这篇文章给所有想要学习rust语言的同学进行一个学习参考,rust语言是一款正在崛起的语言,希望每个出于热爱或者工作学习rust的朋友都能有收获

rust的故事
2006 年,graydon hoare 这一年 29 岁,是 mozilla 浏览器公司的程序员。有一天他下班回到温哥华的公寓,结果发现电梯又坏了——原因是系统崩溃了,而且不是第一次了。
他住在 21 楼,只能硬着头皮爬楼梯。一边爬,一边越想越气:“我们搞计算机的,居然连个不会崩溃的电梯程序都做不出来,简直离谱。”
他很清楚,这类故障常常是内存管理出问题。像电梯这种嵌入式设备里,软件大多是用 c 或 c++ 写的。这类语言运行快、占空间小,但也容易出错,尤其是容易引入“内存漏洞”——只要处理不当,程序就会直接崩溃。
微软曾经统计过,它自家代码中高达 70% 的漏洞,都和 c/c++ 写的内存管理有关。
大多数人可能就是骂几句了事,但 hoare 决定做点什么。他回到家,打开笔记本,开始设计一门新语言。他想要一种既能写出小而快的程序,又能在根本上避免内存 bug 的语言。
他给这门语言起名叫 rust,灵感来自一种非常顽强的真菌——在他眼里,这个名字意味着“为生存而过度设计”
这正是 rust 的设计哲学:
程序可以慢慢变旧,但不能悄悄变坏。
rust的发展历程
rust 的发展历程并不光鲜,甚至可以说一度接近夭折。它最早起源于 2006 年,是 mozilla 工程师 graydon hoare 在个人时间里发起的一个实验性项目,初衷很简单:摆脱 c/c++ 中长期困扰系统开发者的内存安全与并发问题。那时的 rust 只是一个个人尝试,没有明确的目标,也谈不上生态和稳定性。
2009 年 mozilla 接手 rust 后,这门语言并没有立刻走向成熟,反而经历了长期的方向摇摆与设计反复。早期的 rust 版本频繁推翻语法和特性,几乎每个版本都像一门新语言,学习成本极高,社区难以积累经验,mozilla 内部也开始质疑是否有必要继续投入资源维护这样一个复杂而激进的项目。2012 到 2014 年间,rust 迎来了第一次真正的生存危机,如果继续沿着原有路线发展,它很可能会就此消失。
真正的转折点发生在 rust 团队对自身设计的深刻反思之中。他们选择主动“刹车”,冻结特性,明确以所有权与借用系统为核心,放弃短期的灵活性与炫技,转而追求长期的稳定性与可维护性。这一决定虽然让 rust 在使用上显得严格而难学,却为它奠定了坚实的语言基础。2015 年 rust 1.0 正式发布,语法和语义趋于稳定,rust 才真正意义上“活了下来”。
然而,rust 并没有在 1.0 发布后立刻爆发。相当长一段时间里,它依然被认为学习曲线陡峭、编译缓慢、生态尚不成熟,更多是工程师欣赏却不敢在核心业务中使用的语言。直到云计算、大规模并发系统和安全问题成为现实压力,内存安全从“锦上添花”变成“刚性需求”,rust 才迎来了属于自己的时代。
随着 aws、microsoft、google 等大型公司在关键系统中采用 rust,linux 内核也开始引入 rust 支持,这门曾经濒临失败的语言逐渐进入主流视野。回顾 rust 的发展历史,它并不是赢在起点,而是在一次次否定与重构中,选择了最难却最稳的一条路,这也正是 rust 今天能够站在系统级编程舞台中央的原因。
好的,该说的基本都说了,下面就开始我们的rust内容教学。
rust环境安装
可以去官方下载安装工具来安装rust:rust安装工具
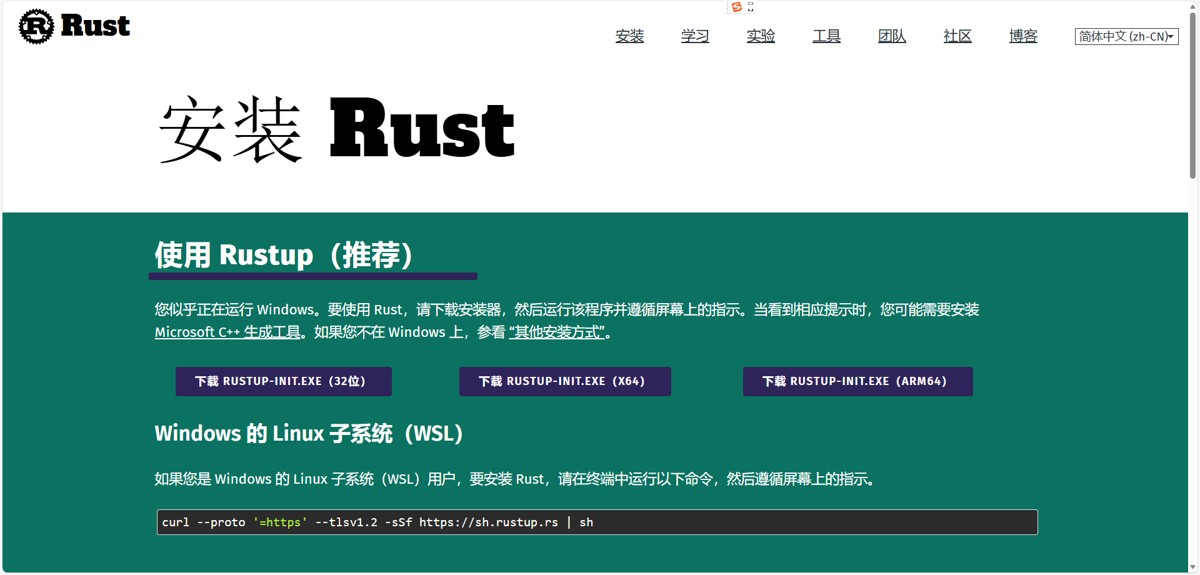
这里我们选择x64(一般的笔记本都是这个)。下载完成之后打开exe文件
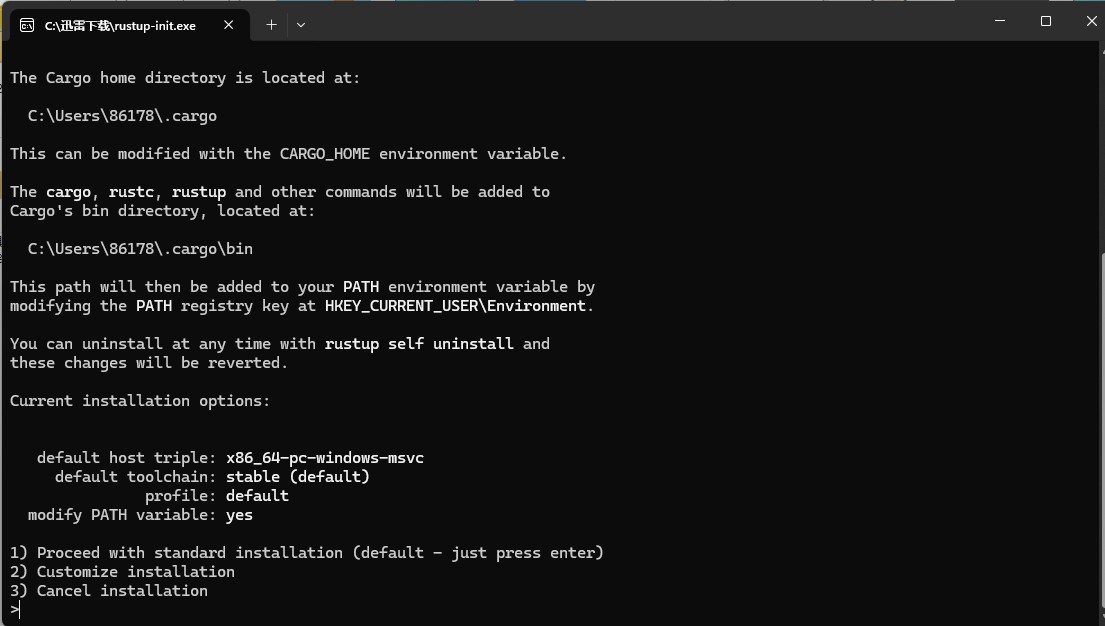
我这里已经安装过了,没有过程。第一次安装的话会自动安装完成,等待即可。
安装完成之后打开cmd控制台,输入下面的命令查看rust编译器版本
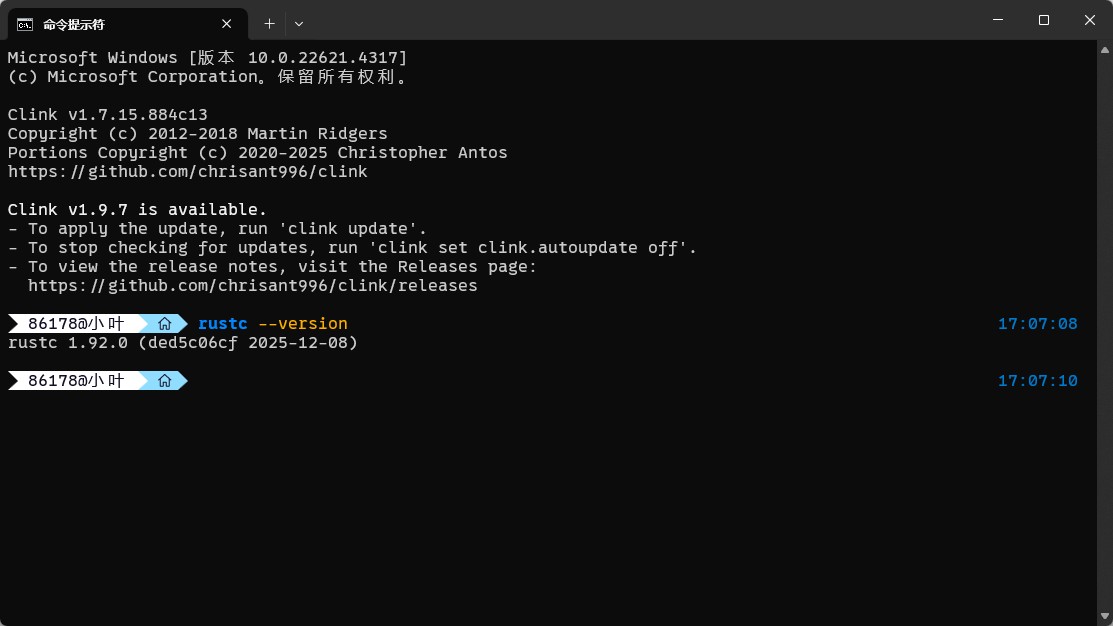
成功输出版本信息,说明安装成功
rust特性和使用场景
rust 并不是“语法炫技型语言”,它的每一个设计,几乎都围绕两个关键词:
安全(safety) 与 性能(performance)
内存安全:内存安全是rust最重要,也是最具代表性的特性,在传统系统级语言(c/c++)当中,常见的内存安全问题包括,空指针访问,野指针,内存泄漏,越界访问等等。rust在编译期间就通过“所有权系统”彻底避免这些问题”。
在保证安全的同时,rust 并没有牺牲性能。rust 的抽象大多是零成本抽象(zero-cost abstraction),例如模式匹配、迭代器、泛型和 trait,在编译后通常会被优化为与手写 c 代码相当的机器指令,不引入额外的运行时开销。这使得 rust 在性能上可以直接对标 c / c++,却大幅降低了出错概率。
rust 对并发安全的关注同样体现在语言层面。传统语言中常见的数据竞争、竞态条件,往往依赖文档约定或运行时检查,而 rust 通过类型系统和所有权规则,将“是否线程安全”变成了编译期问题。send、sync 等 trait 明确约束了数据能否跨线程传递,使得“无数据竞争的并发”成为语言级别的保证,而非最佳实践。
使用场景
正是由于这些特性,rust 非常适合用于对安全性和性能要求极高的场景,例如系统软件、网络服务、云基础设施、区块链、数据库、浏览器内核以及操作系统组件等。近年来,rust 也逐渐进入 web 后端、微服务和高并发服务领域,在保持接近底层性能的同时,显著提升了系统的稳定性和可维护性。
rust的ide选择
vscode
vscode:堪称编程界万金油编译器,含金量无需多言,安装对应的插件什么代码都能跑
网站链接:vscode下载地址
rustrover
rustrover:jetbrains家出品,必属精品,专业rust语言ide,含金量不多说了,可以自己找一下破解方法
网站链接:rustrover下载

下面我的代码编写都是以rustrover为例子
rust的重要概念
所有权系统
每一块内存,都有且只有一个“主人”。
let s = string::from("hello");
let t = s; // 所有权转移(move)
借用(borrowing)
不拥有,但可以临时使用。
fn print_len(s: &string) {
println!("{}", s.len());
}
move / copy 语义
所有权可以被显式或隐式转移。
let a = 10;
let b = a; // copy
let s1 = string::from("hi");
let s2 = s1; // move
crate(包)
rust 的最小编译单元,可以理解为 “一次被编译和链接的完整代码包”。
简要来说:
一个 crate 要么是 库(lib crate),要么是 可执行程序(binary crate)
编译时,rust 以 crate 为单位 进行编译和依赖管理
一个项目可以包含 多个 crate
对外暴露的代码由 crate 的 public api 决定
proc-macro crate(过程宏)
编译期运行的 rust 程序,用来“生成 rust 代码。它不是在运行时干活,而是在“编译 rust 代码时”帮你写代码
本质上是一个 独立的 crate
在 编译期执行
输入是 rust 代码,输出也是 rust 代码
用来减少样板代码、实现语法级扩展
常见的过程宏形式包括三种:
派生宏(derive):如
#[derive(debug)]属性宏(attribute):如
#[route("/hello")]函数式宏(function-like):如
sql!(...)
cargo
cargo 是 rust 的官方构建工具和包管理器,可以把它理解为 rust 世界里的“项目管家 + 构建系统 + 依赖管理器”,几乎所有现代 rust 项目都离不开它。
cargo 的核心配置文件是 cargo.toml,它描述了一个 rust 项目的“身份信息”和“依赖关系”,包括项目名、版本、使用的 rust 版本、依赖的第三方库(crate)以及构建配置。cargo 会根据这个文件自动下载依赖、解析版本、处理编译顺序。
rust变量类型
rust 是强类型 + 静态类型语言,变量的类型在编译期就必须确定。
整数类型(integer)
| 类型 | 位数 | 说明 |
|---|---|---|
| i8 / i16 / i32 / i64 / i128 | 有符号 | 常用 i32 |
| u8 / u16 / u32 / u64 / u128 | 无符号 | |
| isize / usize | 与平台相关 |
let a: i32 = -10; let b: u64 = 100; let idx: usize = 5;
浮点类型(floating-point)
| 类型 | 位数 |
|---|---|
| f32 | 单精度 |
| f64 | 双精度(默认) |
let pi: f64 = 3.14159;
布尔类型(boolean)
let ok: bool = true;
字符类型(char)
unicode 字符
占 4 字节
let c: char = '中'; let emoji: char = '🚀';
元组(tuple)
不同类型的组合
定长
let tup: (i32, f64, char) = (1, 2.0, 'a'); let (x, y, z) = tup;
数组(array)
相同类型
定长
存在栈上
let arr: [i32; 3] = [1, 2, 3];
切片(slice)
对数组或集合的引用
动态长度
let slice: &[i32] = &arr[0..2];
rust基础语法
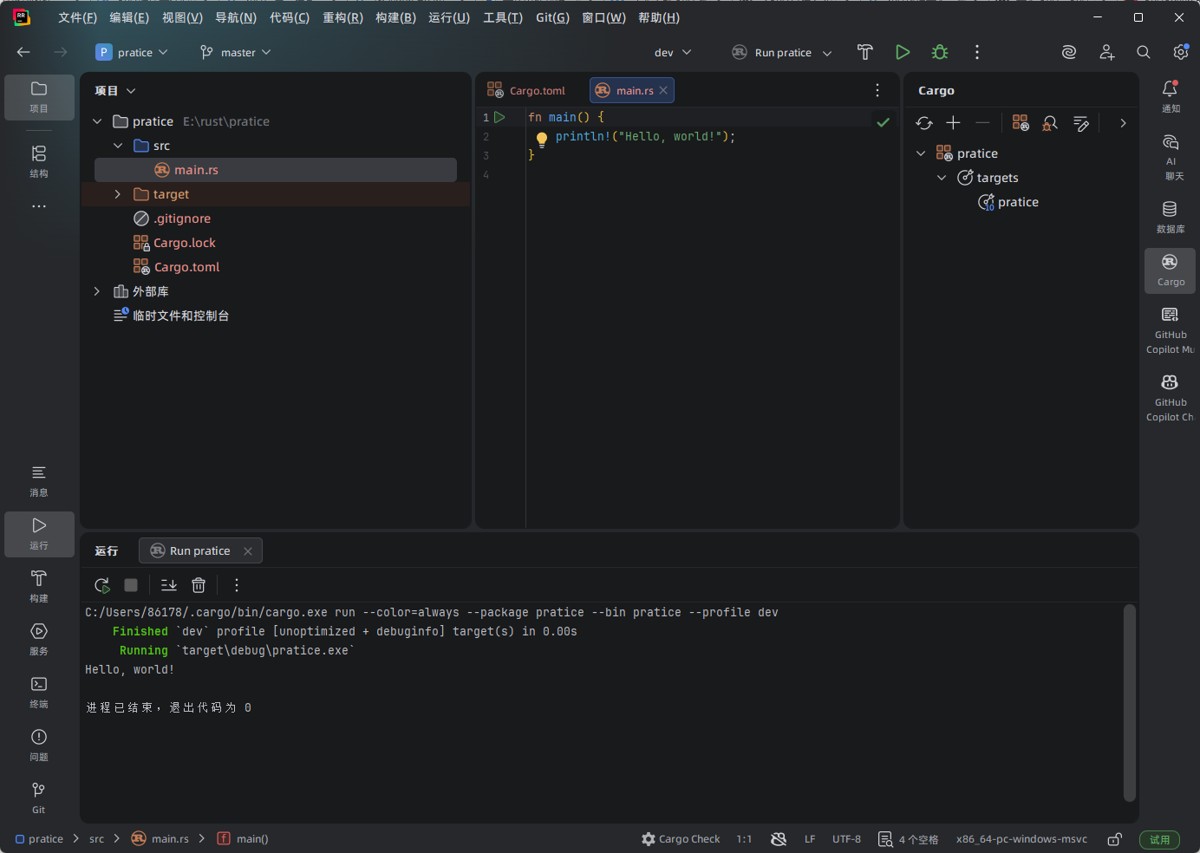
第一行代码hello world
fn main() {
println!("hello, world!");
}
变量声明(let / mut)
let x = 10; // 不可变(默认) let mut y = 20; // 可变 y += 1;
if 条件判断(没有三元运算符)
let n = 10;
if n > 0 {
println!("positive");
} else if n == 0 {
println!("zero");
} else {
println!("negative");
}
for 循环
for i in 0..5 {
println!("{}", i); // 0 ~ 4
}
包含右边界
for i in 0..=5 {
println!("{}", i); // 0 ~ 5
}
while 循环
let mut i = 0;
while i < 5 {
println!("{}", i);
i += 1;
}
loop 无限循环
let mut i = 0;
loop {
if i == 5 {
break;
}
i += 1;
}
loop需要返回值时
let result = loop {
if i > 10 {
break i * 2;
}
i += 1;
};
match 判断
rust没有switch的设计,使用match代替
let n = 2;
match n {
1 => println!("one"),
2 => println!("two"),
3 => println!("three"),
_ => println!("other"),
}
if let(简化match)
let x = some(5);
if let some(v) = x {
println!("{}", v);
}
break / continue
for i in 0..10 {
if i == 3 {
continue;
}
if i == 7 {
break;
}
println!("{}", i);
}
函数定义
rust的函数定义上和go挺像的,fn 函数名称(入参:类型)->返回类型。细节是最后一行返回内容时不需要分号。
fn add(a: i32, b: i32) -> i32 {
a + b // 最后一行是返回值(无分号)
}
注释
rust的注释和其他语言没什么区别,不多介绍了
// 单行注释 /* 多行注释 */ /// 文档注释(用于生成文档)
rust高级语法
下面则是深入一个rust的重要设计和概念,以下内容难度相对比较高和抽象,希望大家都不要放弃。
生命周期
生命周期是 rust 用来描述**引用“活多久”**的机制,它并不影响运行时行为,而是完全服务于编译期检查。通过生命周期,rust 可以在不使用垃圾回收的前提下,确保引用永远不会悬垂。生命周期的本质不是“让你写更多标注”,而是把“对象之间的依赖关系”显式地交给编译器验证。
代码示例:
// 'a 表示 x、y 和返回值共享同一个生命周期
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
// 返回的引用一定来自 x 或 y
if x.len() > y.len() { x } else { y }
}
fn main() {
let a = string::from("hello");
let b = string::from("rust");
// &a、&b 的生命周期都覆盖了 longest 的返回值
println!("{}", longest(&a, &b));
}
闭包和迭代器
rust 对函数式编程的支持体现在闭包和迭代器上。闭包可以捕获环境,并根据捕获方式自动推导 fn、fnmut、fnonce,而迭代器则通过惰性求值和组合操作,提供了极高的表达力。这些抽象在编译期会被完全优化,不引入额外运行时成本,是 rust “零成本抽象”理念的典型体现。
示例如下
// 'a 表示 x、y 和返回值共享同一个生命周期
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
// 返回的引用一定来自 x 或 y
if x.len() > y.len() { x } else { y }
}
fn main() {
let a = string::from("hello");
let b = string::from("rust");
// &a、&b 的生命周期都覆盖了 longest 的返回值
println!("{}", longest(&a, &b));
}
循环引用和自引用
在引入引用计数(如 rc / arc)后,循环引用成为一个必须正视的问题。rust 并不会自动替你处理这些情况,而是通过 weak 指针等机制,让开发者显式打破引用环。同时,自引用结构在 rust 中也是一个典型的高级难点,需要借助 pin 等机制来保证内存地址的稳定性。
代码示例:
use std::rc::{rc, weak};
use std::cell::refcell;
struct node {
next: refcell<option<rc<node>>>, // 强引用:拥有所有权
prev: refcell<option<weak<node>>>, // 弱引用:不增加计数
}
fn main() {
let a = rc::new(node {
next: refcell::new(none),
prev: refcell::new(none),
});
let b = rc::new(node {
next: refcell::new(none),
// weak 用于防止 a <-> b 循环引用
prev: refcell::new(some(rc::downgrade(&a))),
});
// a 强引用 b,但 b 不强引用 a
*a.next.borrow_mut() = some(b);
}
多线程并发模型
rust 的并发模型建立在“编译期无数据竞争”之上。通过 send、sync 以及所有权规则,rust 能在编译阶段阻止绝大多数并发错误。mutex、rwlock、channel 等并发工具在 rust 中并不神秘,但它们的安全使用是由类型系统强制保障的,而不是依赖约定
代码示例:
use std::sync::{arc, mutex};
use std::thread;
fn main() {
// arc:线程安全的引用计数
// mutex:保证同一时间只有一个线程修改数据
let counter = arc::new(mutex::new(0));
let mut handles = vec![];
for _ in 0..5 {
let c = arc::clone(&counter);
handles.push(thread::spawn(move || {
// lock() 返回互斥锁,作用域结束自动释放
*c.lock().unwrap() += 1;
}));
}
for h in handles {
h.join().unwrap();
}
println!("{}", *counter.lock().unwrap());
}
macro 宏编程
rust 的宏是编译期代码生成工具,分为声明宏和过程宏。宏并不是语法糖,而是一种元编程能力,可以用来减少重复代码、扩展语言表达能力,甚至构建领域专用语言(dsl)。许多 rust 生态中的“魔法”,本质都来自宏。
代码示例:
// 声明宏:在编译期展开代码
macro_rules! say_hello {
($name:expr) => {
println!("hello, {}", $name);
};
}
fn main() {
// 这里不是函数调用,而是宏展开
say_hello!("rust");
}
async / await 异步编程
rust 的异步模型是基于 future 的零成本抽象,async/await 只是语法层面的简化。不同于依赖运行时调度的语言,rust 将异步状态机编译成显式结构,由执行器驱动运行。这使得 rust 在高并发场景下既高效又可控。
代码如下:
// async fn 会被编译成一个实现了 future 的状态机
async fn hello() -> i32 {
42
}
#[tokio::main] // 启动异步执行器
async fn main() {
// await 驱动 future 运行,直到完成
let v = hello().await;
println!("{}", v);
}
错误处理
rust 采用 result 和 option 作为核心错误处理机制,避免了异常带来的隐式控制流。通过 ? 运算符,错误可以在保持代码简洁的同时被显式传播。错误在 rust 中是一等公民,而不是运行时的“意外情况”。
fn parse_num(s: &str) -> result<i32, std::num::parseinterror> {
// ?:成功则解包,失败则立刻返回 err
let n = s.parse::<i32>()?;
ok(n * 2)
}
fn main() {
match parse_num("10") {
ok(v) => println!("{}", v),
err(e) => println!("error: {}", e),
}
}
rust生态框架
后端框架
actix-web
actix-web 是一个高性能、偏底层控制的 rust 后端 web 框架,以性能著称,内部基于 actor 模型,在高并发场景下非常强
use actix_web::{get, app, httpserver, responder};
#[get("/hello")]
async fn hello() -> impl responder {
"hello actix-web"
}
#[actix_web::main]
async fn main() -> std::io::result<()> {
httpserver::new(|| {
app::new()
.service(hello)
})
.bind(("127.0.0.1", 8080))?
.run()
.await
}
axum
axum 是一个基于 tokio + tower 的现代 rust web 框架,强调类型安全、组合式设计,api 非常“rust 风格”。
use axum::{routing::get, router};
async fn hello() -> &'static str {
"hello axum"
}
#[tokio::main]
async fn main() {
let app = router::new()
.route("/hello", get(hello));
axum::server::bind(&"127.0.0.1:8080".parse().unwrap())
.serve(app.into_make_service())
.await
.unwrap();
}
数据库框架
diesel
github地址:https://github.com/diesel-rs/diesel

diesel 是 rust 中最成熟的 orm 框架,主打 编译期 sql 校验 和 强类型映射,非常安全,但使用成本较高。
代码示例:
use diesel::prelude::*;
#[derive(queryable)]
struct user {
id: i32,
name: string,
}
let results = users
.limit(10)
.load::<user>(&mut conn)?;
seaorm
github地址:seaql/sea-orm: 🐚 a powerful relational orm for rust

seaorm 是新一代异步 orm,在“类型安全”和“开发效率”之间做了平衡。
适合场景:
crud 密集型业务
快速开发
代码示例:
let users = user::find()
.limit(10)
.all(&db)
.await?;
缓存
redis
redis 是 rust 中最常用的分布式缓存方案,官方社区最成熟的客户端是
redis(也叫 redis-rs)
use redis::asynccommands;
let client = redis::client::open("redis://127.0.0.1/")?;
let mut conn = client.get_async_connection().await?;
conn.set("key", "value").await?;
let val: string = conn.get("key").await?;
本地缓存(moka)
moka 是 rust 非常流行的高性能本地缓存库,支持并发、ttl、lru。
use moka::sync::cache;
let cache = cache::new(10_000);
cache.insert("key", "value");
let v = cache.get(&"key");
消息队列
kafka
rdkafka 是 rust 中最主流的 kafka 客户端,基于 c 库
librdkafka,性能和稳定性非常强。
use rdkafka::producer::{futureproducer, futurerecord};
let producer: futureproducer = config.create()?;
producer.send(
futurerecord::to("topic")
.payload("hello kafka")
.key("key"),
duration::from_secs(0),
).await?;
nats
nats 是轻量级、高性能消息系统,在 rust 微服务中非常常见。
let client = async_nats::connect("localhost").await?;
client.publish("subject", "hello").await?;
api网关
tower
tower 是 rust 服务生态的中间件标准,提供限流、超时、重试、熔断等能力,是很多网关方案的基础。
use tower::{servicebuilder};
use tower_http::trace::tracelayer;
let service = servicebuilder::new()
.layer(tracelayer::new_for_http())
.service(my_service);
hyper
hyper 是 rust 最底层、最高性能的 http 库,axum、tower 等都构建在它之上。
use hyper::{body, request, response};
async fn handler(_: request<body>) -> response<body> {
response::new(body::from("hello gateway"))
}
日志
rust 的日志体系是 分层设计,灵活但需要理解一次。
tracing
tracing 是 rust 新一代结构化日志与链路追踪框架,特别适合微服务。
use tracing::info; info!(user_id = 42, "request received");
tracing + tower_http
在 web / 网关项目中,常见组合是
自动记录请求日志
支持链路追踪
易于接入 opentelemetry
use tower_http::trace::tracelayer;
let app = router::new()
.layer(tracelayer::new_for_http());
一些学习rust语言的网站:
总结
rust 并不是一门“轻松上手”的语言,它对学习者的要求明显高于许多现代编程语言。初学 rust 时,你需要花大量精力去理解所有权、借用、生命周期以及类型系统,这些概念并非语法技巧,而是 rust 对程序正确性和安全性的根本约束。很多在其他语言中可以“先跑起来再说”的写法,在 rust 中必须一开始就想清楚,这会让人感到挫败,也常常产生“写代码像在和编译器较劲”的感觉。
但正是这种看似严苛的学习过程,构成了 rust 最核心的价值。rust 把大量原本在运行时、线上环境中才会暴露的问题,提前到了编译期解决。学习 rust,实际上是在被迫建立一种更严谨的工程思维:清楚数据的生命周期、明确所有权边界、对并发和资源管理保持敬畏。这些能力一旦形成,不仅会让你写出更可靠的 rust 代码,也会反过来提升你在其他语言中的代码质量。
因此,学习 rust 更像是一种“长期投资”。前期进度可能缓慢,甚至会怀疑投入是否值得,但随着理解逐渐加深,你会发现代码变得更可控、系统更稳定、问题更早暴露。rust 不承诺让你写得更快,但它承诺让你在复杂系统中犯更少的错。对于愿意投入时间、耐心和思考深度的开发者来说,这份努力最终会转化为扎实而持久的工程能力。
以上就是所有rust教学的内容,希望这篇文章能帮到每一个正在学习rust的朋友。如果这篇文章对你们有帮助,可以点赞,收藏加关注一下。你们的支持是我更新的最大动力
到此这篇关于新手轻松入门rus学习t语言(基础、高级语法和生态框架)的文章就介绍到这了,更多相关rust语言学习内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论