myabtisplus之高级查询
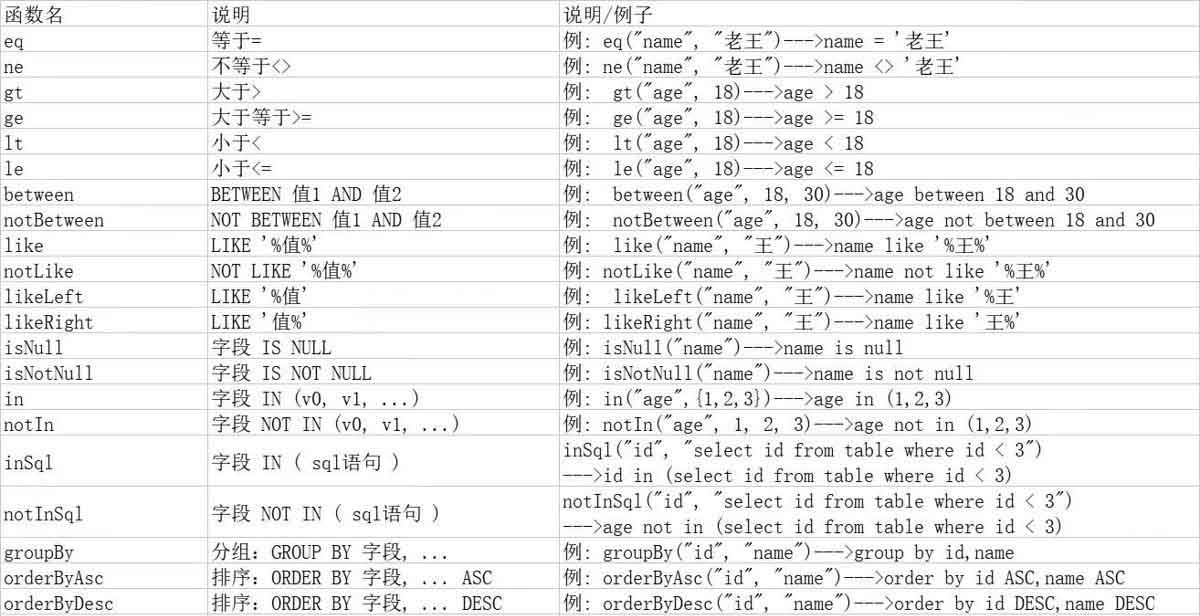

| 函数名 | 说明 | 例子 |
|---|---|---|
| eq | 等于 = | 例:eq(“name”,“张三”) :name = ‘张三’ |
| ne | 不等于<> | 例: eq(“name”,“老王”)—>name = ‘老王’ |
| gt | 大于> | 例:gt(“age”,18)—>age > 18 |
| ge | 大于等于>= | 例:ge(“age”,18)—>age >= 18 |
| lt | 小于< | 例:lt(“age”,18)—>age < 18 |
| le | 小于<= | 例:le(“age”,18)—>age <= 18 |
| between | between值1 and值2 | 例:between(“age”,18,30)—>age between 18 and 30 |
| notbetween | not between值1 and值2 | 例: notbetween(“age”,18,30)—>age not between 18 and 30 |
| like | like ‘%值%’ | 例: like(“name”,“王”)—–>name like '%王%’ |
| notlike | not like ‘%值%’ | 例: notlike (“name”,“王”)—>name not like '%王%’ |
| likeleft | like '%值’ | 例:likeleft (“name”,“王”)—–>name like '%王’ |
| likeright | like’值%’ | 例: likeright(“name”,“王”)—>name like ‘王%’ |
| isnull | 字段is null | 例: isnul1 (“name”)—>name is null |
| isnotnull | 字段is not null | 例: isnotnull(“name”)—>name is not null |
| in | 字段in (v0, v1,…) | 例: in(“age”,{1,2,3} )—–>age in (1,2,3) |
| notin | 字段not in (v0, v1,…) | 例: notin(“age”,1,2,3)—>age not in (1,2,3) |
| insql | 字段in ( sql语句) | insql(“id”, “select id from table where id < 3”) —–>id in (select id from table where id < 3) |
| notinsql | 字段not in ( sql语句) | notinsql(“id”, “select id from table where id < 3”) —–>age not in (select id from table where id < 3) |
| groupby | 分组:group by 字段,… | 例: groupby(“id”, “name”)—>group by id, name |
| orderbyasc | 排序:order by字段,… asc | 例: orderbyasc(“id”, “name”)—>order by id asc, name asc |
| orderbydesc | 排序:order by 字段,…desc | 例: orderbydesc(“id”, “name”)—>order by id desc, name desc |
| orderby | 排序:order by字段,… | 例: orderby(true,true,“id”,“name”)—–>order by id asc, name asc |
| having | having ( sql语句) | having(“sum(age) >{0}”,11)—>having sum(age) > 11 |
| or | 拼接or | 主动调用or表示紧接着下一个方法不是用and连接!(不调用or则默认为使用and连接)例:eq(“id”,1).or().eq(“name”,“老王”)—>id = 1 or name = '老王 |
| and | and嵌套 | 例: and(i -> i.eq(“name”,“李白”).ne(“status”,“活着”))—>and (name ='李白’ and status ’活着’) |
| apply | 拼接sql | 该方法可用于数据库函数动态入参的params对应前面sqlhaving内部的{index}部分.这样是不会有sql注入风险的,反之会有! 例: apply(“date_format(datecolumn, ‘%y一%m-%d’) ={0}”, “2023-08-08”)—>date_format(datecolumn,’%y一%m-%d’) = ‘2023-08-08’") |
| last | 无视优化规则直接拼接到sql 的最后 | 无视优化规则直接拼接到sql 的最后只能调用一次,多次调用以最后一次为准有sql注入的风险,请谨慎使用例: last(“limit 1”) |
| exists | 拼接exists ( sql语句) | exists (select id from table where age = 1) 例: notexists(“select id from table where age = 1”) —>exists (select id from table where age = 1) |
| notexists | 拼接not exists ( sql语句) | 例: notexists(“select id from table where age = 1”)—–>not exists (select id from table where age = 1) |
| nested | 正常嵌套不带and或者 or | 正常嵌套不带and或者or例: nested(i -> i.eq(“name”,“李白”).ne(“status”,“高兴”))—>(name = '李白’and status 高兴’) |
一、列投影(select)
只想看到查询到的数据中部分字段数据。
例: 查询所有学生信息,返回name age 列。
querywrapper<user> wrapper = new querywrapper<>();
1.wrapper.select("name","age");//---------->查询列集合,将查询数据作为两例。
2.wrapper.select("name,age");//---------->查询列集合,将查询数据作为一例。
usermapper.selectlist(wrapper)
二、排序与分组
1.1、排序(orderbyasc/orderbydesc)
orderbyasc: 正序排序
等价sql: select ..from table order by 字段, ... asc
orderbydesc :倒序排序
wrapper方法:
orderbyasc(r... columns)
orderbyasc(boolean condition, r... columns)
效果:
orderbyasc("id", "name")--->order by id asc,name asc
列:查询所有员工信息按age正序排, 如果age一样, 按id正序排
@test
public void test0(){
querywrapper<employee> wrapper = new querywrapper<>();
wrapper.orderbyasc("age", "id");
employeemapper.selectlist(wrapper);
}
//对应sql语句:
select id,name,password,email,age,admin,dept_id from employee order by age asc,id asc
orderbydesc 跟 orderbyasc用法一样, 不过是倒序排
1.2、定制排序(orderby)
orderby:定制排序
等价sql: select ..from table order by 字段,
//参数1:布尔表达式:控制是否进行排序操作
//参数2:控制是不是正序
orderby(boolean condition, boolean isasc, r... columns)
排序:order by 字段, ...
&效果:
orderby(true, true, "id", "name")--->order by id asc,name asc
例:查询所有员工信息按age正序排, 如果age一样, 按id正序排
@test
public void test1(){
querywrapper<employee> wrapper = new querywrapper<>();
//apper.orderbyasc("age", "id");
//等价于:
wrapper.orderby(true, true, "age", "id");
employeemapper.selectlist(wrapper);
}
//sql语句
select id,name,password,email,age,admin,dept_id from employee order by age asc,id asc
列:查询所有员工信息按age正序排, 如果age一样, 按id倒序排
@test
public void test2(){
querywrapper<employee> wrapper = new querywrapper<>();
wrapper.orderbyasc("age");
wrapper.orderbydesc("id");
employeemapper.selectlist(wrapper);
}
//对应sql语句
select id,name,password,email,age,admin,dept_id from employee order by age asc,id desc
三、分组查询(groupby)
方法:
(1):groupby : 分组:group by 字段, ...
(2):groupby(r... columns)
(3):groupby(boolean condition, r... columns)
&效果:
groupby("id", "name")--->group by id,name
例: 以部门id进行分组查询,查每个部门员工个数
@test
public void test3(){
querywrapper<employee> wrapper = new querywrapper<>();
wrapper.groupby("dept_id");
wrapper.select("dept_id", "count(id) count");
employeemapper.selectmaps(wrapper);
}
//对应sql语句
select dept_id,count(id) count from employee group by dept_id
四、过滤条件(having)
方法:
(1): having : having ( sql语句 )
(2): having(string sqlhaving, object... params)
//参数1:布尔表达式:控制是否进行过滤操作
//参数2:以哪个字段为过滤
//参数3:以哪个条件作为过滤条件
(3): having(boolean condition, string sqlhaving, object... params)
例: having("sum(age) > 10")--->having sum(age) > 10
例: having("sum(age) > {0}", 11)--->having sum(age) > 11
需求: 以部门id进行分组查询,查每个部门员工个数, 将大于3人的部门过滤出来
@test
public void test5(){
querywrapper<employee> wrapper = new querywrapper<>();
wrapper.groupby("dept_id")
.select("dept_id", "count(id) count")
//.having("count > {0}", 3)
.having("count >3");
employeemapper.selectmaps(wrapper);
}
//对应sql语句:
select dept_id,count(id) count from employee group by dept_id having count >3
五、比较运算符
1. 等于 不等于
1):alleq:全能匹配;即:所有条件都得等;
例 查询 name='张三‘ age='18‘的学生信息
步骤:
(1): map(string ,object)mp = new hashmap();
mp.put("name","张三");
mp.put("age","18");
(2): querywrapper<employee> wrapper = new querywrapper<>();
wrapper.alleq(mp);
(3):usermapper.selelist(wrapper);
2): eq:当个参数判断是否相等。---------->对应sql中 “等于=”
列:eq("name","zhnagsan")----------->name="zhangsane"
3): ne: 不等于---------->对应sql中 “不等于< >”
列:ne("name","张三")------------->name< >'张三嗯'
2.大于 等于 小于
(1):get :大于 >
列:get("age",18)----------->age>18
(2):ge :大于等于 >=
列:ge("age",18)----------->age>=18
(3):lt :小于 <
列:lt("age",18)----------->age<18
(4):le :小于等于 <=
列:le("age",18)----------->age<=18
六、批量插入或更新数据
方式一:mybatis-plus 的saveorupdatebatch方法
继承basemapper即可,泛型使用当前要操作类
@mapper
public interface hhchaincustomerinfomapper extends basemapper<hhchaincustomerinfo> {
/**
* 使用mybatis-plus方式调用saveorupdatebatch不需要写这个接口
boolean saveorupdatebatch(@param("entities") collection<hhchaincustomerinfo> hhchaincustomerinfos);
*/
}
service 层继承 iservice即可,泛型使用当前要操作类
/**
* 链路客户信息service接口
*
* @author js
* @date 2023-09-10
*/
public interface ihhchaincustomerinfoservice extends iservice<hhchaincustomerinfo> {
}
service 实现类 层继承 serviceimpl即可,泛型使用当前要操作类
@service
public class hhchaincustomerinfoserviceimpl extends serviceimpl<hhchaincustomerinfomapper, hhchaincustomerinfo> implements ihhchaincustomerinfoservice {
/*@override
public boolean saveorupdatebatch(collection<hhchaincustomerinfo> entitylist) {
return hhchaincustomerinfomapper.saveorupdatebatch(entitylist);
}*/
}
七、(单表)分页+高级查询
步骤
第一步:定义一个queryobject类:
@setter
@getter
public class queryobject {
private int currentpage=1;
private int pagesize=1;
}
第二步:定义一个queryobject类:
@setter
@getter
public class employeequery extends queryobject{
}
第三步:在启动类中配置分页插件:
步骤:配置分页插件
//分页
@bean
public mybatisplusinterceptor mybatisplusinterceptor() {
mybatisplusinterceptor interceptor = new mybatisplusinterceptor();
paginationinnerinterceptor paginationinnerinterceptor = new paginationinnerinterceptor(dbtype.mysql);
paginationinnerinterceptor.setoverflow(true); //合理化
interceptor.addinnerinterceptor(paginationinnerinterceptor);
return interceptor;
}
第四步:在service接口层中定义分页方法:
public interface iemployeeservice extends iservice<employee>{//----------->泛型里为实体类
//------->必须继承 iservice<t>
//分页方法:
public ipage<employee> query(employeequery qo);
}
第五步:在service接口实现类中实现分页方法:
public class employeeserviceimpl extends service<employeemapper,employee> implements iemployeeservice{
//------------>service<employeemapper,employee>:实体类mapper接口;实体类
//------->必须继承 service<tmapper,t>
@override
public ipage<employee> query(employeequery qo) {
ipage<employee> page = new page<>(qo.getcurrentpage(), qo.getpagesize()); //设置分页信息
querywrapper<employee> wrapper = wrappers.<employee>query(); //拼接条件
//有条件约束写在这里:
return super.page(page,wrapper);
}
}
列:查询第2页员工信息, 每页显示3条, 按id排序
@test
public void testpage(){
employeequery qo = new employeequery();
qo.setpagesize(3);
qo.setcurrentpage(2);
ipage<employee> page = employeeservice.query(qo);
system.out.println("当前页:" + page.getcurrent());
system.out.println("总页数:" + page.getpages());
system.out.println("每页显示条数:" + page.getsize());
system.out.println("总记录数:" + page.gettotal());
system.out.println("当前页显示记录:" + page.getrecords());
}
//sql语句
select id,name,password,email,age,admin,dept_id from employee where (name like ?) limit ?,?
八、联表分页查询+条件查询
对于一对一,一对多,多对一,还是两表之间通过主外键关联查询,都可以;
总结:
- 第一步:不管是那种情况,首先将响应给前端的数据封装成一个类并继承(pagequery)
- 第二步:按以下步骤做
步骤:
1.编写:请求dto层:
import lombok.data;
@data
public class pagequery {
/**
* 当前页
*/
private integer curpage;
/**
* 页大小
*/
private integer pagesize;
}
2.编写封装响应给前端数据to
import com.baomidou.mybatisplus.annotation.tableid;
import com.zhecre.jx.business.model.index.request.pagequery;
import lombok.data;
import java.util.date;
@data
public class compensateinfo extends pagequery {
/**
* 方案状态(1:未提交|2:已提交|3:已驳回|4:已审核)
*/
private string status;
/**
* 方案编号
*/
@tableid
private string caseid;
/**
* 方案名称
*/
private string casename;
/**
* 医院名称
*/
private string hosname;
private string casetype;
private string remark;
private date commitdate;
private string type;
}
3.定义controller层:
import com.baomidou.mybatisplus.core.metadata.ipage;
import com.zhecre.jx.business.model.index.response.compensateinfo;
import com.zhecre.jx.business.service.cases.icompensateinfoservice;
import lombok.requiredargsconstructor;
import org.springframework.beans.factory.annotation.autowired;
import org.springframework.web.bind.annotation.*;
@restcontroller
@requiredargsconstructor
@requestmapping("/compensation")
public class compensationschemescontroller {
@autowired
private final icompensateinfoservice compensateinfoservice;
@getmapping("/index/query")
public ipage<compensateinfo> compensatepage( compensateinfo info){
//调用service层
ipage<compensateinfo> query = compensateinfoservice.query(info,info.getcasename(),info.getcasetype());
return query;
}
}
4.编写service 层:
public interface icompensateinfoservice extends iservice<compensateinfo> {
//分页方法:
ipage<compensateinfo> query(compensateinfo info, string casename, string casetype);
}
5.实现service层:
import com.baomidou.mybatisplus.core.metadata.ipage;
import com.baomidou.mybatisplus.extension.plugins.pagination.page;
import com.baomidou.mybatisplus.extension.service.impl.serviceimpl;
import com.zhecre.jx.business.mapper.cases.compensateinfomapper;
import com.zhecre.jx.business.model.index.response.compensateinfo;
import com.zhecre.jx.business.service.cases.icompensateinfoservice;
import org.springframework.beans.factory.annotation.autowired;
import org.springframework.stereotype.service;
@service
public class compensateinfoserviceimpl extends serviceimpl<compensateinfomapper, compensateinfo> implements icompensateinfoservice {
@autowired
private compensateinfomapper compensateinfomapper;
@override
public ipage<compensateinfo> query(compensateinfo qo, string casename, string casetype) {
page<compensateinfo> page = new page<>(qo.getcurpage(), qo.getpagesize());//调用mybatisplus分页插件
ipage<compensateinfo> queryvopage = compensateinfomapper.findbypage(page, qo,casename,casetype);//定义分页方法
return queryvopage;
}
}
6.定义mapper层:
public interface compensateinfomapper extends basemapper<compensateinfo> {
//自定义分页方法
ipage<compensateinfo> findbypage(page<compensateinfo> page, compensateinfo qo,
@param("casename") string casename,@param("casetype") string casetype);//这是条件查询参数
}
7.编写mapper.xml:
<?xml version="1.0" encoding="utf-8"?>
<!doctype mapper
public "-//mybatis.org//dtd mapper 3.0//en"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.zhecre.jx.business.mapper.cases.compensateinfomapper">
//将查寻结果对象字段属性和数据库字段对应
<resultmap id="compensateinfomapper" type="com.zhecre.jx.business.model.index.response.compensateinfo">
<id property="caseid" column="caseid"></id>
<result property="status" column="status"></result>
<result property="casename" column="casename"></result>
<result property="casetype" column="casetype"></result>
<result property="remark" column="remark"></result>
<result property="hosname" column="hosname"></result>
<result property="commitdate" column="commitdate"></result>
<result property="type" column="type"></result>
</resultmap>
//查询语句:得到结果集
<select id="findbypage" parametertype="com.zhecre.jx.business.model.index.response.compensateinfo" resultmap="compensateinfomapper">
select
c.status,
c.caseid,
c.casename,
c.casetype,
p.hosname,
c.remark,
c.commitdate,
c.type
from
pas_case c,
pas_case_hospital p
<where>
and c.caseid = p.caseid
<if test="casename !=null and casename != ''">
and c.casename = #{casename}//传入的条件查数;如果传入的参数是对象的话要取对象中的某个属性,这个地方参数直接写成属性名即可,但是对象所属的类 必须提供getter方法;如果是普通变量字段,条件直接写成传入得字段
</if>
</if>
<if test="casetype !=null and casetype != ''">
and c.casetype = #{casetype}
</if>
</where>
</select>
</mapper>九、事务操作
在service层实现类上面加一个@thansaction注解。
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。




发表评论