一、什么是存储过程?
1、存储过程的定义
存储过程(stored procedure)是一组预编译并存储在 mysql 服务器中的 sql 语句集合,可通过名称调用执行,支持参数传递、流程控制(条件、循环)、异常处理等特性,是数据库层面封装业务逻辑的核心工具。
2、存储过程的特性
特性 | 说明 |
预编译 | 创建时编译,调用时无需重复解析 / 优化,执行效率更高 |
封装性 | 将复杂 sql 逻辑封装为单个单元,降低应用层代码复杂度 |
可复用性 | 一次创建,多处调用,减少重复开发 |
安全性 | 可通过权限控制仅允许调用存储过程,不直接操作底层表 |
支持参数 | 输入(in)、输出(out)、输入输出(inout)参数 |
流程控制 | 支持 if、case、loop、while、repeat 等编程逻辑 |
事务支持 | 可在存储过程中管理事务(commit/rollback) |
3、如何构建存储过程?
-- 创建存储过程 delimiter $$ create procedure 存储过程名([参数列表]) begin -- 存储过程体(sql语句/流程控制逻辑) end $$ delimiter; -- 调用存储过程 call 存储过程名([参数列表]);
4、案例:使用存储过程,向表中批量插入2000条数据
(1)创建表t_users,该表中包含主键id值、用户名称、用户性别、用户账号、用户密码、用户生日、用户地址、用户联系方式。
-- 创建表t_users create table if not exists t_users( uid int auto_increment primary key comment '主键id值', uname varchar(30) not null comment '用户名称', ugender varchar(10) not null comment '用户性别', uaccount varchar(9) not null comment '用户账号', upassword varchar(9) not null comment '用户密码', ubirthday varchar(50) not null comment '用户生日', uaddress varchar(100) not null comment '用户地址', uphone char(11) not null comment '用户联系方式' );
(2)创建存储过程p_users,向表中批量插入2000条数据:
模拟生成姓名:先在姓氏列表中随机生成一个姓氏,再根据性别在各自的名字库中获取随机的名字,再将二者组合生成完整的名字;
模拟生成账号:可以采用随机数来做,范围是[100000000,99999999);
模拟生成账号:可以采用随机数来做,密码的范围是数字6位或9位;
模拟生成地址:这里采用的是江苏省和其包含的市进行随机的组合;
模拟生成生日:格式为‘××××-××-××’;
模拟生成手机号码:手机号码的范围为(10000000000,19999999999)。
-- 使用数据库的存储过程,向表中批量存储2000条数据
delimiter $$
create procedure p_users ()
begin
declare
i int default 1; -- 计数器
declare
user_name varchar (30); -- 用户姓名
declare
user_gender varchar (10); -- 用户性别
declare
user_account varchar (9); -- 用户账号
declare
user_password varchar (9); -- 用户密码
declare
user_birthday varchar (50); -- 用户生日
declare
user_address varchar (100); -- 用户地址
declare
user_phone char(11); -- 用户电话号码
-- 随机生成数据
-- 创建姓氏列表变量
set @last_names = '赵,钱,孙,李,周,吴,郑,王,冯,陈,褚,卫,蒋,沈,韩,杨,朱,秦,尤,许,何,吕,施,张,孔,曹,严,华,金,魏,田';
-- 男性名字库
set @male_names = '明轩,沐泽,宏杰,诚,栋盛,健,德清,明,柯鸿,学智,俊,国瑞,东旭,彦晟,哲源,旭磊,兵,海毅,轩俊,文锦,潇阳,明煦,恒文,昌瑞';
-- 女性名字库
set @female_names = '欣瑾,沐璇,涵淇,韶涵,悦琪,凌蕊,凝萱,子琪,惜筠,怡木,巧云,春燕,初柔,雨,翠花,妍茜,捷,语蓉,艺歆,岚菱,冰蕊,蝶静,雅依,思怡';
-- 江苏省包含的市名字库
set @country_names = '南京市,无锡市,徐州市,常州市,苏州市,南通市,连云港市,淮安市,盐城市,扬州市,镇江市,泰州市,宿迁市';
-- 循环插入数据
repeat
-- 随机生成用户性别
set user_gender =
if(rand() > 0.5, '男', '女');
-- 随机生成用户姓名
-- 随机取出用户的性
set @last_name = substring_index(substring_index(@last_names, ',', floor(rand() * 21 + 1)), ',', - 1);
-- 根据性别取名
if user_gender = '男' then
set @first_name = substring_index(substring_index(@male_names, ',', floor(rand() * 24 + 1)), ',', - 1);
else
set @first_name = substring_index(substring_index(@female_names, ',', floor(rand() * 24 + 1)), ',', - 1);
end if;
-- 组合名字
set user_name = concat(@last_name, @first_name);
-- 随机生成账号:账号的长度为9位,范围100000000 -- 999999999
set user_account = floor(rand() * 900000000 + 100000000);
-- 随机生成密码: 密码最少6位,最多九位
set user_password = floor(rand() * 999900000 + 100000);
-- 随机生成生日
set @month_random = floor(rand() * 12 + 1);
set @month_value =
if(@month_random < 10, concat('0', @month_random), @month_random);
set @date_random = floor(rand() * 30 + 1);
set @date_value =
if(@date_random < 10, concat('0', @date_random), @date_random);
set user_birthday = concat(floor(rand() * 46 + 1980), '-', @month_value, '-', @date_value);
-- 随机生成地址
-- 随机市名
set @country_name = substring_index(substring_index(@country_names, ',', floor(rand() * 13 + 1)), ',', - 1);
-- 组合地址信息
set user_address = concat('江苏省', @country_name);
-- 随机生成手机号码 10000000000-19999999999
set user_phone = floor(rand() * 1000000000 + 10000000000);
insert into t_users (uname, ugender, uaccount, upassword, ubirthday, uaddress, uphone)
values
(user_name, user_gender, user_account, user_password, user_birthday, user_address, user_phone);
-- 计数器+1
set i = i + 1;
until i > 2000 end repeat;
commit;
end $$
delimiter;(3)预编译存储过程,调用存储过程
-- 调用存储过程 call p_users();
(4)成功生成2000条模拟数据
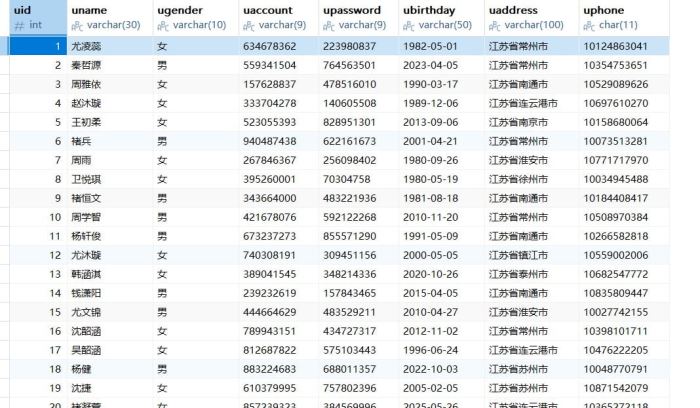
二、java如何调用存储过程?
在上面调用存储过程的案例中,我们已经成功生成2000条模拟数据,那么下面以该表为例,通过调用存储过程来实现查询用户名称的操作。
1、创建存储过程p_demo3,通过传入参数账号和密码信息,获取该用户的名称
-- 创建存储过程:查询该账户的用户名称 delimiter $$ create procedure p_demo3(in v_account varchar(9),in v_password varchar(9),out v_name varchar(30)) begin -- into关键字是给一个变量赋值,如果产生多个值(2个及以上,需要用游标) select uname into v_name from t_users where uaccount = v_account and upassword = v_password; end $$ delimiter;
2、调用存储过程,以表中生成的第一条数据为例,输入该用户的账号和密码。
-- 调用存储过程
call p_demo3('634678362','223980837', @uname);
select @uname; -- 查询返回的结果结果截图:
3、通过上面两步已经通过存储过程实现了对用户姓名的查询,下面在java中连接数据库,调用存储过程。
(1)在pom.xml文件中添加依赖:
<dependencies>
<!-- mysql jdbc driver -->
<dependency>
<groupid>mysql</groupid>
<artifactid>mysql-connector-java</artifactid>
<version>8.0.28</version> <!-- 请使用最新版本 -->
</dependency>
</dependencies>(2)连接数据库代码:
import java.sql.*;
import java.util.scanner;
public class dao {
//创建数据库连接对象
private connection conn;
public dao(){
//加载数据库驱动
try {
class.forname("com.mysql.cj.jdbc.driver");
conn = drivermanager.getconnection("jdbc:mysql://127.0.0.1:3306/computer_class","root","123456");
system.out.println("数据库computer_class连接成功!!!");
} catch (classnotfoundexception e) {
throw new runtimeexception(e);
} catch (sqlexception e) {
throw new runtimeexception(e);
}
}
public void call(string account,string password){
//准备调用语句
string sql = "{call p_demo3(?,?,?)}";
//预执行语句
try {
callablestatement cstmt = this.conn.preparecall(sql);
//注册参数
cstmt.setstring(1,account);
cstmt.setstring(2,password);
//返回值类型
cstmt.registeroutparameter(3, types.varchar);
//执行存储过程
cstmt.execute();
//获取返回结果
string str = cstmt.getstring(3);
system.out.println("执行的结果为:"+str);
} catch (sqlexception e) {
throw new runtimeexception(e);
}
}
public static void main(string[] args) {
//创建scanner对象
scanner sc = new scanner(system.in);
//通过用户输入来获取用户的账号和密码信息
system.out.println("请输入账号:");
string account = sc.nextline();
system.out.println("请输入密码:");
string password = sc.nextline();
dao db = new dao();
db.call(account,password);
}
}(3)在控制台中输入账号和密码信息,以第一条数据为例

*****(4-1)在上面的案例中,调用的存储过程的返回值只有一行。如果出现多行数据的情况,应该使用游标来获取返回的结果。下面介绍一个使用到游标的案例:查询所有地址为江苏省南京市的用户名称、用户性别、地址信息,示例代码:
-- 创建存储过程:查询所有地址为江苏省南京市的用户名称、用户性别、地址信息
-- 返回的结果是有多行数据,是一个结果集,所以需要使用到游标
delimiter $$
create procedure p_demo4(in v_address varchar(100),out v_data varchar(15000))
begin
-- 声明变量
declare user_name varchar(30);
declare user_gender varchar(10);
declare user_address varchar(100);
declare v_str text default "";
-- 声明游标遍历结束的标志变量(必须是 bool/int 类型,默认 null)
declare done int default 0;
-- 游标的定义就是sql的定义
declare v_result cursor for select uname,ugender,uaddress from t_users where uaddress = v_address;
-- 声明游标结束处理器
declare continue handler for not found set done = 1;
-- 打开游标(执行关联的查询,加载结果集到内存)
open v_result;
read_loop: loop
-- 从游标中读取一行数据,赋值给变量
fetch v_result into user_name,user_gender,user_address;
if done = 1 then
leave read_loop;
end if;
-- 业务逻辑:处理当前行的数据(示例:打印/计算/插入等)
set v_str = concat(v_str ,user_name, '-', user_gender,'-',user_address,'|');
end loop;
-- 6. 关闭游标(释放结果集内存)
close v_result;
-- 完成对返回值的赋值
set v_data = v_str;
end $$
delimiter;(4-2)调用存储过程
-- 调用存储过程
call p_demo4('江苏省南京市',@info)
select @info(4-3)运行结果截图

三、什么是自定义函数?
1、自定义函数的定义:
自定义函数(user-defined function,udf)是 mysql 中用户自行定义的、可复用的 sql 函数,与内置函数(如concat()、sum())类似,接收输入参数、执行逻辑并返回单个值(标量),是数据库层封装简单 / 复用性高的计算逻辑的核心工具。
2、自定义函数的特性:
特性 | 说明 |
返回值 | 必须返回单个值(标量),无返回值则报错 |
调用方式 | 可嵌入 sql 语句中(如 select、where) |
使用场景 | 简单计算、数据转换、条件判断(单值输出) |
语法限制 | 不能包含事务操作(commit/rollback) |
3、如何构建自定义函数?
create function 函数名(参数列表) deterministic begin -- 执行的函数体 return 返回值; end;
4、案例:使用自定义函数,通过输入的账号和密码,来实现登录功能,数据来源于上面案例创建的表。
(1)构建自定义函数f_login
create function f_login(v_account varchar(9), v_passsword varchar(9)) returns varchar(50) deterministic begin -- 声明计数器 declare v_count int; -- 声明返回信息、 declare v_message varchar(50); -- 根据输入的账号和密码查表 select count(*) into v_count from t_users where uaccount = v_account and upassword = v_passsword; set v_message = if(v_count > 0,'登录成功','登录失败,账号或密码错误'); return v_message; end;
(2)通过预编译后,调用自定义函数f_login,以第一条数据为例。
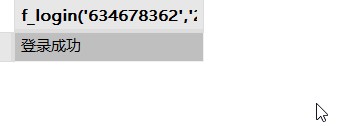
-- 调用自定义函数
select f_login('634678362','223980837') from dual;(3)返回结果截图
四、java如何调用自定义函数?
(1)示例代码:
import java.sql.*;
public class udfcall {
//创建数据库连接对象
private connection conn;
public udfcall(){
//加载数据库驱动
try {
class.forname("com.mysql.cj.jdbc.driver");
conn = drivermanager.getconnection("jdbc:mysql://127.0.0.1:3306/computer_class","root","123456");
system.out.println("数据库computer_class连接成功!!!");
} catch (classnotfoundexception e) {
throw new runtimeexception(e);
} catch (sqlexception e) {
throw new runtimeexception(e);
}
}
public void callfunc (string account,string password){
//准备调用语句
string sql = "{ ? = call f_login(?,?)}";
//预执行语句
try {
callablestatement cstmt = this.conn.preparecall(sql);
//返回值类型
cstmt.registeroutparameter(1, types.varchar);
//注册参数
cstmt.setstring(2,account);
cstmt.setstring(3,password);
//执行存储过程
cstmt.execute();
//获取返回结果
string str = cstmt.getstring(1);
system.out.println("登录的结果为:"+str);
} catch (sqlexception e) {
throw new runtimeexception(e);
}
}
public static void main(string[] args) {
//创建实例对象
udfcall udf = new udfcall();
udf.callfunc("634678362", "223980837");
}
}(2)运行结果截图:

五、mysql数据库的存储过程和自定义函数的区别?
对比维度 | 存储过程(stored procedure) | 自定义函数(udf) |
核心定位 | 封装多步业务逻辑(如事务、多表操作) | 封装单值计算逻辑(如数据转换、简单运算) |
返回值规则 | 支持无返回值、单个返回值、多个返回值 | 仅能返回一个值(标量,如 int/varchar) |
调用方式 | 独立调用: | 嵌入调用:可直接嵌入 select/where/order by 等 sql 语句,也可单独调用 |
参数类型 | 支持 in/out/inout 三种参数(显式声明) | 仅支持 in 参数(默认,不可声明 out/inout) |
事务支持 | 完全支持:可包含 commit/rollback 管理事务 | 完全不支持:禁止包含事务操作(执行会报错) |
使用场景 | 复杂业务逻辑(订单创建、数据同步、批量更新) | 简单计算逻辑(时间转换、积分计算、字符串处理) |
sql 嵌入性 | 不可嵌入 select/update 等语句,仅能独立 call | 可嵌入任意 sql 语句(如 |
语法限制 | 可包含 ddl(create/drop)、dml、dql | 避免包含 ddl,仅建议 dql(读取数据)或纯内存计算 |
异常处理 | 支持 declare handler 捕获异常,可回滚事务 | 支持捕获异常,但仅能返回默认值 / 抛自定义异常 |
到此这篇关于java调用mysql数据库的存储过程和自定义函数及区别解析的文章就介绍到这了,更多相关java调用mysql存储过程和自定义函数内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论