insertorupdate在我们日常使用中比较常见,那么它是如何实现的呢,不知道大家有没有考虑过呢?
在mysql中,可采用insert into ... on duplicate key update语句实现insertorupdate功能。
值得留意的是,在出现重复键时,会在先前索引值和当前值之间添加临时键锁,这可能导致死锁。
若要使用insert into … on duplicate key update语句,需满足以下条件:
- 表必须具有主键或唯一索引;
- 插入的数据必须包含主键或唯一索引列;
- 主键或唯一索引列的值不能为null。
举个例子:
设想有一张student表,包括id、name和age三列,其中id是主键。现在要插入一条数据,若该数据的主键已存在,则更新该数据的姓名和年龄,否则插入该数据。
insert into student (id, name, age) values (1, 'paidaxing', 20) on duplicate key update name='paidaxing', age=18;
底层实现
使用insert into ... on duplicate key update语句,如果数据库中已存在具有相同唯一索引或主键的记录,则更新该记录。
其底层原理和执行流程如下:
- 检查唯一索引或主键:执行
insert into ... on duplicate key update语句时,数据库首先尝试插入新行。在此过程中,数据库会检查表中是否存在与新插入行具有相同的唯一索引或主键的记录。 - 冲突处理:如果不存在冲突的唯一索引或主键,新行将被正常插入。如果存在冲突,即发现重复的唯一索引或主键值,数据库将不会插入新行,而是转而执行更新操作。
- 执行更新:在检测到唯一索引或主键的冲突后,数据库将根据
on duplicate key update后面指定的列和值来更新已存在的记录。这里可以指定一个或多个列进行更新,并且可以使用values函数引用原本尝试插入的值。
相似sql
除了insert into … on duplicate key update之外,还有一些类似的sql语句,比如:
replace into:如果存在唯一索引冲突,则先删除旧记录,再插入新记录。insert ignore into:如果唯一索引冲突,则忽略该条插入操作,不报错。
浅谈主键跳跃
在mysql中使用insert on duplicate key update语句时,如果插入操作失败(因为主键或唯一键冲突),而执行了更新操作,确实会导致自增主键计数器增加,即使没有实际插入新记录。
这是因为mysql在尝试插入新记录时,会先分配一个新的自增主键值,无论后续是插入成功还是执行更新操作,这个主键值都已经被分配并且会增加。
例如,假设有一个表test定义如下:
create table test (
id int auto_increment primary key,
value varchar(255),
unique key unique_value (value)
);
然后执行以下语句:
insert into test (value) values ('a')
on duplicate key update value = 'a';
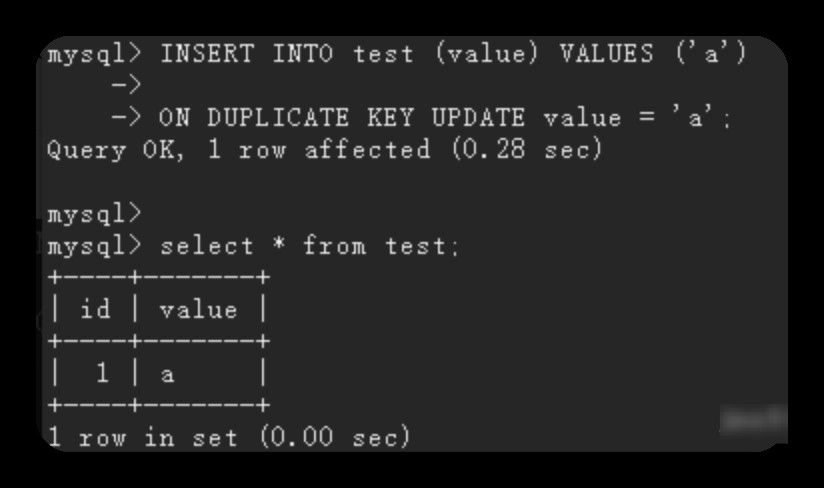
再执行一次:
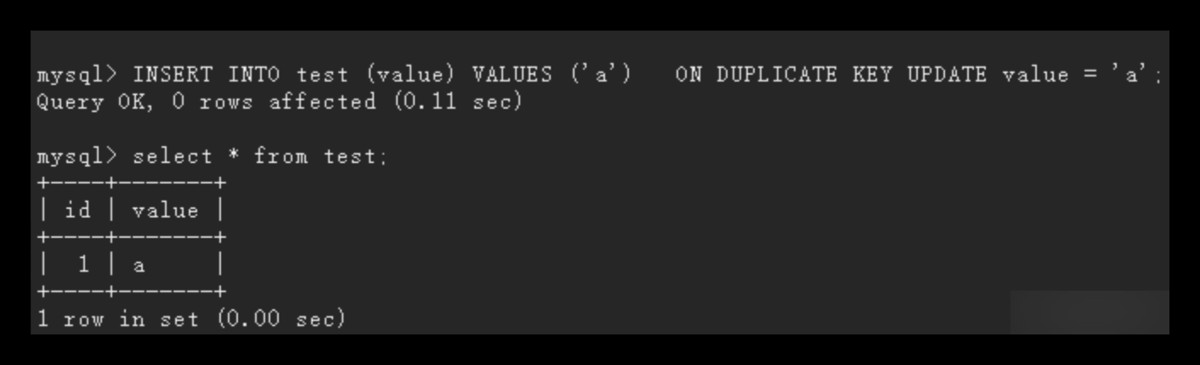
此时,由于value列存在唯一键约束,并且已经存在一条记录value=‘a’,所以不会插入新记录,而是会执行更新操作。但即便如此,自增主键id的计数器依然会增加。
然后再插入一条新的记录:
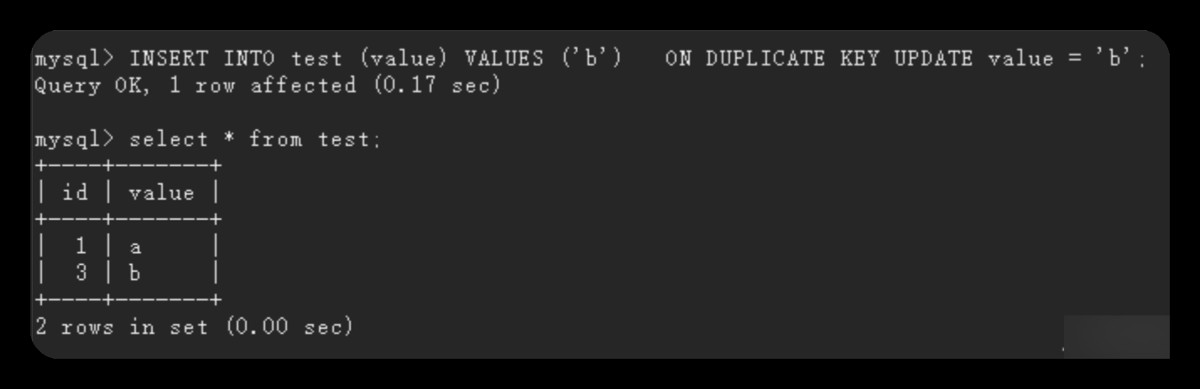
这意味着下一次插入新记录时,自增主键的值会比之前增加,即2已经被用过了,虽然没插入成功,但是新的记录就直接用3了。
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。




发表评论