在日常的 java 开发工作中,我们偶尔会遇到需要将 html 内容转换为 pdf 文档的需求。比如生成格式化的业务报告、导出带有样式的邮件模板、或是将前端页面固化为可存档的文件。实现这一功能有多种技术选型,本文记录一种基于 spire.doc for java 的实现方式,供有类似需求的开发者参考。
环境准备
在开始编码之前,需要先将 spire.doc for java 引入到项目中。该组件支持通过 maven 仓库进行依赖管理,在 pom.xml 中添加以下配置即可:
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.cn/repository/maven-public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupid>e-iceblue</groupid>
<artifactid>spire.doc</artifactid>
<version>13.8.7</version>
</dependency>
</dependencies>如果不使用 maven,也可以手动下载 jar 文件并将其添加到项目的 classpath 中。关于免费版的限制说明:该组件存在免费版 license,但在加载文档时对段落数量、表格数量有硬性限制。若超出限制范围,api 会抛出异常或仅能获取文档的前几页内容。在实际项目中使用时,建议先根据业务文档的平均规模进行可行性评估。
两种常见的转换场景
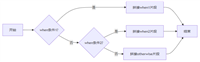
在实际应用中,html 内容的来源通常有两种:一种是已经生成好的 html 文件,另一种是程序运行时动态生成的 html 字符串。下面分别说明这两种情况的处理方式。
场景一:将 html 文件转换为 pdf
这是最直接的使用场景——已经有一个现成的 html 文件,希望将其原样转换为 pdf。核心步骤是加载文件、指定格式、保存输出:
import com.spire.doc.*;
import com.spire.doc.documents.xhtmlvalidationtype;
public class htmlfiletopdf {
public static void main(string[] args) {
// 创建 document 对象
document document = new document();
// 加载 html 文件
// xhtmlvalidationtype.none 表示不进行严格的 xhtml 校验
document.loadfromfile("input.html", fileformat.html, xhtmlvalidationtype.none);
// 保存为 pdf 格式
document.savetofile("output.pdf", fileformat.pdf);
document.dispose();
}
}loadfromfile 方法的第三个参数 xhtmlvalidationtype 用于控制加载时的校验严格程度。如果 html 内容中包含一些非标准写法(如未闭合的标签),设置为 none 可以避免加载过程中抛出异常。
场景二:将 html 字符串转换为 pdf
在一些动态生成内容的场景中,html 可能是在内存中拼接好的字符串,而不是落盘的文件。此时可以通过 appendhtml 方法将字符串写入文档段落,再导出为 pdf:
import com.spire.doc.*;
import com.spire.doc.documents.paragraph;
public class htmlstringtopdf {
public static void main(string[] args) {
// 创建 document 对象并添加节
document document = new document();
section section = document.addsection();
paragraph paragraph = section.addparagraph();
// html 字符串(可包含内联样式)
string htmlcontent = "<html><body>" +
"<h2 style='color: #333;'>销售数据报告</h2>" +
"<table border='1' style='border-collapse: collapse;'>" +
"<tr><th>产品</th><th>销量</th><th>金额</th></tr>" +
"<tr><td>产品a</td><td>120</td><td>¥12,000</td></tr>" +
"<tr><td>产品b</td><td>85</td><td>¥8,500</td></tr>" +
"</table>" +
"<p>生成时间:2026年4月9日</p>" +
"</body></html>";
// 将 html 字符串追加到段落
paragraph.appendhtml(htmlcontent);
// 保存为 pdf
document.savetofile("output_from_string.pdf", fileformat.pdf);
document.dispose();
}
}
这种方式的原理是先将 html 内容渲染到 word 文档对象模型中,再从 word 文档导出为 pdf。对于常见的 css 样式(如颜色、边框、字体等)支持较好,但部分 css3 布局特性(如 flexbox、grid 布局)可能无法被完全解析和呈现。
进阶设置:pdf 输出参数调优
在转换过程中,spire.doc 提供了一些参数可供调整,以优化输出效果。这种转换本质上是先将 html 解析为 word 的文档对象模型(document object model),再调用渲染引擎生成 pdf。因此,针对 word 转 pdf 的输出参数在此场景下同样适用:
import com.spire.doc.*;
public class htmltopdfwithsettings {
public static void main(string[] args) {
document document = new document();
document.loadfromfile("input.html", fileformat.html, xhtmlvalidationtype.none);
// 创建 pdf 参数对象
topdfparameterlist pdfparams = new topdfparameterlist();
// 嵌入所有字体,确保跨设备显示一致
pdfparams.isembeddedallfonts(true);
// 禁用超链接效果(链接文字不再显示为蓝色下划线样式)
pdfparams.setdisablelink(false);
// 设置图片 jpeg 压缩质量(默认 80%)
document.setjpegquality(60);
// 保存时传入参数
document.savetofile("output_optimized.pdf", pdfparams);
document.dispose();
}
}
注意事项与踩坑记录
在使用过程中,有几个容易遇到的问题值得提前关注:
1. 中文字体显示问题
如果 html 中使用了系统中未安装的字体,pdf 输出可能出现乱码或字体回退异常。建议在 html 的 css 中优先使用通用字体族(如 font-family: "microsoft yahei", "simhei", sans-serif;),或确认运行环境已安装所需字体文件。
2. html 复杂布局的兼容性边界
该组件的 html 解析引擎基于 word 文档模型设计,而非浏览器内核。因此,依赖现代 css 特性的布局方式(如 display: flex、position: sticky、grid)大概率无法按浏览器效果呈现。在设计 html 模板时,建议回归传统的文档流布局,以表格和块级元素为主进行排版。
3. 内存资源释放
处理大批量文档转换任务时,需注意在循环中及时调用 dispose() 方法释放非托管资源,避免内存持续占用导致服务压力。
4. 版本迭代带来的兼容性变化
根据公开的版本发布记录,该组件在迭代中会修复 html 转 word/pdf 过程中的图片丢失、样式错乱等问题。若遇到特定结构的渲染异常,可以尝试更新依赖版本以获取最新的解析逻辑。
结语
spire.doc for java 提供了一套 api 接口,能够在无 microsoft office 环境依赖的情况下完成 html 到 pdf 的转换工作流。对于样式复杂度相对可控、排版以文档流为主的转换需求而言,这是一种可行的技术路径。
当然,如果项目对 pdf 输出的像素级精确度有极高要求(例如需要完美还原浏览器渲染效果的电子发票),基于无头浏览器的方案(如 playwright、puppeteer 或 selenium)依然是更稳妥的选择。技术选型总是在环境依赖与渲染精度之间做权衡,建议结合具体业务场景评估后再行决策。
以上就是基于spire.doc for java实现html转pdf的操作方案的详细内容,更多关于java实现html转pdf的资料请关注代码网其它相关文章!




发表评论