大key(large key)通常指的是一个key对应的value很大,例如一个string类型的value大小达到10kb,或者一个list、hash、set、zset等集合类型的元素数量过多(比如超过10000个)。
大key的危害包括:
- 网络阻塞:读取大key会消耗大量带宽,可能导致网络阻塞。
- 内存占用高:导致内存使用不均,可能引发内存不足。
- 阻塞操作:对于redis,删除大key可能导致服务阻塞(因为redis是单线程)。
使用redis自带的命令:redis-cli --bigkeys、有一些开源工具可以分析rdb文件,例如redis-rdb-tools,通过分析rdb文件来找出大key。
- 拆分大key:对于string类型的大key,可以尝试将value拆分成多个部分、对于集合类型,可以按照某种规则(例如哈希取模)将一个大集合拆分成多个小集合
- 删除大key:删除大key时,要避免阻塞redis。对于集合类型,可以使用渐进式删除
- 设置过期时间:对于有时效性的大key,可以设置过期时间,让其自动过期
热点key(hot key)指的是被频繁访问的key。热点key的危害包括:
- 流量集中:可能导致某个redis实例的流量过大,成为瓶颈(尤其是在集群模式下)。
- 服务不可用:如果热点key的访问量超过redis的处理能力,可能导致服务崩溃。
使用redis自带的命令:redis-cli --hotkeys
- 使用本地缓存
- 拆分热点key:如果热点key是一个集合,可以拆分成多个key,分散到不同的节点、对于只读的热点key,可以复制多份,比如key_1, key_2,后面追加随机数。
- 使用读写分离:通过redis的读写分离,将读请求分散到多个从节点,降低主节点的压力
- 使用redis集群:将热点key分散到不同的redis实例上,避免单个实例成为瓶颈。
一、big key
大key通常都会以数据大小与成员数量来判定:
- 一个string类型的key,它的值为5mb(数据过大)
- 一个list类型的key,它的列表数量为20000个(列表数量过多)
- 一个zset类型的key,它的成员数量为10000个(成员数量过多)
- 一个hash格式的key,它的成员数量虽然只有1000个但这些成员的value总大小为100mb(成员体积过大)
1、大key引发的问题
- 存储引发oom:redis内存不断变大引发oom
- 存储:分布不均衡:redis cluster中的某个node内存远超其余node,无法将node上的内存均衡化
- 查询占带宽:大key上的读请求使redis占用服务器全部带宽
- 删除时阻塞:删除一个大key造成主库较长时间的阻塞
2、找出大key
- 通过redis官方客户端redis-cli的big keys参数发现大key
- memory usage:命令来帮助分析key的内存占用,相对debug object命令,它的执行代价更低仍有阻塞风险。
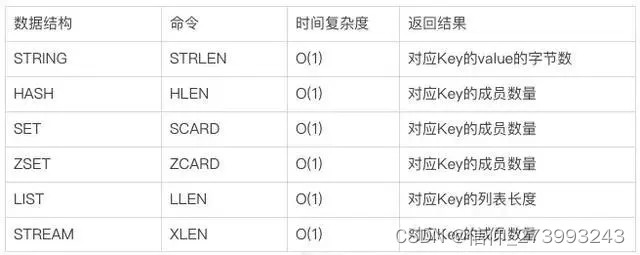
- redis对于不同的数据结构提供了不同的命令来返回其长度或成员数量,如下图
- redis-rdb-tools工具以定制化方式找出大key
3、解决方案
- 存-对大key进行拆分:hash key拆分为多个hash key,确保每个key的成员数量在合理范围
- 删-对大key进行清理:redis自4.0起提供了unlink命令,该命令能够以非阻塞的方式缓慢逐步的清理传入的key,通过unlink,你可以安全的删除大key甚至特大key。
- 监控redis的内存水位:通过[监控系统],比如普罗米修斯,并设置合理的redis内存报警阈值来提醒我们此时可能有大key正在产生,如:redis内存使用率超过70%,redis内存1小时内增长率超过20%等。
二、hotkey
热key则以其接收到的请求频率,请求次数来判定,比如:redis实例的每秒总访问量为10000,而其中一个key的每秒访问量达到了7000
1、带来的问题
- 查询-占用cpu:热key占用大量的redis cpu时间使其性能变差
- 查询-节点请求不均衡:redis cluster中node流量不均衡造成redis cluster的分布式优势无法被client利用
2、找出hotkey
- 通过redis官方客户端redis-cli的hot keys参数发现热key
- 通过业务层定位热key
- 使用monitor命令:在紧急情况时找出热key,能够打印真实的请求,缺点就是redis的cpu、内存、网络资源均有一定的占用
3、处理方式
- 存储-多节点复制:在redis cluster结构中对热key进行复制,因为分布的时候是通过hash key来得到节点,所以通过修改key的值,来改变value的分布。
- 查询-使用读写分离架构:在使用读写分离架构时可以通过不断的【增加从节点】来降低每个redis实例中的读请求压力
三、tair
大key
- 删-使用阿里云的tair(redis企业版)服务避开失效数据的清理工作
hotkey
- 使用阿里云tair的querycache特性,其实就是类似于二级缓存,把缓存放在redis proxy层。
1、介绍
- tair(tair缓存框架)是阿里巴巴开发的分布式缓存系统,它并不是直接基于redis实现的。相反,tair是一个独立的分布式缓存解决方案,具有自己的架构和特性。
- 虽然tair和redis都是分布式缓存系统,但它们是由不同的团队开发,采用了不同的设计和实现。tair在设计上考虑了阿里巴巴业务的特点和需求,提供了一些针对大规模分布式环境的优化和功能。
2、过期算法:
tairhash使用高效的【active expire】算法,实现了在对响应时间几乎无影响的前提下,高效完成对field过期判断和删除的功能。此类高级功能的合理使用能够解放大量redis的运维、故障处理工作并降低业务的代码复杂度,让运维将精力投入到其它更有价值的工作中,让研发有更多的时间来写更有价值的代码。
3、querycache是阿里云tair(redis企业版)服务的企业级特性之一
tair querycache原理
- 阿里云数据库redis会根据高效的排序和统计算法识别出实例中存在的热点key,开启该功能后,proxy点会根据设定的规则【缓存】热点key的请求和查询结果(仅缓存热点key的查询结果,无需缓存整个key),当在缓存有效时间内收到相同的请求时【proxy会直接返回结果至客户端】,无需和后端的redis分片执行交互。
- 在提升读取速度的同时,降低了热点key对数据分片的性能影响,避免发生请求倾斜。
至此,来自客户端的同样的请求无需再与proxy后端的redis进行交互而由proxy直接返回数据,指向热key的请求由一个redis节点承担转为多个proxy共同承担,能够大幅度降低redis节点的热key压力,同时tair的querycache功能还提供了大量的命令来方便用户查看、管理,如通过querycache keys命令查看所有被缓存热key,通过querycache listall获取所有已缓存的所有命令等。
tair querycache智能化的热key判定与缓存联动功同样能够降低运维及研发的工作负担。与传统的redis同步中间件相比,阿里云redis全球分布式缓存具有高可靠性、高吞吐低延迟、同步正确性高等特点。
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。


发表评论