自动垃圾收集器不是万能的,这些隐蔽的oom陷阱你遇到过吗?
java的自动垃圾收集器(gc)让我们能专注于业务逻辑,但内存溢出(oom)依然是生产环境中常见的“隐形杀手”。本文通过三个真实案例,揭示业务代码中容易忽略的oom场景,并给出解决方案。我们将使用关键代码和mermaid图直观展示问题本质,帮助你从根本上避免类似问题。
案例一:太多份相同的对象导致oom
场景描述
某项目需要实现用户名的自动补全功能(类似搜索框的联想提示)。开发同学设计了一个内存缓存:以用户名的所有前缀作为key,value是对应前缀的用户列表。例如用户“aa”和“ab”会生成key“a”、“aa”、“ab”,输入“a”时就能返回两个用户。
问题代码
private concurrenthashmap<string, list<userdto>> autocompleteindex = new concurrenthashmap<>();
@postconstruct
public void wrong() {
// 从数据库加载所有用户(假设1万个)
userrepository.findall().foreach(userentity -> {
int len = userentity.getname().length();
// 为每个用户名的前1~n位创建索引
for (int i = 0; i < len; i++) {
string key = userentity.getname().substring(0, i + 1);
autocompleteindex.computeifabsent(key, s -> new arraylist<>())
.add(new userdto(userentity.getname())); // 每次都new对象
}
});
}
每个userdto除了用户名还包含10kb的模拟数据。运行后,1万个用户却生成了6万个userdto对象,占用约1.2gb内存,远超预期。
问题分析
虽然只有1万个真实用户,但每个用户名平均长度6位,因此产生了6万个索引条目,每个条目都创建了新的userdto对象,导致内存中对象数量膨胀6倍。
原始方案的对象关系图:
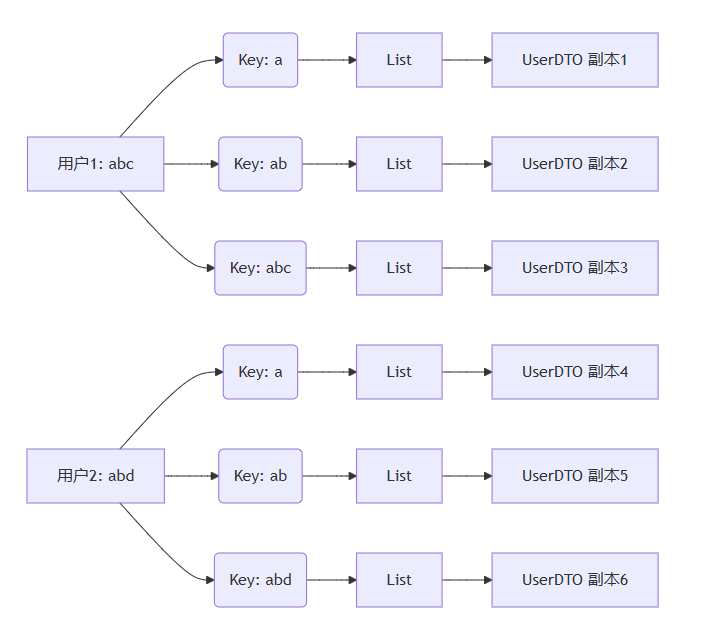
解决方案
使用hashset去重,确保每个用户只保留一份userdto,所有索引key的list都引用同一份对象。
@postconstruct
public void right() {
// 先构建去重的用户缓存
hashset<userdto> cache = userrepository.findall().stream()
.map(item -> new userdto(item.getname()))
.collect(collectors.tocollection(hashset::new));
// 构建索引时共享对象
cache.foreach(userdto -> {
int len = userdto.getname().length();
for (int i = 0; i < len; i++) {
string key = userdto.getname().substring(0, i + 1);
autocompleteindex.computeifabsent(key, s -> new arraylist<>())
.add(userdto); // 共享同一对象
}
});
}
优化后的对象关系图:
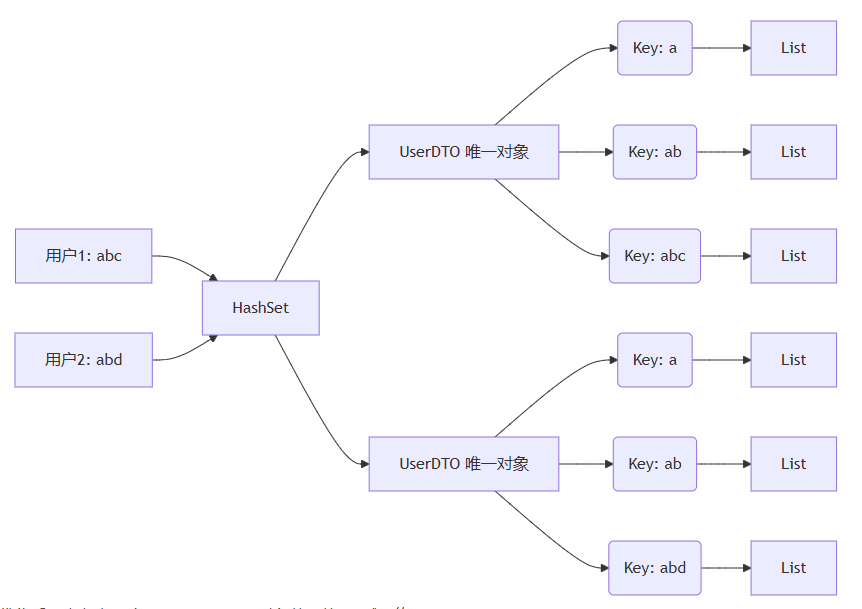
优化后,内存占用降至不足200mb,对象数量从6万减至约1万。
教训
- 容量评估时不能想当然地认为“一份数据在内存中也是一份”。经过框架转换、多次复制,内存占用可能成倍增长。
- 使用集合缓存时,务必考虑对象复用,避免重复创建。
案例二:使用weakhashmap不等于不会oom
场景描述
开发者想用weakhashmap作为缓存,认为当key不再被外部引用时,entry会自动被gc回收,避免内存堆积。于是实现了如下代码,缓存200万个用户资料。
private map<user, userprofile> cache = new weakhashmap<>();
@getmapping("wrong")
public void wrong() {
string username = "zhuye";
longstream.rangeclosed(1, 2000000).foreach(i -> {
user user = new user(username + i);
cache.put(user, new userprofile(user, "location" + i));
});
}
运行后却发现cache.size()始终是200万,最终导致oom。
问题分析
weakhashmap的key是弱引用,但valueuserprofile却持有user对象的强引用(通过其user字段)。这导致即使外部的user变量不再使用,user对象仍然被userprofile引用,无法被gc回收。
引用关系图(问题版):
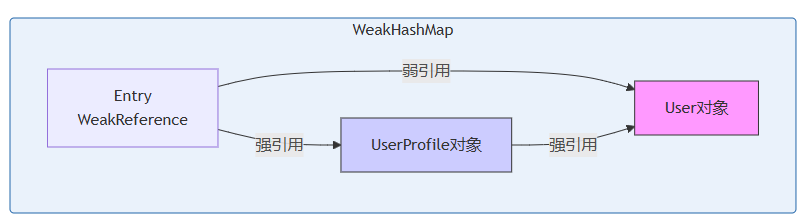
当gc发生时,key(user)只有弱引用,本应被回收,但因value中的强引用,整个entry无法从referencequeue中移除,导致内存泄漏。
解决方案
让value也使用弱引用包装,切断value对key的强引用链。
private map<user, weakreference<userprofile>> cache2 = new weakhashmap<>();
@getmapping("right")
public void right() {
string username = "zhuye";
longstream.rangeclosed(1, 2000000).foreach(i -> {
user user = new user(username + i);
cache2.put(user, new weakreference<>(new userprofile(user, "location" + i)));
});
}
或者重新创建user对象,使userprofile不再引用原来的key:
cache.put(user, new userprofile(new user(user.getname()), "location" + i));
优化后的引用关系:
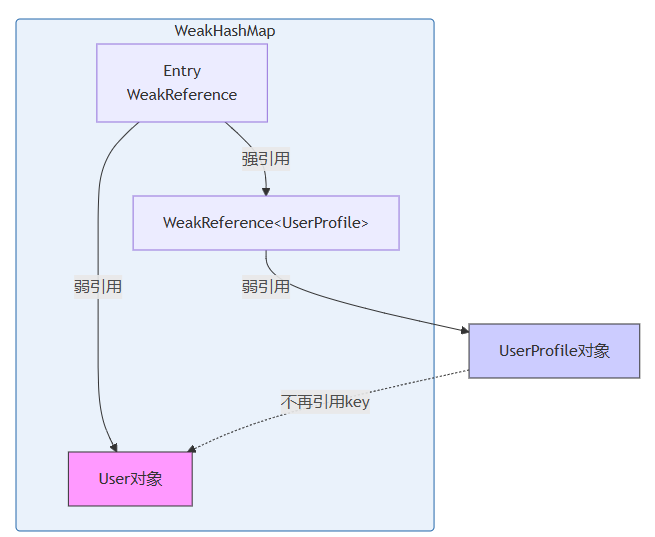
现在,当key只被弱引用时,gc可以回收key,同时weakreference<userprofile>也会被回收,entry最终被清除。
补充
spring提供的concurrentreferencehashmap支持key和value同时使用软引用或弱引用,线程安全且性能更好,是更优的选择。
案例三:tomcat参数配置不合理导致oom
场景描述
某应用在业务高峰期频繁出现oom,堆dump显示有大量1.7gb的byte数组,占满了2gb的堆内存。分析发现,这些数组来自tomcat的工作线程。
问题代码
查看项目配置,发现有人修改了tomcat的max-http-header-size参数:
server.max-http-header-size=10000000
起因是开发遇到了java.lang.illegalargumentexception: request header is too large异常,搜索后简单地将该参数改为一个超大值(10mb),期望永远不再报错。
问题分析
tomcat的http11inputbuffer和http11outputbuffer会根据max-http-header-size分配固定大小的缓冲区。该配置导致每个请求的request和response各占用约10mb内存(实际inputbuffer稍大)。假设有100个工作线程,仅缓冲区就占用近2gb,加上业务对象,很容易oom。
请求处理内存分配示意图:
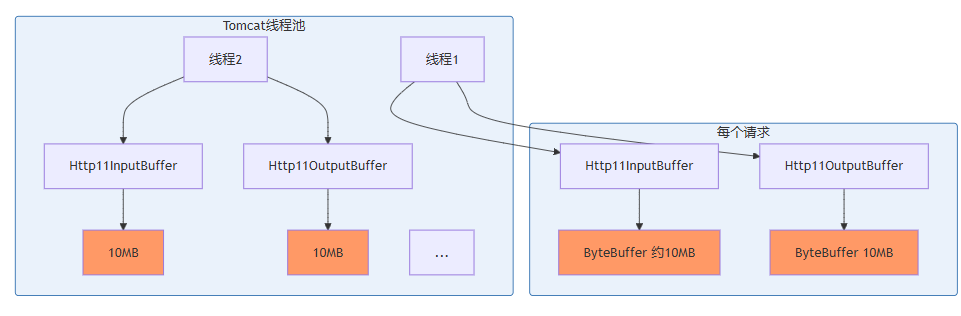
解决方案
将参数改为合理值,例如20000(20kb),并压测验证:
server.max-http-header-size=20000
教训
- 修改参数前要理解其含义,容量类参数背后往往代表资源占用,不能随意设置超大值。
- 建议预留2~5倍余量,但必须结合实际需求。
总结与建议
1.对象复用意识:相同数据可能因多次转换、索引等原因在内存中存在多份,使用hashset等去重可大幅降低内存占用。
2.引用类型陷阱:weakhashmap的value若持有key的强引用,会导致key无法回收。使用弱引用包装value或切断引用链。
3.合理配置资源:tomcat等中间件的容量参数需谨慎设置,过大会直接导致内存暴涨。
4.oom排查手段:
启用gc日志和heapdumponoutofmemoryerror:
-xx:+heapdumponoutofmemoryerror -xx:heapdumppath=. -xx:+printgcdatestamps -xx:+printgcdetails -xloggc:gc.log -xx:+usegclogfilerotation -xx:numberofgclogfiles=10 -xx:gclogfilesize=100m
使用mat、jvisualvm等工具分析堆dump,定位大对象和引用链。
思考与讨论
- spring的
concurrentreferencehashmap支持key和value使用软引用或弱引用。你觉得哪种方式更适合做缓存?为什么? - 动态执行groovy脚本时,每次
new groovyshell()会生成大量类,容易导致metaspace oom。你知道如何避免吗?
到此这篇关于深度解析java中内存溢出(oom)的典型案例与避坑指南的文章就介绍到这了,更多相关java内存溢出避坑内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论