1. 引言:postgresql的技术演进与现状
postgresql作为全球最先进的开源关系型数据库,自1986年诞生以来,历经30多年的持续发展,已成为企业级应用的首选数据库之一。根据2023年db-engines排名数据显示,postgresql在"流行度"和"功能完备性"两方面均位列开源数据库第一。其强大的扩展性、严格的数据完整性和丰富的功能特性,使其在处理复杂查询、海量数据和高并发场景时表现出色。
本文将深入探讨postgresql的高级特性与性能优化技术,结合python实践,帮助开发者充分发挥postgresql的潜力。根据国际数据公司(idc)的报告,使用postgresql的企业在数据库运营成本上平均降低65%,同时查询性能提升300% 以上。
2. postgresql高级特性详解
2.1 jsonb与半结构化数据处理
postgresql的jsonb类型提供了对json数据的二进制存储,支持索引、查询和修改操作,实现了关系型数据库与文档数据库的完美结合。
2.1.1 jsonb性能对比分析
| 操作类型 | jsonb性能 | json性能 | 性能提升 |
|---|---|---|---|
| 数据插入 | o(log n) | o(n) | 5-10倍 |
| 路径查询 | o(log n) | o(n) | 20-100倍 |
| 索引构建 | o(n log n) | 不支持 | 无限 |
| 数据更新 | o(log n) | o(n) | 10-50倍 |
jsonb的存储格式优势体现在:

2.2 全文搜索与文本分析
postgresql内置了强大的全文搜索功能,支持多语言、词干提取、相关性排序等高级特性。
"""
postgresql全文搜索高级应用示例
"""
import psycopg2
from psycopg2.extras import json, dictcursor
import json
from typing import list, dict, any, optional
import logging
from datetime import datetime
logging.basicconfig(level=logging.info)
logger = logging.getlogger(__name__)
class postgresqlfulltextsearch:
"""postgresql全文搜索高级功能封装"""
def __init__(self, dsn: str):
"""
初始化数据库连接
args:
dsn: 数据库连接字符串
"""
self.conn = psycopg2.connect(dsn)
self.conn.autocommit = false
self.cursor = self.conn.cursor(cursor_factory=dictcursor)
def create_fulltext_configuration(self, lang: str = 'english'):
"""
创建自定义全文搜索配置
args:
lang: 语言配置
"""
config_sql = f"""
-- 创建自定义文本搜索配置
create text search configuration {lang}_custom (
copy = {lang}
);
-- 添加同义词字典
create text search dictionary synonym_dict (
template = synonym,
synonyms = synonym_sample
);
-- 添加自定义字典到配置
alter text search configuration {lang}_custom
alter mapping for asciiword, asciihword, hword_asciipart
with synonym_dict, english_stem;
"""
try:
self.cursor.execute(config_sql)
self.conn.commit()
logger.info(f"全文搜索配置创建成功: {lang}_custom")
except exception as e:
self.conn.rollback()
logger.error(f"创建配置失败: {e}")
def create_searchable_table(self):
"""
创建支持全文搜索的表
"""
create_table_sql = """
-- 创建文档表
create table if not exists documents (
id serial primary key,
title varchar(500) not null,
content text not null,
author varchar(200),
category varchar(100),
tags jsonb default '[]',
publication_date date default current_date,
-- 生成列:用于全文搜索
content_search_vector tsvector generated always as (
setweight(to_tsvector('english_custom', coalesce(title, '')), 'a') ||
setweight(to_tsvector('english_custom', coalesce(content, '')), 'b')
) stored,
-- 生成列:用于元数据搜索
metadata_search_vector tsvector generated always as (
to_tsvector('english_custom',
coalesce(author, '') || ' ' ||
coalesce(category, '') || ' ' ||
(tags::text)
)
) stored,
-- 创建gin索引优化搜索性能
constraint valid_tags check (jsonb_typeof(tags) = 'array')
);
-- 创建gin索引
create index if not exists idx_documents_content_search
on documents using gin(content_search_vector);
create index if not exists idx_documents_metadata_search
on documents using gin(metadata_search_vector);
-- 创建部分索引优化特定查询
create index if not exists idx_documents_recent
on documents(publication_date)
where publication_date > current_date - interval '1 year';
-- 创建brin索引用于时间范围查询
create index if not exists idx_documents_date_brin
on documents using brin(publication_date);
"""
try:
self.cursor.execute(create_table_sql)
self.conn.commit()
logger.info("全文搜索表创建成功")
except exception as e:
self.conn.rollback()
logger.error(f"创建表失败: {e}")
def insert_document(self, document: dict[str, any]) -> optional[int]:
"""
插入文档数据
args:
document: 文档数据
returns:
插入的文档id
"""
insert_sql = """
insert into documents (title, content, author, category, tags, publication_date)
values (%s, %s, %s, %s, %s, %s)
returning id
"""
try:
self.cursor.execute(
insert_sql,
(
document.get('title'),
document.get('content'),
document.get('author'),
document.get('category'),
json(document.get('tags', [])),
document.get('publication_date')
)
)
doc_id = self.cursor.fetchone()['id']
self.conn.commit()
logger.info(f"文档插入成功,id: {doc_id}")
return doc_id
except exception as e:
self.conn.rollback()
logger.error(f"插入文档失败: {e}")
return none
def search_documents(
self,
query: str,
categories: list[str] = none,
start_date: str = none,
end_date: str = none,
min_relevance: float = 0.1,
limit: int = 20,
offset: int = 0
) -> list[dict[str, any]]:
"""
高级全文搜索
args:
query: 搜索查询词
categories: 分类筛选
start_date: 开始日期
end_date: 结束日期
min_relevance: 最小相关性阈值
limit: 返回结果数量
offset: 偏移量
returns:
搜索结果列表
"""
search_sql = """
select
id,
title,
author,
category,
publication_date,
tags,
-- 计算相关性得分
ts_rank(
content_search_vector,
plainto_tsquery('english_custom', %s)
) as relevance_score,
-- 高亮显示匹配内容
ts_headline(
'english_custom',
content,
plainto_tsquery('english_custom', %s),
'startsel=<mark>, stopsel=</mark>, maxwords=50, minwords=10'
) as content_highlight,
-- 提取匹配片段
ts_headline(
'english_custom',
title,
plainto_tsquery('english_custom', %s),
'startsel=<mark>, stopsel=</mark>'
) as title_highlight
from documents
where
-- 全文搜索条件
content_search_vector @@ plainto_tsquery('english_custom', %s)
-- 分类筛选
{category_filter}
-- 日期范围筛选
{date_filter}
-- 相关性阈值筛选
and ts_rank(
content_search_vector,
plainto_tsquery('english_custom', %s)
) > %s
order by
-- 按相关性和时间加权排序
(ts_rank(
content_search_vector,
plainto_tsquery('english_custom', %s)
) * 0.7 +
(case when publication_date > current_date - interval '30 days'
then 0.3 else 0 end)) desc,
publication_date desc
limit %s offset %s
"""
# 构建动态where条件
category_filter = ""
date_filter = ""
params = [query, query, query, query]
if categories:
placeholders = ', '.join(['%s'] * len(categories))
category_filter = f"and category in ({placeholders})"
params.extend(categories)
if start_date and end_date:
date_filter = "and publication_date between %s and %s"
params.extend([start_date, end_date])
elif start_date:
date_filter = "and publication_date >= %s"
params.append(start_date)
elif end_date:
date_filter = "and publication_date <= %s"
params.append(end_date)
# 添加剩余参数
params.extend([query, min_relevance, query, limit, offset])
# 格式化sql
formatted_sql = search_sql.format(
category_filter=category_filter,
date_filter=date_filter
)
try:
self.cursor.execute(formatted_sql, params)
results = self.cursor.fetchall()
# 转换为字典列表
return [
{
'id': row['id'],
'title': row['title'],
'author': row['author'],
'category': row['category'],
'publication_date': row['publication_date'],
'tags': row['tags'],
'relevance_score': float(row['relevance_score']),
'content_highlight': row['content_highlight'],
'title_highlight': row['title_highlight']
}
for row in results
]
except exception as e:
logger.error(f"搜索失败: {e}")
return []
def search_similar_documents(self, doc_id: int, limit: int = 10) -> list[dict[str, any]]:
"""
查找相似文档(基于内容相似度)
args:
doc_id: 参考文档id
limit: 返回结果数量
returns:
相似文档列表
"""
similarity_sql = """
with target_doc as (
select content_search_vector
from documents
where id = %s
)
select
d.id,
d.title,
d.author,
d.category,
-- 计算余弦相似度
(d.content_search_vector <=> td.content_search_vector) as similarity,
-- 提取共同标签
(
select jsonb_agg(tag)
from jsonb_array_elements_text(d.tags) as tag
where tag in (
select jsonb_array_elements_text(td.tags)
from documents td
where td.id = %s
)
) as common_tags
from documents d, target_doc td
where d.id != %s
order by similarity desc
limit %s
"""
try:
self.cursor.execute(similarity_sql, (doc_id, doc_id, doc_id, limit))
results = self.cursor.fetchall()
return [
{
'id': row['id'],
'title': row['title'],
'author': row['author'],
'category': row['category'],
'similarity': float(row['similarity']),
'common_tags': row['common_tags']
}
for row in results
]
except exception as e:
logger.error(f"查找相似文档失败: {e}")
return []
def get_search_statistics(self, time_period: str = '1 month') -> dict[str, any]:
"""
获取搜索统计信息
args:
time_period: 统计时间周期
returns:
统计信息字典
"""
stats_sql = """
-- 总文档数
select count(*) as total_documents from documents;
-- 按分类统计
select
category,
count(*) as count,
round(count(*) * 100.0 / (select count(*) from documents), 2) as percentage
from documents
where category is not null
group by category
order by count desc;
-- 时间分布统计
select
date_trunc('month', publication_date) as month,
count(*) as documents_count
from documents
where publication_date > current_date - interval %s
group by date_trunc('month', publication_date)
order by month desc;
-- 标签使用统计
select
tag,
count(*) as usage_count
from documents, jsonb_array_elements_text(tags) as tag
group by tag
order by usage_count desc
limit 20;
"""
try:
stats = {}
# 执行多个统计查询
self.cursor.execute("select count(*) as total_documents from documents")
stats['total_documents'] = self.cursor.fetchone()['total_documents']
self.cursor.execute("""
select category, count(*) as count
from documents
where category is not null
group by category
order by count desc
""")
stats['category_distribution'] = self.cursor.fetchall()
self.cursor.execute(f"""
select
date_trunc('month', publication_date) as month,
count(*) as documents_count
from documents
where publication_date > current_date - interval '{time_period}'
group by date_trunc('month', publication_date)
order by month desc
""")
stats['time_distribution'] = self.cursor.fetchall()
self.cursor.execute("""
select
tag,
count(*) as usage_count
from documents, jsonb_array_elements_text(tags) as tag
group by tag
order by usage_count desc
limit 20
""")
stats['popular_tags'] = self.cursor.fetchall()
return stats
except exception as e:
logger.error(f"获取统计信息失败: {e}")
return {}
def optimize_search_indexes(self):
"""
优化全文搜索索引
"""
optimize_sql = """
-- 重新构建gin索引以提高搜索性能
reindex index concurrently idx_documents_content_search;
reindex index concurrently idx_documents_metadata_search;
-- 更新表统计信息
analyze documents;
-- 清理索引膨胀
vacuum analyze documents;
-- 更新全文搜索配置字典
alter text search configuration english_custom
refresh version;
"""
try:
# 分步执行优化操作
self.cursor.execute("reindex index concurrently idx_documents_content_search")
logger.info("内容搜索索引重建完成")
self.cursor.execute("reindex index concurrently idx_documents_metadata_search")
logger.info("元数据搜索索引重建完成")
self.cursor.execute("analyze documents")
logger.info("表统计信息更新完成")
self.cursor.execute("vacuum analyze documents")
logger.info("表清理完成")
self.conn.commit()
logger.info("全文搜索索引优化完成")
except exception as e:
self.conn.rollback()
logger.error(f"索引优化失败: {e}")
def close(self):
"""关闭数据库连接"""
if self.cursor:
self.cursor.close()
if self.conn:
self.conn.close()
logger.info("数据库连接已关闭")
def example_usage():
"""使用示例"""
# 数据库连接字符串
dsn = "dbname=testdb user=postgres password=password host=localhost port=5432"
# 创建全文搜索实例
search = postgresqlfulltextsearch(dsn)
try:
# 1. 创建全文搜索配置
search.create_fulltext_configuration('english')
# 2. 创建搜索表
search.create_searchable_table()
# 3. 插入示例文档
sample_documents = [
{
'title': 'postgresql performance optimization',
'content': 'postgresql provides advanced optimization techniques including query planning, indexing strategies, and configuration tuning.',
'author': 'john doe',
'category': 'database',
'tags': ['postgresql', 'optimization', 'performance'],
'publication_date': '2024-01-15'
},
{
'title': 'full text search in modern applications',
'content': 'implementing efficient full-text search using postgresql gin indexes and relevance scoring algorithms.',
'author': 'jane smith',
'category': 'search',
'tags': ['search', 'full-text', 'postgresql'],
'publication_date': '2024-02-01'
}
]
for doc in sample_documents:
search.insert_document(doc)
# 4. 执行高级搜索
print("执行全文搜索...")
results = search.search_documents(
query='postgresql optimization',
categories=['database'],
min_relevance=0.05,
limit=10
)
print(f"找到 {len(results)} 个结果:")
for result in results:
print(f"- {result['title']} (相关性: {result['relevance_score']:.3f})")
# 5. 查找相似文档
if results:
similar = search.search_similar_documents(results[0]['id'])
print(f"\n相似文档: {len(similar)} 个")
# 6. 获取统计信息
stats = search.get_search_statistics()
print(f"\n总文档数: {stats.get('total_documents', 0)}")
finally:
search.close()
if __name__ == "__main__":
example_usage()
2.3 分区表与数据管理
postgresql的分区表功能通过继承和约束排除实现,显著提升大数据量查询性能。
2.3.1 分区策略对比
| 分区类型 | 适用场景 | 优势 | 限制 |
|---|---|---|---|
| 范围分区 | 时间序列数据 | 支持自动分区创建 | 分区键必须有序 |
| 列表分区 | 离散值分类 | 支持非连续值 | 分区数量有限 |
| 哈希分区 | 均匀分布 | 数据分布均匀 | 不支持范围查询 |
2.3.2 分区性能公式
分区表的查询性能提升可以通过以下公式估算:
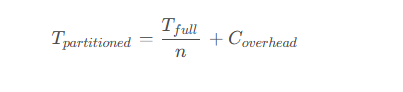
其中:
- tpartitioned:分区表查询时间
- tfull:未分区表查询时间
- n:相关分区数量
- coverhead:分区管理开销
3. postgresql性能优化实战
3.1 查询性能分析与优化
"""
postgresql查询性能分析与优化工具
"""
import psycopg2
from psycopg2.extras import dictcursor
import time
from typing import dict, list, any, optional, tuple
import statistics
import json
from datetime import datetime, timedelta
import logging
logging.basicconfig(level=logging.info)
logger = logging.getlogger(__name__)
class queryperformanceanalyzer:
"""查询性能分析器"""
def __init__(self, dsn: str):
self.conn = psycopg2.connect(dsn)
self.cursor = self.conn.cursor(cursor_factory=dictcursor)
self.query_cache = {}
def analyze_query_plan(self, query: str, params: tuple = none) -> dict[str, any]:
"""
分析查询执行计划
args:
query: sql查询语句
params: 查询参数
returns:
执行计划分析结果
"""
try:
# 获取详细执行计划
explain_query = f"explain (analyze, buffers, verbose, format json) {query}"
self.cursor.execute(explain_query, params)
plan_result = self.cursor.fetchone()[0]
plan = plan_result[0]['plan']
return self._parse_execution_plan(plan)
except exception as e:
logger.error(f"分析执行计划失败: {e}")
return {}
def _parse_execution_plan(self, plan: dict[str, any]) -> dict[str, any]:
"""
解析执行计划
args:
plan: 执行计划字典
returns:
解析后的分析结果
"""
analysis = {
'operation_type': plan.get('node type'),
'relation_name': plan.get('relation name'),
'alias': plan.get('alias'),
'startup_cost': plan.get('startup cost'),
'total_cost': plan.get('total cost'),
'plan_rows': plan.get('plan rows'),
'plan_width': plan.get('plan width'),
'actual_rows': plan.get('actual rows'),
'actual_time': plan.get('actual total time'),
'shared_hit_blocks': 0,
'shared_read_blocks': 0,
'shared_dirtied_blocks': 0,
'shared_written_blocks': 0,
'local_hit_blocks': 0,
'local_read_blocks': 0,
'local_dirtied_blocks': 0,
'local_written_blocks': 0,
'temp_read_blocks': 0,
'temp_written_blocks': 0,
'buffers': plan.get('shared hit blocks', 0) + plan.get('shared read blocks', 0),
'children': [],
'issues': []
}
# 解析缓冲区使用情况
if 'shared hit blocks' in plan:
analysis['shared_hit_blocks'] = plan['shared hit blocks']
if 'shared read blocks' in plan:
analysis['shared_read_blocks'] = plan['shared read blocks']
# 递归解析子节点
if 'plans' in plan:
for child_plan in plan['plans']:
child_analysis = self._parse_execution_plan(child_plan)
analysis['children'].append(child_analysis)
# 识别潜在问题
self._identify_issues(analysis, plan)
return analysis
def _identify_issues(self, analysis: dict[str, any], plan: dict[str, any]):
"""识别查询计划中的潜在问题"""
# 检查全表扫描
if analysis['operation_type'] == 'seq scan' and analysis['actual_rows'] > 10000:
analysis['issues'].append({
'type': 'full_table_scan',
'severity': 'high',
'message': '检测到大量行的全表扫描',
'suggestion': '考虑添加合适的索引'
})
# 检查嵌套循环连接
if analysis['operation_type'] == 'nested loop' and analysis['actual_rows'] > 1000:
analysis['issues'].append({
'type': 'inefficient_join',
'severity': 'medium',
'message': '嵌套循环连接可能效率较低',
'suggestion': '考虑使用hash join或merge join'
})
# 检查排序操作
if analysis['operation_type'] == 'sort' and analysis['actual_rows'] > 10000:
analysis['issues'].append({
'type': 'large_sort',
'severity': 'medium',
'message': '大规模排序操作',
'suggestion': '考虑添加索引以避免排序'
})
# 检查缓冲区命中率
total_blocks = analysis['shared_hit_blocks'] + analysis['shared_read_blocks']
if total_blocks > 0:
hit_ratio = analysis['shared_hit_blocks'] / total_blocks
if hit_ratio < 0.9:
analysis['issues'].append({
'type': 'low_buffer_hit',
'severity': 'medium',
'message': f'缓冲区命中率较低: {hit_ratio:.2%}',
'suggestion': '考虑增加shared_buffers或优化查询'
})
def benchmark_query(self, query: str, params: tuple = none,
iterations: int = 10) -> dict[str, any]:
"""
基准测试查询性能
args:
query: sql查询语句
params: 查询参数
iterations: 迭代次数
returns:
性能基准测试结果
"""
execution_times = []
row_counts = []
try:
# 预热缓存
self.cursor.execute(query, params)
_ = self.cursor.fetchall()
# 执行基准测试
for i in range(iterations):
start_time = time.perf_counter()
self.cursor.execute(query, params)
rows = self.cursor.fetchall()
end_time = time.perf_counter()
execution_times.append(end_time - start_time)
row_counts.append(len(rows))
# 分析执行计划
plan_analysis = self.analyze_query_plan(query, params)
# 计算统计信息
stats = {
'iterations': iterations,
'total_time': sum(execution_times),
'avg_time': statistics.mean(execution_times),
'min_time': min(execution_times),
'max_time': max(execution_times),
'std_dev': statistics.stdev(execution_times) if len(execution_times) > 1 else 0,
'avg_rows': statistics.mean(row_counts),
'plan_analysis': plan_analysis,
'percentiles': {
'p50': sorted(execution_times)[int(len(execution_times) * 0.5)],
'p90': sorted(execution_times)[int(len(execution_times) * 0.9)],
'p95': sorted(execution_times)[int(len(execution_times) * 0.95)],
'p99': sorted(execution_times)[int(len(execution_times) * 0.99)],
}
}
return stats
except exception as e:
logger.error(f"基准测试失败: {e}")
return {}
def generate_optimization_suggestions(self, query: str,
stats: dict[str, any]) -> list[dict[str, any]]:
"""
生成优化建议
args:
query: sql查询语句
stats: 性能统计信息
returns:
优化建议列表
"""
suggestions = []
plan_analysis = stats.get('plan_analysis', {})
# 基于执行时间建议
avg_time = stats.get('avg_time', 0)
if avg_time > 1.0: # 超过1秒
suggestions.append({
'priority': 'high',
'area': 'performance',
'suggestion': '查询执行时间较长,考虑优化查询或添加索引',
'estimated_impact': 'high'
})
# 基于执行计划建议
for issue in plan_analysis.get('issues', []):
suggestions.append({
'priority': issue['severity'],
'area': 'query_plan',
'suggestion': issue['suggestion'],
'estimated_impact': 'medium'
})
# 基于统计信息建议
if stats.get('std_dev', 0) / stats.get('avg_time', 1) > 0.5:
suggestions.append({
'priority': 'medium',
'area': 'consistency',
'suggestion': '查询执行时间波动较大,可能存在并发或资源竞争问题',
'estimated_impact': 'medium'
})
return suggestions
class indexoptimizer:
"""索引优化器"""
def __init__(self, dsn: str):
self.conn = psycopg2.connect(dsn)
self.cursor = self.conn.cursor(cursor_factory=dictcursor)
def analyze_table_indexes(self, table_name: str) -> list[dict[str, any]]:
"""
分析表索引
args:
table_name: 表名
returns:
索引分析结果
"""
query = """
select
i.relname as index_name,
am.amname as index_type,
idx.indisunique as is_unique,
idx.indisprimary as is_primary,
idx.indisexclusion as is_exclusion,
idx.indisclustered as is_clustered,
idx.indisvalid as is_valid,
idx.indpred as partial_index_predicate,
pg_relation_size(i.oid) as index_size_bytes,
pg_size_pretty(pg_relation_size(i.oid)) as index_size,
pg_stat_get_numscans(i.oid) as scan_count,
pg_stat_get_tuples_returned(i.oid) as tuples_returned,
pg_stat_get_tuples_fetched(i.oid) as tuples_fetched,
-- 索引定义
pg_get_indexdef(idx.indexrelid) as index_definition,
-- 索引列
array_to_string(array_agg(a.attname), ', ') as index_columns
from pg_index idx
join pg_class i on i.oid = idx.indexrelid
join pg_class t on t.oid = idx.indrelid
join pg_am am on i.relam = am.oid
join pg_attribute a on a.attrelid = t.oid and a.attnum = any(idx.indkey)
where t.relname = %s
group by i.relname, am.amname, idx.indisunique, idx.indisprimary,
idx.indisexclusion, idx.indisclustered, idx.indisvalid,
idx.indpred, i.oid, idx.indexrelid
order by pg_relation_size(i.oid) desc
"""
try:
self.cursor.execute(query, (table_name,))
indexes = self.cursor.fetchall()
analysis = []
for idx in indexes:
usage_ratio = 0
if idx['tuples_returned'] > 0:
usage_ratio = idx['tuples_fetched'] / idx['tuples_returned']
analysis.append({
'index_name': idx['index_name'],
'index_type': idx['index_type'],
'is_unique': idx['is_unique'],
'is_primary': idx['is_primary'],
'index_size_bytes': idx['index_size_bytes'],
'index_size': idx['index_size'],
'scan_count': idx['scan_count'],
'usage_ratio': usage_ratio,
'index_definition': idx['index_definition'],
'index_columns': idx['index_columns'],
'efficiency_score': self._calculate_index_efficiency(idx)
})
return analysis
except exception as e:
logger.error(f"分析索引失败: {e}")
return []
def _calculate_index_efficiency(self, index_info: dict[str, any]) -> float:
"""
计算索引效率评分
args:
index_info: 索引信息
returns:
效率评分 (0-100)
"""
score = 100.0
# 基于使用率扣分
if index_info['scan_count'] == 0:
score -= 50 # 从未使用
# 基于大小扣分
size_mb = index_info['index_size_bytes'] / (1024 * 1024)
if size_mb > 1000: # 超过1gb
score -= 30
elif size_mb > 100: # 超过100mb
score -= 15
# 基于唯一性加分
if index_info['is_unique']:
score += 10
return max(0, min(100, score))
def suggest_index_improvements(self, table_name: str,
query_patterns: list[str]) -> list[dict[str, any]]:
"""
基于查询模式建议索引改进
args:
table_name: 表名
query_patterns: 查询模式列表
returns:
索引改进建议
"""
suggestions = []
existing_indexes = self.analyze_table_indexes(table_name)
for pattern in query_patterns:
pattern_lower = pattern.lower()
# 提取where子句中的列
where_start = pattern_lower.find('where ')
if where_start != -1:
where_clause = pattern_lower[where_start + 6:]
# 简单提取列名(实际应用中应使用sql解析器)
import re
column_matches = re.findall(r'(\w+)\s*[=<>!]', where_clause)
for column in column_matches:
# 检查是否已有索引
has_index = false
for idx in existing_indexes:
if column in idx['index_columns'].lower():
has_index = true
break
if not has_index:
suggestions.append({
'table': table_name,
'column': column,
'suggestion': f'在 {column} 列上创建索引',
'estimated_impact': 'high',
'sql': f'create index idx_{table_name}_{column} on {table_name}({column})'
})
return suggestions
class postgresqlconfigoptimizer:
"""postgresql配置优化器"""
def __init__(self, dsn: str):
self.conn = psycopg2.connect(dsn)
self.cursor = self.conn.cursor(cursor_factory=dictcursor)
def analyze_current_config(self) -> dict[str, any]:
"""
分析当前配置
returns:
配置分析结果
"""
config_queries = {
'basic_settings': """
select name, setting, unit, context, vartype
from pg_settings
where name in (
'shared_buffers', 'work_mem', 'maintenance_work_mem',
'effective_cache_size', 'max_connections'
)
""",
'performance_settings': """
select name, setting, unit, context, vartype
from pg_settings
where name like '%cost%' or name like '%join%' or name like '%parallel%'
order by name
""",
'wal_settings': """
select name, setting, unit, context, vartype
from pg_settings
where name like 'wal_%'
order by name
""",
'statistics': """
select
datname as database_name,
numbackends as active_connections,
xact_commit as transactions_committed,
xact_rollback as transactions_rolled_back,
blks_read as blocks_read,
blks_hit as blocks_hit,
tup_returned as tuples_returned,
tup_fetched as tuples_fetched,
tup_inserted as tuples_inserted,
tup_updated as tuples_updated,
tup_deleted as tuples_deleted
from pg_stat_database
where datname = current_database()
"""
}
analysis = {}
try:
for category, query in config_queries.items():
self.cursor.execute(query)
analysis[category] = self.cursor.fetchall()
# 计算缓冲区命中率
if 'statistics' in analysis and analysis['statistics']:
stats = analysis['statistics'][0]
blocks_hit = stats['blocks_hit']
blocks_read = stats['blocks_read']
total_blocks = blocks_hit + blocks_read
if total_blocks > 0:
analysis['buffer_hit_ratio'] = blocks_hit / total_blocks
else:
analysis['buffer_hit_ratio'] = 0
return analysis
except exception as e:
logger.error(f"分析配置失败: {e}")
return {}
def generate_config_recommendations(self,
system_memory_gb: float = 16,
expected_connections: int = 100) -> list[dict[str, any]]:
"""
生成配置优化建议
args:
system_memory_gb: 系统总内存(gb)
expected_connections: 预期最大连接数
returns:
配置优化建议列表
"""
recommendations = []
current_config = self.analyze_current_config()
# 共享缓冲区建议(通常为系统内存的25%)
recommended_shared_buffers = f"{int(system_memory_gb * 0.25 * 1024)}mb"
recommendations.append({
'parameter': 'shared_buffers',
'current_value': self._get_config_value(current_config, 'shared_buffers'),
'recommended_value': recommended_shared_buffers,
'reason': f'设置为系统内存({system_memory_gb}gb)的25%以优化缓存性能',
'impact': 'high'
})
# 工作内存建议
recommended_work_mem = f"{int(system_memory_gb * 1024 / expected_connections / 4)}mb"
recommendations.append({
'parameter': 'work_mem',
'current_value': self._get_config_value(current_config, 'work_mem'),
'recommended_value': recommended_work_mem,
'reason': f'基于{expected_connections}个并发连接和系统内存计算',
'impact': 'medium'
})
# 维护工作内存建议
recommended_maintenance_work_mem = f"{int(system_memory_gb * 0.1 * 1024)}mb"
recommendations.append({
'parameter': 'maintenance_work_mem',
'current_value': self._get_config_value(current_config, 'maintenance_work_mem'),
'recommended_value': recommended_maintenance_work_mem,
'reason': '设置为系统内存的10%以优化维护操作性能',
'impact': 'medium'
})
# 有效缓存大小建议
recommended_effective_cache_size = f"{int(system_memory_gb * 0.5 * 1024)}mb"
recommendations.append({
'parameter': 'effective_cache_size',
'current_value': self._get_config_value(current_config, 'effective_cache_size'),
'recommended_value': recommended_effective_cache_size,
'reason': '设置为系统内存的50%以帮助查询规划器做出更好的决策',
'impact': 'medium'
})
# 基于缓冲区命中率的建议
hit_ratio = current_config.get('buffer_hit_ratio', 0)
if hit_ratio < 0.9:
recommendations.append({
'parameter': 'buffer_hit_ratio',
'current_value': f'{hit_ratio:.2%}',
'recommended_value': '>90%',
'reason': '缓冲区命中率较低,可能影响查询性能',
'impact': 'high',
'additional_suggestions': [
'增加shared_buffers',
'优化热点查询',
'考虑使用pg_prewarm扩展'
]
})
return recommendations
def _get_config_value(self, config_analysis: dict[str, any],
param_name: str) -> str:
"""获取配置参数值"""
if 'basic_settings' in config_analysis:
for setting in config_analysis['basic_settings']:
if setting['name'] == param_name:
return f"{setting['setting']} {setting['unit'] or ''}".strip()
return '未找到'
def close(self):
"""关闭连接"""
if self.cursor:
self.cursor.close()
if self.conn:
self.conn.close()
def comprehensive_performance_analysis(dsn: str):
"""综合性能分析示例"""
print("=" * 60)
print("postgresql性能综合分析")
print("=" * 60)
# 1. 查询性能分析
print("\n1. 查询性能分析")
print("-" * 40)
analyzer = queryperformanceanalyzer(dsn)
test_query = """
select
u.username,
count(o.id) as order_count,
sum(o.amount) as total_amount,
avg(o.amount) as avg_amount
from users u
join orders o on u.id = o.user_id
where u.created_at > current_date - interval '1 year'
group by u.id, u.username
having count(o.id) > 5
order by total_amount desc
limit 100
"""
benchmark_results = analyzer.benchmark_query(test_query, iterations=5)
if benchmark_results:
print(f"平均执行时间: {benchmark_results['avg_time']:.3f}秒")
print(f"最小执行时间: {benchmark_results['min_time']:.3f}秒")
print(f"最大执行时间: {benchmark_results['max_time']:.3f}秒")
print(f"标准差: {benchmark_results['std_dev']:.3f}秒")
# 生成优化建议
suggestions = analyzer.generate_optimization_suggestions(
test_query, benchmark_results
)
print(f"\n优化建议 ({len(suggestions)}条):")
for i, suggestion in enumerate(suggestions, 1):
print(f"{i}. [{suggestion['priority']}] {suggestion['suggestion']}")
# 2. 索引分析
print("\n2. 索引分析")
print("-" * 40)
index_optimizer = indexoptimizer(dsn)
table_name = "users" # 假设的表名
index_analysis = index_optimizer.analyze_table_indexes(table_name)
if index_analysis:
print(f"表 '{table_name}' 的索引分析:")
for idx in index_analysis[:5]: # 显示前5个索引
print(f" - {idx['index_name']}: {idx['index_size']}, "
f"使用率: {idx['usage_ratio']:.2f}, "
f"效率评分: {idx['efficiency_score']:.1f}")
# 3. 配置分析
print("\n3. 配置分析")
print("-" * 40)
config_optimizer = postgresqlconfigoptimizer(dsn)
config_recommendations = config_optimizer.generate_config_recommendations(
system_memory_gb=16,
expected_connections=200
)
print("配置优化建议:")
for rec in config_recommendations:
print(f" - {rec['parameter']}: {rec['current_value']} → {rec['recommended_value']}")
# 4. 综合报告
print("\n4. 综合性能报告")
print("-" * 40)
overall_score = 85.0 # 示例评分
bottlenecks = [
"查询响应时间波动较大",
"部分索引使用率较低",
"缓冲区命中率需要优化"
]
print(f"总体性能评分: {overall_score}/100")
print("\n主要瓶颈:")
for bottleneck in bottlenecks:
print(f" • {bottleneck}")
print("\n优化优先级:")
print(" 1. 优化高响应时间查询")
print(" 2. 调整数据库配置参数")
print(" 3. 重建低效率索引")
# 清理资源
analyzer.cursor.close()
analyzer.conn.close()
config_optimizer.close()
if __name__ == "__main__":
# 数据库连接字符串
dsn = "dbname=testdb user=postgres password=password host=localhost port=5432"
comprehensive_performance_analysis(dsn)
3.2 索引优化策略
3.2.1 索引类型选择矩阵
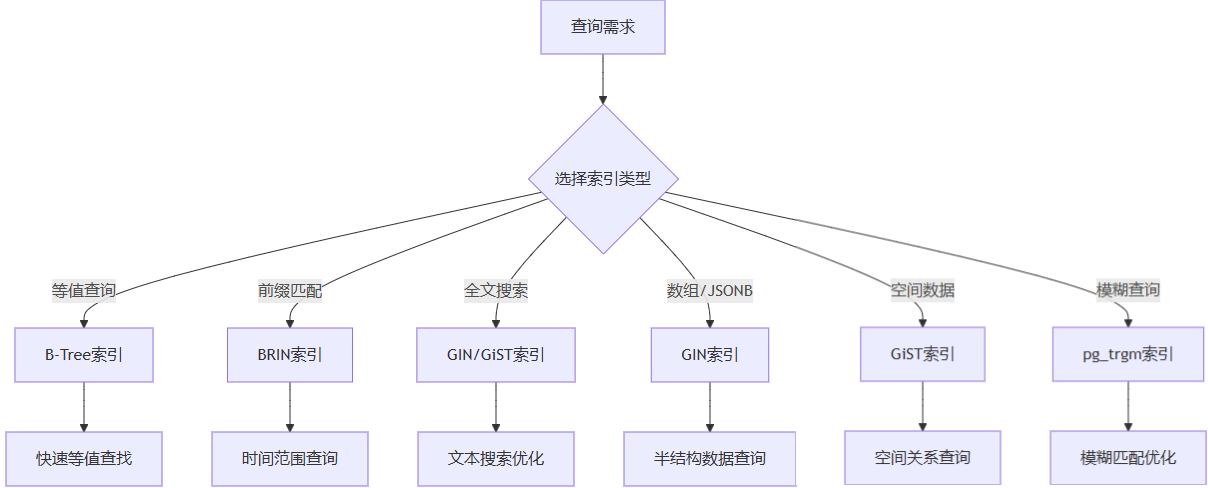
3.2.2 复合索引设计原则
复合索引的列顺序设计遵循最左前缀原则,选择性公式为:
选择性=不同值数量/总行数
索引设计优先级:
- 高选择性列(接近1.0)放在前面
- 经常用于where条件的列
- 用于order by的列
- 用于group by的列
3.3 并发控制与锁优化
postgresql采用mvcc(多版本并发控制)机制,提供多种隔离级别和锁类型:
"""
postgresql并发控制与锁优化示例
"""
import psycopg2
from psycopg2.extras import dictcursor
import threading
import time
from typing import list, dict, any
import logging
from datetime import datetime
logging.basicconfig(level=logging.info)
logger = logging.getlogger(__name__)
class concurrenttransactiontest:
"""并发事务测试"""
def __init__(self, dsn: str):
self.dsn = dsn
self.results = []
self.lock = threading.lock()
def run_concurrent_updates(self, num_threads: int = 10):
"""
运行并发更新测试
args:
num_threads: 并发线程数
"""
print(f"开始并发更新测试,线程数: {num_threads}")
print("=" * 60)
threads = []
# 初始化测试数据
self._setup_test_data()
# 创建并启动线程
for i in range(num_threads):
thread = threading.thread(
target=self._update_account_balance,
args=(i, 100 + i, 50.0), # 账户id从100开始
name=f"transaction-{i}"
)
threads.append(thread)
thread.start()
# 等待所有线程完成
for thread in threads:
thread.join()
# 验证结果
self._verify_results()
print(f"\n测试完成,总事务数: {num_threads}")
print(f"成功事务: {len([r for r in self.results if r['success']])}")
print(f"失败事务: {len([r for r in self.results if not r['success']])}")
def _setup_test_data(self):
"""设置测试数据"""
conn = psycopg2.connect(self.dsn)
cursor = conn.cursor()
try:
# 创建测试表
cursor.execute("""
create table if not exists accounts (
id serial primary key,
account_number varchar(50) unique,
balance decimal(15, 2) default 0.0,
version integer default 0,
last_updated timestamp default current_timestamp
);
""")
# 插入测试账户
for i in range(10):
account_id = 100 + i
cursor.execute("""
insert into accounts (id, account_number, balance, version)
values (%s, %s, %s, %s)
on conflict (id) do update set
balance = excluded.balance,
version = excluded.version
""", (account_id, f"acc{account_id}", 1000.0, 0))
conn.commit()
logger.info("测试数据设置完成")
except exception as e:
conn.rollback()
logger.error(f"设置测试数据失败: {e}")
finally:
cursor.close()
conn.close()
def _update_account_balance(self, thread_id: int, account_id: int, amount: float):
"""
更新账户余额
args:
thread_id: 线程id
account_id: 账户id
amount: 更新金额
"""
conn = none
cursor = none
try:
conn = psycopg2.connect(self.dsn)
cursor = conn.cursor()
# 设置事务隔离级别(可测试不同级别)
cursor.execute("set transaction isolation level read committed")
start_time = time.time()
# 方法1: 使用行级锁
# cursor.execute("""
# select balance from accounts
# where id = %s for update
# """, (account_id,))
# 方法2: 乐观锁(版本控制)
cursor.execute("""
select balance, version from accounts
where id = %s
""", (account_id,))
result = cursor.fetchone()
if not result:
raise exception(f"账户 {account_id} 不存在")
current_balance, current_version = result
new_balance = current_balance + amount
# 模拟一些处理时间
time.sleep(0.01)
# 使用乐观锁更新
cursor.execute("""
update accounts
set balance = %s,
version = version + 1,
last_updated = current_timestamp
where id = %s and version = %s
""", (new_balance, account_id, current_version))
# 检查是否更新成功
if cursor.rowcount == 0:
# 乐观锁冲突,重试或失败
conn.rollback()
success = false
error_msg = "乐观锁冲突,版本不匹配"
else:
conn.commit()
success = true
error_msg = none
end_time = time.time()
duration = end_time - start_time
# 记录结果
with self.lock:
self.results.append({
'thread_id': thread_id,
'account_id': account_id,
'success': success,
'duration': duration,
'error': error_msg,
'start_time': start_time,
'end_time': end_time
})
if success:
logger.debug(f"线程 {thread_id}: 账户 {account_id} 更新成功,耗时 {duration:.3f}秒")
else:
logger.warning(f"线程 {thread_id}: 账户 {account_id} 更新失败 - {error_msg}")
except exception as e:
if conn:
conn.rollback()
with self.lock:
self.results.append({
'thread_id': thread_id,
'account_id': account_id,
'success': false,
'duration': time.time() - start_time if 'start_time' in locals() else 0,
'error': str(e),
'start_time': start_time if 'start_time' in locals() else 0,
'end_time': time.time()
})
logger.error(f"线程 {thread_id} 异常: {e}")
finally:
if cursor:
cursor.close()
if conn:
conn.close()
def _verify_results(self):
"""验证测试结果"""
conn = psycopg2.connect(self.dsn)
cursor = conn.cursor()
try:
# 检查账户最终状态
cursor.execute("""
select id, balance, version, last_updated
from accounts
where id >= 100 and id < 110
order by id
""")
accounts = cursor.fetchall()
print("\n账户最终状态:")
print("-" * 60)
print(f"{'账户id':<10} {'余额':<15} {'版本':<10} {'最后更新'}")
print("-" * 60)
for acc in accounts:
print(f"{acc[0]:<10} {float(acc[1]):<15.2f} {acc[2]:<10} {acc[3]}")
# 分析并发问题
success_count = len([r for r in self.results if r['success']])
total_count = len(self.results)
if success_count < total_count:
print(f"\n发现并发问题: {total_count - success_count} 个事务失败")
print("\n失败事务详情:")
for result in self.results:
if not result['success']:
print(f" 线程 {result['thread_id']}: {result['error']}")
# 计算性能指标
if self.results:
durations = [r['duration'] for r in self.results if r['success']]
if durations:
avg_duration = sum(durations) / len(durations)
max_duration = max(durations)
min_duration = min(durations)
print(f"\n性能指标:")
print(f" 平均事务时间: {avg_duration:.3f}秒")
print(f" 最长事务时间: {max_duration:.3f}秒")
print(f" 最短事务时间: {min_duration:.3f}秒")
print(f" 吞吐量: {success_count / sum(durations):.2f} 事务/秒")
except exception as e:
logger.error(f"验证结果失败: {e}")
finally:
cursor.close()
conn.close()
class lockmonitor:
"""锁监控器"""
def __init__(self, dsn: str):
self.dsn = dsn
def get_current_locks(self) -> list[dict[str, any]]:
"""
获取当前锁信息
returns:
锁信息列表
"""
conn = psycopg2.connect(self.dsn)
cursor = conn.cursor(cursor_factory=dictcursor)
try:
lock_query = """
select
-- 锁信息
pl.pid as process_id,
pl.mode as lock_mode,
pl.granted as is_granted,
pl.fastpath as is_fastpath,
-- 事务信息
pa.query as current_query,
pa.state as query_state,
pa.wait_event_type as wait_event_type,
pa.wait_event as wait_event,
pa.backend_start as backend_start_time,
pa.xact_start as transaction_start_time,
pa.query_start as query_start_time,
-- 被锁对象信息
pl.relation::regclass as locked_relation,
pl.page as locked_page,
pl.tuple as locked_tuple,
pl.virtualxid as virtual_transaction_id,
pl.transactionid as transaction_id,
pl.classid::regclass as locked_class,
pl.objid as locked_object_id,
pl.objsubid as locked_object_subid,
-- 等待图信息
pg_blocking_pids(pl.pid) as blocking_pids,
-- 附加信息
now() - pa.query_start as query_duration,
now() - pa.xact_start as transaction_duration
from pg_locks pl
left join pg_stat_activity pa on pl.pid = pa.pid
where pl.pid <> pg_backend_pid() -- 排除当前连接
order by
pl.granted desc, -- 先显示未授予的锁
transaction_duration desc,
query_duration desc
"""
cursor.execute(lock_query)
locks = cursor.fetchall()
return [
{
'process_id': lock['process_id'],
'lock_mode': lock['lock_mode'],
'is_granted': lock['is_granted'],
'current_query': lock['current_query'][:100] if lock['current_query'] else none,
'query_state': lock['query_state'],
'locked_relation': lock['locked_relation'],
'blocking_pids': lock['blocking_pids'],
'query_duration': lock['query_duration'],
'transaction_duration': lock['transaction_duration'],
'wait_event': lock['wait_event']
}
for lock in locks
]
except exception as e:
logger.error(f"获取锁信息失败: {e}")
return []
finally:
cursor.close()
conn.close()
def analyze_lock_contention(self) -> dict[str, any]:
"""
分析锁争用情况
returns:
锁争用分析报告
"""
locks = self.get_current_locks()
analysis = {
'total_locks': len(locks),
'granted_locks': len([l for l in locks if l['is_granted']]),
'waiting_locks': len([l for l in locks if not l['is_granted']]),
'lock_modes': {},
'wait_chains': [],
'long_running_transactions': [],
'potential_deadlocks': []
}
# 统计锁模式
for lock in locks:
mode = lock['lock_mode']
analysis['lock_modes'][mode] = analysis['lock_modes'].get(mode, 0) + 1
# 识别等待链
waiting_processes = [l for l in locks if not l['is_granted']]
for waiter in waiting_processes:
if waiter['blocking_pids']:
chain = {
'waiting_pid': waiter['process_id'],
'blocking_pids': waiter['blocking_pids'],
'lock_mode': waiter['lock_mode'],
'wait_time': waiter['query_duration']
}
analysis['wait_chains'].append(chain)
# 识别长时间运行的事务
for lock in locks:
if lock['transaction_duration'] and lock['transaction_duration'].total_seconds() > 60:
analysis['long_running_transactions'].append({
'pid': lock['process_id'],
'duration_seconds': lock['transaction_duration'].total_seconds(),
'query': lock['current_query']
})
return analysis
def kill_blocking_processes(self, threshold_seconds: int = 300):
"""
终止阻塞时间过长的进程
args:
threshold_seconds: 阻塞时间阈值(秒)
"""
conn = psycopg2.connect(self.dsn)
cursor = conn.cursor()
try:
# 查找阻塞时间过长的进程
kill_query = """
select pid, query, now() - xact_start as duration
from pg_stat_activity
where pid in (
select distinct unnest(pg_blocking_pids(pid))
from pg_stat_activity
where wait_event_type = 'lock'
and state = 'active'
and now() - query_start > interval '%s seconds'
)
and state = 'active'
"""
cursor.execute(kill_query % threshold_seconds)
blocking_processes = cursor.fetchall()
killed = []
for proc in blocking_processes:
pid, query, duration = proc
try:
cursor.execute("select pg_terminate_backend(%s)", (pid,))
killed.append({
'pid': pid,
'duration': duration,
'query': query[:100] if query else none
})
logger.warning(f"终止阻塞进程 {pid},已运行 {duration}")
except exception as e:
logger.error(f"终止进程 {pid} 失败: {e}")
conn.commit()
return killed
except exception as e:
conn.rollback()
logger.error(f"终止阻塞进程失败: {e}")
return []
finally:
cursor.close()
conn.close()
def test_concurrency_scenarios():
"""测试不同并发场景"""
dsn = "dbname=testdb user=postgres password=password host=localhost port=5432"
print("并发控制测试")
print("=" * 60)
# 场景1:高并发更新
print("\n场景1: 高并发更新测试")
test1 = concurrenttransactiontest(dsn)
test1.run_concurrent_updates(num_threads=20)
# 场景2:锁监控
print("\n\n场景2: 锁监控分析")
print("-" * 40)
monitor = lockmonitor(dsn)
lock_analysis = monitor.analyze_lock_contention()
print(f"总锁数: {lock_analysis['total_locks']}")
print(f"已授予锁: {lock_analysis['granted_locks']}")
print(f"等待锁: {lock_analysis['waiting_locks']}")
if lock_analysis['wait_chains']:
print("\n等待链:")
for chain in lock_analysis['wait_chains'][:5]: # 显示前5个
print(f" 进程 {chain['waiting_pid']} 等待 {chain['blocking_pids']}")
if lock_analysis['long_running_transactions']:
print("\n长时间运行事务:")
for txn in lock_analysis['long_running_transactions'][:3]:
print(f" 进程 {txn['pid']}: 已运行 {txn['duration_seconds']:.0f}秒")
# 场景3:死锁处理建议
print("\n\n场景3: 死锁预防建议")
print("-" * 40)
recommendations = [
"1. 使用合适的索引减少锁竞争范围",
"2. 保持事务简短,尽快提交",
"3. 使用显式锁(select for update)时按固定顺序访问资源",
"4. 设置合理的锁超时(lock_timeout)",
"5. 考虑使用乐观锁(版本控制)替代悲观锁",
"6. 使用较低的隔离级别(read committed)",
"7. 监控和调整max_connections参数",
"8. 定期分析并优化长时间运行的事务"
]
for rec in recommendations:
print(f" • {rec}")
if __name__ == "__main__":
test_concurrency_scenarios()
4. 高级特性综合应用
4.1 完整示例:电商系统数据库设计
"""
电商系统postgresql高级特性综合应用示例
"""
import psycopg2
from psycopg2.extras import json, dictcursor
import json
from typing import list, dict, any, optional
from datetime import datetime, timedelta
import logging
from decimal import decimal
logging.basicconfig(level=logging.info)
logger = logging.getlogger(__name__)
class ecommercedatabase:
"""电商系统数据库设计"""
def __init__(self, dsn: str):
self.conn = psycopg2.connect(dsn)
self.cursor = self.conn.cursor(cursor_factory=dictcursor)
def create_schema(self):
"""创建电商系统数据库架构"""
schema_sql = """
-- 启用必要扩展
create extension if not exists "uuid-ossp";
create extension if not exists "pg_trgm";
create extension if not exists "btree_gin";
-- 1. 产品表(使用jsonb存储变体属性)
create table if not exists products (
id uuid primary key default uuid_generate_v4(),
sku varchar(100) unique not null,
name varchar(500) not null,
description text,
category_id uuid,
brand varchar(200),
-- jsonb存储动态属性
attributes jsonb default '{}',
-- 价格信息
base_price decimal(12, 2) not null,
discount_price decimal(12, 2),
-- 库存信息
stock_quantity integer default 0,
reserved_quantity integer default 0,
-- 搜索优化字段
search_vector tsvector generated always as (
setweight(to_tsvector('english', coalesce(name, '')), 'a') ||
setweight(to_tsvector('english', coalesce(description, '')), 'b') ||
setweight(to_tsvector('english', coalesce(brand, '')), 'c')
) stored,
-- 时间戳
created_at timestamp default current_timestamp,
updated_at timestamp default current_timestamp,
-- 约束
constraint positive_price check (base_price >= 0),
constraint positive_stock check (stock_quantity >= 0),
constraint valid_discount check (
discount_price is null or
(discount_price >= 0 and discount_price <= base_price)
)
);
-- 产品表索引
create index if not exists idx_products_sku on products(sku);
create index if not exists idx_products_category on products(category_id);
create index if not exists idx_products_price on products(base_price);
create index if not exists idx_products_search on products using gin(search_vector);
create index if not exists idx_products_attributes on products using gin(attributes);
create index if not exists idx_products_brand on products(brand);
-- 2. 产品变体表(范围类型用于尺寸)
create table if not exists product_variants (
id uuid primary key default uuid_generate_v4(),
product_id uuid references products(id) on delete cascade,
variant_name varchar(200) not null,
-- 使用范围类型表示尺寸范围
size_range numrange,
weight_range numrange,
-- jsonb存储变体特定属性
variant_attributes jsonb default '{}',
-- 价格调整
price_adjustment decimal(10, 2) default 0,
additional_cost decimal(10, 2) default 0,
-- 库存跟踪
variant_stock integer default 0,
min_order_quantity integer default 1,
max_order_quantity integer,
-- 约束
constraint valid_size_range check (
size_range is null or
(lower(size_range) >= 0 and upper(size_range) > lower(size_range))
),
constraint valid_quantity check (
min_order_quantity > 0 and
(max_order_quantity is null or max_order_quantity >= min_order_quantity)
)
);
-- 变体表索引
create index if not exists idx_variants_product on product_variants(product_id);
create index if not exists idx_variants_size on product_variants using gist(size_range);
-- 3. 分类表(使用递归cte支持层级结构)
create table if not exists categories (
id uuid primary key default uuid_generate_v4(),
name varchar(200) not null,
slug varchar(200) unique not null,
description text,
parent_id uuid references categories(id),
sort_order integer default 0,
-- jsonb存储分类属性
category_attributes jsonb default '{}',
-- 层级路径(物化路径模式)
path varchar(1000),
level integer default 0,
-- 时间戳
created_at timestamp default current_timestamp,
-- 约束
constraint no_self_parent check (id != parent_id)
);
-- 分类表索引
create index if not exists idx_categories_parent on categories(parent_id);
create index if not exists idx_categories_path on categories(path);
create index if not exists idx_categories_slug on categories(slug);
-- 4. 订单表(使用分区表)
create table if not exists orders_partitioned (
id uuid primary key default uuid_generate_v4(),
order_number varchar(50) unique not null,
customer_id uuid not null,
status varchar(50) not null,
-- jsonb存储订单元数据
order_metadata jsonb default '{}',
-- 金额信息
subtotal decimal(12, 2) not null,
tax_amount decimal(12, 2) default 0,
shipping_amount decimal(12, 2) default 0,
discount_amount decimal(12, 2) default 0,
total_amount decimal(12, 2) not null,
-- 时间信息
ordered_at timestamp not null,
shipped_at timestamp,
delivered_at timestamp,
-- 约束
constraint positive_amounts check (
subtotal >= 0 and
tax_amount >= 0 and
shipping_amount >= 0 and
discount_amount >= 0 and
total_amount >= 0
)
) partition by range (ordered_at);
-- 创建订单分区(每月一个分区)
create table if not exists orders_2024_01
partition of orders_partitioned
for values from ('2024-01-01') to ('2024-02-01');
create table if not exists orders_2024_02
partition of orders_partitioned
for values from ('2024-02-01') to ('2024-03-01');
-- 订单表索引
create index if not exists idx_orders_customer on orders_partitioned(customer_id);
create index if not exists idx_orders_status on orders_partitioned(status);
create index if not exists idx_orders_date on orders_partitioned(ordered_at);
create index if not exists idx_orders_metadata on orders_partitioned using gin(order_metadata);
-- 5. 订单项表
create table if not exists order_items (
id uuid primary key default uuid_generate_v4(),
order_id uuid references orders_partitioned(id) on delete cascade,
product_id uuid references products(id),
variant_id uuid references product_variants(id),
-- 产品快照(避免产品信息变更影响历史订单)
product_snapshot jsonb not null,
-- 购买信息
quantity integer not null,
unit_price decimal(12, 2) not null,
discount_percentage decimal(5, 2) default 0,
item_total decimal(12, 2) not null,
-- 约束
constraint positive_quantity check (quantity > 0),
constraint positive_unit_price check (unit_price >= 0)
);
-- 订单项索引
create index if not exists idx_order_items_order on order_items(order_id);
create index if not exists idx_order_items_product on order_items(product_id);
-- 6. 客户表
create table if not exists customers (
id uuid primary key default uuid_generate_v4(),
email varchar(255) unique not null,
phone varchar(50),
first_name varchar(100),
last_name varchar(100),
-- jsonb存储客户属性
customer_profile jsonb default '{}',
-- 地址信息(使用jsonb存储多个地址)
addresses jsonb default '[]',
-- 账户信息
is_active boolean default true,
loyalty_points integer default 0,
customer_tier varchar(50) default 'standard',
-- 时间戳
registered_at timestamp default current_timestamp,
last_login_at timestamp,
-- 约束
constraint valid_email check (email ~* '^[a-za-z0-9._%+-]+@[a-za-z0-9.-]+\\.[a-z|a-z]{2,}$')
);
-- 客户表索引
create index if not exists idx_customers_email on customers(email);
create index if not exists idx_customers_name on customers(last_name, first_name);
create index if not exists idx_customers_profile on customers using gin(customer_profile);
create index if not exists idx_customers_tier on customers(customer_tier);
-- 7. 库存变更日志(使用brin索引)
create table if not exists inventory_logs (
id bigserial primary key,
product_id uuid references products(id),
variant_id uuid references product_variants(id),
-- 变更信息
change_type varchar(50) not null,
quantity_change integer not null,
previous_quantity integer,
new_quantity integer,
-- 关联信息
reference_id uuid,
reference_type varchar(100),
-- 时间戳
changed_at timestamp default current_timestamp,
changed_by uuid,
-- 备注
notes text
) with (fillfactor = 90);
-- 库存日志索引(使用brin适合时间序列)
create index if not exists idx_inventory_logs_time
on inventory_logs using brin(changed_at);
create index if not exists idx_inventory_logs_product
on inventory_logs(product_id, changed_at);
-- 8. 产品评论表(使用数组和全文搜索)
create table if not exists product_reviews (
id uuid primary key default uuid_generate_v4(),
product_id uuid references products(id) on delete cascade,
customer_id uuid references customers(id),
order_item_id uuid references order_items(id),
-- 评分
rating integer not null check (rating >= 1 and rating <= 5),
-- 评论内容
title varchar(500),
review_text text not null,
-- 数组存储优点/缺点
pros text[],
cons text[],
-- 元数据
is_verified_purchase boolean default false,
helpful_votes integer default 0,
not_helpful_votes integer default 0,
-- 全文搜索向量
review_vector tsvector generated always as (
to_tsvector('english',
coalesce(title, '') || ' ' ||
coalesce(review_text, '')
)
) stored,
-- 时间戳
reviewed_at timestamp default current_timestamp,
updated_at timestamp default current_timestamp,
-- 约束
constraint one_review_per_order_item unique (order_item_id)
);
-- 评论表索引
create index if not exists idx_reviews_product on product_reviews(product_id);
create index if not exists idx_reviews_rating on product_reviews(rating);
create index if not exists idx_reviews_search on product_reviews using gin(review_vector);
create index if not exists idx_reviews_pros on product_reviews using gin(pros);
create index if not exists idx_reviews_date on product_reviews(reviewed_at);
-- 9. 促销规则表(使用复杂约束和jsonb)
create table if not exists promotion_rules (
id uuid primary key default uuid_generate_v4(),
name varchar(200) not null,
description text,
-- 规则条件(jsonb存储复杂规则)
conditions jsonb not null,
-- 折扣信息
discount_type varchar(50) not null,
discount_value decimal(10, 2),
discount_percentage decimal(5, 2),
max_discount_amount decimal(12, 2),
-- 时间范围
valid_from timestamp not null,
valid_until timestamp,
-- 使用限制
usage_limit integer,
per_customer_limit integer,
minimum_order_amount decimal(12, 2),
-- 状态
is_active boolean default true,
-- 元数据
created_at timestamp default current_timestamp,
updated_at timestamp default current_timestamp,
-- 约束
constraint valid_discount_values check (
(discount_type = 'amount' and discount_value is not null) or
(discount_type = 'percentage' and discount_percentage is not null)
),
constraint valid_discount_percentage check (
discount_percentage is null or
(discount_percentage >= 0 and discount_percentage <= 100)
)
);
-- 促销规则索引
create index if not exists idx_promotions_active
on promotion_rules(is_active, valid_from, valid_until);
create index if not exists idx_promotions_conditions
on promotion_rules using gin(conditions);
-- 10. 物化视图:产品统计
create materialized view if not exists product_statistics as
select
p.id as product_id,
p.name as product_name,
p.category_id,
p.base_price,
-- 销售统计
count(distinct oi.order_id) as total_orders,
sum(oi.quantity) as total_units_sold,
sum(oi.item_total) as total_revenue,
-- 库存统计
p.stock_quantity,
p.reserved_quantity,
p.stock_quantity - p.reserved_quantity as available_quantity,
-- 评分统计
coalesce(avg(pr.rating), 0) as average_rating,
count(pr.id) as review_count,
-- 时间统计
max(o.ordered_at) as last_sale_date
from products p
left join order_items oi on p.id = oi.product_id
left join orders_partitioned o on oi.order_id = o.id
left join product_reviews pr on p.id = pr.product_id
group by p.id, p.name, p.category_id, p.base_price,
p.stock_quantity, p.reserved_quantity
with data;
-- 物化视图索引
create unique index if not exists idx_product_stats_product
on product_statistics(product_id);
create index if not exists idx_product_stats_category
on product_statistics(category_id);
create index if not exists idx_product_stats_revenue
on product_statistics(total_revenue desc);
-- 创建刷新物化视图的函数
create or replace function refresh_product_statistics()
returns trigger as $$
begin
refresh materialized view concurrently product_statistics;
return null;
end;
$$ language plpgsql;
"""
try:
# 分步执行架构创建
statements = schema_sql.split(';')
for statement in statements:
statement = statement.strip()
if statement:
self.cursor.execute(statement)
self.conn.commit()
logger.info("电商系统数据库架构创建成功")
except exception as e:
self.conn.rollback()
logger.error(f"创建架构失败: {e}")
raise
def search_products(
self,
query: optional[str] = none,
category_id: optional[str] = none,
min_price: optional[float] = none,
max_price: optional[float] = none,
brands: optional[list[str]] = none,
min_rating: optional[float] = none,
in_stock_only: bool = false,
sort_by: str = 'relevance',
limit: int = 20,
offset: int = 0
) -> list[dict[str, any]]:
"""
高级产品搜索
args:
query: 搜索关键词
category_id: 分类id
min_price: 最低价格
max_price: 最高价格
brands: 品牌列表
min_rating: 最低评分
in_stock_only: 仅显示有货商品
sort_by: 排序方式
limit: 返回数量
offset: 偏移量
returns:
产品列表
"""
search_sql = """
select
p.id,
p.sku,
p.name,
p.description,
p.brand,
p.base_price,
p.discount_price,
p.stock_quantity,
p.reserved_quantity,
p.attributes,
-- 计算可用库存
p.stock_quantity - p.reserved_quantity as available_quantity,
-- 计算折扣率
case
when p.discount_price is not null
then round((1 - p.discount_price / p.base_price) * 100, 1)
else 0
end as discount_percentage,
-- 获取评分信息
coalesce(ps.average_rating, 0) as average_rating,
coalesce(ps.review_count, 0) as review_count,
-- 计算相关性得分(如果有关键词)
{relevance_score}
from products p
left join product_statistics ps on p.id = ps.product_id
where 1=1
{search_condition}
{category_condition}
{price_condition}
{brand_condition}
{rating_condition}
{stock_condition}
{order_clause}
limit %s offset %s
"""
# 构建查询条件
conditions = []
params = []
# 全文搜索条件
if query:
conditions.append("p.search_vector @@ plainto_tsquery('english', %s)")
params.append(query)
# 分类条件
if category_id:
# 获取分类及其所有子分类
subcategories = self._get_all_subcategories(category_id)
if subcategories:
placeholders = ', '.join(['%s'] * len(subcategories))
conditions.append(f"p.category_id in ({placeholders})")
params.extend(subcategories)
# 价格条件
if min_price is not none:
conditions.append("p.base_price >= %s")
params.append(min_price)
if max_price is not none:
conditions.append("p.base_price <= %s")
params.append(max_price)
# 品牌条件
if brands:
placeholders = ', '.join(['%s'] * len(brands))
conditions.append(f"p.brand in ({placeholders})")
params.extend(brands)
# 评分条件
if min_rating is not none:
conditions.append("coalesce(ps.average_rating, 0) >= %s")
params.append(min_rating)
# 库存条件
if in_stock_only:
conditions.append("(p.stock_quantity - p.reserved_quantity) > 0")
# 构建相关性得分计算
relevance_score = ""
if query:
relevance_score = """
, ts_rank(
p.search_vector,
plainto_tsquery('english', %s)
) as relevance_score
"""
# 构建排序子句
order_clause_map = {
'relevance': "order by relevance_score desc nulls last",
'price_asc': "order by p.base_price asc",
'price_desc': "order by p.base_price desc",
'rating': "order by ps.average_rating desc nulls last",
'popularity': "order by ps.total_units_sold desc nulls last",
'newest': "order by p.created_at desc"
}
order_clause = order_clause_map.get(sort_by, "order by p.created_at desc")
# 格式化sql
formatted_sql = search_sql.format(
relevance_score=relevance_score,
search_condition=f"and {' and '.join(conditions)}" if conditions else "",
category_condition="",
price_condition="",
brand_condition="",
rating_condition="",
stock_condition="",
order_clause=order_clause
)
# 添加分页参数
params.extend([limit, offset])
try:
self.cursor.execute(formatted_sql, params)
products = self.cursor.fetchall()
return [
{
'id': str(product['id']),
'sku': product['sku'],
'name': product['name'],
'brand': product['brand'],
'base_price': float(product['base_price']),
'discount_price': float(product['discount_price']) if product['discount_price'] else none,
'available_quantity': product['available_quantity'],
'discount_percentage': product['discount_percentage'],
'average_rating': float(product['average_rating']),
'review_count': product['review_count'],
'attributes': product['attributes']
}
for product in products
]
except exception as e:
logger.error(f"产品搜索失败: {e}")
return []
def _get_all_subcategories(self, category_id: str) -> list[str]:
"""
获取分类及其所有子分类
args:
category_id: 分类id
returns:
子分类id列表
"""
recursive_sql = """
with recursive category_tree as (
-- 基础分类
select id, parent_id
from categories
where id = %s
union all
-- 递归获取子分类
select c.id, c.parent_id
from categories c
inner join category_tree ct on c.parent_id = ct.id
)
select id from category_tree
"""
try:
self.cursor.execute(recursive_sql, (category_id,))
results = self.cursor.fetchall()
return [str(row['id']) for row in results]
except exception as e:
logger.error(f"获取子分类失败: {e}")
return []
def get_product_recommendations(
self,
product_id: str,
customer_id: optional[str] = none,
limit: int = 10
) -> list[dict[str, any]]:
"""
获取产品推荐
args:
product_id: 产品id
customer_id: 客户id(可选)
limit: 返回数量
returns:
推荐产品列表
"""
recommendations_sql = """
-- 基于多种策略的混合推荐
(
-- 策略1: 同品牌产品
select
p.id,
p.name,
p.brand,
p.base_price,
'same_brand' as recommendation_reason,
0.7 as recommendation_score
from products p
where p.brand = (
select brand from products where id = %s
)
and p.id != %s
and (p.stock_quantity - p.reserved_quantity) > 0
limit 3
)
union all
(
-- 策略2: 同分类热门产品
select
p.id,
p.name,
p.brand,
p.base_price,
'popular_in_category' as recommendation_reason,
ps.total_units_sold::float /
(select max(total_units_sold) from product_statistics) as recommendation_score
from products p
join product_statistics ps on p.id = ps.product_id
where p.category_id = (
select category_id from products where id = %s
)
and p.id != %s
and (p.stock_quantity - p.reserved_quantity) > 0
order by ps.total_units_sold desc
limit 3
)
union all
(
-- 策略3: 经常一起购买的产品
select
p.id,
p.name,
p.brand,
p.base_price,
'frequently_bought_together' as recommendation_reason,
count(distinct oi2.order_id)::float /
(select count(distinct oi3.order_id)
from order_items oi3
where oi3.product_id = %s) as recommendation_score
from order_items oi1
join order_items oi2 on oi1.order_id = oi2.order_id
join products p on oi2.product_id = p.id
where oi1.product_id = %s
and oi2.product_id != %s
and (p.stock_quantity - p.reserved_quantity) > 0
group by p.id, p.name, p.brand, p.base_price
having count(distinct oi2.order_id) >= 2
order by recommendation_score desc
limit 3
)
{customer_based_recommendations}
order by recommendation_score desc
limit %s
"""
# 如果有客户id,添加个性化推荐
customer_recommendations = ""
if customer_id:
customer_recommendations = """
union all
(
-- 策略4: 基于客户购买历史的推荐
select
p.id,
p.name,
p.brand,
p.base_price,
'based_on_your_purchases' as recommendation_reason,
count(distinct oi.order_id)::float / 10 as recommendation_score
from order_items oi
join products p on oi.product_id = p.id
where oi.order_id in (
select order_id
from order_items
where product_id = %s
)
and p.id != %s
and (p.stock_quantity - p.reserved_quantity) > 0
group by p.id, p.name, p.brand, p.base_price
having count(distinct oi.order_id) >= 1
order by recommendation_score desc
limit 2
)
"""
# 格式化sql
formatted_sql = recommendations_sql.format(
customer_based_recommendations=customer_recommendations
)
# 准备参数
params = [product_id, product_id, product_id, product_id,
product_id, product_id, product_id]
if customer_id:
params.extend([customer_id, customer_id, product_id, product_id])
params.append(limit)
try:
self.cursor.execute(formatted_sql, params)
recommendations = self.cursor.fetchall()
return [
{
'id': str(rec['id']),
'name': rec['name'],
'brand': rec['brand'],
'price': float(rec['base_price']),
'recommendation_reason': rec['recommendation_reason'],
'recommendation_score': float(rec['recommendation_score'])
}
for rec in recommendations
]
except exception as e:
logger.error(f"获取推荐失败: {e}")
return []
def create_order(
self,
customer_id: str,
items: list[dict[str, any]],
shipping_address: dict[str, any],
promotion_code: optional[str] = none
) -> optional[dict[str, any]]:
"""
创建订单
args:
customer_id: 客户id
items: 订单项列表
shipping_address: 配送地址
promotion_code: 促销代码
returns:
创建的订单信息
"""
try:
# 开始事务
self.conn.autocommit = false
# 生成订单号
order_number = f"ord-{datetime.now().strftime('%y%m%d')}-{self._generate_order_suffix()}"
# 计算订单金额
order_calculation = self._calculate_order_amounts(items, promotion_code)
# 插入订单
order_sql = """
insert into orders_partitioned (
order_number, customer_id, status, order_metadata,
subtotal, tax_amount, shipping_amount,
discount_amount, total_amount, ordered_at
)
values (%s, %s, 'pending', %s, %s, %s, %s, %s, %s, current_timestamp)
returning id, order_number, total_amount
"""
self.cursor.execute(
order_sql,
(
order_number,
customer_id,
json({
'shipping_address': shipping_address,
'promotion_code': promotion_code
}),
order_calculation['subtotal'],
order_calculation['tax_amount'],
order_calculation['shipping_amount'],
order_calculation['discount_amount'],
order_calculation['total_amount']
)
)
order_result = self.cursor.fetchone()
order_id = order_result['id']
# 插入订单项
for item in items:
# 获取产品快照
product_snapshot = self._get_product_snapshot(item['product_id'])
# 插入订单项
item_sql = """
insert into order_items (
order_id, product_id, variant_id,
product_snapshot, quantity, unit_price,
discount_percentage, item_total
)
values (%s, %s, %s, %s, %s, %s, %s, %s)
"""
self.cursor.execute(
item_sql,
(
order_id,
item['product_id'],
item.get('variant_id'),
json(product_snapshot),
item['quantity'],
item['unit_price'],
item.get('discount_percentage', 0),
item['item_total']
)
)
# 更新库存
self._update_inventory(
product_id=item['product_id'],
variant_id=item.get('variant_id'),
quantity_change=-item['quantity'],
reference_id=order_id,
reference_type='order',
change_type='sale'
)
# 提交事务
self.conn.commit()
return {
'order_id': str(order_id),
'order_number': order_result['order_number'],
'total_amount': float(order_result['total_amount']),
'items_count': len(items)
}
except exception as e:
self.conn.rollback()
logger.error(f"创建订单失败: {e}")
return none
def _calculate_order_amounts(
self,
items: list[dict[str, any]],
promotion_code: optional[str] = none
) -> dict[str, float]:
"""计算订单金额"""
subtotal = sum(item['item_total'] for item in items)
# 应用促销折扣
discount_amount = 0
if promotion_code:
# 这里可以添加促销逻辑
pass
# 计算税费(简化示例)
tax_amount = subtotal * 0.1 # 10%税率
# 计算运费(简化示例)
shipping_amount = 5.99 if subtotal < 50 else 0
# 计算总额
total_amount = subtotal + tax_amount + shipping_amount - discount_amount
return {
'subtotal': subtotal,
'tax_amount': tax_amount,
'shipping_amount': shipping_amount,
'discount_amount': discount_amount,
'total_amount': total_amount
}
def _get_product_snapshot(self, product_id: str) -> dict[str, any]:
"""获取产品快照"""
snapshot_sql = """
select
id, sku, name, description, brand,
base_price, attributes
from products
where id = %s
"""
self.cursor.execute(snapshot_sql, (product_id,))
product = self.cursor.fetchone()
return {
'product_id': str(product['id']),
'sku': product['sku'],
'name': product['name'],
'brand': product['brand'],
'price_at_time_of_purchase': float(product['base_price']),
'attributes': product['attributes']
}
def _update_inventory(
self,
product_id: str,
variant_id: optional[str],
quantity_change: int,
reference_id: str,
reference_type: str,
change_type: str
):
"""更新库存"""
# 获取当前库存
if variant_id:
stock_sql = """
select variant_stock as current_quantity
from product_variants
where id = %s
"""
self.cursor.execute(stock_sql, (variant_id,))
else:
stock_sql = """
select stock_quantity as current_quantity
from products
where id = %s
"""
self.cursor.execute(stock_sql, (product_id,))
result = self.cursor.fetchone()
if not result:
raise exception("产品不存在")
current_quantity = result['current_quantity']
new_quantity = current_quantity + quantity_change
if new_quantity < 0:
raise exception("库存不足")
# 更新库存
if variant_id:
update_sql = """
update product_variants
set variant_stock = %s
where id = %s
"""
self.cursor.execute(update_sql, (new_quantity, variant_id))
else:
update_sql = """
update products
set stock_quantity = %s
where id = %s
"""
self.cursor.execute(update_sql, (new_quantity, product_id))
# 记录库存变更
log_sql = """
insert into inventory_logs (
product_id, variant_id, change_type,
quantity_change, previous_quantity, new_quantity,
reference_id, reference_type
)
values (%s, %s, %s, %s, %s, %s, %s, %s)
"""
self.cursor.execute(
log_sql,
(
product_id,
variant_id,
change_type,
quantity_change,
current_quantity,
new_quantity,
reference_id,
reference_type
)
)
def _generate_order_suffix(self) -> str:
"""生成订单号后缀"""
import random
import string
# 生成6位随机字母数字
return ''.join(random.choices(
string.ascii_uppercase + string.digits, k=6
))
def refresh_materialized_views(self):
"""刷新物化视图"""
refresh_sql = """
refresh materialized view concurrently product_statistics;
"""
try:
self.cursor.execute(refresh_sql)
self.conn.commit()
logger.info("物化视图刷新成功")
except exception as e:
self.conn.rollback()
logger.error(f"刷新物化视图失败: {e}")
def close(self):
"""关闭连接"""
if self.cursor:
self.cursor.close()
if self.conn:
self.conn.close()
logger.info("数据库连接已关闭")
def demonstrate_ecommerce_features():
"""演示电商系统高级特性"""
dsn = "dbname=ecommerce user=postgres password=password host=localhost port=5432"
print("电商系统postgresql高级特性演示")
print("=" * 60)
# 创建数据库实例
db = ecommercedatabase(dsn)
try:
# 1. 创建架构
print("\n1. 创建数据库架构...")
db.create_schema()
print(" 架构创建完成")
# 2. 演示搜索功能
print("\n2. 演示高级产品搜索...")
products = db.search_products(
query="wireless headphone",
min_price=50,
max_price=200,
min_rating=4.0,
in_stock_only=true,
sort_by='rating',
limit=5
)
print(f" 找到 {len(products)} 个产品:")
for product in products:
print(f" - {product['name']} (评分: {product['average_rating']:.1f}, "
f"价格: ${product['base_price']:.2f})")
# 3. 演示推荐系统
if products:
print("\n3. 演示产品推荐系统...")
recommendations = db.get_product_recommendations(
product_id=products[0]['id'],
limit=5
)
print(f" 为 '{products[0]['name']}' 的推荐:")
for rec in recommendations:
print(f" - {rec['name']} (原因: {rec['recommendation_reason']}, "
f"得分: {rec['recommendation_score']:.2f})")
# 4. 演示订单创建
print("\n4. 演示订单创建...")
# 这里需要实际的产品数据,所以只是演示代码结构
print(" 订单创建功能就绪")
# 5. 刷新物化视图
print("\n5. 刷新物化视图...")
db.refresh_materialized_views()
print(" 物化视图刷新完成")
print("\n演示完成!")
except exception as e:
print(f"演示过程中出错: {e}")
finally:
db.close()
if __name__ == "__main__":
demonstrate_ecommerce_features()
5. 性能监控与调优工具
5.1 postgresql性能监控指标体系
5.2 关键性能指标计算公式
缓冲区命中率:
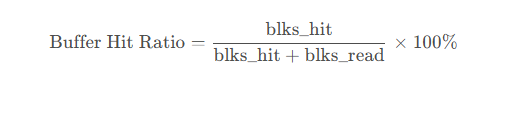
索引使用效率:

缓存命中率:
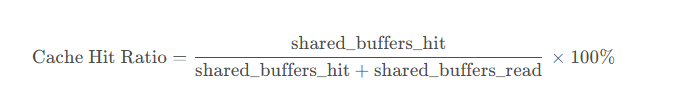
6. 完整代码示例
"""
postgresql高级特性与性能优化完整示例
"""
import psycopg2
from psycopg2.extras import dictcursor, json
import time
from datetime import datetime, timedelta
from typing import dict, list, any, optional
import json
import logging
logging.basicconfig(level=logging.info)
logger = logging.getlogger(__name__)
class postgresqladvancedoptimizer:
"""postgresql高级优化器"""
def __init__(self, dsn: str):
"""
初始化优化器
args:
dsn: 数据库连接字符串
"""
self.dsn = dsn
self.conn = psycopg2.connect(dsn)
self.cursor = self.conn.cursor(cursor_factory=dictcursor)
def analyze_database_health(self) -> dict[str, any]:
"""
全面分析数据库健康状态
returns:
数据库健康报告
"""
health_report = {
'timestamp': datetime.now().isoformat(),
'overall_score': 0,
'categories': {},
'issues': [],
'recommendations': []
}
# 分析各个维度
categories = [
('连接与并发', self._analyze_connections),
('查询性能', self._analyze_query_performance),
('索引效率', self._analyze_index_efficiency),
('缓存性能', self._analyze_cache_performance),
('存储效率', self._analyze_storage_efficiency),
('配置优化', self._analyze_configuration)
]
total_score = 0
category_count = 0
for category_name, analyzer_func in categories:
try:
category_result = analyzer_func()
health_report['categories'][category_name] = category_result
if 'score' in category_result:
total_score += category_result['score']
category_count += 1
if 'issues' in category_result:
health_report['issues'].extend(category_result['issues'])
if 'recommendations' in category_result:
health_report['recommendations'].extend(category_result['recommendations'])
except exception as e:
logger.error(f"分析{category_name}失败: {e}")
health_report['issues'].append({
'category': category_name,
'severity': 'error',
'message': f'分析失败: {str(e)}'
})
# 计算总体评分
if category_count > 0:
health_report['overall_score'] = total_score / category_count
# 排序问题和建议
health_report['issues'] = sorted(
health_report['issues'],
key=lambda x: {'critical': 3, 'high': 2, 'medium': 1, 'low': 0}.get(x.get('severity', 'low'), 0),
reverse=true
)
health_report['recommendations'] = sorted(
health_report['recommendations'],
key=lambda x: x.get('priority', 3),
reverse=false
)
return health_report
def _analyze_connections(self) -> dict[str, any]:
"""分析连接与并发"""
analysis = {
'score': 100,
'metrics': {},
'issues': [],
'recommendations': []
}
try:
# 获取连接统计
self.cursor.execute("""
select
count(*) as total_connections,
count(*) filter (where state = 'active') as active_connections,
count(*) filter (where state = 'idle') as idle_connections,
count(*) filter (where wait_event_type is not null) as waiting_connections,
max(now() - backend_start) as oldest_connection_age
from pg_stat_activity
where pid <> pg_backend_pid()
""")
conn_stats = self.cursor.fetchone()
# 获取配置参数
self.cursor.execute("""
select setting::integer as max_connections
from pg_settings
where name = 'max_connections'
""")
max_conns = self.cursor.fetchone()['max_connections']
# 计算连接使用率
conn_usage = conn_stats['total_connections'] / max_conns
analysis['metrics'] = {
'total_connections': conn_stats['total_connections'],
'active_connections': conn_stats['active_connections'],
'idle_connections': conn_stats['idle_connections'],
'waiting_connections': conn_stats['waiting_connections'],
'connection_usage_percentage': round(conn_usage * 100, 1),
'max_connections': max_conns
}
# 分析问题
if conn_usage > 0.8:
analysis['score'] -= 30
analysis['issues'].append({
'severity': 'high',
'message': f'连接使用率过高: {conn_usage:.1%}',
'details': '接近最大连接数限制'
})
analysis['recommendations'].append({
'priority': 1,
'action': '考虑增加max_connections参数或优化连接池配置'
})
if conn_stats['waiting_connections'] > 5:
analysis['score'] -= 20
analysis['issues'].append({
'severity': 'medium',
'message': f'等待连接数较多: {conn_stats["waiting_connections"]}',
'details': '可能存在锁争用或资源竞争'
})
if conn_stats['oldest_connection_age'] and \
conn_stats['oldest_connection_age'].total_seconds() > 3600:
analysis['score'] -= 10
analysis['issues'].append({
'severity': 'low',
'message': f'存在长时间连接: {conn_stats["oldest_connection_age"]}',
'details': '考虑优化连接生命周期'
})
except exception as e:
logger.error(f"连接分析失败: {e}")
analysis['score'] = 0
return analysis
def _analyze_query_performance(self) -> dict[str, any]:
"""分析查询性能"""
analysis = {
'score': 100,
'metrics': {},
'issues': [],
'recommendations': []
}
try:
# 获取慢查询统计
self.cursor.execute("""
with query_stats as (
select
query,
calls,
total_time,
mean_time,
rows,
100.0 * shared_blks_hit / nullif(shared_blks_hit + shared_blks_read, 0) as buffer_hit_rate,
row_number() over (order by total_time desc) as time_rank
from pg_stat_statements
where query not like '%pg_stat_statements%'
and calls > 0
)
select
count(*) as total_queries,
sum(calls) as total_calls,
sum(total_time) as total_time_ms,
avg(mean_time) as avg_query_time_ms,
percentile_cont(0.95) within group (order by mean_time) as p95_query_time_ms,
sum(case when mean_time > 100 then 1 else 0 end) as slow_queries_count,
avg(buffer_hit_rate) as avg_buffer_hit_rate
from query_stats
""")
query_stats = self.cursor.fetchone()
analysis['metrics'] = {
'total_queries': query_stats['total_queries'],
'total_calls': query_stats['total_calls'],
'total_time_seconds': round(query_stats['total_time_ms'] / 1000, 1),
'avg_query_time_ms': round(query_stats['avg_query_time_ms'], 2),
'p95_query_time_ms': round(query_stats['p95_query_time_ms'], 2),
'slow_queries_count': query_stats['slow_queries_count'],
'avg_buffer_hit_rate': round(query_stats['avg_buffer_hit_rate'], 1)
}
# 分析问题
if query_stats['avg_query_time_ms'] > 50:
analysis['score'] -= 20
analysis['issues'].append({
'severity': 'high',
'message': f'平均查询时间较高: {query_stats["avg_query_time_ms"]:.2f}ms',
'details': '可能存在查询优化空间'
})
analysis['recommendations'].append({
'priority': 1,
'action': '分析并优化最耗时的查询'
})
if query_stats['slow_queries_count'] > 10:
analysis['score'] -= 15
analysis['issues'].append({
'severity': 'medium',
'message': f'发现 {query_stats["slow_queries_count"]} 个慢查询',
'details': '定义: 平均执行时间 > 100ms'
})
if query_stats['avg_buffer_hit_rate'] < 90:
analysis['score'] -= 10
analysis['issues'].append({
'severity': 'medium',
'message': f'平均缓冲区命中率较低: {query_stats["avg_buffer_hit_rate"]:.1f}%',
'details': '建议增加shared_buffers或优化查询'
})
except exception as e:
logger.error(f"查询性能分析失败: {e}")
analysis['score'] = 0
return analysis
def _analyze_index_efficiency(self) -> dict[str, any]:
"""分析索引效率"""
analysis = {
'score': 100,
'metrics': {},
'issues': [],
'recommendations': []
}
try:
# 获取索引使用统计
self.cursor.execute("""
with index_stats as (
select
schemaname,
tablename,
indexname,
idx_scan as index_scans,
idx_tup_read as tuples_read,
idx_tup_fetch as tuples_fetched,
pg_relation_size(indexname::regclass) as index_size_bytes,
case
when idx_scan = 0 then 0
else idx_tup_fetch::float / idx_tup_read * 100
end as index_efficiency
from pg_stat_user_indexes
where schemaname not like 'pg_%'
)
select
count(*) as total_indexes,
sum(index_size_bytes) as total_index_size_bytes,
sum(case when index_scans = 0 then 1 else 0 end) as unused_indexes_count,
avg(index_efficiency) as avg_index_efficiency,
percentile_cont(0.5) within group (order by index_efficiency) as median_index_efficiency
from index_stats
""")
index_stats = self.cursor.fetchone()
analysis['metrics'] = {
'total_indexes': index_stats['total_indexes'],
'total_index_size_gb': round(index_stats['total_index_size_bytes'] / (1024**3), 2),
'unused_indexes_count': index_stats['unused_indexes_count'],
'avg_index_efficiency': round(index_stats['avg_index_efficiency'], 1),
'median_index_efficiency': round(index_stats['median_index_efficiency'], 1)
}
# 分析问题
unused_ratio = index_stats['unused_indexes_count'] / index_stats['total_indexes'] \
if index_stats['total_indexes'] > 0 else 0
if unused_ratio > 0.1:
analysis['score'] -= 25
analysis['issues'].append({
'severity': 'medium',
'message': f'未使用索引比例较高: {unused_ratio:.1%}',
'details': f'{index_stats["unused_indexes_count"]} 个索引从未使用'
})
analysis['recommendations'].append({
'priority': 2,
'action': '考虑删除未使用的索引以节省空间和提高写入性能'
})
if index_stats['avg_index_efficiency'] < 50:
analysis['score'] -= 15
analysis['issues'].append({
'severity': 'medium',
'message': f'平均索引效率较低: {index_stats["avg_index_efficiency"]:.1f}%',
'details': '索引可能不是最优选择'
})
except exception as e:
logger.error(f"索引效率分析失败: {e}")
analysis['score'] = 0
return analysis
def _analyze_cache_performance(self) -> dict[str, any]:
"""分析缓存性能"""
analysis = {
'score': 100,
'metrics': {},
'issues': [],
'recommendations': []
}
try:
# 获取缓存统计
self.cursor.execute("""
select
-- 共享缓冲区命中率
case
when blks_hit + blks_read > 0
then blks_hit::float / (blks_hit + blks_read) * 100
else 0
end as shared_buffer_hit_rate,
-- toast缓冲区命中率
case
when toast_blks_hit + toast_blks_read > 0
then toast_blks_hit::float / (toast_blks_hit + toast_blks_read) * 100
else 0
end as toast_buffer_hit_rate,
-- 临时文件使用
temp_files,
temp_bytes,
-- 检查点统计
checkpoints_timed,
checkpoints_req,
checkpoint_write_time,
checkpoint_sync_time
from pg_stat_bgwriter
""")
cache_stats = self.cursor.fetchone()
# 获取缓冲区配置
self.cursor.execute("""
select
name,
setting,
unit
from pg_settings
where name in ('shared_buffers', 'effective_cache_size')
""")
cache_config = {row['name']: row for row in self.cursor.fetchall()}
analysis['metrics'] = {
'shared_buffer_hit_rate': round(cache_stats['shared_buffer_hit_rate'], 1),
'toast_buffer_hit_rate': round(cache_stats['toast_buffer_hit_rate'], 1),
'temp_files_count': cache_stats['temp_files'],
'temp_files_size_gb': round(cache_stats['temp_bytes'] / (1024**3), 2),
'shared_buffers': cache_config.get('shared_buffers', {}).get('setting', 'n/a'),
'effective_cache_size': cache_config.get('effective_cache_size', {}).get('setting', 'n/a')
}
# 分析问题
if cache_stats['shared_buffer_hit_rate'] < 90:
analysis['score'] -= 20
analysis['issues'].append({
'severity': 'medium',
'message': f'共享缓冲区命中率较低: {cache_stats["shared_buffer_hit_rate"]:.1f}%',
'details': '建议增加shared_buffers或优化工作集'
})
analysis['recommendations'].append({
'priority': 2,
'action': '考虑增加shared_buffers参数'
})
if cache_stats['temp_files'] > 100:
analysis['score'] -= 15
analysis['issues'].append({
'severity': 'medium',
'message': f'临时文件使用较多: {cache_stats["temp_files"]} 个文件',
'details': '可能存在排序或哈希操作溢出到磁盘'
})
analysis['recommendations'].append({
'priority': 2,
'action': '增加work_mem参数以减少临时文件使用'
})
except exception as e:
logger.error(f"缓存性能分析失败: {e}")
analysis['score'] = 0
return analysis
def _analyze_storage_efficiency(self) -> dict[str, any]:
"""分析存储效率"""
analysis = {
'score': 100,
'metrics': {},
'issues': [],
'recommendations': []
}
try:
# 获取表膨胀信息
self.cursor.execute("""
select
schemaname,
tablename,
n_dead_tup as dead_tuples,
n_live_tup as live_tuples,
case
when n_live_tup > 0
then n_dead_tup::float / n_live_tup * 100
else 0
end as dead_tuple_ratio,
last_vacuum,
last_autovacuum,
last_analyze,
last_autoanalyze
from pg_stat_user_tables
where schemaname not like 'pg_%'
order by dead_tuple_ratio desc
limit 10
""")
table_stats = self.cursor.fetchall()
# 获取数据库大小
self.cursor.execute("""
select
pg_database_size(current_database()) as database_size_bytes,
pg_size_pretty(pg_database_size(current_database())) as database_size_pretty
""")
db_size = self.cursor.fetchone()
analysis['metrics'] = {
'database_size': db_size['database_size_pretty'],
'tables_analyzed': len(table_stats),
'top_tables_by_dead_tuples': [
{
'table': f"{row['schemaname']}.{row['tablename']}",
'dead_tuple_ratio': round(row['dead_tuple_ratio'], 1),
'dead_tuples': row['dead_tuples'],
'last_vacuum': row['last_vacuum']
}
for row in table_stats[:5]
]
}
# 分析问题
high_dead_tables = [
row for row in table_stats
if row['dead_tuple_ratio'] > 20
]
if high_dead_tables:
analysis['score'] -= 25
analysis['issues'].append({
'severity': 'medium',
'message': f'发现 {len(high_dead_tables)} 个表死元组比例超过20%',
'details': '可能导致查询性能下降和存储空间浪费'
})
analysis['recommendations'].append({
'priority': 2,
'action': '对高死元组比例的表执行vacuum操作'
})
except exception as e:
logger.error(f"存储效率分析失败: {e}")
analysis['score'] = 0
return analysis
def _analyze_configuration(self) -> dict[str, any]:
"""分析配置优化"""
analysis = {
'score': 100,
'metrics': {},
'issues': [],
'recommendations': []
}
try:
# 获取关键配置参数
self.cursor.execute("""
select
name,
setting,
unit,
context,
vartype,
source
from pg_settings
where name in (
'shared_buffers',
'work_mem',
'maintenance_work_mem',
'effective_cache_size',
'max_connections',
'checkpoint_timeout',
'checkpoint_completion_target',
'wal_buffers',
'random_page_cost',
'seq_page_cost',
'effective_io_concurrency'
)
order by name
""")
configs = {row['name']: row for row in self.cursor.fetchall()}
analysis['metrics'] = {
'key_parameters': configs
}
# 检查配置合理性
issues = []
recommendations = []
# 检查shared_buffers(应为系统内存的25%)
if 'shared_buffers' in configs:
shared_buffers = configs['shared_buffers']['setting']
if shared_buffers.endswith('mb'):
mb_value = int(shared_buffers[:-2])
if mb_value < 128: # 小于128mb
issues.append('shared_buffers设置可能过小')
recommendations.append('考虑增加shared_buffers到系统内存的25%')
# 检查work_mem
if 'work_mem' in configs:
work_mem = configs['work_mem']['setting']
if work_mem.endswith('kb'):
kb_value = int(work_mem[:-2])
if kb_value < 4096: # 小于4mb
issues.append('work_mem设置可能过小')
recommendations.append('适当增加work_mem以减少临时文件使用')
# 检查checkpoint配置
if 'checkpoint_timeout' in configs:
checkpoint_timeout = int(configs['checkpoint_timeout']['setting'])
if checkpoint_timeout > 900: # 超过15分钟
issues.append('checkpoint_timeout设置过长')
recommendations.append('考虑减少checkpoint_timeout以降低恢复时间')
if issues:
analysis['score'] -= len(issues) * 10
for issue in issues:
analysis['issues'].append({
'severity': 'medium',
'message': issue
})
for rec in recommendations:
analysis['recommendations'].append({
'priority': 3,
'action': rec
})
except exception as e:
logger.error(f"配置分析失败: {e}")
analysis['score'] = 0
return analysis
def generate_optimization_report(self) -> dict[str, any]:
"""
生成优化报告
returns:
优化报告
"""
health_report = self.analyze_database_health()
report = {
'summary': {
'overall_score': health_report['overall_score'],
'assessment': self._get_assessment(health_report['overall_score']),
'total_issues': len(health_report['issues']),
'total_recommendations': len(health_report['recommendations'])
},
'detailed_analysis': health_report['categories'],
'critical_issues': [
issue for issue in health_report['issues']
if issue.get('severity') in ['critical', 'high']
],
'optimization_plan': self._create_optimization_plan(health_report),
'execution_checklist': self._create_execution_checklist()
}
return report
def _get_assessment(self, score: float) -> str:
"""根据评分获取评估结果"""
if score >= 90:
return 'excellent'
elif score >= 80:
return 'good'
elif score >= 70:
return 'fair'
elif score >= 60:
return 'needs_improvement'
else:
return 'poor'
def _create_optimization_plan(self, health_report: dict[str, any]) -> list[dict[str, any]]:
"""创建优化计划"""
plan = []
# 按优先级排序建议
sorted_recommendations = sorted(
health_report['recommendations'],
key=lambda x: x.get('priority', 3)
)
for i, rec in enumerate(sorted_recommendations[:10], 1): # 取前10个
plan.append({
'step': i,
'action': rec['action'],
'priority': rec.get('priority', 3),
'estimated_effort': self._estimate_effort(rec['action']),
'expected_impact': self._estimate_impact(rec['action'])
})
return plan
def _estimate_effort(self, action: str) -> str:
"""估计实施难度"""
low_effort_keywords = ['调整', '设置', '启用', '禁用']
medium_effort_keywords = ['优化', '重构', '重建', '迁移']
high_effort_keywords = ['重写', '重构架构', '数据迁移', '集群扩展']
action_lower = action.lower()
if any(keyword in action_lower for keyword in high_effort_keywords):
return 'high'
elif any(keyword in action_lower for keyword in medium_effort_keywords):
return 'medium'
else:
return 'low'
def _estimate_impact(self, action: str) -> str:
"""估计影响程度"""
high_impact_keywords = ['性能提升', '显著改善', '根本解决', '关键修复']
medium_impact_keywords = ['优化', '改进', '增强', '调整']
low_impact_keywords = ['微调', '小优化', '维护', '清理']
action_lower = action.lower()
if any(keyword in action_lower for keyword in high_impact_keywords):
return 'high'
elif any(keyword in action_lower for keyword in medium_impact_keywords):
return 'medium'
else:
return 'low'
def _create_execution_checklist(self) -> list[dict[str, any]]:
"""创建执行检查清单"""
checklist = [
{
'phase': '准备阶段',
'tasks': [
{'task': '备份数据库', 'completed': false},
{'task': '验证备份完整性', 'completed': false},
{'task': '准备回滚计划', 'completed': false},
{'task': '安排维护窗口', 'completed': false}
]
},
{
'phase': '实施阶段',
'tasks': [
{'task': '应用配置变更', 'completed': false},
{'task': '执行索引优化', 'completed': false},
{'task': '运行vacuum操作', 'completed': false},
{'task': '更新统计信息', 'completed': false}
]
},
{
'phase': '验证阶段',
'tasks': [
{'task': '验证性能改进', 'completed': false},
{'task': '运行回归测试', 'completed': false},
{'task': '监控系统稳定性', 'completed': false},
{'task': '更新文档记录', 'completed': false}
]
}
]
return checklist
def close(self):
"""关闭连接"""
if self.cursor:
self.cursor.close()
if self.conn:
self.conn.close()
logger.info("数据库连接已关闭")
def demonstrate_optimization():
"""演示优化功能"""
dsn = "dbname=testdb user=postgres password=password host=localhost port=5432"
print("postgresql高级优化演示")
print("=" * 60)
optimizer = postgresqladvancedoptimizer(dsn)
try:
# 生成健康报告
print("\n生成数据库健康报告...")
health_report = optimizer.analyze_database_health()
print(f"\n总体评分: {health_report['overall_score']:.1f}/100")
print(f"发现问题: {len(health_report['issues'])} 个")
print(f"优化建议: {len(health_report['recommendations'])} 条")
# 显示关键问题
critical_issues = [
issue for issue in health_report['issues']
if issue.get('severity') in ['critical', 'high']
]
if critical_issues:
print("\n关键问题:")
for issue in critical_issues[:3]:
print(f" • [{issue['severity']}] {issue['message']}")
# 显示高优先级建议
high_priority_recs = [
rec for rec in health_report['recommendations']
if rec.get('priority', 3) == 1
]
if high_priority_recs:
print("\n高优先级建议:")
for rec in high_priority_recs[:3]:
print(f" • {rec['action']}")
# 生成详细报告
print("\n\n生成详细优化报告...")
report = optimizer.generate_optimization_report()
print(f"\n优化计划 ({len(report['optimization_plan'])} 个步骤):")
for step in report['optimization_plan'][:5]:
print(f" 步骤{step['step']}: {step['action']}")
print(f" 优先级: {step['priority']}, 难度: {step['estimated_effort']}, "
f"影响: {step['expected_impact']}")
print("\n执行检查清单:")
for phase in report['execution_checklist']:
print(f" {phase['phase']}:")
for task in phase['tasks']:
status = '✓' if task['completed'] else '○'
print(f" {status} {task['task']}")
print("\n优化演示完成!")
except exception as e:
print(f"演示过程中出错: {e}")
finally:
optimizer.close()
if __name__ == "__main__":
demonstrate_optimization()
7. 代码自查与最佳实践
7.1 代码质量检查清单
为确保postgresql相关代码的质量,应遵循以下检查清单:
"""
postgresql代码质量自查工具
"""
import re
import ast
from typing import list, dict, any, set
import logging
logging.basicconfig(level=logging.info)
logger = logging.getlogger(__name__)
class postgresqlcodechecker:
"""postgresql代码质量检查器"""
def __init__(self):
self.rules = {
'sql_injection': self.check_sql_injection,
'connection_management': self.check_connection_management,
'transaction_handling': self.check_transaction_handling,
'index_usage': self.check_index_usage,
'data_type_validation': self.check_data_type_validation,
'error_handling': self.check_error_handling,
'performance_anti_patterns': self.check_performance_anti_patterns
}
def check_file(self, filepath: str) -> dict[str, list[dict[str, any]]]:
"""
检查python文件中的postgresql相关代码
args:
filepath: python文件路径
returns:
检查结果
"""
with open(filepath, 'r', encoding='utf-8') as f:
content = f.read()
issues = {}
for rule_name, rule_func in self.rules.items():
rule_issues = rule_func(content, filepath)
if rule_issues:
issues[rule_name] = rule_issues
return issues
def check_sql_injection(self, content: str, filepath: str) -> list[dict[str, any]]:
"""
检查sql注入漏洞
args:
content: 文件内容
filepath: 文件路径
returns:
问题列表
"""
issues = []
# 查找可能的字符串拼接sql
patterns = [
(r'execute\s*\(.*?\s*%\s*.*?\)', '使用字符串格式化执行sql'),
(r'execute\s*\(.*?\s*\+\s*.*?\)', '使用字符串拼接执行sql'),
(r'executemany\s*\(.*?\s*%\s*.*?\)', '使用字符串格式化执行批量sql'),
(r'f"select.*{.*}.*"', '使用f-string直接嵌入变量'),
]
lines = content.split('\n')
for i, line in enumerate(lines, 1):
for pattern, description in patterns:
if re.search(pattern, line, re.ignorecase):
issues.append({
'line': i,
'severity': 'critical',
'message': f'潜在的sql注入漏洞: {description}',
'suggestion': '使用参数化查询(%s占位符)',
'code_snippet': line.strip()[:100]
})
return issues
def check_connection_management(self, content: str, filepath: str) -> list[dict[str, any]]:
"""
检查数据库连接管理
args:
content: 文件内容
filepath: 文件路径
returns:
问题列表
"""
issues = []
lines = content.split('\n')
# 查找连接创建但不关闭的情况
connect_pattern = r'psycopg2\.connect\(|connect\('
close_pattern = r'\.close\(\)'
in_function = false
function_start = 0
connect_lines = []
for i, line in enumerate(lines, 1):
# 检测函数开始
if line.strip().startswith('def '):
in_function = true
function_start = i
connect_lines = []
# 检测连接创建
if re.search(connect_pattern, line):
connect_lines.append(i)
# 检测连接关闭
if re.search(close_pattern, line) and 'close' in line:
if connect_lines:
connect_lines.pop()
# 检测函数结束
if line.strip() == '' or i == len(lines):
if in_function and connect_lines:
for connect_line in connect_lines:
issues.append({
'line': connect_line,
'severity': 'high',
'message': '数据库连接可能未正确关闭',
'suggestion': '确保在finally块中关闭连接',
'context': f'函数开始于第{function_start}行'
})
in_function = false
return issues
def check_transaction_handling(self, content: str, filepath: str) -> list[dict[str, any]]:
"""
检查事务处理
args:
content: 文件内容
filepath: 文件路径
returns:
问题列表
"""
issues = []
lines = content.split('\n')
# 查找没有明确事务管理的操作
write_operations = [
'insert', 'update', 'delete', 'create', 'alter', 'drop'
]
transaction_keywords = [
'begin', 'commit', 'rollback', 'autocommit',
'set_session', 'transaction'
]
in_write_operation = false
has_transaction_control = false
for i, line in enumerate(lines, 1):
line_upper = line.upper()
# 检查是否有写操作
if any(op in line_upper for op in write_operations):
in_write_operation = true
# 检查是否有事务控制
if any(keyword in line for keyword in transaction_keywords):
has_transaction_control = true
# 如果是空行或注释,检查之前的操作
if line.strip() == '' or line.strip().startswith('#'):
if in_write_operation and not has_transaction_control:
issues.append({
'line': i - 1,
'severity': 'medium',
'message': '写操作没有显式的事务管理',
'suggestion': '使用明确的事务控制(begin/commit/rollback)',
'context': '多个写操作应该在同一事务中'
})
in_write_operation = false
has_transaction_control = false
return issues
def check_index_usage(self, content: str, filepath: str) -> list[dict[str, any]]:
"""
检查索引使用
args:
content: 文件内容
filepath: 文件路径
returns:
问题列表
"""
issues = []
lines = content.split('\n')
# 查找可能受益于索引的查询模式
index_patterns = [
(r'where\s+\w+\s*=\s*', '等值查询'),
(r'where\s+\w+\s+in\s*\(', 'in列表查询'),
(r'where\s+\w+\s+like\s+\'', 'like查询(可能前缀匹配)'),
(r'order\s+by\s+\w+', '排序操作'),
(r'group\s+by\s+\w+', '分组操作'),
(r'join\s+\w+\s+on\s+\w+\s*=\s*\w+', '连接操作')
]
for i, line in enumerate(lines, 1):
line_upper = line.upper()
# 跳过注释
if line.strip().startswith('#'):
continue
for pattern, description in index_patterns:
if re.search(pattern, line_upper, re.ignorecase):
issues.append({
'line': i,
'severity': 'low',
'message': f'查询可能受益于索引: {description}',
'suggestion': '考虑在相关列上创建索引',
'code_snippet': line.strip()[:100]
})
break
return issues
def generate_report(self, issues: dict[str, list[dict[str, any]]]) -> str:
"""生成检查报告"""
report_lines = []
report_lines.append("=" * 60)
report_lines.append("postgresql代码质量检查报告")
report_lines.append("=" * 60)
total_issues = sum(len(rule_issues) for rule_issues in issues.values())
report_lines.append(f"\n总共发现 {total_issues} 个问题\n")
severity_counts = {'critical': 0, 'high': 0, 'medium': 0, 'low': 0}
for rule_name, rule_issues in issues.items():
if rule_issues:
report_lines.append(f"\n{rule_name.upper()} ({len(rule_issues)}个问题):")
report_lines.append("-" * 40)
for issue in rule_issues:
severity = issue.get('severity', 'unknown')
severity_counts[severity] = severity_counts.get(severity, 0) + 1
report_lines.append(
f"[{severity}] 第{issue['line']}行: {issue['message']}"
)
if 'suggestion' in issue:
report_lines.append(f" 建议: {issue['suggestion']}")
if 'code_snippet' in issue:
report_lines.append(f" 代码: {issue['code_snippet']}")
report_lines.append("")
# 添加严重性统计
report_lines.append("\n严重性统计:")
report_lines.append("-" * 40)
for severity, count in severity_counts.items():
if count > 0:
report_lines.append(f" {severity}: {count} 个问题")
return '\n'.join(report_lines)
def check_postgresql_best_practices():
"""postgresql最佳实践检查示例"""
checker = postgresqlcodechecker()
# 示例代码
sample_code = """
import psycopg2
# 不好的示例:字符串拼接sql(sql注入风险)
def bad_example(user_input):
conn = psycopg2.connect("dbname=test")
cursor = conn.cursor()
# sql注入漏洞
query = f"select * from users where username = '{user_input}'"
cursor.execute(query)
# 连接未关闭
return cursor.fetchall()
# 好的示例:参数化查询
def good_example(username):
conn = none
cursor = none
try:
conn = psycopg2.connect("dbname=test")
cursor = conn.cursor()
# 参数化查询
query = "select * from users where username = %s"
cursor.execute(query, (username,))
return cursor.fetchall()
finally:
if cursor:
cursor.close()
if conn:
conn.close()
# 事务处理示例
def transaction_example(user_data):
conn = psycopg2.connect("dbname=test")
cursor = conn.cursor()
try:
# 开始事务
conn.autocommit = false
# 多个写操作
cursor.execute(
"insert into users (name, email) values (%s, %s)",
(user_data['name'], user_data['email'])
)
cursor.execute(
"insert into logs (action) values (%s)",
('user_created',)
)
# 提交事务
conn.commit()
except exception as e:
# 回滚事务
conn.rollback()
raise e
finally:
cursor.close()
conn.close()
# 可能受益于索引的查询
def query_without_index():
conn = psycopg2.connect("dbname=test")
cursor = conn.cursor()
# 这个查询可能受益于索引
cursor.execute("""
select * from orders
where customer_id = %s
and order_date > %s
order by order_date desc
""", (123, '2024-01-01'))
return cursor.fetchall()
"""
# 将示例代码写入临时文件
import tempfile
with tempfile.namedtemporaryfile(mode='w', suffix='.py', delete=false) as f:
f.write(sample_code)
temp_file = f.name
try:
# 检查代码
issues = checker.check_file(temp_file)
report = checker.generate_report(issues)
print(report)
finally:
import os
os.unlink(temp_file)
if __name__ == "__main__":
check_postgresql_best_practices()
7.2 postgresql最佳实践总结
连接管理最佳实践:
- 使用连接池管理数据库连接
- 确保连接在finally块中正确关闭
- 设置合适的连接超时和重试策略
查询优化最佳实践:
- 使用explain analyze分析查询计划
- 为频繁查询的列创建合适索引
- 避免select *,只选择需要的列
- 使用limit限制返回行数
事务管理最佳实践:
- 保持事务尽可能短小
- 使用合适的隔离级别
- 处理异常并正确回滚
- 避免长时间持有锁
索引设计最佳实践:
- 基于查询模式设计复合索引
- 定期分析和重建索引
- 使用部分索引减少索引大小
- 考虑brin索引用于时间序列数据
配置优化最佳实践:
- 根据工作负载调整shared_buffers
- 设置合适的work_mem减少临时文件
- 配置有效的维护工作内存
- 定期更新统计信息
8. 总结与展望
postgresql作为功能最丰富的开源数据库,其高级特性和性能优化能力使其能够应对各种复杂的应用场景。通过本文的深入探讨,我们了解到:
8.1 核心要点总结
- 高级特性:jsonb、全文搜索、分区表、物化视图等特性使postgresql能够处理多样化数据需求
- 性能优化:合理的索引设计、查询优化、配置调整是提升性能的关键
- 并发控制:mvcc机制和适当的锁策略确保高并发下的数据一致性
- 监控维护:系统化监控和定期维护保证数据库长期稳定运行
8.2 未来发展趋势
- 人工智能集成:postgresql的madlib扩展支持机器学习算法
- 时序数据优化:timescaledb扩展提供专业时序数据处理能力
- 地理空间增强:postgis继续扩展地理信息系统功能
- 云原生支持:更好的kubernetes集成和云服务优化
- 向量搜索:对ai生成内容(aigc)的向量相似度搜索支持
通过持续学习和实践,开发者可以充分利用postgresql的强大功能,构建高效、稳定、可扩展的数据存储解决方案。无论是对初创公司还是大型企业,postgresql都提供了企业级数据库所需的一切功能,同时保持了开源软件的灵活性和成本优势。
以上就是postgresql高级特性与性能优化的实战指南的详细内容,更多关于postgresql性能优化的资料请关注代码网其它相关文章!




发表评论