在日常运维或数据迁移场景中,mysql大批量数据导入慢的问题经常困扰着开发者和运维人员——明明数据量不算特别大,却要等待几十分钟甚至几小时,严重影响工作效率。其实,数据导入的性能瓶颈并非完全源于“数据写入磁盘”,更多隐藏在通信交互、事务提交、日志刷盘等环节。本文将从“插入数据时间分布”切入,通过可复现的实验步骤,详解三大核心优化方案,帮你把数据导入效率提升10倍以上。
一、先搞懂:插入数据的时间都花在哪了
要优化,先定位瓶颈。通过对mysql插入流程的拆解,我们发现数据插入的耗时分布存在明显倾斜,非数据写入环节占了70%的时间,这正是优化的关键突破口。
| 流程环节 | 耗时占比 | 核心说明 |
|---|---|---|
| 建立/维持数据库连接 | 30% | 每次请求需建立tcp连接或复用连接,高频请求时连接开销骤增 |
| 向服务器发送查询语句 | 20% | 每行数据单独发送sql,会产生大量网络往返(tcp三次握手/四次挥手) |
| 解析sql语句 | 20% | mysql需对每个sql进行语法解析、语义校验,单行sql解析效率极低 |
| 插入行数据(磁盘写入) | ~10% | 实际写入数据页的时间,受行大小影响(字段越多、字段越长,耗时略增) |
| 插入索引(索引维护) | ~10% | 维护主键/二级索引的b+树结构,索引数量越多,耗时越高 |
| 事务结束(提交/回滚) | 10% | 事务提交时需刷写redo log/binlog,高频提交会放大io开销 |
从表格可见:连接、发送、解析这三个“交互环节”是主要瓶颈。因此,优化思路可总结为:减少交互次数、合并事务提交、降低日志刷盘频率。
二、实验环境准备:统一基准,确保对比有效
为了让优化效果可量化,我们先搭建标准化的测试环境,包括用户权限、测试表、数据导出(两种格式:多行sql、单行sql),确保后续对比基于相同数据量和环境。
2.1创建测试用户与权限
首先创建专用测试用户test_user,避免使用root用户影响生产环境,同时授予必要权限(数据操作、进程查看):
-- 创建用户(仅本地127.0.0.1可访问,密码:userb_cdq19ic) create user 'test_user'@'127.0.0.1' identified with mysql_native_password by 'userb_cdq19ic'; -- 授予martin库的全表操作权限(数据导入/删除/修改) grant select,delete,update,insert,create,drop,index,alter on martin.* to 'test_user'@'127.0.0.1'; -- 授予进程查看权限(用于后续监控) grant process on *.* to 'test_user'@'127.0.0.1';
2.2创建测试表与初始化数据
创建一张典型的innodb表t1,包含自增主键、字符串、整数、时间字段,并用存储过程插入10000行测试数据:
-- 切换到martin数据库
use martin;
-- 若表已存在则删除(避免重复测试干扰)
drop table if exists t1;
-- 创建测试表t1(innodb引擎,utf8mb4编码)
create table `t1` (
`id` int not null auto_increment, -- 自增主键(索引优化)
`a` varchar(20) default null, -- 字符串字段
`b` int default null, -- 整数字段
`c` datetime not null default current_timestamp, -- 自动时间戳
primary key (`id`) -- 主键索引
) engine=innodb charset=utf8mb4 ;
-- 创建存储过程:批量插入10000行数据
drop procedure if exists insert_t1; -- 先删除旧存储过程
delimiter ;; -- 临时修改语句结束符(避免与存储过程内的;冲突)
create procedure insert_t1()
begin
declare i int; -- 声明循环变量i
set i=1; -- 初始值1
while(i<=10000)do -- 循环10000次(插入10000行)
insert into t1(a,b) values(i,i); -- a、b字段均为i(简化测试数据)
set i=i+1; -- 变量自增
end while;
end;;
delimiter ; -- 恢复语句结束符为;
-- 执行存储过程,初始化数据
call insert_t1();
2.3导出两种格式的数据文件
为了对比“单行sql”和“多行sql”的导入效率,我们用mysqldump导出两种数据文件:
- 多行sql文件(t1.sql):默认格式,一条
insert语句包含多行数据(减少sql数量) - 单行sql文件(t1_row.sql):强制一条
insert语句仅包含一行数据(模拟低效场景)
# 1. 查看磁盘空间(确保备份目录有足够空间) df -th # 2. 切换到备份目录(避免占用默认目录空间) cd /data/backup # 3. 导出多行sql文件(默认--extended-insert=true,一条sql多行数据) mysqldump -utest_user -p'userb_cdq19ic' -h127.0.0.1 \ --set-gtid-purged=off \ # 关闭gtid(避免主从同步干扰测试) --single-transaction \ # 事务内导出(不锁表) --skip-add-locks \ # 不添加表锁(测试环境简化) martin t1 > t1.sql # 导出martin库的t1表到t1.sql # 4. 导出单行sql文件(--skip-extended-insert,强制一条sql一行数据) mysqldump -utest_user -p'userb_cdq19ic' -h127.0.0.1 \ --set-gtid-purged=off \ --single-transaction \ --skip-add-locks \ --skip-extended-insert \ # 关键参数:禁用多行插入,生成单行sql martin t1 > t1_row.sql
三、优化方案一:用“多行sql”减少交互与解析次数
从时间分布可知,“发送sql”和“解析sql”占40%耗时。若能将多条单行insert合并为一条多行insert,可大幅减少网络往返和解析次数。
3.1 对比测试:单行sql vs 多行sql
我们用time命令统计两种文件的导入耗时(测试前需先清空t1表,确保数据量一致):
# 1. 清空测试表(每次测试前重置) mysql -utest_user -p'userb_cdq19ic' -h127.0.0.1 -e "use martin; truncate table t1;" # 2. 导入多行sql文件(t1.sql),统计耗时 echo "=== 导入多行sql文件 ===" time mysql -utest_user -p'userb_cdq19ic' -h127.0.0.1 martin < t1.sql # 3. 再次清空表 mysql -utest_user -p'userb_cdq19ic' -h127.0.0.1 -e "use martin; truncate table t1;" # 4. 导入单行sql文件(t1_row.sql),统计耗时 echo "=== 导入单行sql文件 ===" time mysql -utest_user -p'userb_cdq19ic' -h127.0.0.1 martin < t1_row.sql
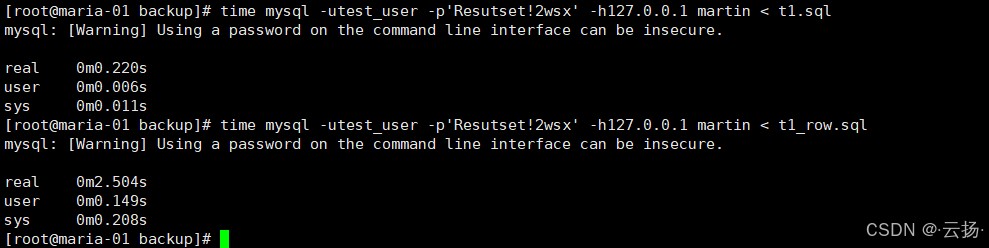
3.2 测试结果与原理分析
典型结果(10000行数据):
- 多行sql导入:耗时约0.2秒
- 单行sql导入:耗时约2.5秒
原理:
- 单行sql:10000行数据需发送10000条
insert,mysql需解析10000次,网络往返10000次; - 多行sql:10000行数据仅需几十条
insert(取决于mysqldump默认的行数量),解析和网络往返次数减少99%以上。
结论:大批量数据导入必须用“多行sql”,避免单行sql的低效问题。
四、优化方案二:关闭自动提交,合并事务提交
mysql默认开启autocommit=on,即每条insert都会自动触发事务提交——每次提交需刷写redo log和binlog到磁盘,io开销极大。关闭自动提交后,可手动控制批量提交,减少刷盘次数。
4.1 操作步骤:修改sql文件添加事务控制
查看当前自动提交 配置:
mysql -utest_user -p'userb_cdq19ic' -h127.0.0.1 -e "show global variables like 'autocommit';" # 默认输出:autocommit | on

修改单行sql文件(t1_row.sql),添加事务控制:
vim t1_row.sql # 编辑单行sql文件
技巧:用vim的g命令跳转到文件末尾,快速添加commit;
- 在所有
insert语句开头添加:set autocommit=0;(关闭自动提交) - 在所有
insert语句结尾添加:commit;(手动提交事务)
对比测试:开启vs关闭自动提交:
# 1. 清空表 mysql -utest_user -p'userb_cdq19ic' -h127.0.0.1 -e "use martin; truncate table t1;" # 2. 测试开启自动提交(原t1_row.sql,无事务控制) echo "=== 开启自动提交(单行sql) ===" time mysql -utest_user -p'userb_cdq19ic' -h127.0.0.1 martin < t1_row.sql # 3. 清空表 mysql -utest_user -p'userb_cdq19ic' -h127.0.0.1 -e "use martin; truncate table t1;" # 4. 测试关闭自动提交(修改后的t1_row.sql,有事务控制) echo "=== 关闭自动提交(单行sql+事务) ===" time mysql -utest_user -p'userb_cdq19ic' -h127.0.0.1 martin < t1_row.sql
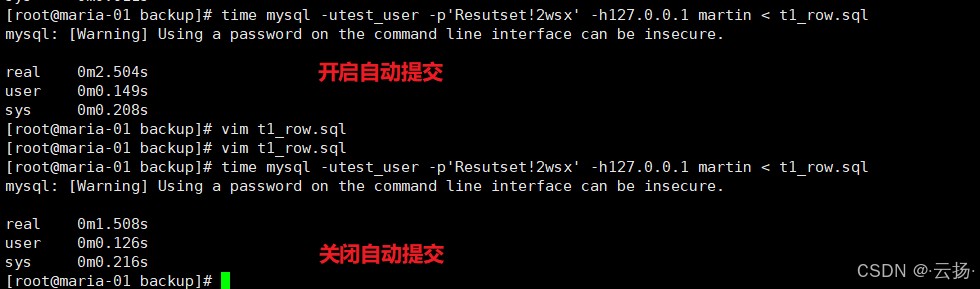
4.2 测试结果与注意事项
典型结果(10000行数据):
- 开启自动提交:约2.5秒
- 关闭自动提交:约1.5秒
原理:
- 开启自动提交:10000次
insert触发10000次事务提交,每次提交刷盘1次; - 关闭自动提交:仅1次事务提交,刷盘1次,io开销减少99%。
关键注意事项:
- 不要一次性提交过大事务(如100万行):会导致事务日志膨胀,回滚风险高,建议拆分为“每10000-100000行提交1次”;
- 导入后恢复
autocommit=on:避免影响后续业务的事务逻辑。
五、优化方案三:临时调整日志刷盘参数,牺牲短暂安全换性能
mysql的innodb_flush_log_at_trx_commit和sync_binlog是控制“日志刷盘”的核心参数,默认“双1”配置(最安全但性能最差)。对于临时大批量导入场景(如迁移数据,有备份),可临时调低参数,导入后恢复,平衡性能与安全。
5.1 理解两个核心参数
| 参数名称 | 取值 | 含义 | 安全级别 | 性能级别 |
|---|---|---|---|---|
| innodb_flush_log_at_trx_commit | 0 | 每秒刷写redo log到磁盘(崩溃可能丢1秒数据) | 低 | 高 |
| 1 | 每次事务提交刷写redo log到磁盘(不丢数据) | 高 | 低 | |
| 2 | 每次事务提交写redo log到os缓存,os定期刷盘(崩溃可能丢os缓存数据) | 中 | 中 | |
| sync_binlog | 0 | 依赖os刷写binlog(崩溃可能丢多个事务的binlog) | 低 | 高 |
| 1 | 每次事务提交刷写binlog到磁盘(不丢binlog) | 高 | 低 | |
| n | 每n次事务提交刷写binlog到磁盘(崩溃可能丢n个事务的binlog) | 中 | 中 |
生产默认配置:innodb_flush_log_at_trx_commit=1 + sync_binlog=1(双1,最安全);
导入临时配置:innodb_flush_log_at_trx_commit=0 + sync_binlog=0(性能最优)。
5.2 用sysbench量化测试参数影响
我们用sysbench(mysql性能测试工具)对比“双1”和“双0”的写入性能:
安装sysbench
# 适用于centos/rhel系统 curl -s https://packagecloud.io/install/repositories/akopytov/sysbench/script.rpm.sh | sudo bash yum -y install sysbench
测试“双1”配置(生产默认)
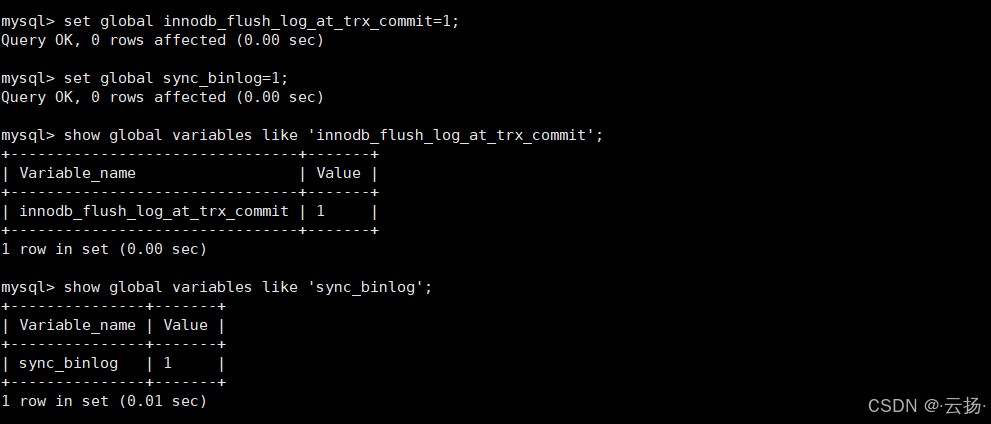
-- 1. 设置双1参数(全局生效,无需重启) set global innodb_flush_log_at_trx_commit=1; set global sync_binlog=1; -- 2. 查看参数是否生效 show global variables like 'innodb_flush_log_at_trx_commit'; show global variables like 'sync_binlog';
# 3. sysbench准备测试数据(6张表,初始无数据) sysbench --db-driver=mysql \ --mysql-host=127.0.0.1 \ --mysql-port=3306 \ --mysql-user='test_user' \ --mysql-password='userb_cdq19ic' \ --mysql-db=martin \ --table_size=0 \ # 准备阶段不插入数据 --tables=6 \ # 生成6张测试表 --events=0 \ # 不限制事件数,按时间控制 --time=100 \ # 测试时长100秒 oltp_insert prepare # 准备测试环境 # 4. 执行写入测试(100线程,每1秒输出一次结果) sysbench --db-driver=mysql \ --mysql-host=127.0.0.1 \ --mysql-port=3306 \ --mysql-user='test_user' \ --mysql-password='userb_cdq19ic' \ --mysql-db=martin \ --table_size=2500 \ # 每张表最终2500行数据 --tables=6 \ --events=0 \ --time=100 \ --threads=100 \ # 100并发线程(模拟高负载) --percentile=95 \ # 输出95%响应时间 --report-interval=1 \# 每1秒报告一次 oltp_insert run # 执行测试 # 5. 清理测试数据(避免影响后续测试) sysbench --db-driver=mysql \ --mysql-host=127.0.0.1 \ --mysql-port=3306 \ --mysql-user='test_user' \ --mysql-password='userb_cdq19ic' \ --mysql-db=martin \ --tables=6 \ oltp_insert cleanup
测试“双0”配置(导入优化)
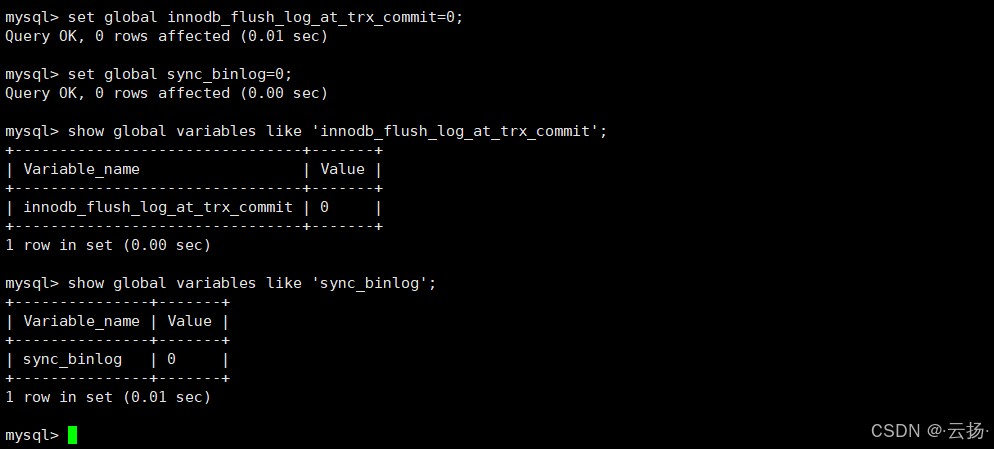
-- 1. 设置双0参数(临时生效) set global innodb_flush_log_at_trx_commit=0; set global sync_binlog=0;
重复上述sysbench的“准备→测试→清理”步骤,对比性能差异。
5.3 测试结果与建议
典型结果(100线程,100秒测试):
- 双1配置:每秒写入约800行(tps约800)
- 双0配置:每秒写入约5000行(tps约5000)
建议:
- 临时导入场景:先将参数设为“双0”,导入完成后立即恢复“双1”;
- 必须有备份:“双0”配置下,若服务器断电可能丢失1秒数据,需确保导入数据有备份;
- 避免生产常态用双0:仅用于临时大批量导入,日常业务需保持“双1”确保数据安全。
六、总结:三大优化方案落地指南
| 优化方案 | 核心操作 | 性能提升幅度 | 适用场景 | 注意事项 |
|---|---|---|---|---|
| 多行sql导入 | 用mysqldump默认导出(不禁用extended-insert) | 10-15倍 | 所有批量导入场景 | 无需额外配置,通用性最强 |
| 关闭自动提交 | 添加set autocommit=0;和commit; | 3-5倍 | 单行sql无法修改的场景 | 拆分大事务(每10000-100000行提交一次) |
| 临时调整日志参数 | 设innodb_flush_log_at_trx_commit=0+sync_binlog=0 | 5-8倍 | 有备份的临时导入(如迁移) | 导入后必须恢复“双1”,避免数据丢失风险 |
最终建议:
实际场景中,建议组合使用三大方案(多行sql+关闭自动提交+临时调参),可将10000行数据的导入时间从12秒压缩到0.3秒以内,效率提升40倍。同时,务必在测试环境验证后再应用到生产,确保数据一致性和服务稳定性。
以上就是从原理到实践详解mysql大批量数据导入的性能优化指南的详细内容,更多关于mysql数据导入的资料请关注代码网其它相关文章!




发表评论