简介
在编写处理字符串的程序或网页时,经常会有查找符合某些复杂规则的字符串的需要。正则表达式就是用于描述这些规则的工具。换句话说,正则表达式就是记录文本规则的代码。
很可能你使用过windows/dos下用于文件查找的通配符(wildcard),也就是*和?。如果你想查找某个目录下的所有的word文档的话,你会搜索*.doc。在这里,*会被解释成任意的字符串。和通配符类似,正则表达式也是用来进行文本匹配的工具,只不过比起通配符,它能更精确地描述你的需求——当然,代价就是更复杂。
假设你在一篇英文小说里查找 hi,你可以使用正则表达式 hi。
这几乎是最简单的正则表达式了,它可以精确匹配这样的字符串:由两个字符组成,前一个字符是 h,后一个是 i。通常,处理正则表达式的工具会提供一个忽略大小写的选项,如果选中了这个选项,它可以匹配 hi,hi,hi,hi 这四种情况中的任意一种。
不幸的是,很多单词里包含hi这两个连续的字符,比如 him,history,high 等等。用 hi来查找的话,这里边的 hi 也会被找出来。如果要精确地查找 hi 这个单词的话,我们应该使用\bhi\b。
\b 是正则表达式规定的一个特殊代码(将其称之为 元字符),代表着单词的开头或结尾,也就是单词的分界处。虽然通常英文的单词是由空格,标点符号或者换行来分隔的,但是\b并不匹配这些单词分隔字符中的任何一个,它只匹配一个位置。
假如你要找的是hi后面不远处跟着一个lucy,你应该用\bhi\b.*\blucy\b。
这里,.是另一个元字符,匹配除了换行符以外的任意字符。* 同样是元字符,不过它代表的不是字符,也不是位置,而是数量——它指定* 前边的内容可以连续重复使用任意次以使整个表达式得到匹配。
因此,.*连在一起就意味着任意数量的不包含换行的字符。现在 \bhi\b.*\blucy\b 的意思就很明显了:先是一个单词 hi,然后是任意个任意字符(但不能是换行),最后是 lucy 这个单词。
如果同时使用其它元字符,我们就能构造出功能更强大的正则表达式。比如下面这个例子:
0\d\d-\d\d\d\d\d\d\d\d匹配这样的字符串:以 0 开头,然后是两个数字,然后是一个连字号“-”,最后是8个数字(也就是中国的电话号码。当然,这个例子只能匹配区号为3位的情形)。
这里的\d是个新的元字符,匹配一位数字(0,或1,或2,或……)。- 不是元字符,只匹配它本身——连字符(或者减号,或者中横线,或者随你怎么称呼它)。
为了避免那么多烦人的重复,我们也可以这样写这个表达式:0\d{2}-\d{8}。这里\d后面的{2}({8})的意思是前面\d必须连续重复匹配 2 次(8次)。
总的来说,正则表达式一种特殊的编程语言,专门用来匹配一些特定的字符串。正则表达式一般不会单独使用,通常会结合具体的编程语言(例如 c++、python、perl等)或者工具(vim等)使用。
在线工具
正则表达式本身比较复杂,可以借助一些工具来验证所写的正则表达式是否符合预期。
元字符
基本元字符
| metacharacter | descriptions | examples |
|---|---|---|
| \ | 转义字符,使后面的字符失去特殊含义或者标记为特殊字符 | \. 匹配实际的点号而不是任意字符,\n 匹配一个换行符 |
| ^ | 匹配字符串的开始位置 | ^abc 匹配以 abc 开头的字符串 |
| $ | 匹配字符串的结束位置 | xyz$ 匹配以 “xyz” 结尾的字符串 |
| . | 匹配除换行符(\n)外的任意单个字符 | a.b 匹配 “aab”, “a1b”, “a b” 等 |
| * | 匹配前面的子表达式零次或多次 | zo* 能匹配 “z” 以及 “zoo” |
| + | 匹配前面的子表达式 1 次或多次 | zo+ 能匹配 “zo” 以及 “zoo”,但不能匹配 “z” |
| ? | 匹配前面的子表达式零次或一次 | do(es)? 可以匹配 “do” 或 “does” |
| {n} | n 是一个非负整数。匹配确定的 n 次 | o{2} 不能匹配 “bob” 中的 ‘o’,但是能匹配 “food” 中的两个 o |
| {n,} | n 是一个非负整数。至少匹配n 次 | o{2,} 不能匹配 “bob” 中的 ‘o’,但能匹配 “foooood” 中的所有 o |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次 | o{1,3} 匹配 “fooooood” 中的前三个 o |
| x|y | 匹配 x 或 y | z|food 能匹配 “z” 或 “food” |
| [xyz] | 字符集合。匹配所包含的任意一个字符 | [abc] 可以匹配 “plain” 中的 ‘a’。 |
| [^xyz] | 负值字符集合。匹配未包含的任意字符 | [^abc] 可以匹配 “plain” 中的’p’、‘l’、‘i’、‘n’ |
| [a-z] | 字符范围。匹配指定范围内的任意字符 | [a-z] 可以匹配 ‘a’ 到 ‘z’ 范围内的任意小写字母字符 |
| [^a-z] | 负值字符范围。匹配任何不在指定范围内的任意字符 | [^a-z] 可以匹配任何不在 ‘a’ 到 ‘z’ 范围内的任意字符 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置 | er\b 可以匹配"never" 中的 ‘er’,但不能匹配 “verb” 中的 ‘er’ |
| \b | 匹配非单词边界 | er\b 能匹配 “verb” 中的 ‘er’,但不能匹配 “never” 中的 ‘er’ |
| \cx | 匹配由 x 指明的控制字符,x 的值必须为 a-z 或 a-z 之一。否则,将 c 视为一个原义的 ‘c’ 字符 | \cm 匹配一个 control-m 或回车符 |
| \d | 匹配一个数字字符 | 等价于 [0-9] |
| \d | 匹配一个非数字字符 | 等价于 [^0-9] |
| \f | 匹配一个换页符 | 等价于 \x0c 和 \cl |
| \n | 匹配一个换行符 | 等价于 \x0a 和 \cj |
| \r | 匹配一个回车符 | 等价于 \x0d 和 \cm |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等 | 等价于 [ \f\n\r\t\v] |
| \s | 匹配任何非空白字符 | 等价于 [^ \f\n\r\t\v] |
| \t | 匹配一个制表符 | 等价于 \x09 和 \ci |
| \v | 匹配一个垂直制表符 | 等价于 \x0b 和 \ck |
| \w | 匹配字母、数字、下划线 | 等价于 [a-za-z0-9_] |
| \w | 匹配非字母、数字、下划线 | 等价于 [^a-za-z0-9_] |
分组与引用
直接在字符后面加上限定符,就可以实现重复单个字符。如果想要重复多个字符,比如重复 ab,可以使用小括号来指定子表达式(也叫做分组),然后指定这个子表达式的重复次数。
例如,(ab)+ 可以匹配 “ab”、“abab”、“ababab” 等,但不能匹配 “a” 或 “b”。
- 捕获分组
正则表达式中有几种不同类型的分组,捕获分组是最常见的分组形式,它会捕获匹配的内容并分配一个编号(从 1 开始)。后续可以基于编号访问分组中的内容。
示例:
(\d{4})-(\d{2})-(\d{2}) # 匹配日期格式 yyyy-mm-dd
这个表达式会创建3个分组:① 4位数字的年份;② 2位数字的月份;③ 2位数字的日期
- 分组引用
分组最强大的功能之一是可以在正则表达式内部或外部引用已匹配的内容。
在正则表达式内部引用前面的分组,使用 \num,其中 num 是分组索引。
(\w+) \1 # 匹配重复的单词,如 "hello hello"
这个 pattern 会匹配两个相同的单词,中间用空格分隔,其中 \1 就是对分组的引用。
- 非捕获分组
使用 (?:pattern) 语法,表示只分组但不捕获。
例如,(?:mr|ms|mrs)\. (\w+) 表示匹配 “mr. smith” 但只捕获 “smith”。
- 命名分组与引用
在一些高级语言中,还可以为分组指定名称,提高可读性(不同语言语法可能不同)。
例如,在 python 中对分组进行命令的方法如下:
### named capturing group
(?p<year>\d{4})-(?p<month>\d{2})-(?p<day>\d{2})
### reference
(?p<word>\w+) (?p=word)
运算符优先级
正则表达式从左到右进行计算,并遵循优先级顺序,这与算术表达式非常类似。
相同优先级的从左到右进行运算,不同优先级的运算先高后低。
正则表达式中,各种运算符的优先级顺序如下:
| 优先级 | 运算符 | 描述 |
|---|---|---|
| 1 | \ | 转义符 |
| 2 | ()、[] | 圆括号和方括号 |
| 3 | *、 +、 ?、 {n}、{n,}、{n,m} | 限定符 |
| 4 | ^、$、\任何元字符、任何字符 | 定位点和序列(即:位置和顺序) |
| 5 | | | "或"操作 |
贪婪模式
当正则表达式中包含能接受重复的限定符时,通常的行为是(在使整个表达式能得到匹配的前提下)匹配尽可能多的字符。以表达式a.*b 为例,它将会匹配最长的以a开始,以b结束的字符串。如果用它来搜索aabab的话,它会匹配整个字符串aabab。这被称为贪婪匹配。
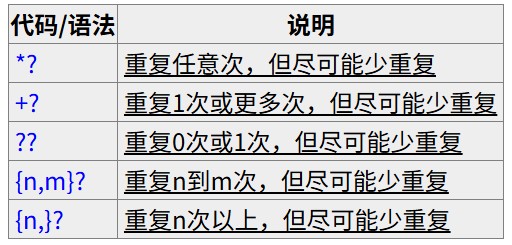
有时,我们更需要懒惰匹配,也就是匹配尽可能少的字符。前面给出的限定符都可以被转化为懒惰匹配模式,只要在它后面加上一个?。
这样.*?就意味着匹配任意数量的重复,但是在能使整个匹配成功的前提下使用最少的重复
a.*?b 匹配最短的,以a开始,以b结束的字符串。如果把它应用于 aabab 的话,它会匹配 aab(第一到第三个字符)和ab(第四到第五个字符)。
为什么第一个匹配是aab(第一到第三个字符)而不是ab(第二到第三个字符)?简单地说,因为正则表达式有另一条规则,比懒惰/贪婪规则的优先级更高:最先开始的匹配拥有最高的优先权。
对于其他的的重复限定符,都支持使用 ? 进入懒惰模式:
总结
到此这篇关于regexp正则表达式基础语法的文章就介绍到这了,更多相关regexp正则表达式语法内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论