在我们讲解这个案例前,我们先来了解/预热一下sql server的两个概念:键查找(key lookup)和rid查找(rid lookup),通常,当查询优化器使用非聚集索引进行查找时,如果所选择的列或查询条件中的列只部分包含在使用的非聚集索引和聚集索引中时,就需要一个查找(lookup)来检索其他字段来满足请求。对一个有聚簇索引的表来说是一个键查找(key lookup),对一个堆表来说是一个rid查找(rid lookup),这种查找即是——书签查找(bookmark lookup)。在其他数据库概念中,可能又叫回表查询之类的概念。
那么我们先来构造案例所需的测试环境。下面测试环境为sql server 2014。
select * into test from sys.objects create clustered index pk_test on test(object_id, name,create_date) create index ix_test_n1 on test(parent_object_id, type) update statistics test with fullscan;
如上所示,表test在字段object_id, name,create_date建立了聚集索引,然后下面这种查询语句,你查看其实际执行计划
select object_id, name,create_date,parent_object_id, type from test where parent_object_id=2255213;
你会发现,sql server优化器走索引ix_test_n1查找就返回了所有数据。没有书签查找(回表查询),那么这是为什么呢?朋友这样问我的时候,我还真没有想明白。难道索引ix_test_n1中也会存储object_id, name,create_date的值? 当然你构造其它的案例时,有可能是索引ix_test_n1扫描就返回了数据。不会发生书签查找。
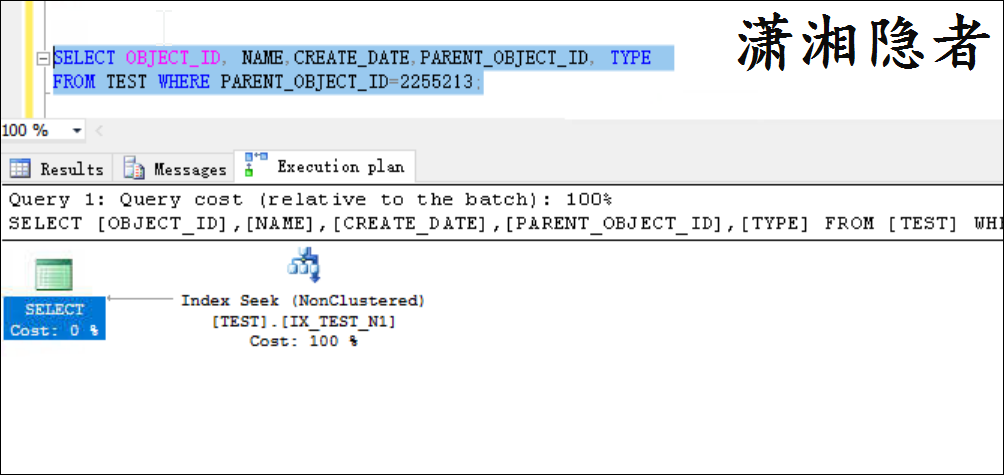
后面才想明白,非聚集索引中的索引行指向数据行的指针称为行定位器。 行定位器的结构取决于数据页是存储在堆中还是聚集表中。 对于堆,行定位器是指向行的指针。 对于聚集表,行定位器是聚集索引键。这是不是有点眼熟,类似于mysql innodb的二级索引(secondary index)会自动补齐主键,将主键列追加到二级索引列后面。所以执行计划就走索引ix_test_n1查找就能返回数据了。根本不需要书签查找(回表查询)。如果查询语句多一个字段或者是select *的话,你就会看到书签查找了。如下所示
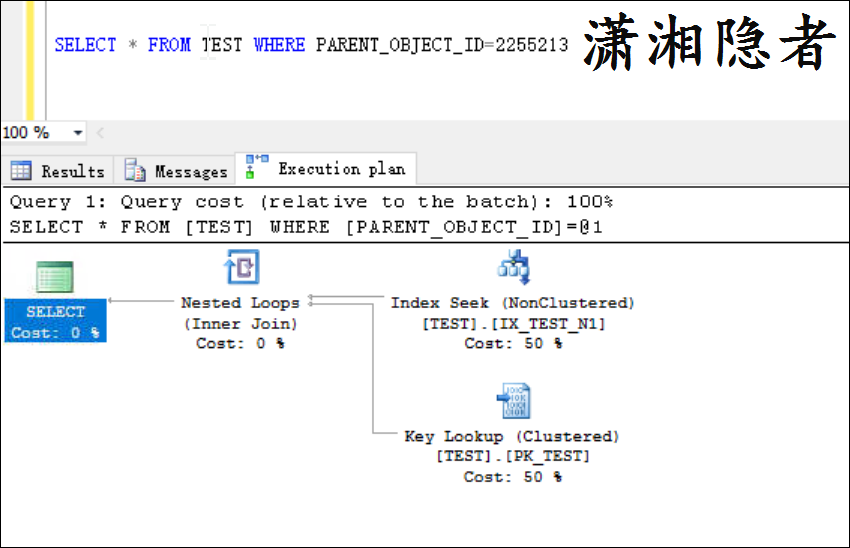
到此这篇关于sql server索引查找/扫描没有出现key lookup的案例浅析的文章就介绍到这了,更多相关sql server索引查找/扫描内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论