当前版本:
- python 3.8.4
1.lambda 的特点
lambda 是一种匿名函数的定义方式,也称为 lambda 函数。它不需要为函数命名,这使得在需要临时或一次性的函数功能时非常方便,通常只需要一行代码即可完成函数的定义。
为什么说它简洁呢,来看一组对比:
【传统函数】
def add_def(a, b):
return a + b
print(add_def(2, 3))【lambda函数】
add_lambda = lambda a, b: a + b print(add_lambda(2, 3))
使用传统函数使用2行代码,使用 lambda 函数仅需要1行代码,从代码量来讲确实简洁,如果代码量大,使用传统函数更容易阅读。所以一般只有在逻辑简单的情况使用 lambda 函数最合适。
2.lambda 的用法
2.1. 基本语法
lambda 由2部分组成(关键字:表达式)
lambda : 表达式
- 表达式:表示函数的逻辑操作,可以是任意有效的 python 表达式。
用一个最简单的表达式来举例:
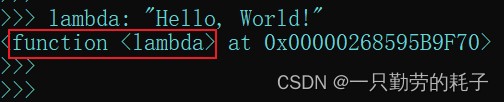
lambda: "hello, world!"
结果(匿名函数):
正常情况下,我们是通过 lambda 来定义一个匿名函数,比如:
func = lambda : 1+1
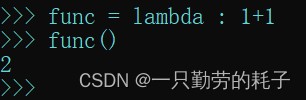
通过 lambda 来定义一个匿名函数(func),我们可以直接调用这个函数,也支持向函数传参。
2.2. 函数传参
匿名函数本身就是函数的一种,所以它也支持传参,语法如下:
lambda 参数 : 表达式
定义1个参数的例子
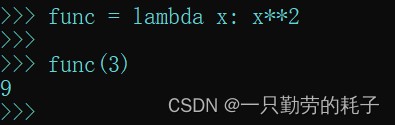
func = lambda x: x**2
我们定义一个名为func的匿名函数,调用时与正常情况下传参即可
func(3) # 传入一个参数
定义多个参数也是同样的方法
func = lambda x,y,z: x+y+z
调用函数时传入多个参数
func(3,4,5)

当然了,参数同样支持默认值
func = lambda x=10,y=20,z=30: x+y+z
调用时可以使用默认值或自定义的值,与传统函数没有区别
func() # 使用默认值 func(x=20) # 使用部分默认值 func(1,2,3) # 不使用默认值

也支持可变参数(语法:*参数名)
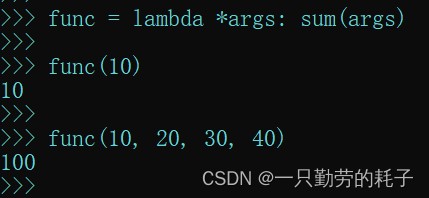
func = lambda *args: sum(args)
调用参数时没有数量限制
func(10) # 传入1个参数 func(10, 20, 30, 40) # 传入多个参数
2.3. 结合条件语句
lambda 支持与条件语句一起使用,语法如下:
lambda 参数 : 条件语句
比如简单的三目运算:
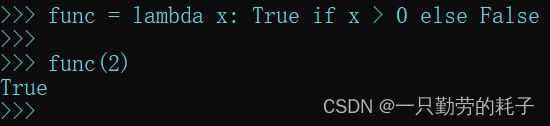
func = lambda x: true if x > 0 else false
通过传入的参数判断是否大于0,如果大于0返回true,否则返回false
func(2) # 传入一个大于0的参数
多条件可以使用多个 if
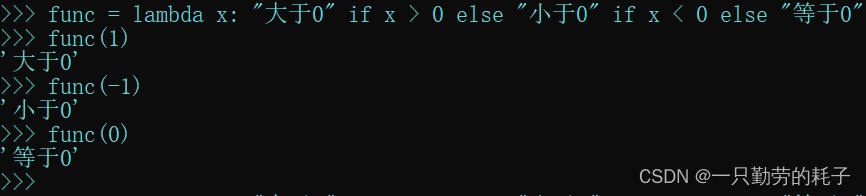
func = lambda x: "大于0" if x > 0 else "小于0" if x < 0 else "等于0"
- 如果 x 大于 0,则满足条件 x > 0;如果 x 不大于 0,但小于 0,则满足条件 x < 0;如果 x 不满足前面两个条件,即等于 0,则执行最后的 else 分支。
- 如果语句再复杂一点就不适用匿名函数了,不太好阅读。
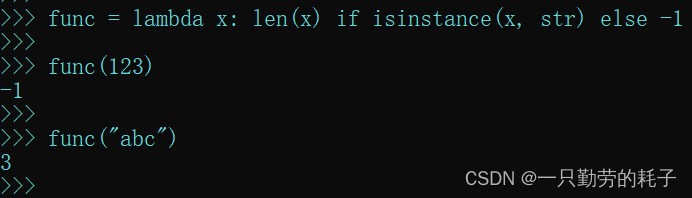
如果参数是字符串,返回字符串的长度,否则返回-1
func = lambda x: len(x) if isinstance(x, str) else -1
- 同样通过 if 判断这个参数,成功返回 len(x),失败返回 -1
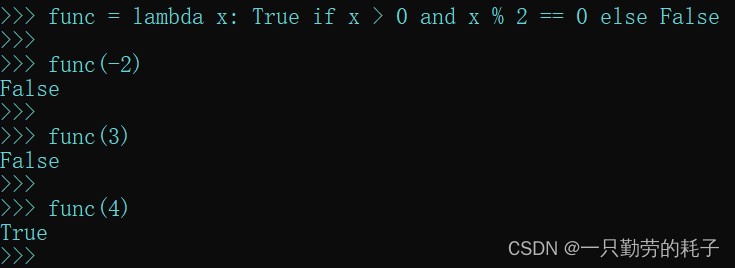
更加复杂一点的判断
func = lambda x: true if (x > 0) and (x % 2 == 0) else false
- 如果参数 x 大于0,并且是偶数,返回 true,否则返回 false
3. lambda 的应用场景
3.1. 处理列表
处理列表的元素还需要借助 filter 函数,用于过滤序列(列表、元组等)。它的语法如下:
filter(函数, 序列)
利用一个函数来对序列进行判断,该函数返回true保留元素,返回false则不保留元素。
【案例一】过滤元素的偶数
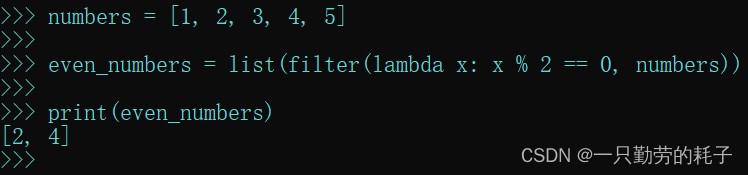
numbers = [1, 2, 3, 4, 5] even_numbers = list(filter(lambda x: x % 2 == 0, numbers))
- 元素取余为0则保留元素,反之不保留
也可以直接定义1~10的偶数列表
even_numbers = list(filter(lambda x: x % 2 == 0, range(1, 11)))

【案例二】过滤元素的奇数
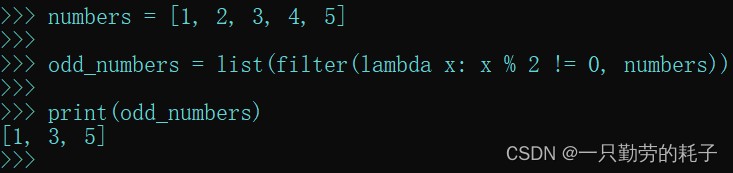
numbers = [1, 2, 3, 4, 5] odd_numbers = list(filter(lambda x: x % 2 != 0, numbers))
- 元素取余不等于0则保留元素,反之不保留
【案例三】过滤字符串长度大于3的元素
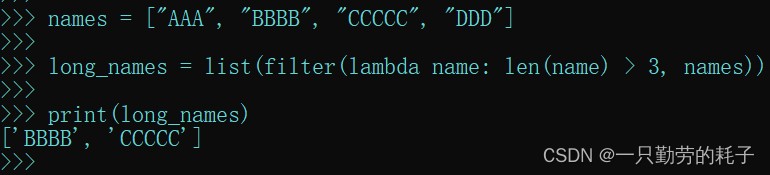
names = ["aaa", "bbbb", "ccccc", "ddd"] long_names = list(filter(lambda name: len(name) > 3, names))
- 元素长度大于3则保留元素,反之不保留
【案例四】过滤出空元素
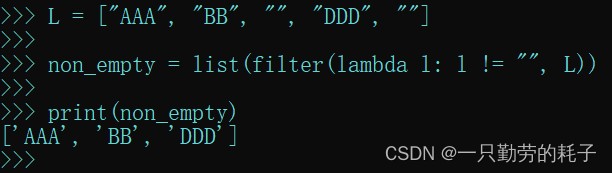
l = ["aaa", "bb", "", "ddd", ""] non_empty = list(filter(lambda l: l != "", l))
- 元素不为空则保留元素,反之不保留
3.2. 处理字典
【案例一】将值排序
age = {"小李": 18, "小王": 27, "小张": 23}
# 升序
sorted_age = dict(sorted(age.items(), key=(lambda item: item[1]) ))
# 降序
sorted_age = dict(sorted(age.items(), key=(lambda item: item[1]), reverse=true))- 利用 lambda 表达式作为排序的关键字,根据字典中的值对键值对进行排序,并使用 reverse=true/false 参数进行降/升序排序。
复杂一点的字典也是使用同样的方式处理
students = [
{"姓名": "小李", "年龄": 18, "成绩": "a"},
{"姓名": "小王", "年龄": 20, "成绩": "b"},
{"姓名": "小张", "年龄": 19, "成绩": "a"},
{"姓名": "小徐", "年龄": 21, "成绩": "c"}
]
sorted_students = sorted(students, key=lambda x: x["年龄"]) # 通过年龄排序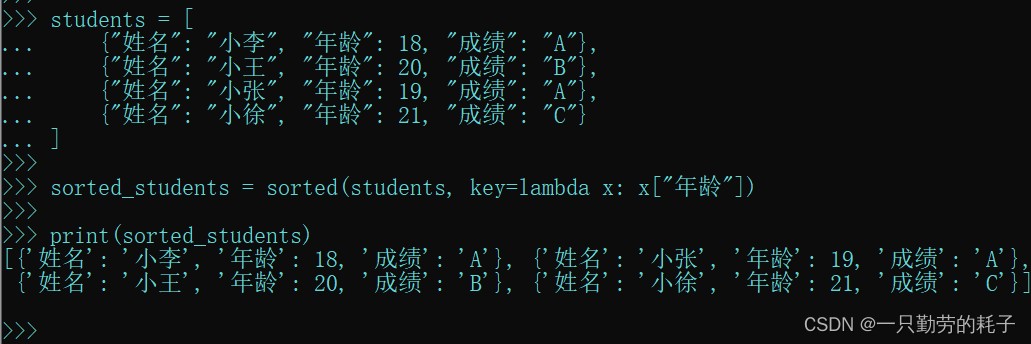
【案例二】保留值大于20的键值对
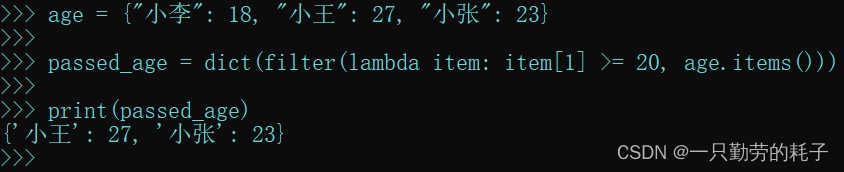
age = {"小李": 18, "小王": 27, "小张": 23}
passed_age = dict(filter(lambda item: item[1] >= 20, age.items()))
- age.items() 表示取键值对,lambda将这个键值对传入匿名函数,再通过这个参数取索引为1(就是值)的值来判断是否大于等于20。如果为true保留键值对,为false则不保留。
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。



发表评论