http 头信息来检测爬虫行为。
- 应对方法:
- 设置合理的 user-agent:模拟真实浏览器的 user-agent,避免被识别为爬虫。
- 添加合理的 referer:在请求头中添加合理的 referer,模拟从其他页面跳转过来的请求。
示例代码(设置请求头):
import requests headers = { 'user-agent': 'mozilla/5.0 (windows nt 10.0; win64; x64) applewebkit/537.36 (khtml, like gecko) chrome/91.0.4472.124 safari/537.36', 'referer': 'http://example.com' } url = 'http://example.com' response = requests.get(url, headers=headers) -
使用代理 ip:
- 问题分析:网站可能会监测频繁的请求或来自同一 ip 的高流量,如果检测到异常行为,可能会封禁该 ip 地址。
- 应对方法:
- 轮换代理 ip:使用代理池来轮换不同的 ip 地址,避免过多请求集中在同一 ip 上。
- ip 池服务:使用专门的代理 ip 服务商,提供稳定和高匿名度的代理 ip,避免被目标网站检测到。
示例代码(使用代理请求):
import requests proxies = { 'http': 'http://your_proxy_ip:port', 'https': 'https://your_proxy_ip:port' } url = 'http://example.com' response = requests.get(url, proxies=proxies) -
限制请求频率:
- 问题分析:连续高频率的请求容易被网站识别为恶意访问。
- 应对方法:
- 设置请求间隔:在爬取过程中设置合理的请求间隔,避免短时间内发送过多请求。
- 随机化请求间隔:在请求间隔中引入随机化,模拟人类的自然访问行为。
示例代码(设置请求间隔):
import time import random import requests url = 'http://example.com' def fetch_data_with_delay(url): time.sleep(random.uniform(1, 3)) # 随机间隔1到3秒 response = requests.get(url) return response.text html_content = fetch_data_with_delay(url) -
处理验证码和 javascript 渲染:
- 问题分析:有些网站使用验证码或依赖 javascript 渲染页面内容,需要特殊处理。
- 应对方法:
- 使用自动化工具:如selenium等工具来模拟浏览器行为,处理动态页面内容和验证码。
- 分析和模拟请求:通过分析网站的请求和响应,模拟正确的请求流程和参数。
示例代码(使用selenium处理动态内容):
from selenium import webdriver url = 'http://example.com' driver = webdriver.chrome() driver.get(url) # 等待页面加载和处理验证码
总结
14.在爬取大规模数据时,你如何有效地监控和调试爬虫程序?请分享你的经验或者使用过的工具和技巧。
监控和调试爬虫程序的方法
-
日志记录:
- 问题分析:通过详细的日志记录可以追踪爬取过程中的各种操作和事件,有助于排查问题和分析程序行为。
- 应对方法:
- 使用标准库 logging 进行日志记录:记录关键操作、异常情况和重要变量值。
- 设置不同级别的日志信息:如 debug、info、warning、error 等,便于根据需要调整显示级别。
示例代码(使用 logging 进行日志记录):
import logging # 配置日志记录器 logging.basicconfig(filename='crawler.log', level=logging.debug, format='%(asctime)s - %(levelname)s - %(message)s') def fetch_data(url): try: logging.info(f"fetching data from {url}") # 爬取数据的代码 response = requests.get(url) # 其他处理逻辑 logging.debug(f"response status code: {response.status_code}") except exception as e: logging.error(f"failed to fetch data from {url}: {str(e)}") # 调用示例 fetch_data('http://example.com') -
异常处理:
- 问题分析:爬虫程序可能会面临网络超时、连接中断、页面解析失败等异常情况,需要适当地处理以保证程序的稳定性。
- 应对方法:
- 使用 try-except 语句捕获异常:在关键的网络请求、页面解析和数据处理过程中使用 try-except 块捕获异常,并记录到日志中。
- 实现重试机制:针对特定的网络请求或页面解析,可以实现简单的重试逻辑,以应对临时性的网络问题。
示例代码(异常处理和重试机制):
import requests import logging import time logging.basicconfig(filename='crawler.log', level=logging.debug, format='%(asctime)s - %(levelname)s - %(message)s') def fetch_data_with_retry(url, max_retry=3): retries = 0 while retries < max_retry: try: logging.info(f"fetching data from {url}, attempt {retries + 1}") response = requests.get(url) response.raise_for_status() # 检查响应状态码 return response.text except requests.exceptions.requestexception as e: logging.error(f"request error: {str(e)}") retries += 1 if retries < max_retry: logging.info(f"retrying in 5 seconds...") time.sleep(5) else: logging.error("max retries exceeded.") raise # 调用示例 try: data = fetch_data_with_retry('http://example.com') # 处理获取的数据 except exception as e: logging.error(f"failed to fetch data: {str(e)}") -
性能监控和优化:
- 问题分析:爬虫程序在处理大规模数据时,需要关注其性能表现,及时发现和优化性能瓶颈。
- 应对方法:
- 使用性能分析工具:如 cprofile、line_profiler 等工具对代码进行性能分析,找出耗时较长的函数或代码段。
- 优化代码逻辑:根据性能分析结果优化代码,减少不必要的网络请求或数据处理操作,提升爬取效率。
示例代码(使用 cprofile 进行性能分析):
import cprofile def main(): # 主要爬取逻辑 pass if __name__ == '__main__': cprofile.run('main()')
总结
15.处理需要登录或授权访问的网站数据时,你通常会如何处理登录认证和会话管理?请描述你的方法或者采取过的措施。
处理登录认证和会话管理的方法
-
使用 requests 库进行登录认证:
- 问题分析:有些网站需要用户登录后才能访问特定页面或数据,因此需要实现登录认证功能。
- 应对方法:
- 使用 requests 库发送 post 请求模拟登录:通过向登录页面发送用户名和密码等认证信息,获取登录后的会话。
- 保存登录后的会话状态:使用 requests.session 对象来保持会话状态,确保后续的请求能够保持登录状态。
示例代码(使用 requests 实现登录认证):
import requests login_url = 'http://example.com/login' data = { 'username': 'your_username', 'password': 'your_password' } # 创建会话对象 session = requests.session() # 发送登录请求 response = session.post(login_url, data=data) # 检查登录是否成功 if response.status_code == 200: print("登录成功!") else: print("登录失败!") # 使用 session 对象发送其他请求,保持登录状态 response = session.get('http://example.com/protected_page') -
处理登录状态的持久化:
- 问题分析:登录后获取的会话状态需要在多个请求之间持久化,确保每次请求都能维持登录状态。
- 应对方法:
- 将 session 对象保存到持久化存储:可以使用 pickle 序列化 session 对象,或者将会话信息保存到数据库或文件中。
- 定期更新会话信息:根据网站的登录策略,定期更新会话信息或重新登录,避免会话过期或失效。
示例代码(持久化 session 对象):
import requests import pickle # 登录过程省略... # 将 session 对象保存到文件 with open('session.pickle', 'wb') as f: pickle.dump(session, f) # 加载 session 对象 with open('session.pickle', 'rb') as f: session = pickle.load(f) # 使用 session 对象发送请求 response = session.get('http://example.com/profile') -
处理验证码和多因素认证:
- 问题分析:有些网站可能会要求输入验证码或进行多因素认证,需要特殊处理以完成登录流程。
- 应对方法:
- 使用第三方库处理验证码:如 pytesseract 处理图像验证码,或者通过人工输入验证码的方式解决。
- 处理多因素认证:根据网站要求,逐步完成多因素认证流程,确保登录成功并获取有效的会话状态。
示例代码(处理图像验证码):
import requests from pil import image import pytesseract # 获取验证码图片 img_url = 'http://example.com/captcha_image.jpg' response = requests.get(img_url) img = image.open(bytesio(response.content)) # 使用 pytesseract 识别验证码 captcha_text = pytesseract.image_to_string(img) # 将识别结果提交给登录表单 data['captcha'] = captcha_text # 发送带验证码的登录请求 response = session.post(login_url, data=data)
总结
16.在设计一个高效的爬虫系统时,你如何平衡数据抓取速度和对目标网站的访问频率?请分享你的方法或者采取的策略。
平衡数据抓取速度和访问频率的策略
-
设置合理的请求间隔:
- 问题分析:过于频繁的请求会增加服务器负载,可能导致网站采取反爬虫措施或者拒绝服务。
- 应对方法:
- 根据网站的 robots.txt 文件设定请求间隔:遵循 robots.txt 中的 crawl-delay 指令,设定合适的请求间隔。
- 随机化请求间隔:在设定的基础上,引入随机化请求间隔,避免过于规律的访问模式。
示例代码(随机化请求间隔):
import time import random import requests def fetch_data(url): # 设置基础请求间隔为2秒 base_interval = 2 # 引入随机化请求间隔,范围为1到3秒 interval = base_interval + random.uniform(1, 3) time.sleep(interval) response = requests.get(url) return response.text -
使用并发和异步处理:
- 问题分析:提高数据抓取速度的一种方法是使用并发请求或者异步处理技术。
- 应对方法:
- 使用多线程或者多进程:通过 python 的 threading 或者 multiprocessing 模块实现并发请求,加快数据抓取速度。
- 采用异步框架:如 asyncio 或者 aiohttp,利用非阻塞的异步 io 实现高效的并发处理,降低请求响应的等待时间。
示例代码(使用多线程并发请求):
import threading import requests def fetch_data(url): response = requests.get(url) return response.text urls = ['http://example.com/page1', 'http://example.com/page2', 'http://example.com/page3'] threads = [] for url in urls: thread = threading.thread(target=fetch_data, args=(url,)) thread.start() threads.append(thread) for thread in threads: thread.join() -
监控和调整策略:
- 问题分析:持续监控数据抓取的效率和对目标网站的访问频率,及时调整策略以适应网站的反应。
- 应对方法:
- 实时监控日志和响应时间:记录请求响应时间和访问状态码,发现异常情况及时调整。
- 定期评估和优化:根据监控结果,定期评估和优化爬取策略,包括调整请求间隔、并发数量等参数。
示例代码(监控和调整策略):
import requests def fetch_data(url): response = requests.get(url) # 监控日志记录响应时间和状态码 if response.status_code != 200: print(f"failed to fetch data from {url}, status code: {response.status_code}") urls = ['http://example.com/page1', 'http://example.com/page2', 'http://example.com/page3'] for url in urls: fetch_data(url)
总结
平衡数据抓取速度和对目标网站的访问频率是设计高效爬虫系统的重要考虑因素。通过设置合理的请求间隔、使用并发和异步处理技术以及持续监控和调整策略,可以有效地提高数据抓取效率并减少对目标网站的影响,确保爬虫系统稳定运行并长期有效获取数据。
17.在处理需要定期更新的数据抓取任务时,你通常会如何设计和实现数据的增量更新机制?请分享你的方法或者采取的策略。
设计和实现数据的增量更新机制
在处理需要定期更新的数据抓取任务时,特别是对于大规模数据或者频繁变化的数据源,采用增量更新机制可以有效减少重复抓取和提升数据同步效率。以下是一些常见的方法和策略:
-
使用时间戳或版本号:
- 方法:通过记录每次数据抓取的时间戳或者版本号,可以识别出自上次抓取以来有更新的数据。
- 实现:在数据存储中添加时间戳字段或者版本号字段,每次抓取时检查目标数据源中的数据更新时间或版本信息,只抓取时间戳或版本号大于上次抓取时间戳或版本号的数据。
示例代码(基于时间戳的增量更新):
import datetime import pymongo # 连接 mongodb 数据库 client = pymongo.mongoclient('mongodb://localhost:27017/') db = client['my_database'] collection = db['my_collection'] def fetch_and_update_data(): last_updated_timestamp = datetime.datetime(2024, 7, 10, 0, 0, 0) # 上次抓取的时间戳 # 查询数据源中大于上次更新时间戳的数据 new_data = query_data_source(last_updated_timestamp) # 更新到数据库 for data in new_data: collection.update_one({'_id': data['_id']}, {'$set': data}, upsert=true) def query_data_source(last_updated_timestamp): # 查询数据源中大于指定时间戳的数据 # 示例中假设使用的是数据库查询操作或者 api 查询操作 # 假设数据源是 mongodb,查询大于指定时间戳的数据 new_data = collection.find({'timestamp': {'$gt': last_updated_timestamp}}) return list(new_data) fetch_and_update_data() -
使用唯一标识符进行增量更新:
- 方法:如果数据源提供唯一的标识符(如id或者url),可以根据标识符识别出新增或更新的数据。
- 实现:将每个数据项的唯一标识符与已存储的数据进行比对,新增或更新标识符不在已存储数据中的数据项。
示例代码(基于唯一标识符的增量更新):
import requests import hashlib def fetch_and_update_data(): stored_data = get_stored_data() # 获取已存储的数据标识符集合 new_data = query_data_source() # 查询数据源中的新数据 for data in new_data: data_id = hashlib.md5(data['url'].encode()).hexdigest() # 假设使用 url 作为唯一标识符 if data_id not in stored_data: store_data(data) stored_data.add(data_id) def get_stored_data(): # 获取已存储数据的标识符集合,可能从数据库或者其他存储中获取 return set() def query_data_source(): # 查询数据源中的新数据 response = requests.get('http://example.com/api/data') new_data = response.json() return new_data def store_data(data): # 将新数据存储到数据库或者其他存储中 pass fetch_and_update_data() -
定期全量更新与增量更新结合:
- 方法:定期执行全量数据抓取,同时通过增量更新机制处理增量数据,结合两者优势。
- 实现:定期执行全量数据抓取(如每周或每月一次),然后使用增量更新机制处理自上次全量更新以来的变化数据。
示例代码(定期全量更新与增量更新结合):
import datetime import requests def fetch_and_update_data(): last_full_update_time = datetime.datetime(2024, 7, 1, 0, 0, 0) # 上次全量更新时间 current_time = datetime.datetime.now() # 如果距离上次全量更新时间超过一周,执行全量更新 if (current_time - last_full_update_time).days >= 7: perform_full_update() else: perform_incremental_update(last_full_update_time) def perform_full_update(): # 执行全量数据抓取和更新 pass def perform_incremental_update(last_full_update_time): # 执行增量数据更新,查询自上次全量更新时间后的变化数据 new_data = query_data_source(last_full_update_time) update_data(new_data) def query_data_source(last_full_update_time): # 查询数据源中自上次全量更新时间后的变化数据 # 示例中假设使用的是数据库查询操作或者 api 查询操作 pass def update_data(new_data): # 更新到数据库或者其他存储中 pass fetch_and_update_data()
总结
18.在处理多级页面爬取时,你如何设计爬虫系统以有效地管理页面链接和避免重复抓取?请分享你的设计思路或者采取的策略。
设计爬虫系统管理页面链接和避免重复抓取的策略
-
使用队列管理页面链接:
- 方法:使用队列(如待抓取url队列)来管理需要访问和抓取的页面链接,确保每个页面链接只被抓取一次。
- 实现:当爬虫程序访问一个页面时,将页面中发现的新链接加入到待抓取队列中,同时标记已经访问过的链接,避免重复抓取。
示例代码(使用队列管理页面链接):
from queue import queue import requests from bs4 import beautifulsoup import time # 设置初始url和待抓取队列 base_url = 'http://example.com' queue = queue() queue.put(base_url) visited_urls = set() def crawl(): while not queue.empty(): url = queue.get() # 检查是否已经访问过 if url in visited_urls: continue # 访问页面并处理 try: response = requests.get(url) if response.status_code == 200: visited_urls.add(url) process_page(response.text) extract_links(response.text) except exception as e: print(f"failed to crawl {url}: {str(e)}") # 添加新的链接到待抓取队列 time.sleep(1) # 避免请求过快 queue.task_done() def process_page(html): # 处理页面内容,如抓取数据或者存储数据 pass def extract_links(html): # 使用 beautifulsoup 等工具提取页面中的链接 soup = beautifulsoup(html, 'html.parser') links = soup.find_all('a', href=true) for link in links: new_url = link['href'] if new_url.startswith('http'): # 只处理绝对链接 queue.put(new_url) crawl() -
使用哈希表或数据库记录访问状态:
- 方法:使用哈希表或者数据库来记录每个页面链接的访问状态(已访问或待访问),以及已经抓取的内容,确保链接不被重复抓取。
- 实现:在访问每个页面之前,先检查链接的状态(是否已经访问过),并将新的链接加入到待访问列表或数据库中。
示例代码(使用数据库记录访问状态):
import sqlite3 import requests from bs4 import beautifulsoup import hashlib import time # 连接 sqlite 数据库 conn = sqlite3.connect('crawler.db') cursor = conn.cursor() # 创建链接表 cursor.execute('''create table if not exists urls (url text primary key, visited integer)''') # 设置初始url base_url = 'http://example.com' cursor.execute('insert or ignore into urls (url, visited) values (?, 0)', (base_url,)) conn.commit() def crawl(): while true: # 获取待访问的url cursor.execute('select url from urls where visited = 0 limit 1') row = cursor.fetchone() if row is none: break url = row[0] # 访问页面并处理 try: response = requests.get(url) if response.status_code == 200: process_page(response.text) extract_links(response.text) # 更新访问状态 cursor.execute('update urls set visited = 1 where url = ?', (url,)) conn.commit() except exception as e: print(f"failed to crawl {url}: {str(e)}") time.sleep(1) # 避免请求过快 def process_page(html): # 处理页面内容,如抓取数据或者存储数据 pass def extract_links(html): # 使用 beautifulsoup 等工具提取页面中的链接 soup = beautifulsoup(html, 'html.parser') links = soup.find_all('a', href=true) for link in links: new_url = link['href'] if new_url.startswith('http'): # 只处理绝对链接 # 插入新的链接到数据库 cursor.execute('insert or ignore into urls (url, visited) values (?, 0)', (new_url,)) conn.commit() crawl() -
避免陷入死循环和循环重复访问:
- 方法:设置合理的链接深度限制或者路径记录,避免爬虫在多级页面间陷入死循环或者重复访问同一链接。
- 实现:在抓取每个页面时,记录页面的深度或者路径,检查新发现的链接是否已经在当前路径中出现过,避免重复访问。
示例代码(避免重复访问的深度限制):
import requests from bs4 import beautifulsoup import time base_url = 'http://example.com' visited_urls = set() def crawl(url, depth=1, max_depth=3): if depth > max_depth: return # 访问页面并处理 try: response = requests.get(url) if response.status_code == 200: visited_urls.add(url) process_page(response.text) extract_links(response.text, depth) except exception as e: print(f"failed to crawl {url}: {str(e)}") time.sleep(1) # 避免请求过快 def process_page(html): # 处理页面内容,如抓取数据或者存储数据 pass def extract_links(html, current_depth): # 使用 beautifulsoup 等工具提取页面中的链接 soup = beautifulsoup(html, 'html.parser') links = soup.find_all('a', href=true) for link in links: new_url = link['href'] if new_url.startswith('http') and new_url not in visited_urls: crawl(new_url, current_depth + 1) crawl(base_url)
总结
19.在设计爬虫系统时,如何处理和避免被目标网站识别并阻止的风险?请分享你的反反爬虫策略或者技巧。
反反爬虫策略和技巧
-
模拟人类行为:
- 方法:使爬虫行为更像人类浏览器访问网站,降低被识别为爬虫的风险。
- 实现:
- 设置随机的用户代理:使用不同的用户代理,模拟不同的浏览器和设备。
- 随机化请求间隔:不要以固定模式请求页面,随机化请求间隔可以模拟人类的浏览行为。
- 模拟点击和滚动:对于需要触发动态加载内容的页面,模拟点击和滚动来获取完整的页面内容。
示例代码(随机化请求间隔和设置随机用户代理):
import requests import random import time user_agents = [ "mozilla/5.0 (windows nt 10.0; win64; x64) applewebkit/537.36 (khtml, like gecko) chrome/91.0.4472.124 safari/537.36", "mozilla/5.0 (windows nt 10.0; win64; x64) applewebkit/537.36 (khtml, like gecko) chrome/91.0.4472.114 safari/537.36", "mozilla/5.0 (macintosh; intel mac os x 10_15_7) applewebkit/537.36 (khtml, like gecko) chrome/91.0.4472.114 safari/537.36", "mozilla/5.0 (windows nt 10.0; win64; x64) applewebkit/537.36 (khtml, like gecko) edge/91.0.864.64 safari/537.36", "mozilla/5.0 (windows nt 10.0; win64; x64; rv:89.0) gecko/20100101 firefox/89.0", ] def fetch_data(url): headers = { 'user-agent': random.choice(user_agents) } # 设置随机化请求间隔 time.sleep(random.uniform(1, 3)) response = requests.get(url, headers=headers) return response.text url = 'http://example.com' data = fetch_data(url) print(data) -
处理验证码和动态内容:
- 方法:对于需要验证码或者动态内容加载的网站,使用 ocr 技术处理验证码或者模拟交互操作获取动态内容。
- 实现:
- 集成验证码识别服务:使用第三方验证码识别服务或者自行实现 ocr 技术识别验证码。
- 模拟用户交互:使用工具(如 selenium)模拟用户输入和操作,获取动态生成的内容。
示例代码(使用 selenium 模拟点击和获取动态内容):
from selenium import webdriver from selenium.webdriver.common.by import by from selenium.webdriver.support.ui import webdriverwait from selenium.webdriver.support import expected_conditions as ec import time # 设置 chrome 驱动程序路径 driver_path = '/path/to/chromedriver' def fetch_dynamic_content(url): # 启动 chrome 浏览器 options = webdriver.chromeoptions() options.add_argument('--headless') # 无头模式运行浏览器 driver = webdriver.chrome(executable_path=driver_path, options=options) try: # 打开页面 driver.get(url) # 等待动态内容加载完成 webdriverwait(driver, 10).until(ec.presence_of_element_located((by.css_selector, 'dynamic-element-selector'))) # 获取动态内容 dynamic_content = driver.page_source return dynamic_content finally: driver.quit() url = 'http://example.com' dynamic_content = fetch_dynamic_content(url) print(dynamic_content) -
使用代理ip和分布式爬取:
- 方法:通过使用代理ip和分布式爬取,避免单一 ip 频繁访问同一网站被封禁或者识别为爬虫。
- 实现:
- 代理ip池:使用代理ip服务提供商获取多个代理ip,定期更换和测试代理ip的可用性。
- 分布式爬取架构:使用多台服务器或者多个进程并发爬取目标网站,分散访问压力。
示例代码(使用代理ip和 requests 库实现):
import requests def fetch_data_with_proxy(url, proxy): proxies = { 'http': f'http://{proxy}', 'https': f'https://{proxy}' } try: response = requests.get(url, proxies=proxies, timeout=10) if response.status_code == 200: return response.text else: print(f"failed to fetch data from {url}, status code: {response.status_code}") except exception as e: print(f"failed to fetch data from {url}: {str(e)}") url = 'http://example.com' proxy = '123.456.789.10:8888' # 替换为有效的代理ip data = fetch_data_with_proxy(url, proxy) print(data)
总结
20. 在处理反爬虫策略时,你如何评估和选择合适的代理ip服务?请分享你的选择标准和实际操作经验。
如何评估和选择合适的代理ip服务?
-
选择标准:
-
实际操作经验:
-
使用方式:
总结




发表评论