在网站分析、广告监测、推荐系统等场景中,独立用户访问量(uv,unique visitor) 是一个核心指标。uv 的关键在于去重——同一个用户多次访问只计一次。
redis 提供了多种数据结构来高效实现 uv 统计,各有优劣。本文将详细对比 set、bitmap、hyperloglog、incr + 日期维度(即用户提到的两种方式)四种方案,并通过流程图和代码示例帮助你选型。
一、方案概览(附选型流程图)
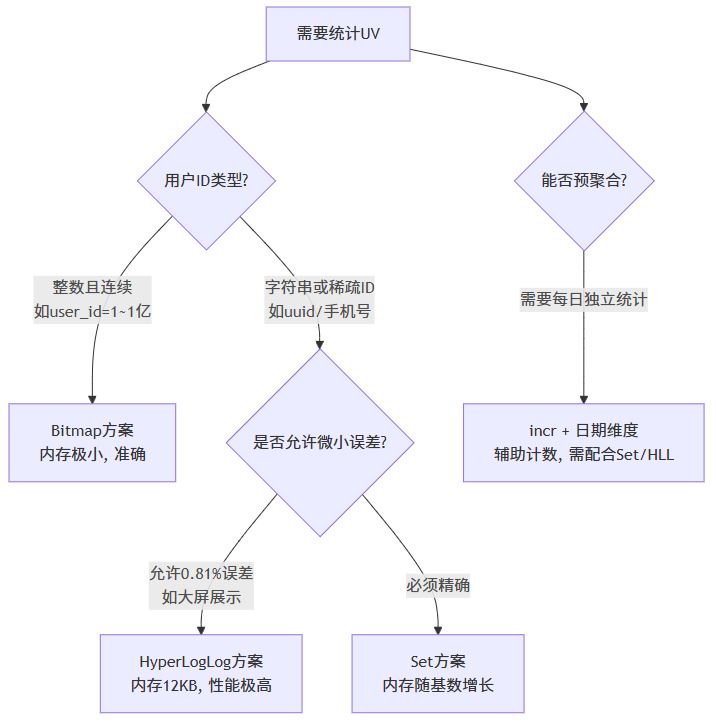
二、方案一:set 集合(精确去重)
最直观的方法:每个统计周期(如一天)维护一个 set,将每个访问过的用户 id 加入 set,最后用 scard 获取基数。
# 示例:用户 1001 访问首页
redis.sadd("uv:home:2025-04-15", "user_1001")
# 获取当天 uv
uv = redis.scard("uv:home:2025-04-15")优点:精确、支持用户 id 任意类型(字符串/整数)。
缺点:内存占用高,每个用户 id 都需要存储一份(例如 1000 万用户,每个 id 按 30 字节算,需约 300mb)。
适用:用户量小(< 百万级)或必须精确统计的场景。
三、方案二:bitmap(位图法,精确且内存极省)
当用户 id 是整数且相对连续(如自增 user_id)时,可以用 bitmap 将每个 user_id 映射到位偏移量,存在则置 1。
# 用户 id=1001 访问,设置第 1001 位为 1
redis.setbit("uv:home:2025-04-15", 1001, 1)
# 统计当日 uv(统计 1 的个数)
uv = redis.bitcount("uv:home:2025-04-15")
内存计算:如果有 1 亿用户,只需 1亿 bit ≈ 12 mb,比 set 节省数十倍。
优点:精确、内存极小、性能高(bitcount 时间复杂度 o(n) 但 redis 做了优化)。
缺点:用户 id 必须为整数且不太稀疏(若 id 最大为 10 亿,但实际只有 100 万用户,依然会占用 125mb 的连续空间,造成浪费)。
适用:用户 id 是自增整数、最大 id 可控(如 2^32 以内)、对内存敏感且要求精确的场景。
四、方案三:hyperloglog(近似去重,误差 0.81%)
你提到的 hyperloglog 是一种概率性数据结构,用 12kb 固定内存即可统计上亿级别的 uv,误差率约为 0.81%。
# 添加元素
redis.pfadd("uv:home:2025-04-15", "user_1001", "user_1002")
# 获取近似 uv
uv = redis.pfcount("uv:home:2025-04-15")
原理:通过哈希函数将元素映射为二进制串,观察低位连续零的个数来估计基数。
优点:内存固定(12kb),性能极高(o(1) 添加),适合海量数据。
缺点:不精确(误差 ±0.81%),无法取出具体有哪些用户(只能计数),不适合敏感计费场景。
适用:大屏展示、趋势分析、非精准营销统计等可容忍误差的场景。
五、方案四:incr + 日期维度(你提到的“incr自增”)
严格来说,单纯使用 incr 无法实现独立用户去重,因为 incr 是累加计数器,每次访问都 +1,得到的是 pv(页面访问量),不是 uv。
# 这样得到的是 pv,不是 uv
redis.incr("pv:home:2025-04-15")
如何用 incr 辅助 uv?
通常做法是 incr + set/bitmap/hll 组合:
- 用 set 或 hll 存储独立用户(保证去重)
- 同时用 incr 记录总访问次数(pv)
# 记录 pv
redis.incr("pv:home:2025-04-15")
# 记录 uv(使用 hll)
redis.pfadd("uv:home:2025-04-15", user_id)
所以,你提到的“incr 通过自增方式判断用户的访问量”并不适用于 uv,应理解为 pv 统计。但为了贴合你的原文,我们修正说明:incr 适合 pv,uv 必须依赖去重结构。
六、四种方案对比表
| 方案 | 内存占用 | 精确性 | 支持用户id类型 | 时间复杂度(写入) | 典型应用 |
|---|---|---|---|---|---|
| set | o(n)(每个元素完整存储) | 精确 | 任意 | o(1) | 小规模精确统计 |
| bitmap | o(max_id) 位,连续整数时极省 | 精确 | 非负整数 | o(1) | 亿级整数id,如手机号后几位 |
| hyperloglog | 固定 12kb | 近似(误差 0.81%) | 任意(需哈希) | o(1) | 海量uv快速估算 |
| incr(pv) | 固定(每个key一个整数) | 精确 | 无(只是计数) | o(1) | 页面访问总量(非uv) |
七、实战选型建议
你的用户 id 是整数且密集(如 user_id 从 1 到 5000 万)
👉 首选 bitmap,精确且内存最小。
用户 id 是字符串(如 uuid、手机号),且允许 0.81% 误差
👉 首选 hyperloglog,12kb 内存统计上亿 uv。
必须精确统计,且用户量较小(< 500 万)
👉 用 set,简单可靠。
既要 pv 又要 uv
👉 组合:incr 记录 pv + pfadd 记录 uv(hll)或 sadd(set)。
数据敏感场景(如计费、反 作弊)
❌ 不能用 hyperloglog,必须用 bitmap 或 set。
八、代码示例:三种方案对比(python + redis)
import redis
r = redis.redis(decode_responses=true)
# 模拟 100 万个用户 id(字符串)
user_ids = [f"user_{i}" for i in range(1_000_000)]
# 1. set 方式
key_set = "uv:set"
r.delete(key_set)
for uid in user_ids:
r.sadd(key_set, uid)
print(f"set 精确 uv: {r.scard(key_set)}")
print(f"set 内存: {r.memory_usage(key_set) / 1024 / 1024:.2f} mb")
# 2. hyperloglog 方式
key_hll = "uv:hll"
r.delete(key_hll)
for uid in user_ids:
r.pfadd(key_hll, uid)
print(f"hll 近似 uv: {r.pfcount(key_hll)}")
print(f"hll 内存: {r.memory_usage(key_hll)} 字节") # 固定约 12kb
# 3. bitmap 方式(假设 user_id 转为整数,此处用 i 模拟)
key_bit = "uv:bitmap"
r.delete(key_bit)
for i in range(1, 1_000_001):
r.setbit(key_bit, i, 1)
print(f"bitmap 精确 uv: {r.bitcount(key_bit)}")
print(f"bitmap 内存: {r.memory_usage(key_bit) / 1024 / 1024:.2f} mb")
运行结果参考(百万级):
- set:内存约 30~40 mb
- hll:12 kb
- bitmap:0.12 mb(100 万 bit = 0.125 mb)
九、总结
| 你的原始说法 | 修正/补充 |
|---|---|
| “incr 通过自增方式判断用户的访问量” | incr 得到的是 pv(总访问次数),不是 uv。uv 需要去重。 |
| “hyperloglog 用来做基数统计,误差很小,不适合数据敏感场景” | ✅ 正确。误差约 0.81%,内存固定 12kb,适合海量近似统计。 |
最终结论:
- 对精度要求不高、数据量极大 → hyperloglog
- 需要精确、用户 id 为整数 → bitmap
- 需要精确、用户 id 为字符串且量小 → set
- 想要统计 pv → incr
合理选择数据结构,能让你的 uv 统计既快又省内存。
以上就是redis统计独立用户访问量的四种方案的详细内容,更多关于redis统计独立用户访问量的资料请关注代码网其它相关文章!


发表评论