本文围绕手写数字识别项目展开,涵盖前端交互(vue)、后端接口(fastapi)、cnn模型训练(pytorch)全流程,把之前学习过的知识综合运用起来。
内容包含环境搭建、代码实现、操作步骤及问题解决,借助该项目来掌握前后端分离项目开发、mnist数据集应用、lenet5模型训练与部署,获取可复用的图像分类项目流程,快速复现或扩展类似项目。
1 项目基础与环境准备
1.1 项目介绍与目标
1.1.1 项目介绍
手写数字识别是计算机视觉入门经典任务,基于mnist数据集(含6万训练样本、1万测试样本,每个样本为28×28灰度图,对应0-9数字),采用lenet5卷积神经网络(cnn)实现分类,架构为前端交互+后端预测+模型支撑的前后端分离模式。
1.1.2 项目目标
- 前端:提供画布供用户手写数字,完成图像预处理(缩放、灰度转换),发起后端请求并展示结果。
- 后端:接收前端图像,通过预训练lenet5模型预测数字,返回结果。
- 整体:实现端到端识别,准确率达98%以上,掌握全流程开发逻辑。
具体的流程可以参考下图:
1.2 开发环境准备
1.2.1 基础环境要求
- 编程语言:python 3.8+(后端+模型训练)、javascript(前端vue)
- 运行环境:node.js 16+(vue项目依赖管理)、python虚拟环境
1.2.2 依赖库安装
1.2.2.1 python依赖(后端+模型)
通过pip安装核心库,命令如下:
# 后端框架与网络请求 pip install fastapi uvicorn # pytorch核心(含cpu版本,gpu版本需替换命令) pip install torch torchvision # 图像处理与数据处理 pip install pillow numpy # 前端请求库(vue侧后续安装)
这里还有个要注意的点就是,如果电脑里有多个python环境,在这里用pip下载最好指定一下,不然会默认用全局的python环境去下载。
比如:
d:\python\scripts\pip3.12.exe install [安装包]
1.2.2.2 vue依赖(前端)
进入前端项目目录(mnist-frontend),通过npm安装:
# 初始化vue项目(若未创建) npm create vue@latest mnist-frontend # 进入目录并安装axios(请求后端) cd mnist-frontend npm install axios
1.2.3 项目目录结构
参考实际文件路径(d:\projectpython\dnn_cnn),规范结构如下(便于后续复用):
dnn_cnn/ # 项目根目录 ├─ mnist-frontend/ # 前端vue项目 │ ├─ src/ │ │ ├─ app.vue # 前端核心文件(模板+逻辑+样式) │ │ ├─ main.js # vue入口文件 │ │ └─ style.css # 全局样式(本项目用组件内联样式) │ └─ package.json # vue依赖配置 ├─ cnn_proj.py # 模型训练脚本(生成权重文件) ├─ main.py # 后端fastapi服务脚本 ├─ lenet5_mnist.pth # 预训练模型权重(训练后生成) └─ dataset/ # mnist数据集(训练脚本自动下载)
2 前端实现(vue)
2.1 前端核心功能定位
前端是用户交互入口,需解决如何让用户输入数字、如何将输入转为模型可识别格式和如何与后端通信三个核心问题,最终实现绘制→预处理→请求→展示的这一闭环。
2.2 模板结构设计(app.vue的<template>)
模板需包含交互组件+反馈组件,结构如下:
<template>
<div class="container">
<h1>手写数字识别</h1>
<!-- 1. 主画布(用户绘制数字) -->
<canvas
ref="canvas"
width="280"
height="280"
@mousedown="startdrawing"
@mousemove="draw"
@mouseup="stopdrawing"
@mouseleave="stopdrawing"
></canvas>
<!-- 2. 调试画布(预览28×28预处理图像,便于排查问题) -->
<div class="debug-section" v-show="showdebug">
<h3>预处理后图像(28x28 放大)</h3>
<canvas ref="debugcanvas" width="280" height="280"></canvas>
<p class="debug-info">实际尺寸 28x28 | 放大 10 倍</p>
</div>
<!-- 3. 控制按钮(功能操作) -->
<div class="buttons">
<button @click="clearcanvas" :disabled="isloading">清除画布</button>
<button @click="predictdigit" :disabled="isloading">
{{ isloading ? '识别中...' : '识别' }}
</button>
<button @click="toggledebug">显示/隐藏调试</button>
</div>
<!-- 4. 结果与错误反馈 -->
<div class="result" v-if="recognitionresult">识别结果:{{ recognitionresult }}</div>
<div class="error" v-if="errormessage">错误:{{ errormessage }}</div>
</div>
</template>
2.3 核心逻辑实现(app.vue的<script setup>)
2.3.1 响应式变量定义
通过vue的ref定义状态变量,确保视图与数据同步:
import { ref, onmounted, nexttick, watch } from 'vue';
import axios from 'axios';
// 画布dom引用
const canvas = ref(null);
const debugcanvas = ref(null);
// 控制状态
const showdebug = ref(false); // 调试视图开关
const isdrawing = ref(false); // 绘制状态
const isloading = ref(false); // 识别加载状态
// 结果反馈
const recognitionresult = ref(''); // 识别结果
const errormessage = ref(''); // 错误信息
// 绘制辅助变量
let ctx = null; // 主画布上下文
let debugctx = null; // 调试画布上下文
let lastx = 0; // 上一次绘制x坐标
let lasty = 0; // 上一次绘制y坐标
2.3.2 画布初始化(onmounted钩子)
画布需在dom渲染完成后初始化,确保上下文获取成功,同时配置绘制参数(匹配模型输入要求):
onmounted(async () => {
await nexttick(); // 等待dom完全渲染
// 主画布初始化(280×280,后续缩放为28×28,避免绘制精度不足)
if (canvas.value) {
ctx = canvas.value.getcontext('2d', { willreadfrequently: true });
if (ctx) {
ctx.fillstyle = '#ffffff'; // 纯白背景(匹配mnist数据集背景)
ctx.fillrect(0, 0, 280, 280);
ctx.linewidth = 12; // 画笔宽度(过细会导致预处理后线条消失)
ctx.strokestyle = 'black'; // 黑色画笔(与mnist数字颜色一致)
ctx.linecap = 'round'; // 画笔端点圆润(避免锯齿)
ctx.linejoin = 'round'; // 画笔拐角圆润(提升绘制体验)
} else {
errormessage.value = '主画布初始化失败,请刷新';
}
}
// 调试画布初始化(与主画布逻辑一致,用于预览预处理结果)
if (debugcanvas.value) {
debugctx = debugcanvas.value.getcontext('2d', { willreadfrequently: true });
if (debugctx) {
debugctx.fillstyle = '#ffffff';
debugctx.fillrect(0, 0, 280, 280);
} else {
console.warn('调试画布初始化失败(不影响主功能)');
}
}
});
2.3.3 绘制逻辑(鼠标事件处理)
通过mousedown/mousemove/mouseup事件实现连续绘制,需处理画布缩放导致的坐标偏移问题:
// 开始绘制(记录初始坐标)
function startdrawing(e) {
if (!ctx) return;
isdrawing.value = true;
const rect = canvas.value.getboundingclientrect(); // 获取画布在页面中的位置
// 计算画布内真实坐标(解决浏览器缩放导致的坐标偏差)
lastx = (e.clientx - rect.left) * (canvas.value.width / rect.width);
lasty = (e.clienty - rect.top) * (canvas.value.height / rect.height);
ctx.beginpath();
ctx.moveto(lastx, lasty);
ctx.lineto(lastx + 0.1, lasty + 0.1); // 绘制初始点(避免点击不拖动无痕迹)
ctx.stroke();
}
// 实时绘制
function draw(e) {
if (!ctx || !isdrawing.value) return;
const rect = canvas.value.getboundingclientrect();
const x = (e.clientx - rect.left) * (canvas.value.width / rect.width);
const y = (e.clienty - rect.top) * (canvas.value.height / rect.height);
ctx.lineto(x, y); // 连接上一坐标与当前坐标
ctx.stroke();
lastx = x; // 更新上一坐标
lasty = y;
}
// 结束绘制
function stopdrawing() {
isdrawing.value = false;
}
2.3.4 图像预处理(关键步骤)
模型输入要求为1×1×28×28灰度图(batch×通道×高×宽)+ 归一化,需通过辅助函数实现转换:
2.3.4.1 画布空检测(checkcanvasempty)
避免前端发送空图像请求,通过亮度阈值判断是否有绘制内容:
async function checkcanvasempty() {
return new promise((resolve) => {
if (!ctx) { resolve(true); return; }
const imagedata = ctx.getimagedata(0, 0, 280, 280);
const data = imagedata.data; // 像素数据(rgba,每4个值对应一个像素)
const threshold = 250; // 亮度阈值(纯白亮度255,低于250视为有绘制)
for (let i = 0; i < data.length; i += 4) {
const brightness = (data[i] + data[i+1] + data[i+2]) / 3; // 计算亮度(灰度值)
if (brightness < threshold) {
resolve(false); // 有绘制内容
return;
}
}
resolve(true); // 无绘制内容
});
}
2.3.4.2 28×28灰度转换与反转(canvasto28x28gray)
mnist数据集为黑底白字,而前端绘制是白底黑字,需反转颜色;同时缩放为28×28:
function canvasto28x28gray(canvasel) {
return new promise((resolve) => {
// 1. 创建临时画布(28×28,模型输入尺寸)
const tempcanvas = document.createelement('canvas');
tempcanvas.width = 28;
tempcanvas.height = 28;
const tempctx = tempcanvas.getcontext('2d');
if (!tempctx) { resolve({ imgblob: null, tempcanvas: null }); return; }
// 2. 缩放绘制(保持比例居中,避免拉伸)
tempctx.fillstyle = '#ffffff';
tempctx.fillrect(0, 0, 28, 28); // 填充纯白背景
const scale = math.min(28 / canvasel.width, 28 / canvasel.height); // 等比例缩放
const xoffset = (28 - canvasel.width * scale) / 2; // x轴居中偏移
const yoffset = (28 - canvasel.height * scale) / 2; // y轴居中偏移
tempctx.drawimage(
canvasel,
0, 0, canvasel.width, canvasel.height, // 源图像区域
xoffset, yoffset, canvasel.width * scale, canvasel.height * scale // 目标绘制区域
);
// 3. 灰度转换与颜色反转(匹配mnist数据分布)
const imagedata = tempctx.getimagedata(0, 0, 28, 28);
const data = imagedata.data;
for (let i = 0; i < data.length; i += 4) {
const brightness = (data[i] + data[i+1] + data[i+2]) / 3; // 灰度值
const inverted = 255 - brightness; // 反转:白底黑字→黑底白字
data[i] = data[i+1] = data[i+2] = inverted; // rgb通道统一为反转后值
data[i+3] = 255; // 透明度保持100%
}
tempctx.putimagedata(imagedata, 0, 0);
// 4. 生成blob(用于formdata传输)
tempcanvas.toblob((blob) => {
resolve({ imgblob: blob, tempcanvas: tempcanvas });
}, 'image/png', 1.0); // 无损压缩,避免图像细节丢失
});
}
2.3.5 后端请求逻辑(predictdigit)
通过axios发送post请求,传递图像blob,处理响应与错误:
async function predictdigit() {
if (!ctx) { errormessage.value = '画布未初始化,请刷新'; return; }
isloading.value = true;
errormessage.value = '';
try {
// 步骤1:检查画布是否有内容
const isempty = await checkcanvasempty();
if (isempty) {
errormessage.value = '请先绘制数字';
isloading.value = false;
return;
}
// 步骤2:预处理图像(转为28×28灰度blob)
const { imgblob, tempcanvas } = await canvasto28x28gray(canvas.value);
if (!imgblob) { throw new error('图像转换失败,无法生成有效数据'); }
// 步骤3:预览调试图像(若开启调试)
if (showdebug.value && debugctx && tempcanvas) {
debugctx.drawimage(tempcanvas, 0, 0, 280, 280); // 放大10倍显示
}
// 步骤4:构建formdata(后端接收文件格式)
const formdata = new formdata();
formdata.append('file', imgblob, 'digit.png'); // 参数名'file'需与后端一致
// 步骤5:发送请求(不手动设置content-type,axios自动处理边界符)
const response = await axios.post(
'http://localhost:8000/predict', // 后端接口地址
formdata
);
// 步骤6:处理响应(验证数据格式)
if (response.data && 'predicted_digit' in response.data) {
recognitionresult.value = response.data.predicted_digit;
} else {
throw new error('后端返回数据格式异常');
}
} catch (error) {
// 精细化错误提示(便于排查问题)
if (error.response) {
// 后端返回错误(如422参数错误、500服务器错误)
errormessage.value = `识别失败:${error.response.status} - ${
error.response.data?.error || error.response.data?.detail || '未知错误'
}`;
} else if (error.request) {
// 无响应(后端未启动、跨域问题)
errormessage.value = '识别失败:无法连接后端服务,请检查后端是否运行';
} else {
// 前端本地错误(如图像转换失败)
errormessage.value = `识别失败:${error.message}`;
}
console.error('预测错误详情:', error);
} finally {
isloading.value = false; // 无论成功失败,结束加载状态
}
}
这里简单说下图像blob,图像blob(binary large object)简单说就是以二进制形式存储的图像文件数据,比如png、jpg格式的图像在计算机中实际存储的字节流,就属于blob。
在项目里,前端把画布绘制的内容(28×28灰度图)转成blob,是因为:
- 后端接口接收的是“文件”类型数据(
uploadfile),blob能模拟文件的二进制格式; - 配合
formdata(表单数据)传递时能保持图像的原始编码,避免文本格式转换导致的数据损坏。
比如项目中canvasto28x28gray函数里,通过tempcanvas.toblob(...)生成blob,再用formdata.append('file', imgblob, 'digit.png')附加到请求里,就能让后端像接收本地图片文件一样解析它。
2.4 样式设计(app.vue的<style scoped>)
样式保证交互友好性,没有放过多冗杂的东西,核心代码如下:
<style scoped>
.container {
text-align: center;
padding: 20px;
max-width: 600px;
margin: 0 auto; /* 容器居中 */
}
canvas {
border: 2px solid #ccc;
margin: 10px auto;
display: block;
background-color: #ffffff; /* 匹配画布初始化背景 */
touch-action: none; /* 禁止浏览器默认触摸行为(适配移动端) */
}
.debug-section {
margin-top: 20px;
padding: 15px;
background-color: #f9f9f9;
border-radius: 8px; /* 圆角提升美观度 */
}
.debug-info {
color: #666;
font-size: 14px;
margin-top: 5px;
}
.buttons {
margin: 20px 0;
}
button {
padding: 10px 20px;
margin: 0 10px;
cursor: pointer;
background-color: #42b983; /* vue默认主题色,辨识度高 */
color: white;
border: none;
border-radius: 4px;
transition: opacity 0.3s; /* hover过渡效果 */
}
button:disabled {
background-color: #ccc;
cursor: not-allowed; /* 禁用状态光标提示 */
opacity: 0.7;
}
button:hover:not(:disabled) {
opacity: 0.8; /* hover时降低透明度,反馈交互 */
}
.result {
font-size: 20px;
margin-top: 20px;
color: #42b983; /* 成功颜色 */
}
.error {
font-size: 16px;
color: #e53e3e; /* 错误颜色 */
margin-top: 10px;
}
</style>
3 后端实现(fastapi + pytorch)
3.1 后端核心功能定位
后端需解决如何接收前端图像、如何用模型预测和如何返回结果这三个问题,核心是提供高可用的预测接口,确保与前端数据格式兼容、与模型输入匹配。
3.2 fastapi服务搭建
3.2.1 初始化fastapi实例
from fastapi import fastapi, file, uploadfile from fastapi.middleware.cors import corsmiddleware import torch import torch.nn as nn from pil import image import numpy as np # 初始化fastapi应用 app = fastapi()
3.2.2 跨域配置(关键)
前端(默认5173端口)与后端(8000端口)端口不同,会触发浏览器跨域拦截,需配置corsmiddleware:
app.add_middleware(
corsmiddleware,
allow_origins=["*"], # 开发环境允许所有源(生产环境需指定具体域名)
allow_credentials=true, # 允许携带cookie(本项目暂用不到,保留扩展性)
allow_methods=["*"], # 允许所有http方法(get/post等)
allow_headers=["*"], # 允许所有请求头
)
3.3 lenet5模型定义(与训练脚本一致)
模型结构必须与训练时完全相同,否则权重加载失败。lenet5是经典cnn架构,适配mnist数据:
class lenet5(nn.module):
def __init__(self):
super(lenet5, self).__init__()
# 网络层序列(卷积→激活→池化→卷积→激活→池化→卷积→激活→展平→全连接→激活→全连接)
self.net = nn.sequential(
# c1层:1→6通道,5×5卷积核,padding=2(保持28×28输出)
nn.conv2d(in_channels=1, out_channels=6, kernel_size=5, padding=2),
nn.tanh(), # 激活函数(lenet5原设计,引入非线性)
nn.avgpool2d(kernel_size=2, stride=2), # s2层:2×2平均池化,输出14×14
# c3层:6→16通道,5×5卷积核(无padding,输出10×10)
nn.conv2d(in_channels=6, out_channels=16, kernel_size=5),
nn.tanh(),
nn.avgpool2d(kernel_size=2, stride=2), # s4层:输出5×5
# c5层:16→120通道,5×5卷积核(输出1×1,等效全连接)
nn.conv2d(in_channels=16, out_channels=120, kernel_size=5),
nn.tanh(),
nn.flatten(), # 展平:120×1×1→120维向量
# f6层:全连接,120→84
nn.linear(in_features=120, out_features=84),
nn.tanh(),
# 输出层:全连接,84→10(对应0-9数字)
nn.linear(in_features=84, out_features=10)
)
# 前向传播(定义数据流动路径)
def forward(self, x):
return self.net(x)
3.4 模型加载与图像预处理
3.4.1 模型初始化与权重加载
加载训练生成的lenet5_mnist.pth权重,切换为评估模式(禁用训练相关层):
# 初始化模型
model = lenet5()
# 加载权重(map_location='cpu'适配无gpu环境)
state_dict = torch.load('lenet5_mnist.pth', map_location=torch.device('cpu'))
model.load_state_dict(state_dict) # 权重参数映射到模型
model.eval() # 切换为评估模式(关键:禁用dropout/batchnorm等训练层)
3.4.2 图像预处理函数(preprocess_image)
前端传入的是28×28 png图像,需转为模型要求的1×1×28×28张量+归一化:
def preprocess_image(image):
# 1. 转为灰度图(即使前端已处理,后端二次确认,避免格式错误)
image = image.convert('l') # 'l'模式为单通道灰度图
# 2. 确保尺寸为28×28(前端可能因异常未缩放,后端兜底)
image = image.resize((28, 28), image.resampling.lanczos) # 高质量插值缩放
# 3. 转为numpy数组并归一化(匹配训练时的数据分布)
image = np.array(image, dtype=np.float32) # 转为32位浮点数数组
mean = 0.1307 # mnist数据集均值(训练时计算,需固定)
std = 0.3081 # mnist数据集标准差(训练时计算,需固定)
image = (image / 255.0 - mean) / std # 步骤:0-255→0-1→标准化(均值0,标准差1)
# 4. 调整维度(模型输入:batch×通道×高×宽)
image = np.expand_dims(image, axis=0) # 增加通道维度:(28,28)→(1,28,28)
image = np.expand_dims(image, axis=0) # 增加batch维度:(1,28,28)→(1,1,28,28)
# 5. 转为pytorch张量
return torch.tensor(image)
3.5 预测接口实现(/predict)
定义post接口,接收前端uploadfile类型文件,处理流程为读取图像→预处理→预测→返回结果:
@app.post("/predict")
async def predict_digit(file: uploadfile = file(...)):
try:
# 1. 打印调试信息(便于排查文件接收问题)
print(f"收到文件: {file.filename}, 类型: {file.content_type}")
# 2. 读取图像(pil.image打开)
image = image.open(file.file)
print(f"原始图像 - 尺寸: {image.size}, 模式: {image.mode}")
# 3. 图像预处理
input_tensor = preprocess_image(image)
print(f"预处理后 - 张量维度: {input_tensor.shape}, 数据类型: {input_tensor.dtype}")
# 4. 模型预测(禁用梯度计算,节省资源)
with torch.no_grad():
output = model(input_tensor) # 模型输出:(1,10)(1个样本,10个类别概率)
predicted_digit = torch.argmax(output, dim=1).item() # 取概率最大的类别
# 5. 返回结果(json格式,前端可直接解析)
return {"predicted_digit": predicted_digit}
except exception as e:
# 异常捕获(打印错误信息,返回错误提示)
print(f"处理请求时出错: {str(e)}")
return {"error": str(e)}
# 启动服务(当脚本直接运行时)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000) # 0.0.0.0允许局域网访问,端口8000
4 模型训练(pytorch + mnist)
4.1 训练核心目标
生成可复用的权重文件(lenet5_mnist.pth),该模型在mnist测试集上准确率为98.17%,准确率还算不错,用它来为后端提供预测能力。
4.2 训练脚本实现(cnn_proj.py)
4.2.1 数据准备(prepare_data)
加载mnist数据集,应用与后端一致的预处理(归一化),用dataloader按批次加载:
import torch
import torch.nn as nn
from torch.utils.data import dataloader
from torchvision import transforms, datasets
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcparams['font.sans-serif'] = ['simsun']
plt.rcparams['axes.unicode_minus'] = false
def prepare_data():
# 数据转换 pipeline(与后端预处理逻辑一致)
transform = transforms.compose([
transforms.totensor(), # 转为张量:(h,w,c)→(c,h,w),值归一化到0-1
transforms.normalize(0.1307, 0.3081) # 标准化(均值+标准差)
])
# 加载训练集(train=true),自动下载到./dataset/mnist/
train_dataset = datasets.mnist(
root='./dataset/mnist/',
train=true,
download=true,
transform=transform
)
# 加载测试集(train=false)
test_dataset = datasets.mnist(
root='./dataset/mnist/',
train=false,
download=true,
transform=transform
)
# 创建dataloader(按批次加载,训练集打乱)
train_loader = dataloader(
train_dataset,
batch_size=256, # 批次大小(根据内存调整,256兼顾速度与内存)
shuffle=true # 训练集打乱,增强泛化能力
)
test_loader = dataloader(
test_dataset,
batch_size=256,
shuffle=false # 测试集无需打乱
)
return train_loader, test_loader
4.2.2 模型训练(train_model)
定义训练循环,包含“前向传播→损失计算→反向传播→参数更新”核心步骤:
def train_model(model, train_loader, epochs=5, lr=0.9):
# 1. 损失函数:交叉熵损失(分类任务专用,含softmax激活)
criterion = nn.crossentropyloss()
# 2. 优化器:随机梯度下降(sgd),lr=0.9为lenet5经典学习率
optimizer = torch.optim.sgd(model.parameters(), lr=lr)
# 3. 记录损失(用于绘制曲线,观察训练效果)
train_losses = []
# 4. 训练循环
print("\n开始训练...")
for epoch in range(epochs):
model.train() # 切换为训练模式(启用dropout/batchnorm)
total_loss = 0.0
# 遍历训练集批次
for batch_idx, (images, labels) in enumerate(train_loader):
# 前向传播:输入图像,获取模型输出
outputs = model(images)
# 计算损失:输出与真实标签的差异
loss = criterion(outputs, labels)
# 反向传播与参数更新
optimizer.zero_grad() # 清空上一轮梯度(避免累积)
loss.backward() # 反向传播计算梯度
optimizer.step() # 根据梯度更新模型参数
# 记录损失
train_losses.append(loss.item())
total_loss += loss.item()
# 每100个批次打印一次中间结果
if (batch_idx + 1) % 100 == 0:
print(f"轮次 [{epoch+1}/{epochs}], 批次 [{batch_idx+1}/{len(train_loader)}], "
f"当前批次损失: {loss.item():.4f}")
# 打印本轮平均损失
avg_loss = total_loss / len(train_loader)
print(f"轮次 [{epoch+1}/{epochs}] 平均损失: {avg_loss:.4f}")
# 5. 绘制损失曲线(直观观察训练收敛情况)
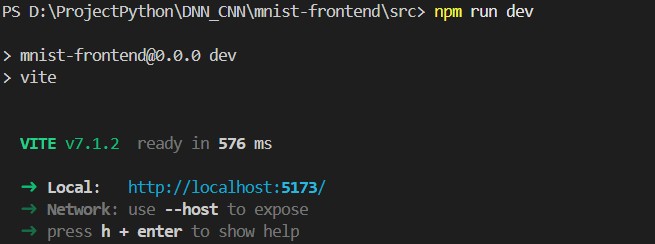
plt.figure(figsize=(10, 4))
plt.plot(train_losses, label='训练损失')
plt.xlabel('批次')
plt.ylabel('损失值')
plt.title('训练损失变化曲线')
plt.legend()
plt.show()
# 6. 保存模型权重(仅保存状态字典,节省空间)
torch.save(model.state_dict(), 'lenet5_mnist.pth')
print(f"模型已保存为 'lenet5_mnist.pth'")
return model, train_losses
4.2.3 模型测试(test_model)
评估模型在测试集上的准确率,验证泛化能力:
def test_model(model, test_loader):
model.eval() # 切换为评估模式
correct = 0 # 正确预测数
total = 0 # 总样本数
# 禁用梯度计算(测试阶段无需更新参数)
with torch.no_grad():
print("\n开始测试...")
for images, labels in test_loader:
outputs = model(images)
_, predicted = torch.max(outputs.data, 1) # 取概率最大的类别
total += labels.size(0)
correct += (predicted == labels).sum().item() # 统计正确数
# 计算并打印准确率
accuracy = 100 * correct / total
print(f"测试集准确率: {accuracy:.2f}%")
return accuracy
4.2.4 主函数(串联训练流程)
def main():
# 步骤1:准备数据
train_loader, test_loader = prepare_data()
print("数据准备完成,训练集样本数:", len(train_loader.dataset),
"测试集样本数:", len(test_loader.dataset))
# 步骤2:初始化模型(与后端lenet5完全一致)
model = lenet5()
print("\nlenet-5模型初始化完成")
# 步骤3:训练模型
trained_model, losses = train_model(model, train_loader, epochs=5)
# 步骤4:测试模型
test_model(trained_model, test_loader)
if __name__ == "__main__":
main()
5 完整项目操作流程
5.1 前置准备
安装基础环境:
搭建项目目录:
- 在
d:\projectpython\下创建dnn_cnn文件夹(根目录)。 - 在
dnn_cnn下创建mnist-frontend文件夹(前端目录)。
安装依赖:
- 打开命令提示符(cmd),执行python依赖安装:
pip install fastapi uvicorn torch torchvision pillow numpy
- 进入前端目录,执行vue依赖安装:
cd d:\projectpython\dnn_cnn\mnist-frontend npm create vue@latest . # 初始化vue项目,全部选“no”(简化配置) npm install axios
5.2 模型训练(可选,已有权重可跳过)
在dnn_cnn根目录创建cnn_proj.py,第4章的训练脚本程序放在该py文件里。
运行训练脚本:
cd d:\projectpython\dnn_cnn python cnn_proj.py
等待训练完成,根目录会生成lenet5_mnist.pth(权重文件),这个时候可以管擦测试集准确率,一般来说满足≥95%就可以了。
比如我这边自己训练的,
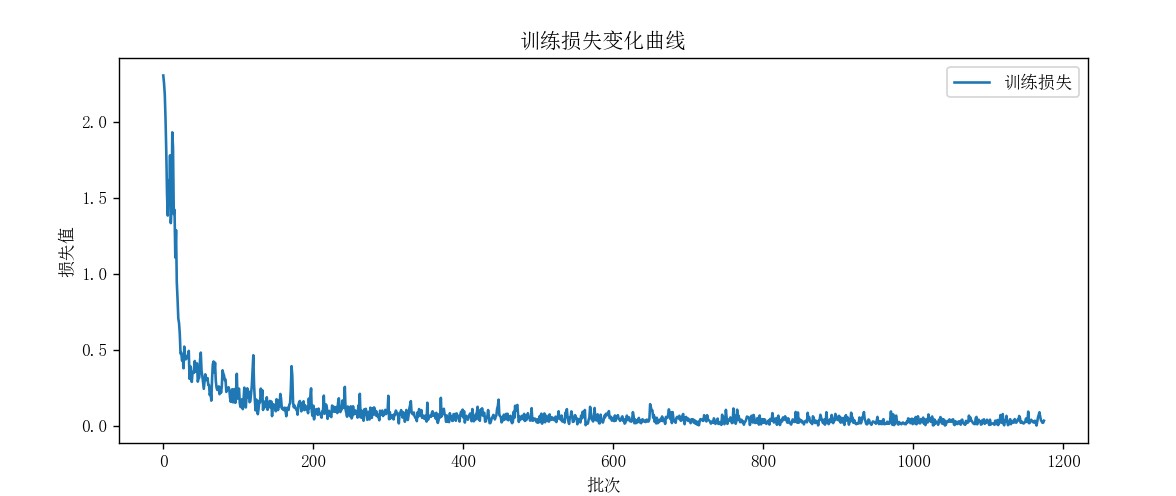
从训练结果来看,这个 lenet-5 模型在 mnist 测试集上达到了98.17% 的准确率,对于基础的手写数字识别任务来说,这个性能算是比较理想的,直接用于简单的手写数字识别这个实际场景是足够的。
5.3 后端部署
在dnn_cnn根目录创建main.py,程序详见第3章的后端脚本程序。
确保lenet5_mnist.pth在根目录下,启动后端服务:
python main.py
看到“uvicorn running on http://0.0.0.0:8000”表示启动成功,不要关闭cmd窗口。
这里有两个点要说清楚,
第一,如果直接在 python 里运行 main.py(比如点击 ide 的“运行”按钮),程序会加载模型 → 定义 fastapi 实例 → 定义路由,但不会但不会启动 web 服务!代码里的 api 接口(/predict )根本没法被外部访问, postman 也连不上。
第二,uvicorn main:app --reload 是干啥的? uvicorn 是一个 asgi 服务器,作用是:
- 找到你的
main.py文件,加载里面的app = fastapi()实例 - 启动一个 web 服务,让你的 api(
/predict)能被外部访问(比如 postman、前端页面 ) --reload:文件改动时自动重启服务(开发时超方便,不用手动重启 )
main.py完整程序如下:
# 后端 main.py(pytorch 版本)
from fastapi import fastapi, file, uploadfile
from fastapi.middleware.cors import corsmiddleware
import torch
import torch.nn as nn
from pil import image
import numpy as np
app = fastapi()
# 允许跨域
app.add_middleware(
corsmiddleware,
allow_origins=["*"],
allow_credentials=true,
allow_methods=["*"],
allow_headers=["*"],
)
# 定义与cnn_proj.py中一致的lenet5模型结构
class lenet5(nn.module):
def __init__(self):
super(lenet5, self).__init__()
self.net = nn.sequential(
nn.conv2d(in_channels=1, out_channels=6, kernel_size=5, padding=2),
nn.tanh(),
nn.avgpool2d(kernel_size=2, stride=2),
nn.conv2d(in_channels=6, out_channels=16, kernel_size=5),
nn.tanh(),
nn.avgpool2d(kernel_size=2, stride=2),
nn.conv2d(in_channels=16, out_channels=120, kernel_size=5),
nn.tanh(),
nn.flatten(),
nn.linear(in_features=120, out_features=84),
nn.tanh(),
nn.linear(in_features=84, out_features=10)
)
def forward(self, x):
return self.net(x)
# 初始化模型
model = lenet5()
# 加载权重(无需修改键名,直接匹配)
state_dict = torch.load('lenet5_mnist.pth', map_location=torch.device('cpu'))
model.load_state_dict(state_dict)
model.eval() # 切换为评估模式
# 图像预处理(适配mnist数据集的预处理方式)
def preprocess_image(image):
# 确保图像转为灰度图(即使前端已处理,后端再次确认)
image = image.convert('l') # 转为灰度图
# 确保图像尺寸为28x28(即使前端已处理,后端再次确认)
image = image.resize((28, 28), image.resampling.lanczos) # 使用高质量插值方法
# 转换为numpy数组并归一化
image = np.array(image, dtype=np.float32) # 转为数组
# 按照训练时的方式归一化(mnist的均值和标准差)
mean = 0.1307
std = 0.3081
image = (image / 255.0 - mean) / std # 先归一化到0-1再标准化
# 确保输入维度正确
image = np.expand_dims(image, axis=0) # 增加通道维度 (1,28,28)
image = np.expand_dims(image, axis=0) # 增加batch维度 (1,1,28,28)
return torch.tensor(image)
# 预测接口
@app.post("/predict")
async def predict_digit(file: uploadfile = file(...)):
try:
# 打印文件基本信息用于调试
print(f"收到文件: {file.filename}, 类型: {file.content_type}")
# 读取图像
image = image.open(file.file)
print(f"原始图像 - 尺寸: {image.size}, 模式: {image.mode}") # 检查图像初始状态
# 预处理
input_tensor = preprocess_image(image)
print(f"预处理后 - 张量维度: {input_tensor.shape}, 数据类型: {input_tensor.dtype}") # 检查处理后状态
# 预测
with torch.no_grad():
output = model(input_tensor)
predicted_digit = torch.argmax(output, dim=1).item()
return {"predicted_digit": predicted_digit}
except exception as e:
# 打印异常信息用于调试
print(f"处理请求时出错: {str(e)}")
return {"error": str(e)}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)```
接下来简单展示一下启动步骤:
#### 1. 打开终端,进入 `main.py` 所在目录
以我的文件结构来举例:
d:\projectpython\dnn_cnn
├── main.py
├── cnn_proj.py
└── lenet5_mnist.pth
在 **vs code** 里: - 点击左侧“资源管理器”,找到 `dnn_cnn` 文件夹 - 点击顶部菜单 **终端 → 新建终端**(会自动进入当前目录 ) - 也可以直接用cd + 文件路径 #### 2. 运行 `uvicorn` 命令 在终端里输入: ```bash uvicorn main:app --reload
main:app:告诉 uvicorn:
- 找
main.py文件(main) - 加载里面的
app = fastapi()实例(app)
--reload:开发模式,改代码后自动重启
3. 看启动结果
如果成功,终端会显示:
info: uvicorn running on http://127.0.0.1:8000 (press ctrl+c to quit) info: started reloader process [12345] info: started server process [12346] info: waiting for application startup. info: application startup complete.
这说明:
- 你的 api 服务启动了,地址是
http://127.0.0.1:8000 - 现在可以用 postman 访问
http://127.0.0.1:8000/predict测试

如果想要保险起见,可以先用下面这一步来测试一下,测试下api的情况。
4. 测试 api(用 postman 或浏览器)
打开 postman:
- 请求方法:post
- url:
http://127.0.0.1:8000/predict
** body → form-data**:
key选file,类型选filevalue选一张手写数字的图片(28x28 黑白图最佳 )
发送请求后,就能看到返回的 predicted_digit(识别结果 )
打开后配置请求信息:
step 1:选请求方法 + 填 url
- 选 post(必须和你
main.py里的@app.post("/predict")对应); - 中间 url 输入框,填
http://127.0.0.1:8000/predict(就是你 fastapi 服务的地址 + 接口名)。
step 2:配置 body(上传图片)
- 点击请求下方的 “body” 标签 → 勾选 “form data”(表单上传,和
main.py接收uploadfile对应); - 第一行“key”输入
file(必须和main.py里predict(file: uploadfile = file(...))的参数名一致); - 第一行“value”右侧,点击 “file” 按钮(默认是“text”,要改成文件上传),然后选择一张你的手写数字图片(28x28 黑白图最佳,手机拍的手写数字照片也能试)。
step 3:发送请求
- 点击右上角的 “send” 按钮(蓝色箭头),发送请求。
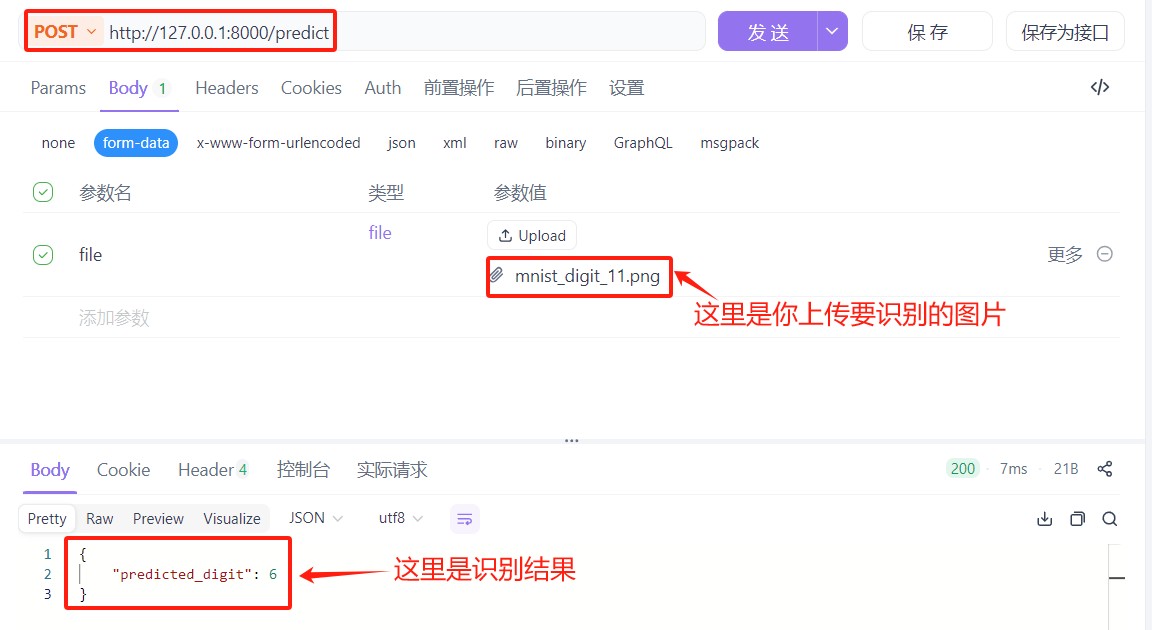
发送后,右侧会显示服务器返回的结果:
- 成功情况:如果返回类似
{"predicted_digit": 5},说明模型识别出图片里的数字是 5,api 调用成功!
常见问题排查:
- 若显示“connection refused”:检查 fastapi 服务是否启动(终端里的
uvicorn命令有没有在运行); - 若显示“找不到文件”:检查
main.py里torch.load("lenet5_mnist.pth")的模型路径是否正确,确保lenet5_mnist.pth和main.py在同一目录; - 若识别结果错误:检查
preprocess_image函数的预处理逻辑(比如是否转灰度、是否 resize 到 28x28),要和训练时完全一致。
5.4 前端部署
首先确保你的 node.js 环境已经准备好,接下来用 vue3 + vite 实现手写数字识别的前端界面并和后端 api 打通:
5.4.1 创建 vue3 + vite 项目
打开终端(cmd/powershell/vs code 终端都可以 );
创建项目(按顺序执行 ):
# 1. 创建 vue3 项目(项目名 mnist-frontend,模板选 vue) npm create vite@latest mnist-frontend -- --template vue # 2. 进入项目目录 cd mnist-frontend # 3. 安装依赖(等待安装完成) npm install # 4. 启动开发环境(启动后,浏览器访问 http://127.0.0.1:5173) npm run dev
执行完后,浏览器会自动打开 vue3 初始页面(或手动访问 http://127.0.0.1:5173 ),看到 vue 的欢迎界面,说明项目创建成功。

5.4.2 编写前端界面
在 vs code 中打开项目目录 mnist-frontend,找到 src/app.vue 文件,替换成以下完整程序:
<template>
<div class="container">
<h1>手写数字识别</h1>
<!-- 主画布 -->
<canvas
ref="canvas"
width="280"
height="280"
@mousedown="startdrawing"
@mousemove="draw"
@mouseup="stopdrawing"
@mouseleave="stopdrawing"
></canvas>
<!-- 调试画布(v-show 保持 dom 存在) -->
<div class="debug-section" v-show="showdebug">
<h3>预处理后图像(28x28 放大)</h3>
<canvas ref="debugcanvas" width="280" height="280"></canvas>
<p class="debug-info">实际尺寸 28x28 | 放大 10 倍</p>
</div>
<!-- 控制按钮 -->
<div class="buttons">
<button @click="clearcanvas" :disabled="isloading">清除画布</button>
<button @click="predictdigit" :disabled="isloading">
{{ isloading ? '识别中...' : '识别' }}
</button>
<button @click="toggledebug">显示/隐藏调试</button>
</div>
<!-- 结果与错误提示 -->
<div class="result" v-if="recognitionresult">识别结果:{{ recognitionresult }}</div>
<div class="error" v-if="errormessage">错误:{{ errormessage }}</div>
</div>
</template>
<script setup>
import { ref, onmounted, nexttick, watch } from 'vue';
import axios from 'axios';
// 响应式变量
const canvas = ref(null);
const debugcanvas = ref(null);
const showdebug = ref(false);
const isdrawing = ref(false);
const isloading = ref(false);
const recognitionresult = ref('');
const errormessage = ref('');
let ctx = null;
let debugctx = null;
let lastx = 0;
let lasty = 0;
// 初始化画布(确保 dom 渲染完成)
onmounted(async () => {
await nexttick(); // 等待 dom 完全渲染
// 主画布初始化
if (canvas.value) {
ctx = canvas.value.getcontext('2d', { willreadfrequently: true });
if (ctx) {
ctx.fillstyle = '#ffffff'; // 改为纯白背景,与mnist训练数据背景一致
ctx.fillrect(0, 0, 280, 280);
ctx.linewidth = 12; // 调整画笔宽度,避免预处理后线条过细
ctx.strokestyle = 'black';
ctx.linecap = 'round'; // 画笔端点圆润,避免锯齿
ctx.linejoin = 'round'; // 画笔拐角圆润,提升绘制体验
} else {
errormessage.value = '主画布初始化失败,请刷新';
}
} else {
errormessage.value = '未找到主画布元素,请检查代码';
}
// 调试画布初始化(v-show 已确保 dom 存在)
if (debugcanvas.value) {
debugctx = debugcanvas.value.getcontext('2d', { willreadfrequently: true });
if (debugctx) {
debugctx.fillstyle = '#ffffff';
debugctx.fillrect(0, 0, 280, 280);
} else {
console.warn('调试画布初始化失败(不影响主功能)');
}
}
});
// 监听 showdebug 变化,重新初始化调试画布
watch(showdebug, (newval) => {
if (newval && debugcanvas.value && !debugctx) {
debugctx = debugcanvas.value.getcontext('2d', { willreadfrequently: true });
if (debugctx) {
debugctx.fillstyle = '#ffffff';
debugctx.fillrect(0, 0, 280, 280);
}
}
});
// 绘制逻辑 - 修复坐标计算与绘制连续性问题
function startdrawing(e) {
if (!ctx) return;
isdrawing.value = true;
const rect = canvas.value.getboundingclientrect();
// 计算画布内真实坐标(处理画布缩放场景)
lastx = (e.clientx - rect.left) * (canvas.value.width / rect.width);
lasty = (e.clienty - rect.top) * (canvas.value.height / rect.height);
ctx.beginpath();
ctx.moveto(lastx, lasty);
// 绘制初始点(解决点击画布不拖动无痕迹问题)
ctx.lineto(lastx + 0.1, lasty + 0.1);
ctx.stroke();
}
function draw(e) {
if (!ctx || !isdrawing.value) return;
const rect = canvas.value.getboundingclientrect();
// 计算画布内真实坐标
const x = (e.clientx - rect.left) * (canvas.value.width / rect.width);
const y = (e.clienty - rect.top) * (canvas.value.height / rect.height);
ctx.lineto(x, y);
ctx.stroke();
lastx = x;
lasty = y;
}
function stopdrawing() {
isdrawing.value = false;
}
// 清除画布
function clearcanvas() {
if (!ctx) return;
ctx.fillstyle = '#ffffff';
ctx.fillrect(0, 0, 280, 280);
// 清除调试画布
if (debugctx) {
debugctx.fillstyle = '#ffffff';
debugctx.fillrect(0, 0, 280, 280);
}
recognitionresult.value = '';
errormessage.value = '';
}
// 切换调试视图
function toggledebug() {
showdebug.value = !showdebug.value;
}
// 预测逻辑 - 修复formdata构建与错误处理
async function predictdigit() {
if (!ctx) {
errormessage.value = '画布未初始化,请刷新';
return;
}
isloading.value = true;
errormessage.value = '';
try {
// 检查画布是否有内容(优化阈值,适配纯白背景)
const isempty = await checkcanvasempty();
if (isempty) {
errormessage.value = '请先绘制数字';
isloading.value = false;
return;
}
// 转换为 28x28 灰度图(前端预处理)
const { imgblob, tempcanvas } = await canvasto28x28gray(canvas.value);
if (!imgblob) {
throw new error('图像转换失败,无法生成有效图像数据');
}
// 显示调试图像(放大)
if (showdebug.value && debugctx && tempcanvas) {
debugctx.drawimage(tempcanvas, 0, 0, 280, 280);
}
// 调用后端识别 - 修复formdata构建,移除手动设置content-type(axios自动处理)
const formdata = new formdata();
formdata.append('file', imgblob, 'digit.png'); // 参数名改为'file',与后端uploadfile参数名匹配
const response = await axios.post(
'http://localhost:8000/predict',
formdata
// 移除手动设置的content-type,避免边界符缺失问题
);
// 验证响应数据格式
if (response.data && 'predicted_digit' in response.data) {
recognitionresult.value = response.data.predicted_digit;
} else {
throw new error('后端返回数据格式异常');
}
} catch (error) {
// 精细化错误提示
if (error.response) {
// 后端返回错误(如422、500)
errormessage.value = `识别失败:${error.response.status} - ${
error.response.data?.error || error.response.data?.detail || '未知错误'
}`;
} else if (error.request) {
// 无响应(如后端未启动、跨域问题)
errormessage.value = '识别失败:无法连接后端服务,请检查后端是否运行';
} else {
// 前端本地错误(如图像转换)
errormessage.value = `识别失败:${error.message}`;
}
console.error('预测错误详情:', error);
} finally {
isloading.value = false;
}
}
// 辅助函数:检查画布是否为空(优化阈值,适配纯白背景)
async function checkcanvasempty() {
return new promise((resolve) => {
if (!ctx) {
resolve(true);
return;
}
const imagedata = ctx.getimagedata(0, 0, 280, 280);
const data = imagedata.data;
const threshold = 250; // 纯白背景下,低于250视为有绘制内容
for (let i = 0; i < data.length; i += 4) {
const brightness = (data[i] + data[i+1] + data[i+2]) / 3;
if (brightness < threshold) {
resolve(false);
return;
}
}
resolve(true);
});
}
// 辅助函数:canvas 转 28x28 灰度图(修复图像反转逻辑,匹配mnist)
function canvasto28x28gray(canvasel) {
return new promise((resolve) => {
const tempcanvas = document.createelement('canvas');
tempcanvas.width = 28;
tempcanvas.height = 28;
const tempctx = tempcanvas.getcontext('2d');
if (!tempctx) {
resolve({ imgblob: null, tempcanvas: null });
return;
}
// 1. 绘制时保持图像比例,避免拉伸(居中绘制)
tempctx.fillstyle = '#ffffff';
tempctx.fillrect(0, 0, 28, 28); // 先填充纯白背景
// 计算缩放比例(确保图像完全放入28x28画布,保留比例)
const scale = math.min(28 / canvasel.width, 28 / canvasel.height);
const xoffset = (28 - canvasel.width * scale) / 2;
const yoffset = (28 - canvasel.height * scale) / 2;
tempctx.drawimage(
canvasel,
0, 0, canvasel.width, canvasel.height,
xoffset, yoffset, canvasel.width * scale, canvasel.height * scale
);
// 2. 转灰度并反转(mnist:白底黑字 → 黑底白字,增强特征)
const imagedata = tempctx.getimagedata(0, 0, 28, 28);
const data = imagedata.data;
for (let i = 0; i < data.length; i += 4) {
// 计算亮度(灰度值)
const brightness = (data[i] + data[i+1] + data[i+2]) / 3;
// 反转:白色(高亮度)→ 黑色(0),黑色(低亮度)→ 白色(255),匹配mnist数据分布
const inverted = 255 - brightness;
data[i] = data[i+1] = data[i+2] = inverted;
data[i+3] = 255; // 保持不透明
}
tempctx.putimagedata(imagedata, 0, 0);
// 3. 生成blob(指定质量,避免数据损坏)
tempcanvas.toblob((blob) => {
resolve({ imgblob: blob, tempcanvas: tempcanvas });
}, 'image/png', 1.0); // 1.0表示无损压缩,确保图像细节不丢失
});
}
</script>
<style scoped>
.container {
text-align: center;
padding: 20px;
max-width: 600px;
margin: 0 auto;
}
canvas {
border: 2px solid #ccc;
margin: 10px auto;
display: block;
background-color: #ffffff; /* 匹配初始化的纯白背景 */
touch-action: none;
}
.debug-section {
margin-top: 20px;
padding: 15px;
background-color: #f9f9f9;
border-radius: 8px;
}
.debug-info {
color: #666;
font-size: 14px;
margin-top: 5px;
}
.buttons {
margin: 20px 0;
}
button {
padding: 10px 20px;
margin: 0 10px;
cursor: pointer;
background-color: #42b983;
color: white;
border: none;
border-radius: 4px;
transition: opacity 0.3s;
}
button:disabled {
background-color: #ccc;
cursor: not-allowed;
opacity: 0.7;
}
button:hover:not(:disabled) {
opacity: 0.8;
}
.result {
font-size: 20px;
margin-top: 20px;
color: #42b983;
}
.error {
font-size: 16px;
color: #e53e3e;
margin-top: 10px;
}
</style>
已经在mnist-frontend/src目录下创建好app.vue,程序详见第2章的前端脚本程序。
启动前端服务:
cd d:\projectpython\dnn_cnn\mnist-frontend\src npm run dev
看到local: http://localhost:5173/表示启动成功,复制链接在浏览器打开。
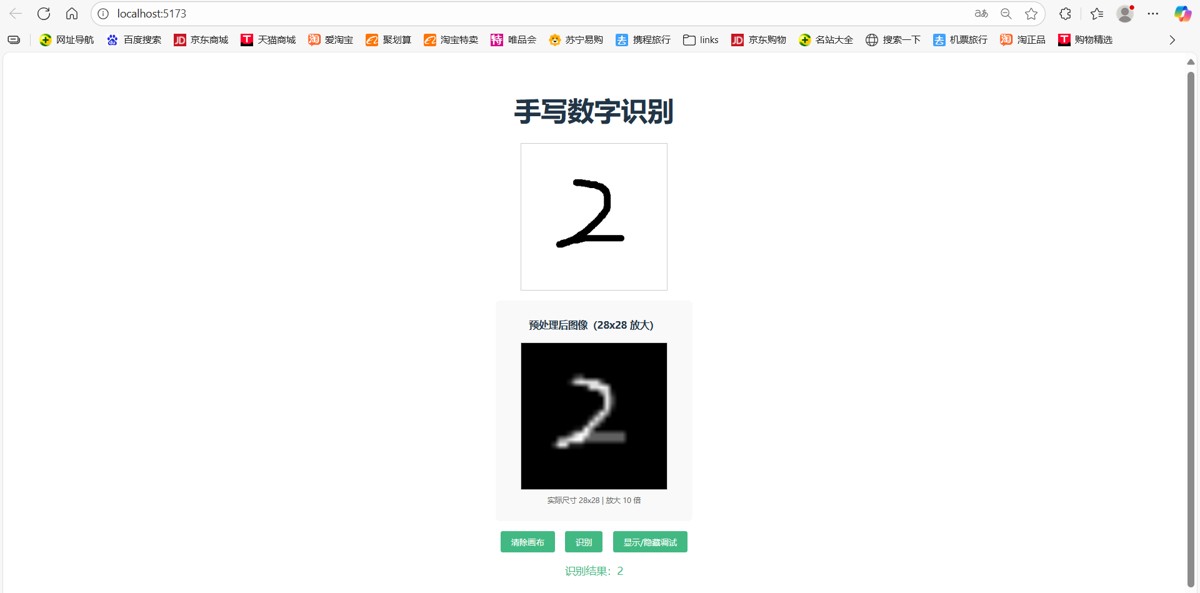
5.5 功能测试
- 在浏览器页面的画布上,用鼠标绘制0-9任意数字。
- 点击
显示/隐藏调试,查看28×28预处理图像。 - 点击
识别按钮,下方会显示识别结果。 - 点击
清除画布可重新绘制,测试其他数字。
结果如下,只列举部分:

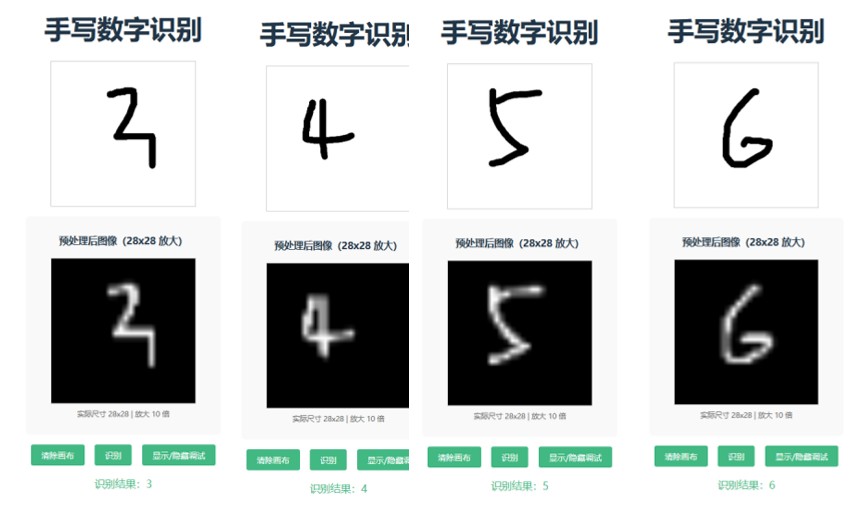

当然,你在终端上也可以看到具体的信息,如果出现错误也可以从中看到是什么错误:
在前端页面上也可以通过fn + 12来打开浏览器后台查看具体信息。
在你创建好后,如果未更改前后端文件,后续你的启动步骤就只需要两步:
1.启动后端api服务:
uvicorn main:app --reload
2.启动前端开发环境:
npm run dev
6 问题复盘与解决
6.1 错误1:422 unprocessable entity(前端请求后端失败)
这个算是一开始很常见的问题,具体来说很大概率基本都是参数名与后端不匹配。
- 原因:前端formdata参数名与后端不匹配(原前端用
image,后端需file);手动设置content-type: multipart/form-data导致请求边界符缺失。 - 解决思路:前端
formdata.append('file', imgblob, 'digit.png');删除axios的headers配置,让axios自动处理。
6.2 错误2:预测结果不准确(如“3”识别为“8”)
- 原因:前端图像未反转(与mnist黑底白字分布相反);画笔过细导致预处理后线条消失。
- 解决思路:在
canvasto28x28gray中添加灰度反转(255 - brightness);将ctx.linewidth设为12-15。
7 小结
7.1 收获
技术栈整合:切身体会vue(前端交互)、fastapi(后端接口)和pytorch(cnn模型)的前后端分离开发模式,理解各模块间的数据流转逻辑(图像→blob→formdata→张量→预测结果)。
关键技术点:
图像预处理:灰度转换、尺寸缩放、颜色反转、归一化,核心是“匹配模型训练时的数据分布”。模型部署:训练权重加载、评估模式切换、无梯度预测,确保模型高效且正确运行。问题排查:通过调试信息(如后端打印的文件尺寸、张量维度)定位数据格式问题,通过精细化错误提示快速排查接口问题。
7.2 可扩展方向
- 功能扩展:支持手写字母识别(替换数据集为emnist)、多数字识别(修改模型输出层为多分类)。
- 性能优化:用resnet-18替换lenet5提升准确率,用tensorrt加速模型推理,前端添加防抖绘制减少冗余数据。
- 场景适配:开发移动端页面,添加历史记录功能,部署到云服务器实现公网访问,但相关知识目前还没学完,后面有时间试试。
7.3 可复用方向
本笔记的环境搭建→代码实现→操作流程可直接复用于图像分类类项目(如验证码识别、水果分类),只需替换三个部分:
- 数据集:将mnist替换为目标数据集(如emnist、fruits-360)。
- 模型结构:根据数据集复杂度调整cnn层数(简单任务用lenet5,复杂任务用resnet)。
- 前端交互:根据输入类型修改交互组件(将画布改为图片上传)。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。




发表评论