- 创建数据库、表,插入数据
create database idx_optimize character set 'utf8';
create table users(
id int primary key auto_increment,
user_name varchar(20) not null comment '姓名',
user_age int not null default 0 comment '年龄',
user_level varchar(20) not null comment '用户等级',
reg_time timestamp not null default current_timestamp comment '注册时间'
);
insert into users(user_name,user_age,user_level,reg_time)
values('tom',17,'a',now()),('jack',18,'b',now()),('lucy',18,'c',now());- 创建联合索引
alter table users add index idx_nal (user_name,user_age,user_level) using btree;
2.优化原则详解
1)最佳左前缀法则
最佳左前缀法则: 如果创建的是联合索引,就必须遵守这个法则,当使用联合索引时,where后面条件需要从索引的最左前开始使用。
- 场景1: 按照索引字段顺序使用,三个字段都使用了索引,没有问题
explain select * from users where user_name = 'tom' and user_age = 17 and user_level = 'a';

- 场景2: 直接跳过user_name使用索引字段,索引无效,未使用到索引。
explain select * from users where user_age = 17 and user_level = 'a';

- 场景3: 不按照创建联合索引的顺序,使用索引
explain select * from users where user_age = 17 and user_name = 'tom' and user_level = 'a';

where后面查询条件顺序是 user_age、user_level、user_name与我们创建的索引顺序user_name、user_age、user_level不一致,为什么还是使用了索引,原因是因为mysql底层优化器对其进行了优化。
- 最佳左前缀底层原理
- mysql创建联合索引的时候要遵守一个规则: 首先会对联合索引最左边的字段进行排序,再在第一个字段的基础之上对第二个字段进行排序。
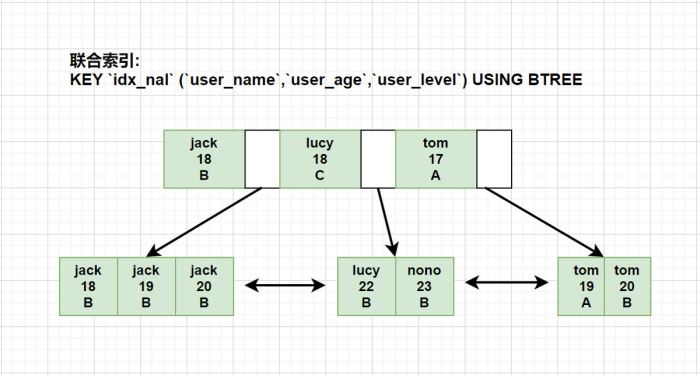
所以: 最佳左前缀原则其实是和b+树的结构有关系, 最左字段肯定是有序的, 第二个字段则是无序的(联合索引的排序方式是: 先按照第一个字段进行排序,如果第一个字段相等再根据第二个字段排序). 所以如果直接使用第二个字段 user_age 通常是使用不到索引的.
2) 不要在索引列上做任何计算
不要在索引列上做任何操作,比如计算、使用函数、自动或手动进行类型转换,会导致索引失效,从而使查询转向全表扫描。
- 插入数据
insert into users(user_name,user_age,user_level,reg_time) values('11223344',22,'d',now());- 场景1: 使用系统函数 left()函数,对user_name进行操作
explain select * from users where left(user_name, 6) = '112233';

场景2: 字符串不加单引号 (隐式类型转换)
varchar类型的字段,在查询的时候不加单引号,就需要进行隐式转换, 导致索引失效,转向全表扫描。
explain select * from users where

3) 范围之后全失效
范围之后全失效: where条件中如果有范围条件,并且范围条件之后还有其他条件.
- 场景1: 条件单独使用user_name时,
type=ref,key_len=62
-- 条件只有一个 user_name explain select * from users where user_name = 'tom';

场景2: 条件增加一个 user_age ( 使用常量等值) ,type= ref , key_len = 66
explain select * from users where user_name = 'tom' and user_age = 17;

场景3: 使用全值匹配, type = ref , key_len = 128 , 索引都利用上了.
explain select * from users where user_name = 'tom' and user_age = 17 and user_level = 'a';

场景4: 使用范围条件时, avg > 17 , type = range , key_len = 66 , 与场景3 比较,可以发现 user_level 索引没有用上.
-----使用范围条件 user_age>17 ,user_level索引就失效了 explain select * from users where user_name = 'tom' and user_age > 17 and user_level = 'a';


4) 避免使用 is null 、 is not null、!= 、or
- 使用
is null会使索引失效
explain select * from users where user_name is null; ---impossible where: 表示where条件不成立,不能返回任何的行

- 使用
is not null会使索引失效
explain select * from users where user_name is not null; ---全表扫描

- 使用
!=和or会使索引失效
explain select * from users where user_name != 'tom'; explain select * from users where user_name = 'tom' or user_name = 'jack';


5) like以%开头会使索引失效
like查询为范围查询,%出现在左边,则索引失效。%出现在右边索引未失效.
- 场景1: 两边都有% 或者 字段右边有%,索引都会失效
explain select * from users where user_name like '%tom%'; explain select * from users where user_name like '%tom';

对比场景1可以知道, 通过使用覆盖索引 type = index,并且 extra = using index,从全表扫描变成了全索引扫描.
场景2: 字段左边有%,索引生效
explain select * from users where user_name like 'tom%';

解决%出现在左边索引失效的方法
- 使用覆盖索引
explain select user_name from users where user_name like '%jack%'; explain select user_name,user_age,user_level from users where user_name like '%jack%';

like 失效的原理
- %号在右: 由于b+树的索引顺序,是按照首字母的大小进行排序,%号在右的匹配又是匹配首字母。所以可以在b+树上进行有序的查找,查找首字母符合要求的数据。所以有些时候可以用到索引.
- %号在左: 是匹配字符串尾部的数据,我们上面说了排序规则,尾部的字母是没有顺序的,所以不能按照索引顺序查询,就用不到索引.
- 两个%%号: 这个是查询任意位置的字母满足条件即可,只有首字母是进行索引排序的,其他位置的字母都是相对无序的,所以查找任意位置的字母是用不上索引的.
索引优化原则总结
- 最左前缀法则要遵守
- 索引列上不计算
- 范围之后全失效
- 覆盖索引记住用。
- 不等于、is null、is not null、or导致索引失效。
- like百分号加右边,加左边导致索引失效,解决方法:使用覆盖索引。
到此这篇关于mysql的索引优化原则的文章就介绍到这了,更多相关mysql索引优化内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论