随着业务的不断发展和系统的日益复杂,传统的单一数据库架构往往难以满足高并发、海量数据以及高可用的需求。为了应对这些挑战,分布式数据库架构逐渐成为主流。而在分布式数据库架构中,如何灵活高效地切换数据源,成为了一个关键问题。
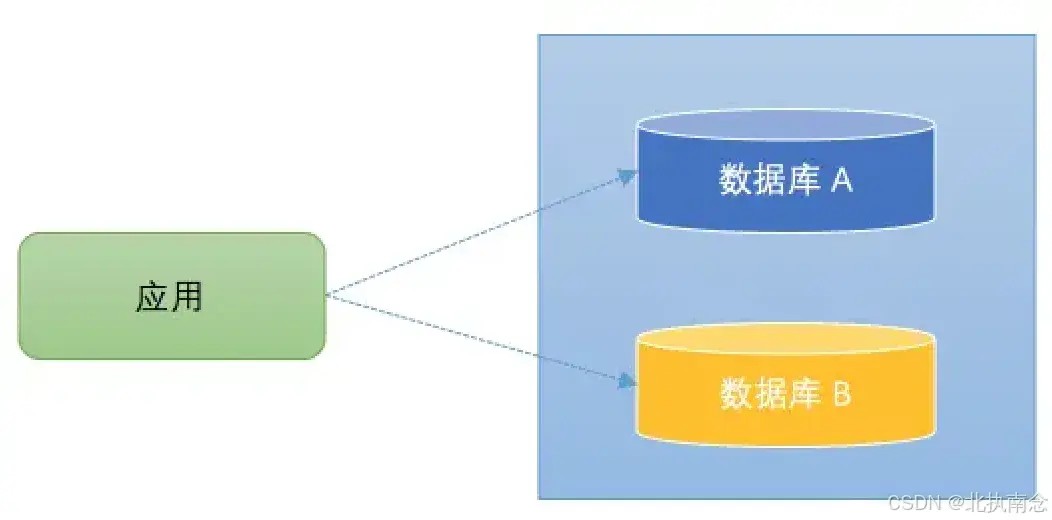
这个问题在多租户架构、读写分离、数据库分片等场景中尤为重要。通过动态数据源切换,我们能够根据不同的业务需求、请求来源或者负载情况动态选择不同的数据源,从而提升系统的性能、可扩展性和高可用性。
基础知识
spring boot 中实现动态数据源切换 之前,我们需要先了解一些相关的基础知识,这些知识将帮助我们理解动态数据源切换的概念和实施方法。
1. 什么是数据源?
数据源(datasource)是一个接口,它为 java 程序提供数据库连接。
它通常由数据库连接池实现,比如 hikaricp、c3p0 或 dbcp 等,数据源的作用就是帮助应用程序与数据库建立连接并管理这些连接。
2. 动态数据源切换的概念
动态数据源切换的核心思想是,根据不同的业务场景、请求类型、用户身份或者负载情况,动态地切换到不同的数据源。这种技术在多租户架构、读写分离、数据库分片等场景中尤为重要。
- 多租户架构:每个租户可以使用独立的数据库,或者共享一个数据库中的表,但不同的租户数据是隔离的。
- 读写分离:在高并发的系统中,通常采用主从数据库架构,主库用于写操作,从库用于读操作。动态切换数据源可以根据请求的类型(读/写)自动选择合适的数据源。
- 数据库分片:当单个数据库承载的数据量过大时,可以将数据分散到多个数据库(分片),根据请求的数据范围选择不同的数据库。
3. spring boot 中的默认数据源配置
在 spring boot 中,默认情况下,我们通过 application.properties 或 application.yml 文件配置数据源。spring boot 会自动根据这些配置创建一个单一的数据源对象,应用程序使用该数据源进行数据库操作。
例如,常见的单数据源配置如下:
spring.datasource.url=jdbc:mysql://localhost:3306/mydb spring.datasource.username=root spring.datasource.password=password spring.datasource.driver-class-name=com.mysql.cj.jdbc.driver
4. 动态数据源的挑战
在一些场景下,我们可能需要基于某些条件切换数据源,比如:
- ● 根据用户身份切换到不同的数据库。
- ● 根据请求的类型(如读请求或写请求)切换到不同的数据源。
- 在高并发情况下,动态地根据负载选择数据库。
在这种情况下,动态数据源切换将面临如下挑战:
- ● 事务的隔离性:在切换数据源时,必须确保事务的原子性和一致性,避免因切换数据源导致事务出错或失败。
- ● 数据源的管理:随着数据源数量的增加,如何管理和切换多个数据源,确保高效和稳定的连接池管理,成为一个问题。
- ● 性能问题:频繁的切换数据源可能会导致性能瓶颈,因此需要优化数据源的切换策略,确保系统的高效性。
5. spring 中的数据源切换方式
在 spring 框架中,常见的数据源切换方式有两种:
- 基于动态代理的方式:通过 aop(面向切面编程)技术,结合 spring 的 abstractroutingdatasource 实现动态数据源切换。这种方法通过创建一个动态的代理类,根据业务逻辑动态决定当前使用的数据源。
- 基于注解的方式:通过自定义注解和 aop 切面结合,标识需要切换数据源的方法或类,在方法调用时动态切换数据源。
设计思路
设计 spring boot 中动态数据源切换 的思路时,需要结合应用场景和系统需求来选择合适的架构和技术。
1. 明确应用场景
首先,我们需要明确为什么要实现动态数据源切换。常见的场景包括:
- 多租户架构:每个租户可能使用不同的数据库,或者同一数据库中使用不同的 schema 进行隔离。
- 读写分离:将写操作指向主库,读操作指向从库,从而提高系统的并发处理能力。
- 数据库分片:数据量过大,单一数据库无法满足需求时,通过分片将数据分布到不同的数据库节点。
2. 选择数据源切换策略
根据不同的场景,数据源切换的策略也有所不同。通常有以下几种策略:
- 按请求类型切换:根据请求类型(如读请求或写请求)动态选择数据源。写操作使用主库,读操作使用从库。
- 按用户切换:根据当前用户的身份或租户信息,动态选择数据源。例如,多租户场景下,不同租户可能使用不同的数据库。
- 按业务逻辑切换:根据具体的业务逻辑来选择数据源。比如,特定业务流程可能需要访问某个特定的数据库。
3. 数据源管理
在设计动态数据源切换时,数据源的管理非常重要。需要解决以下问题:
- 连接池的管理:每个数据源都应该有独立的数据库连接池。可以使用 hikaricp 等数据库连接池来管理连接的生命周期和性能。
- 数据源的动态切换:实现动态切换数据源的核心是
abstractroutingdatasource。通过abstractroutingdatasource,可以在运行时根据某些条件动态选择数据源。 - 事务的一致性:在动态切换数据源时,需要确保事务的一致性。spring 提供了
@transactional注解来保证事务的一致性,但在多数据源环境下,必须确保事务管理能够跨多个数据源正确执行。
4. 动态数据源切换的实现方案
实现动态数据源切换可以通过以下步骤:
4.1 创建动态数据源路由
abstractroutingdatasource 是 spring 提供的一个抽象类,可以通过它实现数据源的动态路由。我们可以继承 abstractroutingdatasource,并重写 determinecurrentlookupkey() 方法,该方法用于获取当前应该使用的数据源的标识。基于该标识,系统可以在多个数据源之间进行切换。
public class dynamicdatasource extends abstractroutingdatasource {
@override
protected object determinecurrentlookupkey() {
return datasourcecontextholder.getdatasourcetype(); // 获取当前的数据源标识
}
}
4.2 数据源上下文管理
为了在运行时动态切换数据源,我们需要维护一个上下文来存储当前的数据库标识。通常,可以通过 threadlocal 来管理当前线程的数据库标识。可以使用 datasourcecontextholder 来进行数据源的切换。
public class datasourcecontextholder {
private static final threadlocal<string> contextholder = new threadlocal<>();
public static void setdatasourcetype(string datasourcetype) {
contextholder.set(datasourcetype);
}
public static string getdatasourcetype() {
return contextholder.get();
}
public static void cleardatasourcetype() {
contextholder.remove();
}
}
4.3 切换数据源
在具体的业务逻辑中,可以通过设置 datasourcecontextholder 来切换数据源。例如:
public class someservice {
public void somemethod() {
datasourcecontextholder.setdatasourcetype("master"); // 切换到主库
// 执行主库操作
}
public void anothermethod() {
datasourcecontextholder.setdatasourcetype("slave"); // 切换到从库
// 执行从库操作
}
}
4.4 配置多个数据源
在 application.yml 或 application.properties 配置文件中,可以配置多个数据源。spring boot 会自动为每个数据源生成一个 datasource bean。我们需要为每个数据源配置合适的连接池,并根据需要进行切换。
spring:
datasource:
master:
url: jdbc:mysql://localhost:3306/master
username: root
password: password
driver-class-name: com.mysql.cj.jdbc.driver
slave:
url: jdbc:mysql://localhost:3306/slave
username: root
password: password
driver-class-name: com.mysql.cj.jdbc.driver4.5 事务管理
在多数据源的情况下,事务的管理需要特别注意。如果使用的是 @transactional 注解,spring 会根据当前的数据源来处理事务。为保证事务一致性,可以使用 platformtransactionmanager 来管理不同数据源的事务。
5. 优雅的切换和性能优化
动态切换数据源的性能和稳定性是设计的关键。我们可以采取以下策略来优化性能:
- ●数据源的连接池管理:确保每个数据源都配置了合适的连接池,避免频繁创建和销毁连接。
- ●懒加载数据源:只有在需要的时候才初始化数据源,避免不必要的资源占用。
- ●数据源切换的粒度控制:避免频繁切换数据源,尽量减少切换的粒度,降低系统的开销。
6. 监控与日志
为了更好地管理动态数据源切换,我们需要加入监控和日志记录机制,跟踪哪些数据源被切换,当前的数据源是什么,以及执行的 sql 查询是什么。这有助于在问题出现时进行排查。
实现步骤
实现 spring boot 中动态数据源切换 的步骤涉及多个关键环节,包括数据源的配置、动态数据源的切换、事务管理等。
1. 添加依赖
首先,确保你的 spring boot 项目中已经引入了 spring data jpa 或 mybatis 等数据访问框架的依赖。然后,添加数据库连接池和 spring boot starter 数据源的依赖。
<dependency>
<groupid>org.springframework.boot</groupid>
<artifactid>spring-boot-starter-jdbc</artifactid>
</dependency>
<dependency>
<groupid>com.zaxxer</groupid>
<artifactid>hikaricp</artifactid>
</dependency>
<dependency>
<groupid>org.springframework.boot</groupid>
<artifactid>spring-boot-starter-data-jpa</artifactid>
</dependency>2. 配置多个数据源
在 application.yml 或 application.properties 中配置多个数据源。这里我们以主库和从库为例进行配置。
spring:
datasource:
master:
url: jdbc:mysql://localhost:3306/master
username: root
password: password
driver-class-name: com.mysql.cj.jdbc.driver
slave:
url: jdbc:mysql://localhost:3306/slave
username: root
password: password
driver-class-name: com.mysql.cj.jdbc.driver3. 创建动态数据源路由类
我们需要继承 abstractroutingdatasource 类来实现数据源的动态路由。在该类中,通过 determinecurrentlookupkey() 方法来决定当前使用哪个数据源。
import org.springframework.jdbc.datasource.lookup.abstractroutingdatasource;
public class dynamicdatasource extends abstractroutingdatasource {
@override
protected object determinecurrentlookupkey() {
return datasourcecontextholder.getdatasourcetype(); // 获取当前线程的数据源类型
}
}
4. 创建数据源上下文管理类
为了在不同的业务逻辑中切换数据源,我们需要创建一个上下文管理类,来管理当前线程的 datasource。可以使用 threadlocal 来存储当前线程的数据源标识。
public class datasourcecontextholder {
private static final threadlocal<string> contextholder = new threadlocal<>();
// 设置当前线程使用的数据源
public static void setdatasourcetype(string datasourcetype) {
contextholder.set(datasourcetype);
}
// 获取当前线程的数据源
public static string getdatasourcetype() {
return contextholder.get();
}
// 清除当前线程的数据源
public static void cleardatasourcetype() {
contextholder.remove();
}
}
5. 配置数据源的 bean
接下来,我们需要在 spring 配置类中注册多个数据源并设置动态数据源。在这个步骤中,动态数据源会根据上下文管理类返回的数据源类型来选择具体的数据源。
@configuration
@enabletransactionmanagement
public class datasourceconfig {
@bean
@primary
public datasource datasource() {
dynamicdatasource datasource = new dynamicdatasource();
// 配置主库和从库的数据源
datasource.settargetdatasources(getdatasources()); // 设置数据源
datasource.setdefaulttargetdatasource(masterdatasource()); // 设置默认数据源
return datasource;
}
// 主库的数据源
@bean
public datasource masterdatasource() {
hikaridatasource datasource = new hikaridatasource();
datasource.setjdbcurl("jdbc:mysql://localhost:3306/master");
datasource.setusername("root");
datasource.setpassword("password");
return datasource;
}
// 从库的数据源
@bean
public datasource slavedatasource() {
hikaridatasource datasource = new hikaridatasource();
datasource.setjdbcurl("jdbc:mysql://localhost:3306/slave");
datasource.setusername("root");
datasource.setpassword("password");
return datasource;
}
// 返回数据源的 map,key 是数据源标识(例如:主库或从库)
private map<object, object> getdatasources() {
map<object, object> datasources = new hashmap<>();
datasources.put("master", masterdatasource());
datasources.put("slave", slavedatasource());
return datasources;
}
}
6. 在业务逻辑中切换数据源
在业务方法中,我们可以通过调用 datasourcecontextholder.setdatasourcetype() 来切换数据源。这里假设我们要根据业务逻辑切换数据源,比如主库和从库的读写分离。
@service
public class someservice {
@transactional
public void writedata() {
// 切换到主库进行写操作
datasourcecontextholder.setdatasourcetype("master");
// 执行写操作
}
@transactional
public void readdata() {
// 切换到从库进行读操作
datasourcecontextholder.setdatasourcetype("slave");
// 执行读操作
}
}
7. 清理数据源上下文
在每次操作完成后,要确保清除当前线程的数据源标识,以避免影响后续的请求。
public class datasourceaspect {
@after("@annotation(org.springframework.transaction.annotation.transactional)")
public void cleardatasource() {
datasourcecontextholder.cleardatasourcetype();
}
}
8. 事务管理
在多数据源的情况下,事务管理需要特别小心。spring 提供的 @transactional 注解支持跨多个数据源进行事务管理,但需要确保不同数据源的事务管理器是独立的。通常,使用 platformtransactionmanager 来确保每个数据源的事务能够独立处理。
9. 测试与优化
完成以上步骤后,进行数据源切换的测试,确保数据源能够根据业务逻辑正确切换。在高并发场景下,还需要优化连接池的配置,避免连接池资源浪费。
切换策略
在 spring boot 中实现动态数据源切换时,切换策略是一个非常重要的环节。切换策略决定了何时以及如何从一个数据源切换到另一个数据源。
1. 读写分离策略
读写分离是最常见的动态数据源切换策略之一。主库用于写操作,从库用于读操作。数据源切换的策略通常基于操作类型:
- ● 写操作(insert/update/delete):所有写操作需要访问主库。
- ● 读操作(select):所有读操作可以访问从库。
在进行数据操作时,判断当前操作是读操作还是写操作,然后根据操作类型动态切换数据源。
@service
public class dataservice {
// 读操作
public void readdata() {
datasourcecontextholder.setdatasourcetype("slave"); // 切换到从库
// 执行读操作
}
// 写操作
public void writedata() {
datasourcecontextholder.setdatasourcetype("master"); // 切换到主库
// 执行写操作
}
}
2. 基于线程或上下文的切换策略
此策略适用于每个线程有不同的数据库访问需求,例如基于用户或请求的上下文来决定使用哪个数据源。使用 threadlocal 或 requestcontext 来存储当前请求的数据源信息,确保每个请求可以独立切换数据源。通过上下文保存当前请求的数据源,常见的做法是使用 threadlocal 来存储每个线程的数据源信息。
public class datasourcecontextholder {
private static final threadlocal<string> contextholder = new threadlocal<>();
public static void setdatasourcetype(string datasourcetype) {
contextholder.set(datasourcetype);
}
public static string getdatasourcetype() {
return contextholder.get();
}
public static void cleardatasourcetype() {
contextholder.remove();
}
}
在请求中根据需要切换数据源:
public void processrequest(string datasourcetype) {
datasourcecontextholder.setdatasourcetype(datasourcetype);
// 执行数据库操作
}
3. 基于注解的切换策略
基于注解的策略允许在方法或类上直接使用注解来指定数据源,从而简化代码逻辑。这种方式可以更加灵活地在不同的服务方法中指定数据源,通常是使用自定义注解来标记需要使用的具体数据源。创建一个自定义注解,例如 @targetdatasource,在方法级别使用该注解来切换数据源。
@target(elementtype.method)
@retention(retentionpolicy.runtime)
public @interface targetdatasource {
string value();
}
使用该注解来标记需要切换数据源的方法:
@service
public class someservice {
@targetdatasource("master")
public void writedata() {
// 执行写操作
}
@targetdatasource("slave")
public void readdata() {
// 执行读操作
}
}
创建一个切面(aspect)来拦截带有 @targetdatasource 注解的方法,并动态切换数据源:
@aspect
@component
public class datasourceaspect {
@around("@annotation(targetdatasource)")
public object switchdatasource(proceedingjoinpoint point, targetdatasource targetdatasource) throws throwable {
// 切换数据源
datasourcecontextholder.setdatasourcetype(targetdatasource.value());
try {
return point.proceed();
} finally {
// 切换回默认数据源
datasourcecontextholder.cleardatasourcetype();
}
}
}
4. 基于请求类型的切换策略
在某些场景下,切换策略可以基于请求类型进行判断,例如区分 api 接口、用户身份或请求的 uri 等。通过拦截请求的 url 或参数来确定使用哪个数据源。可以使用 spring 的 handlerinterceptor 或自定义的过滤器来拦截请求并根据请求类型进行数据源切换。
@component
public class requestinterceptor implements handlerinterceptor {
@override
public boolean prehandle(httpservletrequest request, httpservletresponse response, object handler) throws exception {
string path = request.getrequesturi();
if (path.contains("/admin")) {
// 切换到主库
datasourcecontextholder.setdatasourcetype("master");
} else {
// 切换到从库
datasourcecontextholder.setdatasourcetype("slave");
}
return true;
}
@override
public void aftercompletion(httpservletrequest request, httpservletresponse response, object handler, exception ex) throws exception {
// 清理数据源
datasourcecontextholder.cleardatasourcetype();
}
}
5. 基于事务的切换策略
在某些复杂场景下,可能需要通过事务来控制数据源的切换,确保同一个事务中的多个操作使用相同的数据源。spring 提供的 @transactional 注解可以帮助实现事务管理,在事务中进行数据源的切换。在方法上使用 @transactional 注解进行事务管理,并在方法内切换数据源。
@transactional
public void processtransaction() {
datasourcecontextholder.setdatasourcetype("master");
// 执行事务相关操作
}
6. 基于业务类型的切换策略
有时候业务需求决定了数据源的选择。例如,某些业务模块专门使用主库,另一些业务模块则专门使用从库。通过业务模块类型来决定数据源切换。根据业务模块的类型来动态切换数据源,常见的是通过方法参数或业务配置来决定。
public void processbusinessrequest(string businesstype) {
if ("financial".equals(businesstype)) {
datasourcecontextholder.setdatasourcetype("master");
} else {
datasourcecontextholder.setdatasourcetype("slave");
}
// 执行业务操作
}
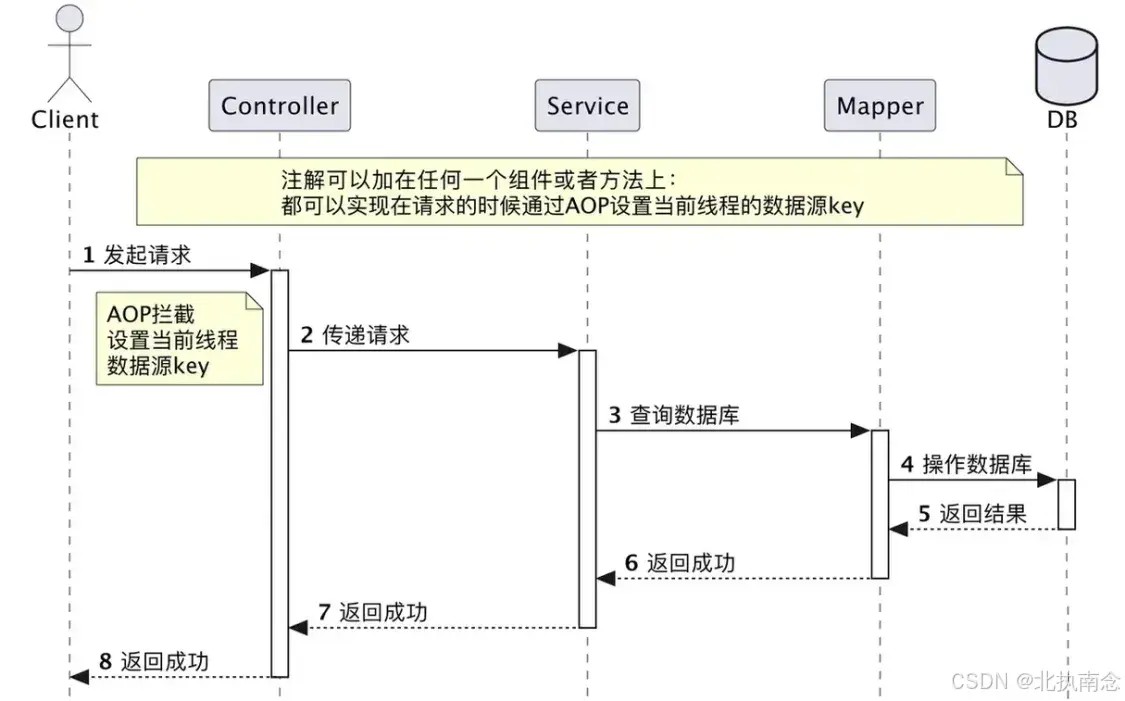
aop实现数据源切换
使用 aop(面向切面编程)来实现数据源切换是一种非常常见和优雅的做法。aop 允许我们在不修改业务代码的情况下,动态地切换数据源。通过 aop,我们可以在方法执行前或执行后切换数据源,依据方法的特性(如读写操作或注解)来决定使用哪个数据源。
1. 概述
aop 通过切面(aspect)来拦截方法的调用,在方法执行前后进行一些操作。在实现动态数据源切换时,通常会基于以下几个要素进行切换:
- 业务逻辑类型(如读或写)
- 自定义注解
- 方法执行的上下文(如请求、用户权限等)
2. 使用 aop 实现数据源切换的基本步骤
- 定义数据源上下文:使用 threadlocal 或类似方式在当前线程中保存当前的数据源。
- 创建自定义注解:用来标记需要切换数据源的方法或类。
- 编写切面:使用 aop 拦截器来拦截指定方法或类,并根据自定义注解来动态切换数据源。
- 切换数据源:在切面中根据业务逻辑切换数据源。
- 清理数据源:方法执行后清理当前数据源的上下文,避免影响到其他方法。
3. 实现步骤
1.定义数据源上下文
首先,我们需要定义一个 datasourcecontextholder 类来存储当前的数据源类型。可以使用 threadlocal 来确保每个线程都有独立的数据源。
public class datasourcecontextholder {
private static final threadlocal<string> contextholder = new threadlocal<>();
// 设置当前线程的数据源
public static void setdatasourcetype(string datasourcetype) {
contextholder.set(datasourcetype);
}
// 获取当前线程的数据源
public static string getdatasourcetype() {
return contextholder.get();
}
// 清除当前线程的数据源
public static void cleardatasourcetype() {
contextholder.remove();
}
}
2.定义自定义注解
我们定义一个注解 @targetdatasource,用于标记需要切换数据源的方法。
@target(elementtype.method)
@retention(retentionpolicy.runtime)
public @interface targetdatasource {
string value(); // 数据源名称
}
3.编写切面
使用 aop 来创建一个切面类,在方法执行前根据注解中的值来切换数据源。切面会拦截所有使用 @targetdatasource 注解的方法,并在执行时切换数据源。
@aspect
@component
public class datasourceaspect {
// 方法执行前切换数据源
@before("@annotation(targetdatasource)")
public void before(joinpoint point, targetdatasource targetdatasource) {
string datasource = targetdatasource.value();
datasourcecontextholder.setdatasourcetype(datasource); // 切换数据源
}
// 方法执行后清理数据源
@after("@annotation(targetdatasource)")
public void after(joinpoint point, targetdatasource targetdatasource) {
datasourcecontextholder.cleardatasourcetype(); // 清除数据源
}
}
4.使用注解切换数据源
在业务逻辑中,使用 @targetdatasource 注解标记需要切换数据源的方法。根据注解的值,切面会决定使用哪个数据源。
@service
public class myservice {
@targetdatasource("master")
public void writedata() {
// 执行写操作,使用主数据库
}
@targetdatasource("slave")
public void readdata() {
// 执行读操作,使用从数据库
}
}
5) 配置数据源
在 spring boot 配置文件中,配置多个数据源,并确保数据源切换的逻辑正常工作。
spring:
datasource:
master:
url: jdbc:mysql://localhost:3306/masterdb
username: root
password: password
slave:
url: jdbc:mysql://localhost:3306/slavedb
username: root
password: password异常与回滚处理
在使用动态数据源切换时,异常和回滚处理是非常重要的,因为在数据源切换的过程中可能会遇到各种异常,且如果没有适当的回滚机制,可能会导致数据不一致或其他严重问题。为了确保系统的可靠性和一致性,我们需要在处理数据源切换时合理地管理事务和异常。
1. 问题背景
在分布式或多数据源的应用场景中,通常需要根据不同的业务需求切换数据源。例如,在读写分离的场景中,读操作使用从数据库,而写操作使用主数据库。动态切换数据源时,涉及多个数据源的连接和事务管理,这使得异常处理和回滚更加复杂。如果在执行操作时遇到异常,没有适当的回滚处理,可能导致数据库中的数据不一致,甚至事务未能正确完成。
2. 异常处理的重要性
动态数据源切换和数据库操作中可能会发生不同类型的异常,这些异常可能来自于:
- 数据源连接失败
- 数据库查询或更新失败
- 事务提交失败
- 跨多个数据源的事务不一致问题
因此,我们必须采取合理的措施来捕获异常并回滚事务,保证系统的稳定性和一致性。
3. 异常和回滚处理的关键步骤
1) 事务管理
对于多数据源的应用,事务管理至关重要。在 spring 中,我们可以通过 @transactional 注解来管理事务,它能够确保操作的原子性和一致性。事务注解可以应用于服务层的方法,自动启动和提交事务。
@service
public class myservice {
@transactional
public void handletransaction() {
try {
// 切换到主数据源进行写操作
datasourceservice.writedata();
// 切换到从数据源进行读操作
datasourceservice.readdata();
} catch (exception e) {
// 异常处理和回滚
handleexception(e);
}
}
private void handleexception(exception e) {
// 记录异常信息
system.out.println("exception occurred: " + e.getmessage());
// 手动回滚事务(spring会自动回滚,但可以根据需要自定义)
throw new runtimeexception("transaction failed, performing rollback.");
}
}
在 @transactional 注解下,spring 会自动为所有参与的操作开启事务,如果有异常抛出,spring 会自动回滚事务。
2) 动态数据源切换时的回滚机制
当我们进行数据源切换时,必须保证在出现异常时能够正确地进行回滚。为了实现这一点,可以通过以下几种方式:
- 全局回滚:在多数据源环境中,使用一个全局事务管理器(如 atomikos、narayana 等)来管理多个数据源的事务。这样可以保证在一个数据源操作失败时,所有相关数据源的操作都会回滚,保证数据一致性。
- 本地回滚:如果只是切换了一个数据源,且没有涉及多个数据源的操作,spring 的
@transactional注解可以确保数据源相关的事务回滚。
3) 捕获与处理异常
在多数据源和多事务的环境下,异常处理尤为重要。以下是一些常见的异常处理策略:
- 捕获并记录异常:及时捕获异常并记录日志,以便追踪和调试问题。
- 事务回滚:在数据源切换时,如果发生异常,必须确保事务能够正确回滚,避免造成数据不一致。
- 根据异常类型判断回滚:使用 @transactional(rollbackfor = exception.class) 来控制特定异常时是否回滚事务。例如,可以根据业务需求,选择只针对某些特定异常进行回滚。
@transactional(rollbackfor = sqlexception.class)
public void somemethod() throws sqlexception {
// 数据库操作
}
4) 数据源恢复与错误重试机制
在动态数据源切换时,数据源的不可用或错误可能导致操作失败。为了提升系统的健壮性,可以加入数据源恢复或重试机制:
- 重试机制:在出现临时性异常时,可以尝试重新连接数据库。spring 提供了 @retryable 注解,可以帮助实现方法级别的重试逻辑。
- 数据源切换失败后的恢复机制:在数据源连接失败时,可以切换到备用数据源或进行自动恢复操作。
5) 跨数据库事务管理(分布式事务)
如果涉及多个数据源操作,并且需要保证跨多个数据库的事务一致性,可以使用分布式事务框架来管理。常用的分布式事务框架有:
- atomikos:一个开源的 java 分布式事务管理器,支持多数据源的事务管理。
- seata:一个现代化的分布式事务框架,支持高效地管理分布式事务。
通过这些框架,我们可以保证在多个数据库间操作时的一致性和可靠性。
4. 示例:使用 atomikos 进行分布式事务管理
@service
public class myservice {
@transactional
public void handletransaction() throws sqlexception {
try {
// 执行主数据库操作
datasourceservice.writedata();
// 执行从数据库操作
datasourceservice.readdata();
} catch (exception e) {
// 在分布式事务框架下,异常发生时自动回滚所有操作
system.out.println("exception occurred, performing rollback: " + e.getmessage());
throw new runtimeexception("transaction failed, performing rollback.");
}
}
}
通过 atomikos 等分布式事务框架,事务将在多个数据源之间自动进行协调,并保证跨数据源操作的一致性。
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。





发表评论