mysql主从同步和分库分表是应对高并发、大数据量场景的两大核心技术,通过数据复制和水平/垂直拆分,有效解决了单点性能瓶颈和存储容量限制。主从同步实现了数据库的高可用性和读写分离,而分库分表则进一步提升了系统的扩展性和负载能力。本文将深入解析这两项技术的原理、实现方法及最佳实践,帮助您在实际项目中构建高性能的mysql架构。
一、主从同步原理与架构
1.1 核心组件与工作流程
mysql主从同步通过二进制日志(binlog)实现数据的异步/半同步复制。主库负责处理写操作并将变更记录到binlog中,从库通过io线程获取binlog并写入本地的relay log,然后由sql线程执行这些日志中的事件,最终实现与主库的数据一致。

工作流程详解:
- 主库操作:当客户端在主库执行写操作时,innodb引擎首先将数据变更记录到redo log以确保事务持久性,随后将变更写入binlog。
- io线程传输:从库的io线程通过长连接监听主库的binlog变更,获取新事件后写入本地中继日志(relay log)。
- sql线程执行:从库的sql线程读取中继日志中的事件并重放,将变更应用到本地数据库,最终实现与主库的数据一致。
1.2 同步模式对比
mysql主从同步支持三种模式,各有优缺点:
| 模式 | 特点 | 适用场景 | rto/rpo |
|---|---|---|---|
| 异步复制 | 主库处理完sql直接返回结果 | 高写入性能要求,对数据一致性要求较低 | 最高 |
| 半同步复制 | 主库处理完sql等待至少1个从完成 | 平衡性能与一致性,多数生产环境使用 | 中等 |
| 全同步复制 | 主库处理完sql等待所有从完成 | 数据一致性要求极高,但性能最差 | 最低 |
半同步复制实现机制:mysql半同步复制依赖rpl_semi_sync_master插件,通过after_sync或after_commit两种模式实现 。after同步模式要求主库等待从库将binlog写入中继日志,而after提交模式则要求从库执行到sql线程阶段。
半同步复制能显著降低数据丢失风险,但会增加约20%的写入延迟。配置时需设置rpl_semi_sync_master_timeout(超时时间,默认10000ms)和rpl_semi_sync_master enabled(启用状态) 。
1.3 主从同步配置步骤
1. 主库配置
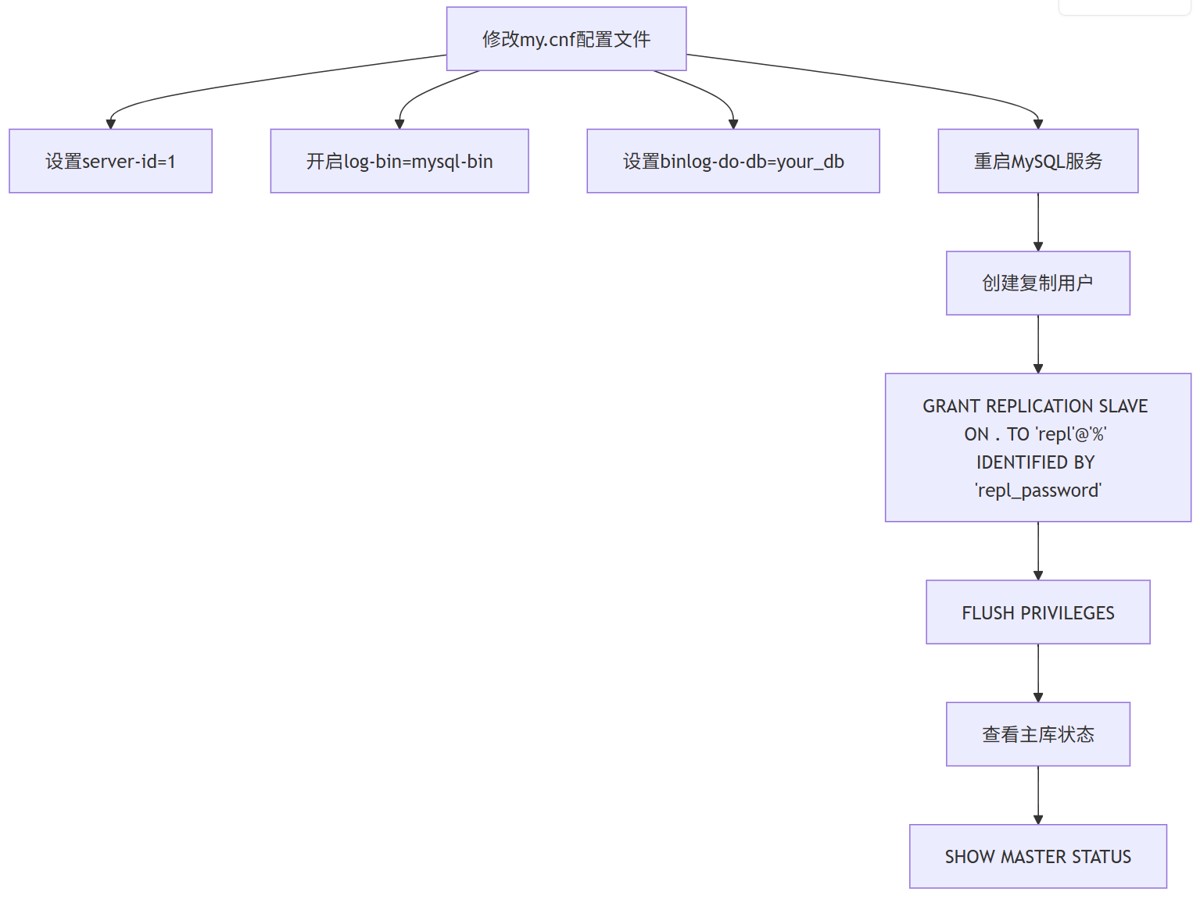
配置参数详解:
server-id:唯一标识符,主从库必须不同,范围1~2^32-1。log-bin:开启二进制日志功能,指定日志文件前缀。binlog-do-db:指定需要同步的数据库,可设置多个。binlog_format:推荐设为row格式,确保精确复制,避免statement格式的不可重现问题。sync_binlog:控制binlog刷盘策略,设为1最安全但性能损耗大,设为1000平衡性能与安全。enforce_gtid_consistency:若使用gtid模式,必须设为on以保证事务一致性
2. 从库配置
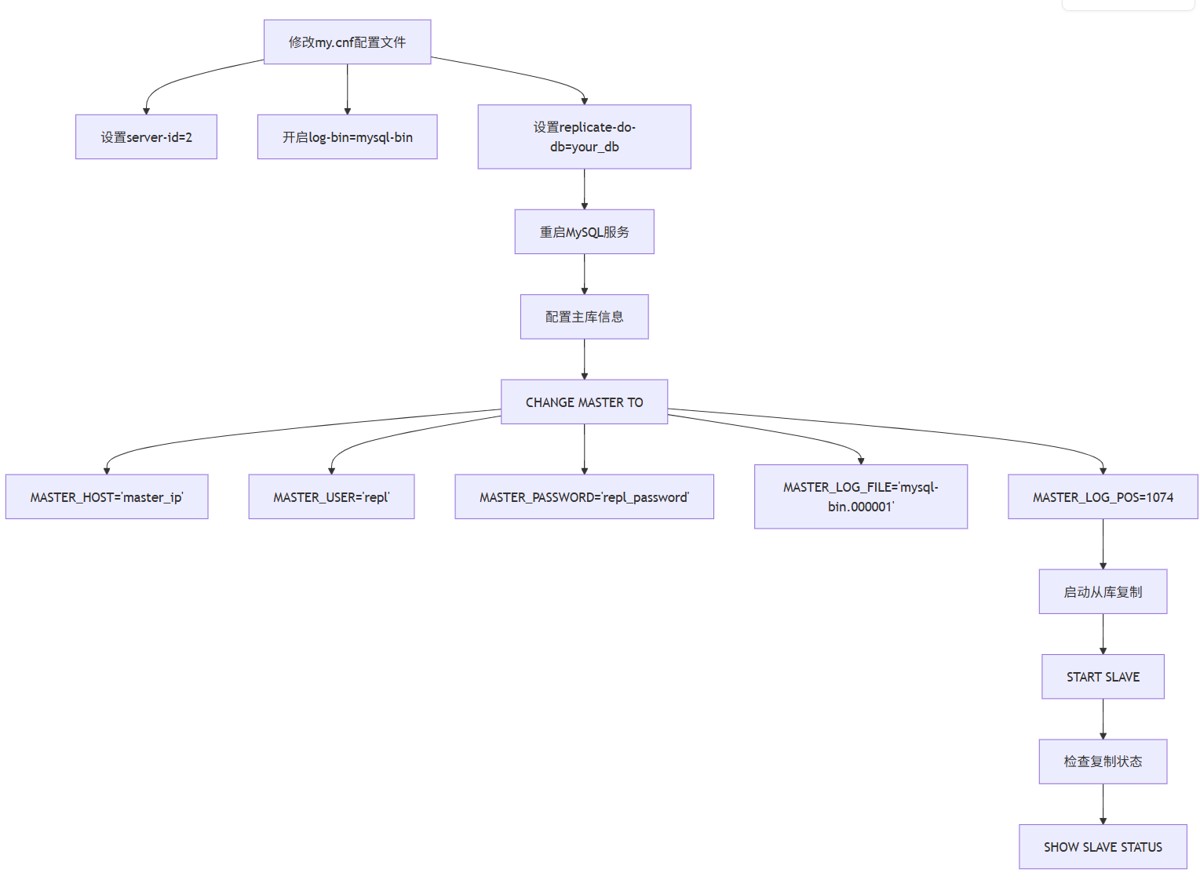
配置参数详解:
server-id:从库唯一标识符,与主库不同。replicate-do-db:指定需要复制的数据库,可设置多个。master_auto_position:若使用gtid模式,设为1可自动同步gtid,无需手动指定file/pos。read-only:建议设为on防止从库被误写
3. 验证同步
-- 在主库插入测试数据 insert into test_table (id, name) values (1, 'test'); -- 在从库查询数据 select * from test_table where id=1;
若数据成功同步,则配置成功。
二、分库分表策略与实现
2.1 分库分表类型
分库分表主要分为垂直分库/分表和水平分库/分表,通常建议先进行垂直拆分,再考虑水平拆分 。
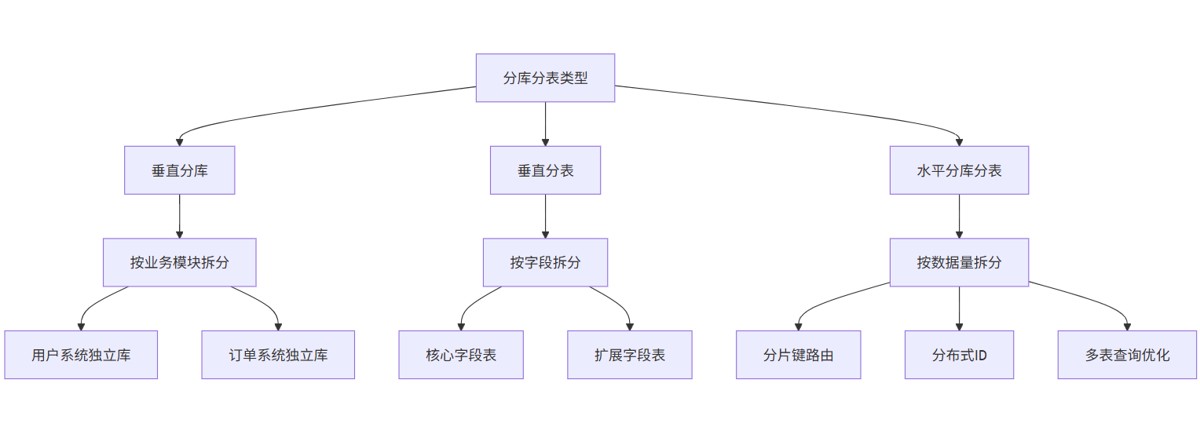
垂直分库适用场景:
- 业务模块解耦:如电商系统中用户、订单、商品模块独立部署,降低耦合度。
- 冷热数据分离:如历史日志与实时交易表分离,减少io争抢。
- 高并发场景:单库连接数达到瓶颈时,通过垂直分库提高系统并发能力。
- 数据量级建议:当单库表数超过500+或总数据量达tb级时考虑拆分 。
水平分表适用场景 :
- 单表数据量过大:行数超过1000万或单表大小超过10gb
- 高并发写入:qps超过3000或写入延迟持续超过100ms
- 查询模式优化:频繁查询特定范围数据(如按时间查询日志)时,可按范围分片提高效率 。
2.2 垂直分库实现
1. 创建独立业务库
-- 创建用户库和订单库 create database user_db; create database order_db; -- 将用户表迁移到用户库 rename table original_db.user to user_db.user; -- 将订单表迁移到订单库 rename table original_db.order to order_db.order;
2. 应用层路由配置
在应用层代码中设置不同业务的数据库连接:
// 用户操作使用user_db连接
datasource userdatasource = setupdatasource("user_db");
// 订单操作使用order_db连接
datasource orderdatasource = setupdatasource("order_db");3. 分片键选择原则
分片键的选择直接影响分库分表的效果,需遵循以下原则:
- 高基数字段:如用户id或订单id,确保数据均匀分布。
- 查询模式匹配:分片键应与业务查询条件一致,如订单查询常按
user_id,则选user_id为分片键 。 - 避免热点数据:如时间字段可能导致最新分片负载过高,需结合其他策略(如哈希)
- 稳定性:分片键值不应频繁变更,否则会导致数据迁移
2.3 垂直分表示例
1. 原始宽表结构
create table user (
id bigint primary key auto_increment,
name varchar(50),
email varchar(100),
phone varchar(20),
address text,
profile json,
created_at datetime default current_timestamp
);2. 分表后结构
-- 核心信息表
create table user core (
id bigint primary key auto_increment,
name varchar(50),
email varchar(100),
phone varchar(20),
created_at datetime default current_timestamp
);
-- 扩展信息表
create table user extend (
id bigint primary key auto_increment,
user_id bigint,
address text,
profile json,
foreign key (user_id) references user core(id)
);2.4 水平分表示例
1. 按用户id取模分
-- 创建4张分表
create table user_001 (
id bigint primary key auto_increment,
user_id bigint,
name varchar(50),
email varchar(100),
phone varchar(20),
created_at datetime default current_timestamp
) engine=innodb;
-- 类似创建user_002、user_003、user_004表
-- 设置主键步长避免冲突
alter table user_001 auto_increment=1;
alter table user_002 auto_increment=2;
alter table user_003 auto_increment=3;
alter table user_004 auto_increment=4;
-- 设置全局步长
set global auto_increment_increment=4;2. 数据操作示例
public class userdao {
private static final int shard_count = 4;
// 获取分片编号
private int getshardnumber(long userid) {
return (int) (userid % shard_count);
}
// 插入用户
public void insertuser(user user) {
int shardnumber = getshardnumber(user.getid());
string table = "user_" + string.format("%03d", shardnumber);
try (connection conn = getdatasource(shardnumber). connections()) {
conn预备语句(
"insert into " + table + " (user_id, name, email, phone) " +
"values (?, ?, ?, ?)"
). executeupdate();
}
}
// 查询用户
public user getuser(long userid) {
int shardnumber = getshardnumber(userid);
string table = "user_" + string.format("%03d", shardnumber);
try (connection conn = getdatasource(shardnumber). connections()) {
预备语句ps = conn预备语句(
"select * from " + table + " where user_id = ?"
);
ps.setlong(1, userid);
结果集rs = ps执行查询();
if (rs.next()) {
return maptouser(rs);
}
}
return null;
}
// 获取对应分片的数据库连接
private datasource getdatasource(int shardnumber) {
switch (shardnumber) {
case 0:
return userdatasource0;
case 1:
return userdatasource1;
case 2:
return userdatasource2;
case 3:
return userdatasource3;
default:
throw new illegalargumentexception("无效的分片编号");
}
}
}三、分库分表后的挑战与解决方案
3.1 分布式事务处理(若感兴趣,评论区告诉我,会单独出一期详细讲述)
1. xa事务实现
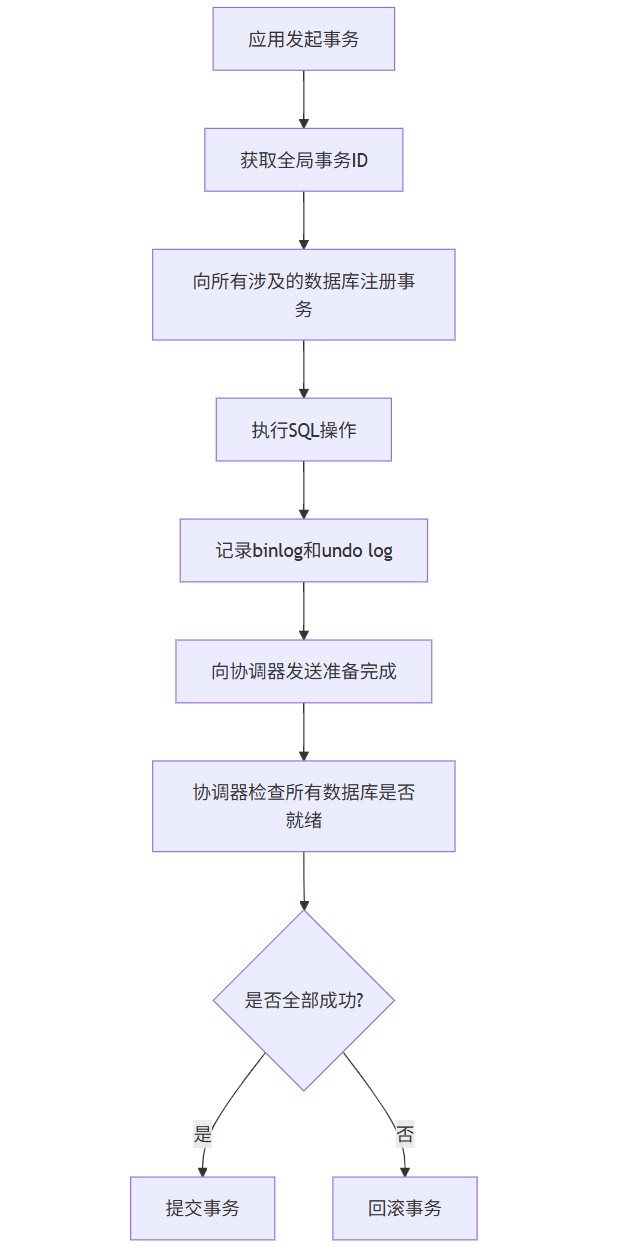
xa事务实现步骤 :
- 准备阶段:事务协调器向所有参与的数据库发送"准备"请求,每个数据库执行本地事务操作但不提交,记录事务日志并持有相关资源锁。
- 提交阶段:若所有数据库都反馈"同意提交",协调器向所有数据库发送"提交"指令,释放资源锁并提交事务。若有任何数据库失败,则发送"回滚"指令 。
xa事务优缺点:
- 优点:实现简单,依赖数据库原生支持,能保证强一致性。
- 缺点:性能较差(需等待所有数据库响应),可用性低(协调器单点故障风险),锁竞争导致阻塞
2. tcc事务模式
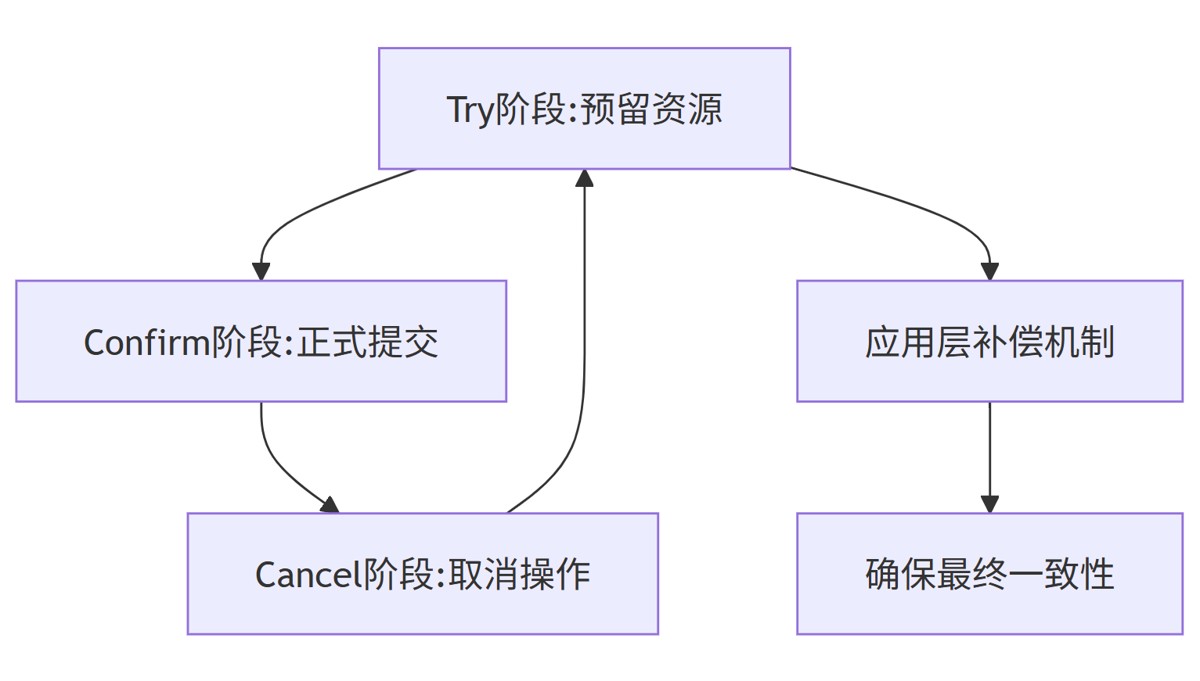
tcc事务实现步骤 :
- try阶段:检查资源是否满足要求(如检查账户余额是否足够),若符合条件则对资源进行锁定(如冻结可扣减金额)。
- confirm阶段:若try阶段所有操作都成功,则执行正式提交(如实际扣减金额)。
- cancel阶段:若try阶段有失败,则执行回滚(如释放冻结金额) 。
tcc事务优缺点:
- 优点:无锁、支持复杂业务流程,性能较好。
- 缺点:对业务有侵入性,需提供try/confirm/cancel三个接口,开发成本高
3.2 跨库join查询优化(若感兴趣,评论区告诉我,会单独出一期详细讲述shardingsphere)
1. 业务层聚合
分别查询用户表、订单表,再应用层对结果合并
2. 宽表同步

实现方法:
- 将关联表的数据同步到数据仓库(如hadoop或clickhouse)。
- 在数据仓库中生成宽表,包含所有需要关联的字段。
- 通过中间件(如shardingsphere)或直接查询宽表完成关联查询
3.3 主键冲突解决方案
1. 步长分配法(使用较少)
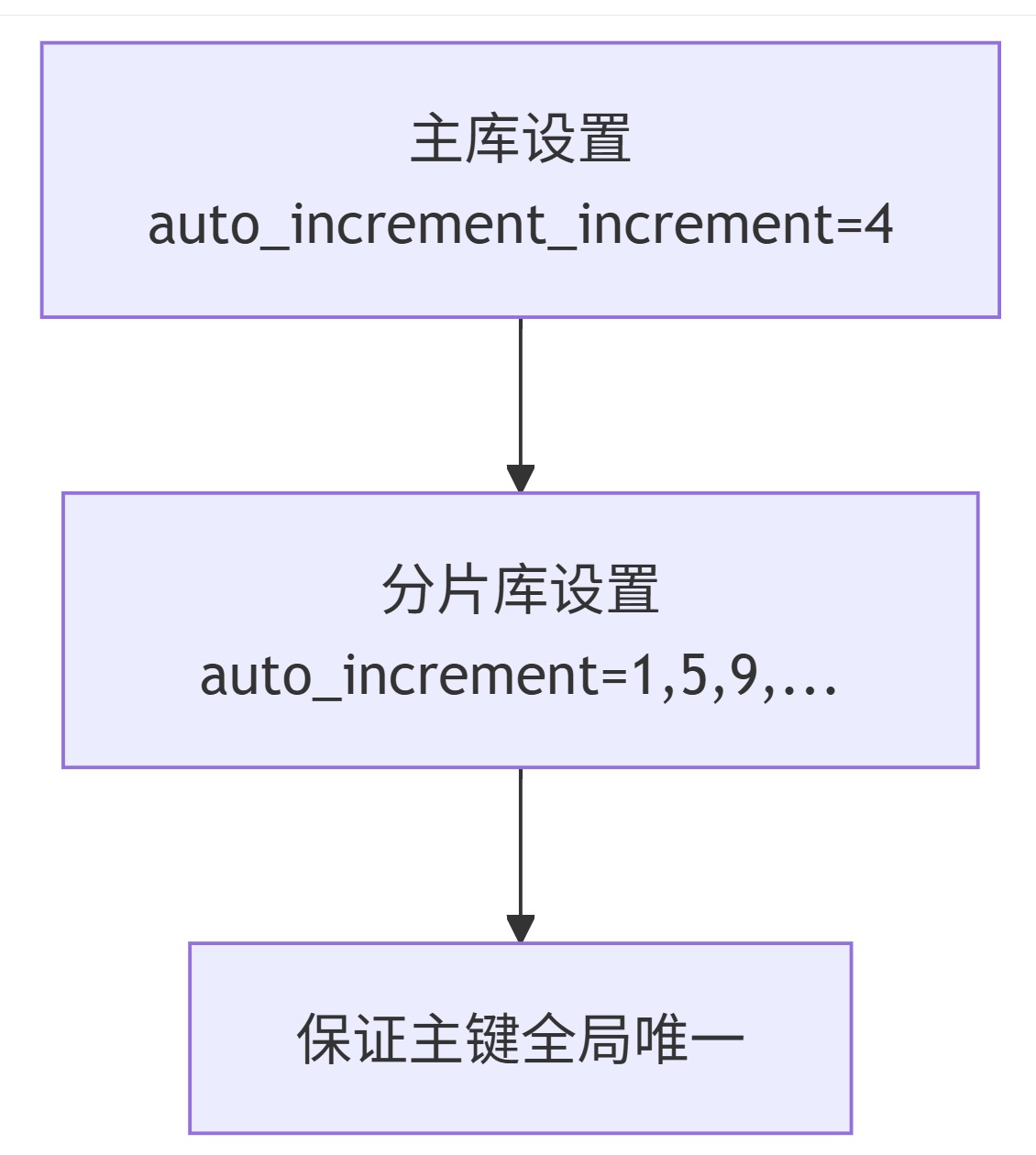
实现步骤:
在主库设置全局步长
set global auto_increment_increment = 4;
在每个分片表设置初始值:
alter table user_001 auto_increment = 1; alter table user_002 auto_increment = 5; alter table user_003 auto_increment = 9; alter table user_004 auto_increment = 13;
每个分片表的步长与全局步长一致,确保主键全局唯一
步长分配法优缺点:
- 优点:实现简单,无需额外工具,性能较好。
- 缺点:分片数固定,扩容困难,需重新计算步长
2. 雪花算法实现(高频)

实现步骤:
- 设计分布式id生成器,包含时间戳、机器id和序列号。
- 为每个分片分配唯一的机器id。
- 在分片间共享序列号,避免重复。
雪花算法优缺点:
- 优点:全局唯一,无需依赖mysql参数,支持动态扩容。
- 缺点:实现复杂,需额外开发id生成服务
四、实际操作指南
4.1 主从同步完整配置流程
1. 环境准备
# 主库ip: 192.168.1.100 # 从库ip: 192.168.1.101 # 安装mysql 8.0 sudo yum install mysql-server sudo systemctl start mysqld sudo systemctl enable mysqld
2. 主库配置
# 获取初始化密码 sudo grep 'temporary password' /var/log/mysqld.log # 登录mysql mysql -u root -p # 修改root密码 alter user 'root'@'localhost' identified with mysql_native_password by 'newpassword123'; # 创建复制用户 create user 'repl'@'192.168.1.%' identified with mysql_native_password by 'replpassword123'; grant replication slave on *.* to 'repl'@'192.168.1.%'; flush privileges; # 修改my.cnf配置文件 sudo vi /etc/my.cnf # 添加以下配置 [mysqld] server-id=1 log-bin=mysql-bin binlog-do-db=your_db binlog-checksum=none binlog-format=row sync_binlog=1 innodb_flush_log_at_trx_commit=1 gtid_mode=on enforce_gtid_consistency=on
3. 从库配置
# 修改my.cnf配置文件 sudo vi /etc/my.cnf # 添加以下配置 [mysqld] server-id=2 log-bin=mysql-bin replicate-do-db=your_db replicate_binlog checksum=0 replicate_binlog format=mixed gtid_mode=on enforce_gtid_consistency=on read-only=on
4. 初始化数据同步
# 主库导出数据
mysqldump -u root -p --single-transaction your_db > dump.sql
# 从库导入数据
mysql -u root -p your_db < dump.sql
# 从库设置主库信息
change master to
master_host='192.168.1.100',
master_user='repl',
master_password='replpassword123',
master auto_position=1;
# 启动从库复制
start slave;
# 检查复制状态
show slave status\g关键指标检查:
slaveiorunning应为yesslavesqlrunning应为yessecondsbehindmaster应接近0
4.2 分库分表示例
1. 手动分库分表示例
-- 创建分片表
create table user_001 (
id bigint primary key auto_increment,
user_id bigint,
name varchar(50),
email varchar(100),
phone varchar(20),
created_at datetime default current_timestamp
) engine=innodb;
-- 创建其他分片表
create table user_002 like user_001;
create table user_003 like user_001;
create table user_004 like user_001;
-- 设置主键步长
alter table user_001 auto_increment=1;
alter table user_002 auto_increment=5;
alter table user_003 auto_increment=9;
alter table user_004 auto_increment=13;
-- 设置全局步长
set global auto_increment_increment=4;2. 数据操作路由逻辑
// 使用shardingsphere的shardingspheredatasource
shardingspheredatasource datasource = shardingspheredatasourcefactory.createdatasource(
createdatasourcemap(),
createruleconfiguration(),
new properties()
);
// 插入用户
public void insertuser(user user) {
try (connection conn = datasource.getconnection()) {
conn预备语句(
"insert into t_user (user_id, name, email, phone) " +
"values (?, ?, ?, ?)"
). executeupdate();
}
}
// 查询用户
public user getuser(long userid) {
try (connection conn = datasource.getconnection()) {
预备语句ps = conn预备语句(
"select * from t_user where user_id = ?"
);
ps.setlong(1, userid);
结果集rs = ps执行查询();
if (rs.next()) {
return maptouser(rs);
}
}
return null;
}3. shardingsphere中间件配置
# shardingsphere配置文件
rules:
- !sharding
tables:
t_user:
actualdatanodes: ds_${0..3}.t_user_${0..3}
tablestrategy:
standard:
shardingcolumn: user_id
shardingalgorithmname: inline
shardingalgorithms:
inline:
type: inline
props:
algorithm-expression: t_user_${user_id % 4}配置说明:
actualdatanodes:定义物理数据节点,ds_${0..3}表示4个数据库实例。shardingcolumn:指定分片键为user_id。algorithm-expression:使用取模算法将数据均匀分布到4个分表中。
五、最佳实践与性能优化
5.1 主从同步优化建议
1. 配置优化
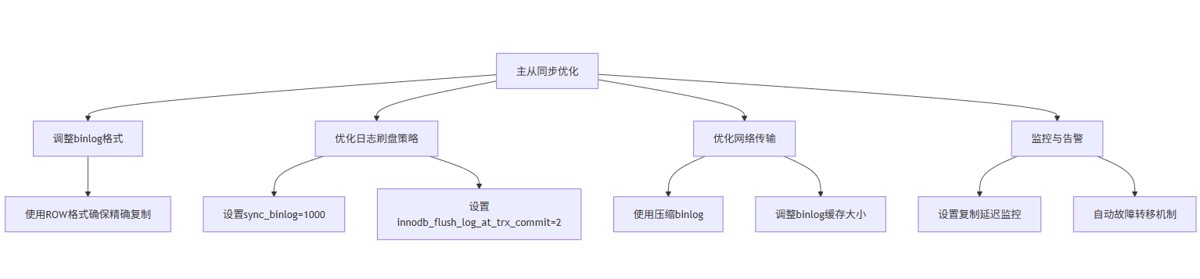
优化建议:
- binlog格式:推荐使用
row格式,确保精确复制,避免statement格式的不可重现问题 。 - 日志刷盘策略:设
sync_binlog=1000平衡性能与安全,设innodb_flush_log_at_trx_commit=2减少i/o开销 。 - 网络传输优化:使用
binlog_row_image=minimal仅记录变更的列,减少传输数据量。 - 监控与告警:设置复制延迟监控(
secondsbehindmaster),当延迟超过阈值时自动告警。
2. 性能监控指标
监控方法:
- 定期执行
show slave status\g检查复制状态。 - 使用
checksum table验证主从数据一致性。 - 使用
pt-table-checksum工具进行大规模数据校验
5.2 分库分表优化策略
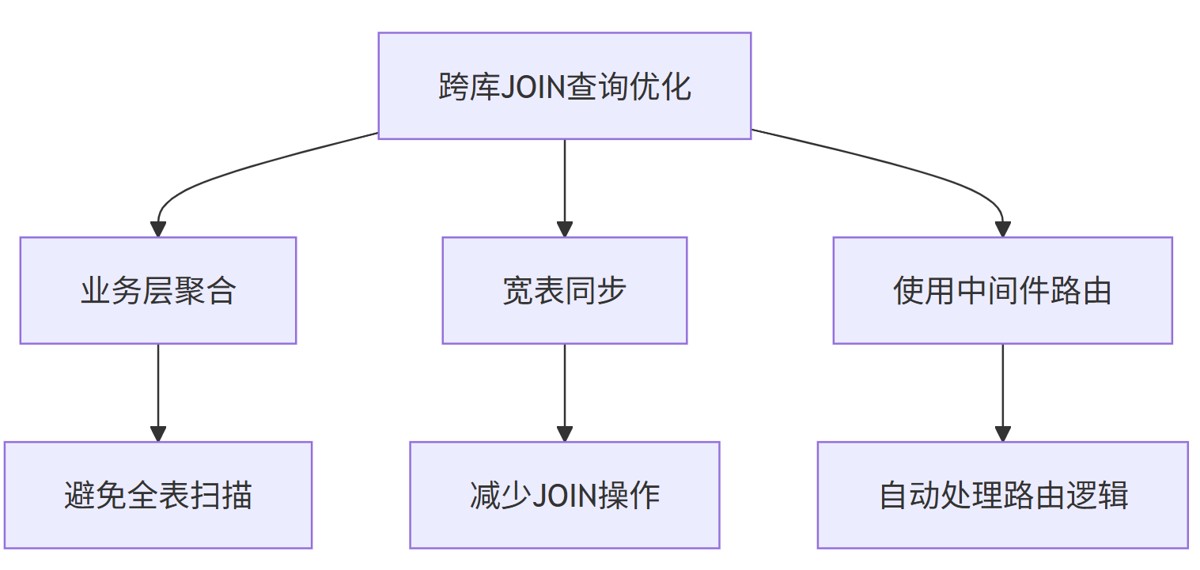
1. 跨库查询优化
优化方法:
- 业务层聚合:在应用层先查询主表获取主键列表,再查询关联表,最后合并结果。
- 宽表同步:将关联表的数据同步到数据仓库(如hadoop或clickhouse),生成宽表减少join操作。
- 中间件路由:使用shardingsphere等中间件自动处理路由逻辑,简化开发(若感兴趣,评论区告诉我,会单独出一期讲述)
六、总结与实施建议
mysql主从同步和分库分表是应对高并发、大数据量场景的核心技术,通过合理设计和配置,可以显著提升系统的性能和可靠性。在实际实施中,建议遵循以下原则:
- 先垂直后水平:优先按业务模块进行垂直分库分表,再考虑水平分片
- 逐步扩展:从简单的读写分离开始,随着数据量增长逐步引入分库分表
- 工具辅助:使用mycat、shardingsphere等中间件简化分库分表实现
- 监控先行:建立完善的监控体系,跟踪复制延迟、分片负载等关键指标
- 数据一致性:在性能与一致性之间找到平衡点,根据业务需求选择合适的事务处理方案
结语: 至此,《7天读懂mysql》已完结,你都懂了吗?
到此这篇关于mysql主从同步与分库分表的文章就介绍到这了,更多相关mysql内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论