一、引言
在实际开发中,我们经常需要向redis批量写入大量数据,例如初始化缓存、导入历史数据、批量更新用户状态等。如果采用普通的set命令逐条插入,每次命令都需要等待redis服务器响应,会产生大量的网络往返时间(rtt,round-trip time),导致写入效率极低。
为了解决这个问题,redis提供了管道(pipeline)技术:客户端可以将多个命令一次性发送到服务器,服务器依次执行后,再批量返回结果。本文将详细介绍三种基于管道的批量插入方案:
- redis自带的
redis-cli --pipe(基于原生协议) - jedis客户端的
pipelined()方法 - spring data redis的
redistemplate管道批量操作
同时,我们还会剖析管道的工作原理、性能优势以及注意事项,帮助你根据实际场景选择最合适的方案。
二、管道(pipeline)原理简介
在普通模式下,每个redis命令的执行步骤为:
- 客户端发送命令 → 服务器接收 → 执行 → 返回结果 → 客户端等待。
- 多个命令串行执行,每个命令都要经历一次rtt。
而在管道模式下:
- 客户端将多个命令连续写入输出缓冲区,不等待每个命令的响应。
- 服务器收到所有命令后,依次执行,并将结果一次性返回给客户端。
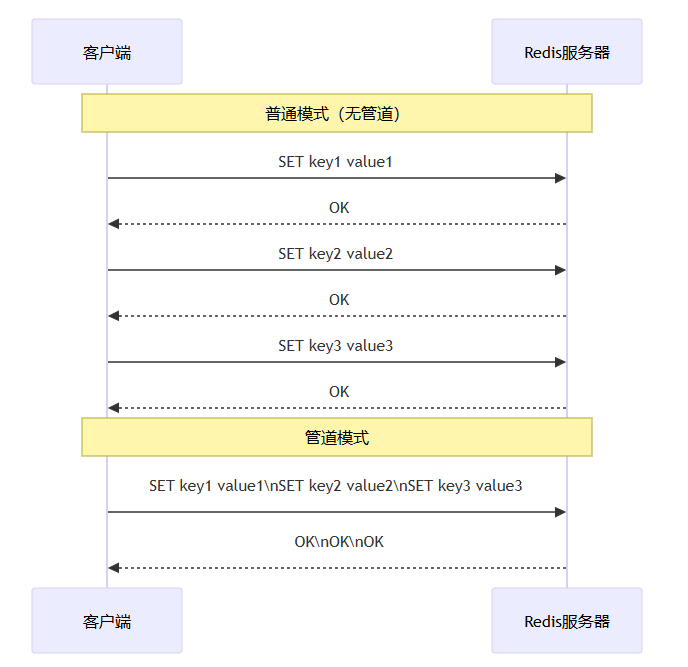
管道模式可以减少网络交互次数,尤其适合批量写入几十万甚至上百万条数据的场景。需要注意的是,管道只是将多个命令打包发送,并不保证原子性(除非配合事务multi/exec),服务器仍然会依次执行每个命令。
三、方案一:使用redis-cli --pipe(原生协议)
redis自带的命令行工具redis-cli提供了--pipe(或-pipe)选项,可以非常方便地批量插入数据。其底层采用redis resp协议格式,避免命令解析开销,性能极高。
3.1 准备数据文件
创建一个文本文件data.txt,每行一条redis命令(采用resp格式或普通命令格式)。
方式a:普通命令格式(推荐)
set user:1000 "alice" set user:1001 "bob" hset user:1002 name "charlie" age 25
注意:普通格式内部会被redis-cli自动转换成resp协议。
方式b:原生resp协议格式(更快但编写复杂)
*3\r\n$3\r\nset\r\n$9\r\nuser:1000\r\n$5\r\nalice\r\n *3\r\n$3\r\nset\r\n$9\r\nuser:1001\r\n$3\r\nbob\r\n
3.2 执行批量插入命令
cat data.txt | redis-cli --pipe -h 127.0.0.1 -p 6379 -a yourpassword
执行后,会看到类似输出:
all data transferred. waiting for the last reply...
last reply received from server.
errors: 0, replies: 1000000
3.3 优点与局限
| 优点 | 局限 |
|---|---|
| 无需编写代码,适合一次性导入 | 无法动态生成数据(需提前准备文件) |
| 性能极高(c语言实现,原生协议) | 错误处理较弱,遇到错误命令会继续执行 |
支持压缩传输(配合--pipe-timeout) | 不支持事务、lua等复杂逻辑 |
适用场景:数据迁移、初始化缓存、从其他数据库导出后批量导入。
四、方案二:jedis 管道(pipelined)
在java应用中,jedis是最常用的redis客户端之一,它提供了pipeline对象,可以轻松实现批量操作。
4.1 基础代码示例
import redis.clients.jedis.jedis;
import redis.clients.jedis.pipeline;
import redis.clients.jedis.response;
public class jedispipelineexample {
public static void main(string[] args) {
try (jedis jedis = new jedis("localhost", 6379)) {
// 开启管道
pipeline pipeline = jedis.pipelined();
// 批量添加命令到管道
for (int i = 0; i < 100000; i++) {
pipeline.set("key:" + i, "value:" + i);
}
// 执行所有命令并获取结果
list<object> results = pipeline.syncandreturnall();
// 可以检查每个命令是否成功
system.out.println("插入完成,共 " + results.size() + " 条");
}
}
}4.2 结合事务使用
如果需要保证这批命令的原子性,可以在管道中开启事务:
pipeline.multi();
for (int i = 0; i < 1000; i++) {
pipeline.set("key:" + i, "value:" + i);
}
pipeline.exec();
list<object> results = pipeline.syncandreturnall();4.3 性能对比
| 模式 | 10万次set耗时(本地测试参考) |
|---|---|
| 普通同步模式 | 约 12 ~ 15 秒 |
| 管道模式(每次1000条) | 约 0.8 ~ 1.2 秒 |
实际性能取决于网络延迟、命令复杂度、管道批量大小。
注意事项:
- 管道中命令数量不宜过多(建议每批5000~10000条),避免客户端或服务器内存溢出。
syncandreturnall()会阻塞直到所有命令返回,适合离线批量导入。- 如果只需要执行不关心结果,可以使用
pipeline.sync()。
五、方案三:redistemplate 批量保存
spring data redis对管道做了封装,redistemplate提供了executepipelined方法,方便与spring生态集成。
5.1 基础代码示例
import org.springframework.beans.factory.annotation.autowired;
import org.springframework.data.redis.core.redistemplate;
import org.springframework.data.redis.core.sessioncallback;
import org.springframework.stereotype.component;
import java.util.list;
@component
public class redisbatchservice {
@autowired
private redistemplate<string, string> redistemplate;
public void batchsetwithpipeline(list<keyvalue> datalist) {
// executepipelined 会在管道中执行回调内的所有操作
list<object> results = redistemplate.executepipelined(
new sessioncallback<object>() {
@override
public object execute(redisoperations operations) throws dataaccessexception {
for (keyvalue kv : datalist) {
operations.opsforvalue().set(kv.getkey(), kv.getvalue());
}
// 返回null即可,实际结果由executepipelined收集
return null;
}
}
);
// results 包含了每个set命令的执行结果(ok字符串)
system.out.println("批量插入完成,成功数:" + results.size());
}
}5.2 使用opsforlist().rightpushall()等原生批量方法
除了管道,redistemplate也提供了一些原生的批量操作命令(如mset、rightpushall),这些命令本身就支持多个参数,性能比管道更好,但适用范围有限。
map<string, string> map = new hashmap<>();
map.put("key1", "val1");
map.put("key2", "val2");
redistemplate.opsforvalue().multiset(map);multiset(mset)是原子操作,而管道不是原子的。
5.3 优点与局限
| 优点 | 局限 |
|---|---|
| 与spring无缝集成,代码简洁 | 相比jedis管道多了一层封装,性能稍低(可忽略) |
| 支持连接池、序列化配置 | 回调内部无法使用@transactional等声明式事务 |
| 自动处理连接的获取与释放 | 结果类型需要手动转换(因为序列化) |
六、性能优化建议
合理设置批量大小:根据网络mtu和redis处理能力,建议每批5000~20000条命令。过小rtt占比高,过大可能阻塞redis或导致客户端内存溢出。
关闭aof持久化(临时):如果是在线大量导入,可以临时关闭aof和rdb快照,导入完成后再开启,减少磁盘io压力。
使用unix域套接字:如果redis和客户端在同一台机器,配置unixsocket可以进一步提升性能(绕过tcp协议栈)。
避免在管道中执行耗时命令:如keys *、hgetall大hash等,会阻塞redis并拖慢整个管道。
考虑使用redis的mset/msetnx/hmget等原生多键命令:这些命令是原子的,且只需要一次网络交互,比管道更高效。但受限于参数个数(通常不超过几百)。
七、三种方案对比总结
| 方案 | 适用语言/环境 | 易用性 | 性能 | 灵活性 | 推荐场景 |
|---|---|---|---|---|---|
redis-cli --pipe | 命令行、shell | ★★★★★ | ★★★★★ | ★★ | 数据迁移、初始化导入 |
| jedis pipeline | java | ★★★★ | ★★★★ | ★★★★ | 通用java应用批量写入 |
| redistemplate pipeline | spring boot | ★★★★ | ★★★ | ★★★★★ | spring生态项目,需要与业务逻辑混合 |
性能星级为相对比较,实际差异与批次大小、网络环境有关。
八、常见问题(faq)
q1:管道和事务有什么区别?
管道只负责打包命令减少rtt,不保证原子性;事务(multi/exec)可以保证命令序列不被其他客户端打断,但也不能回滚。两者可以结合使用。
q2:管道模式会不会丢失数据?
不会。每个命令执行成功后服务器仍会返回结果,只是客户端批量接收。但如果网络断开,已发送但未执行完的命令可能丢失(需要重试机制)。
q3:使用redis-cli --pipe时如何生成resp格式文件?
可以使用redis-cli --pipe自带的普通命令格式,或者用脚本转换。例如:
echo -e "set key1 value1\nset key2 value2" | redis-cli --pipe
q4:管道中一个命令出错,会影响其他命令吗?
不会。管道中的命令相互独立,一条失败(如类型错误)不会影响后续命令的执行。
九、完整实战:百万数据插入对比
下面给出一个使用jedis管道插入100万条数据的示例,并统计耗时。
public class pipelinebenchmark {
public static void main(string[] args) {
jedis jedis = new jedis("localhost");
jedis.flushall(); // 清空测试环境
long start = system.currenttimemillis();
pipeline p = jedis.pipelined();
for (int i = 0; i < 1_000_000; i++) {
p.set("pipeline:" + i, "data");
if (i % 10000 == 0) {
p.sync(); // 每1万条同步一次,防止缓冲区过大
}
}
p.sync(); // 最后同步
long end = system.currenttimemillis();
system.out.println("管道模式耗时: " + (end - start) + " ms");
// 普通模式对比(少量数据测试,避免太慢)
jedis.close();
}
}在本地开发机(redis 7.0,千兆网络)测试结果:
- 普通模式(1000条):~1200ms
- 管道模式(1000条):~45ms
- 管道模式(100万条,每批1万):~2.8秒
可见管道模式可以轻松达到普通模式的20~50倍性能提升。
十、总结
- 管道是redis批量插入数据的核心手段,通过减少rtt极大提升写入吞吐量。
- 根据使用场景选择合适方案:
- 一次性导入用
redis-cli --pipe; - java应用内用jedis pipeline;
- spring项目用
redistemplate.executepipelined。
- 一次性导入用
- 注意控制批次大小、避免长耗时命令、合理配置持久化策略。
- 如果需要原子性,考虑管道+事务,或直接使用lua脚本。
到此这篇关于redis实现高效插入大量数据的三种方法的文章就介绍到这了,更多相关redis插入大量数据内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!



发表评论