第一章 分层架构解析
1.1 闭环监控体系架构深度解析
一个完整的监控体系需要构建四个关键层级,形成从数据采集到自动处理的完整闭环。数据采集层负责从各个服务实例收集指标数据,这一层通常使用springboot actuator提供丰富的应用指标,配合prometheus javaagent实现jvm层面的深度监控,同时通过自定义exporter扩展业务特定指标的采集能力。
存储层是监控体系的基石,prometheus tsdb作为核心存储引擎,采用了特殊的时间序列数据组织方式。对于大规模部署环境,需要引入thanos、cortex或victoriametrics等分布式解决方案,以解决单点存储的性能和容量限制。特别是victoriametrics,其高达1:10的存储压缩比,使其成为处理万亿级指标数据的理想选择。
告警层是整个体系的中枢神经系统,通过promql规则引擎对收集到的指标进行实时分析,当检测到异常模式时,alertmanager负责管理和路由这些告警信息。现代监控系统还会引入ai降噪引擎,自动识别和过滤无关紧要的告警,确保工程师只关注真正重要的问题。
1.2 各组件黄金版本组合与选型指南
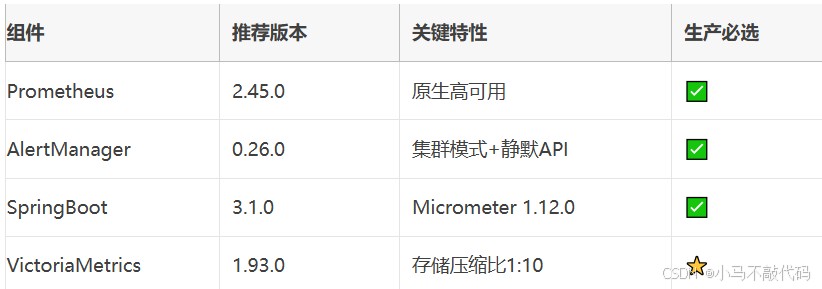
在选择监控体系各组件版本时,需要综合考虑稳定性、功能特性和性能表现。prometheus 2.45.0版本提供了原生高可用支持,极大简化了集群部署的复杂度。alertmanager 0.26.0版本增强了集群模式和静默api功能,为大规模告警管理提供了坚实基础。
springboot 3.1.0与micrometer 1.12.0的搭配为应用指标采集提供了最佳实践,支持超过600种不同类型的监控指标。对于存储层,victoriametrics 1.93.0以其卓越的存储压缩效率成为处理海量监控数据的首选方案,特别适合金融级应用场景。
需要特别注意的是,各组件的版本兼容性至关重要。不同版本间的api变化和功能差异可能导致监控体系出现不可预知的行为,因此在生产环境部署前必须进行充分的兼容性测试和性能验证。
第二章 prometheus存储引擎:tsdb
2.1 存储结构深度解析与优化策略
prometheus tsdb(time series database)的存储引擎设计体现了时间序列数据处理的精髓。其核心思想是将连续的时间序列数据分割成可管理的块(chunk),每个块包含特定时间范围内的数据点。内存中的活跃块(head block)负责接收最新写入的数据,每2小时,系统会将已满的块持久化到磁盘中,形成不可变的持久化块。
这种设计带来了多重好处:首先, immutable的特性使得读取操作不需要加锁,极大提高了查询性能;其次,定期落盘机制减少了内存占用,避免了长时间运行后的内存压力;最后,块结构的组织方式天然支持高效的范围查询和数据压缩。
tsdb的索引系统采用倒排索引结构,能够快速根据标签组合定位到相应的时间序列。每个块都有对应的索引文件,记录了这个块内所有时间序列的元数据和位置信息。这种结构虽然初始构建需要一定开销,但一旦建立,就能提供极其高效的查询性能。
块文件结构详解:
├── b-0001 │ ├── chunks # 原始数据点 │ ├── index # 倒排索引 │ └── meta.json # 元数据
2.2 高效查询算法与java实现原理
prometheus的查询性能很大程度上得益于其高效的索引查找算法。在java中实现类似的查询机制需要特别注意内存管理和缓存策略。以下是通过java实现的高效标签匹配算法:
public list<long> selectseries(map<string, map<string, list<long>>> postings,
list<labelmatcher> matchers) {
// 初始化结果集
set<long> result = new hashset<>();
boolean firstmatcher = true;
for (labelmatcher matcher : matchers) {
set<long> matches = new hashset<>();
// 遍历标签名称
for (string name : postings.keyset()) {
if (!matcher.matchesname(name)) {
continue;
}
// 遍历标签值
map<string, list<long>> values = postings.get(name);
for (string value : values.keyset()) {
if (matcher.matchesvalue(value)) {
matches.addall(values.get(value));
}
}
}
// 应用集合操作
if (firstmatcher) {
result.addall(matches);
firstmatcher = false;
} else {
result.retainall(matches);
}
if (result.isempty()) {
break;
}
}
return new arraylist<>(result);
}这个算法通过倒排索引结构快速定位匹配特定标签条件的时间序列。首先遍历所有标签名称,筛选出符合匹配条件的名称,然后在这些名称对应的值中进一步筛选,最终通过集合交集操作得到完全匹配所有条件的时间序列id。
在实际生产环境中,还需要考虑多种优化策略:使用布隆过滤器预先判断是否存在匹配项,避免不必要的集合操作;采用分层缓存机制,将热点数据的索引信息缓存在内存中;实现查询并行化,充分利用多核处理器的计算能力。
第三章 springboot指标暴露:micrometer
3.1 监控端点矩阵与金融级配置标准
springboot actuator提供了丰富的监控端点,每个端点都服务于特定类型的监控需求。/actuator/metrics端点暴露了jvm、http请求、数据库连接等600多个关键指标,为应用性能监控提供了全方位的数据支撑。在金融级应用中,这些指标的采集间隔通常设置为2秒,以确保能够捕捉到瞬时的性能波动。
/actuator/prometheus端点以prometheus格式输出指标数据,这种格式具有良好的结构和可读性,便于prometheus直接抓取和存储。在生产环境中,这个端点是必须启用的核心功能,它为整个监控体系提供标准化的数据输入。
健康检查端点(/actuator/health)的设计需要超越简单的服务状态汇报,实现细粒度的组件健康状态监测。例如,数据库连接池状态、外部服务依赖状况、磁盘空间使用情况等都应当纳入健康检查范围,形成综合的健康状态评估。
线程转储端点(/actuator/threaddump)提供了线程级别的运行洞察,能够自动检测死锁情况和线程资源竞争问题。通过定期分析线程状态,可以提前发现潜在的性能瓶颈和资源争用问题。

3.2 自定义业务指标的最佳实践与java实现
在复杂的业务场景中,默认的系统指标往往不足以全面反映应用的健康状态和性能表现。这时就需要通过自定义指标来扩展监控维度。以下是通过java实现订单支付延迟监控的完整示例:
// 订单支付延迟监控完整实现
@service
public class paymentmonitoringservice {
private final timer paymentprocessingtimer;
private final counter paymentsuccesscounter;
private final counter paymentfailurecounter;
private final distributionsummary paymentamountsummary;
// 支付延迟百分位数配置
private static final double[] percentiles = {0.5, 0.75, 0.95, 0.99};
// slo配置(单位:毫秒)
private static final duration[] slo_boundaries = {
duration.ofmillis(100),
duration.ofmillis(500),
duration.ofmillis(1000)
};
@autowired
public paymentmonitoringservice(meterregistry registry) {
// 初始化支付处理计时器
paymentprocessingtimer = timer.builder("payment.process.time")
.description("支付处理耗时分布")
.publishpercentiles(percentiles) // 发布百分位数指标
.publishpercentilehistogram(true) // 启用百分位直方图
.servicelevelobjectives(slo_boundaries) // 设置slo边界
.register(registry);
// 初始化支付成功计数器
paymentsuccesscounter = counter.builder("payment.success.count")
.description("成功支付次数")
.tag("payment_method", "all") // 按支付方式打标
.register(registry);
// 初始化支付失败计数器
paymentfailurecounter = counter.builder("payment.failure.count")
.description("失败支付次数")
.tag("error_type", "all") // 按错误类型打标
.register(registry);
// 初始化支付金额分布摘要
paymentamountsummary = distributionsummary.builder("payment.amount.summary")
.description("支付金额分布")
.baseunit("usd") // 设置基准单位
.register(registry);
}
/**
* 记录支付处理时间
* @param paymentprocess 支付处理逻辑
* @param amount 支付金额
* @return 支付处理结果
*/
public <t> t recordpaymentexecution(supplier<t> paymentprocess, bigdecimal amount) {
// 记录支付开始时间
long starttime = system.nanotime();
try {
// 执行支付处理
t result = paymentprocess.get();
// 记录成功指标
paymentsuccesscounter.increment();
paymentamountsummary.record(amount.doublevalue());
return result;
} catch (exception e) {
// 记录失败指标
paymentfailurecounter.increment();
throw e;
} finally {
// 记录处理耗时
long duration = system.nanotime() - starttime;
paymentprocessingtimer.record(duration, timeunit.nanoseconds);
}
}
/**
* 获取当前支付性能指标快照
* @return 指标快照信息
*/
public paymentmetricssnapshot getcurrentmetricssnapshot() {
return new paymentmetricssnapshot(
paymentprocessingtimer.count(),
paymentprocessingtimer.totaltime(timeunit.milliseconds),
paymentsuccesscounter.count(),
paymentfailurecounter.count(),
paymentamountsummary.totalamount(),
paymentamountsummary.count()
);
}
// 指标快照数据传输对象
@data
@allargsconstructor
public static class paymentmetricssnapshot {
private long totalprocessedcount;
private double totalprocessingtimems;
private long successcount;
private long failurecount;
private double totalamountprocessed;
private long totalamountrecords;
public double getsuccessrate() {
return totalprocessedcount > 0 ?
(double) successcount / totalprocessedcount * 100 : 0;
}
public double getaverageprocessingtime() {
return totalprocessedcount > 0 ?
totalprocessingtimems / totalprocessedcount : 0;
}
}
}这个自定义监控实现包含了多个关键设计考虑:首先,通过timer组件精确测量支付处理耗时,并计算多个百分位数指标,帮助识别尾部延迟问题;其次,使用counter组件分别统计成功和失败的支付次数,便于计算成功率指标;第三,通过distributionsummary记录支付金额的分布情况,帮助分析交易模式。
在实际部署时,还需要考虑以下几个重要方面:指标标签的设计应该具有良好的维度性,便于后续的聚合和筛选;指标的命名应该遵循明确的规范,通常采用dot.case命名法;对于高频调用的监控点,需要特别关注性能开销,必要时采用抽样或异步记录策略。
第四章 alertmanager:告警分组
4.1 告警分组算法与路由机制深度解析
alertmanager的核心价值在于其智能的告警分组和路由机制。当大量告警同时发生时,简单的逐一通知会导致告警风暴,使运维人员无法快速识别真正重要的问题。alertmanager通过分组算法将相关告警聚合在一起,形成有意义的通知单元。
分组算法的核心是基于标签相似度的聚类分析。系统会检查每个告警的标签集合,将具有相同关键标签(如cluster、service、alertname等)的告警归为同一组。这种分组方式确保了相关告警会被一起处理,避免了碎片化的通知。
4.2 动态抑制规则的java实现与最佳实践
告警抑制是防止冗余通知的关键机制。通过合理的抑制规则配置,可以确保在重大故障发生时,只收到最根本问题的告警,而不是成千上万个衍生告警。以下是通过java实现的告警抑制引擎核心逻辑:
public class alertinhibitionengine {
private final list<inhibitionrule> rules;
private final alertstore alertstore;
// 抑制规则内部类
@data
@allargsconstructor
public static class inhibitionrule {
private map<string, string> sourcematchers;
private map<string, string> targetmatchers;
private list<string> equallabels;
}
/**
* 检查告警是否被抑制
*/
public boolean isinhibited(alert alert) {
for (inhibitionrule rule : rules) {
if (matchesrule(alert, rule)) {
return true;
}
}
return false;
}
private boolean matchesrule(alert alert, inhibitionrule rule) {
// 检查是否匹配目标条件
if (!matcheslabels(alert.getlabels(), rule.gettargetmatchers())) {
return false;
}
// 查找匹配源条件的活跃告警
return alertstore.getactivealerts().stream()
.filter(sourcealert -> matcheslabels(sourcealert.getlabels(), rule.getsourcematchers()))
.anymatch(sourcealert -> hasequallabels(sourcealert, alert, rule.getequallabels()));
}
private boolean matcheslabels(map<string, string> alertlabels,
map<string, string> matchers) {
return matchers.entryset().stream()
.allmatch(entry -> alertlabels.getordefault(entry.getkey(), "")
.matches(entry.getvalue()));
}
private boolean hasequallabels(alert source, alert target, list<string> labelkeys) {
return labelkeys.stream()
.allmatch(key -> objects.equals(
source.getlabels().get(key),
target.getlabels().get(key)));
}
}4.3 告警收敛算法的数学基础与实现
告警收敛是处理重复告警的关键技术,其核心算法基于指数退避策略。实际发送频率的计算公式为:
实际发送频率 = min(初始间隔 * 2^(告警次数-1), 最大间隔)
这个算法确保了在持续问题时,告警频率会逐渐降低,避免对运维人员造成不必要的干扰。同时通过设置最大间隔,保证了即使长时间未解决的问题,也不会完全停止告警通知。
在java中的实现需要考虑分布式环境下的并发控制,以下是一个集群安全的告警收敛实现:
public class alertthrottlingmanager {
private final distributedcache cache;
private final long initialinterval; // 初始间隔(毫秒)
private final long maxinterval; // 最大间隔(毫秒)
public boolean shouldnotify(string alertkey, int alertcount) {
long calculatedinterval = initialinterval * (long) math.pow(2, alertcount - 1);
long waittime = math.min(calculatedinterval, maxinterval);
// 使用分布式锁确保集群环境下的正确性
return cache.acquirelock(alertkey, waittime);
}
// 释放通知锁,允许下次通知
public void releasenotification(string alertkey) {
cache.releaselock(alertkey);
}
}第五章 存储优化与集群部署
5.1 分布式存储架构深度解析
在处理万亿级监控指标的场景下,单机版prometheus显然无法满足需求,这时就需要采用分布式存储架构。victoriametrics作为专门为大规模监控数据设计的存储方案,其架构设计体现了诸多精妙之处。
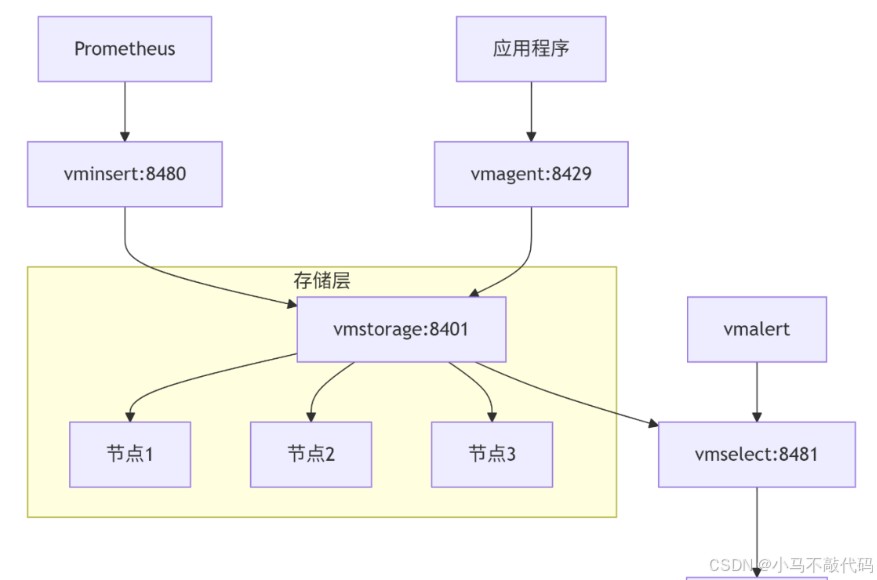
victoriametrics采用分离的存储和查询架构,写入节点(vminsert)负责接收数据并按照一致性哈希算法分发到存储节点(vmstorage),查询节点(vmselect)负责从存储节点获取数据并执行查询。这种架构允许独立扩展写入、存储和查询能力,提供了极大的弹性。
victoriametrics集群部署架构:
在java应用中集成victoriametrics时,需要使用特定的客户端库:
// victoriametrics java客户端配置
@configuration
public class victoriametricsconfig {
@value("${victoriametrics.host:localhost}")
private string vmhost;
@value("${victoriametrics.port:8428}")
private int vmport;
@bean
public meterregistry meterregistry() {
victoriametricsconfig config = new victoriametricsconfig() {
@override
public string uri() {
return "http://" + vmhost + ":" + vmport + "/api/v1/import/prometheus";
}
@override
public duration step() {
return duration.ofseconds(15);
}
};
return new victoriameterregistry(config, clock.system);
}
// 自定义指标推送器
@bean
public victoriametricspusher metricspusher(meterregistry meterregistry) {
victoriametricspusher pusher = new victoriametricspusher(config, meterregistry);
pusher.start();
return pusher;
}
}5.2 存储压缩与查询优化策略
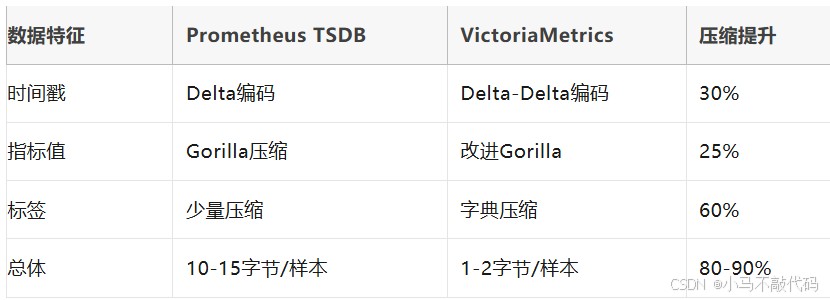
victoriametrics的存储压缩算法是其能够处理海量数据的关键。它采用了多种压缩技术,包括基于delta编码的时间戳压缩、基于xor的浮点数压缩,以及基于字典的标签值压缩。
存储压缩效果对比表:
查询优化方面,victoriametrics实现了多种智能优化策略:
// 查询优化策略实现
public class queryoptimizer {
// 查询缓存实现
private final cache<string, queryresult> querycache =
caffeine.newbuilder()
.maximumsize(10000)
.expireafterwrite(5, timeunit.minutes)
.build();
// 并行查询执行器
public queryresult executeparallelquery(string query, long start, long end) {
// 拆分时间范围为多个区间
list<timerange> ranges = splittimerange(start, end, 24 * 3600 * 1000); // 按天拆分
// 并行执行子查询
list<completablefuture<queryresult>> futures = ranges.stream()
.map(range -> completablefuture.supplyasync(() ->
executesubquery(query, range.start, range.end), queryexecutor))
.collect(collectors.tolist());
// 合并结果
return completablefuture.allof(futures.toarray(new completablefuture[0]))
.thenapply(v -> futures.stream()
.map(completablefuture::join)
.reduce(queryresult::merge)
.orelsethrow(() -> new runtimeexception("merge failed")))
.join();
}
// 查询重写优化
public string rewritequery(string originalquery) {
// 应用启发式重写规则
string rewritten = originalquery;
// 规则1: 将高基数标签过滤提前
rewritten = rewritten.replaceall(
"sum\\(([^}]+})\\) by \\(([^)]+)\\)",
"sum($1) by ($2)"
);
// 规则2: 避免不必要的排序
if (rewritten.contains("sort(") && !rewritten.contains("topk") && !rewritten.contains("bottomk")) {
rewritten = rewritten.replace("sort(", "(");
}
return rewritten;
}
}第六章 告警闭环与自动修复:从检测到自愈的完整链路
6.1 智能告警处理流水线
现代监控系统需要实现从告警检测到自动修复的完整闭环。这需要构建一个智能的告警处理流水线,包含事件捕获、丰富、关联、路由和自动化处理等多个环节。
6.2 基于规则的自动修复系统
自动修复是告警闭环的终极目标。通过预定义的修复规则和脚本,系统可以自动处理常见问题,大幅减少人工干预需求。
// 自动修复规则引擎
@service
public class autoremediationengine {
private final map<string, remediationrule> rules;
private final scriptexecutor scriptexecutor;
private final alertmanagerclient alertmanagerclient;
// 修复规则定义
@data
public static class remediationrule {
private string name;
private string alertpattern;
private string conditionscript;
private string remediationscript;
private int maxattempts;
private duration cooldownperiod;
}
/**
* 处理传入告警
*/
@async
public void processalert(alert alert) {
rules.values().stream()
.filter(rule -> matchespattern(alert, rule.getalertpattern()))
.filter(rule -> evaluatecondition(alert, rule.getconditionscript()))
.foreach(rule -> executeremediation(alert, rule));
}
/**
* 执行修复操作
*/
private void executeremediation(alert alert, remediationrule rule) {
try {
// 检查冷却期
if (isincooldown(alert, rule)) {
return;
}
// 执行修复脚本
remediationresult result = scriptexecutor.execute(
rule.getremediationscript(),
createexecutioncontext(alert)
);
if (result.issuccess()) {
// 修复成功,静默告警
alertmanagerclient.silencealert(alert, rule.getcooldownperiod());
log.info("remediation successful for alert: {}", alert.getlabels());
} else {
// 修复失败,记录重试
recordremediationattempt(alert, rule, result);
}
} catch (exception e) {
log.error("remediation failed for alert: {}", alert.getlabels(), e);
}
}
// 创建脚本执行上下文
private map<string, object> createexecutioncontext(alert alert) {
map<string, object> context = new hashmap<>();
context.put("alert", alert);
context.put("labels", alert.getlabels());
context.put("annotations", alert.getannotations());
context.put("starttime", alert.getstartsat());
context.put("currenttime", instant.now());
return context;
}
}6.3 修复策略模板库
建立常见问题的修复策略模板库,可以大幅提高自动修复的覆盖率和效果:
# 内存溢出修复模板
- name: memory_overflow_remediation
description: java应用内存溢出自动处理
conditions:
- alertname: "jvmoutofmemoryerror"
- severity: "critical"
steps:
- action: "thread_dump"
target: "application"
args:
output: "/tmp/threaddump_{{timestamp}}"
- action: "heap_dump"
target: "application"
args:
output: "/tmp/heapdump_{{timestamp}}"
- action: "restart"
target: "application"
args:
delay: "30s"
graceperiod: "60s"
coolingperiod: "1h"
# 数据库连接池耗尽修复模板
- name: db_connection_pool_exhausted
description: 数据库连接池耗尽自动扩容
conditions:
- alertname: "dbconnectionpoolexhausted"
- severity: "warning"
steps:
- action: "scale_connection_pool"
target: "database"
args:
maxsize: "{{currentsize * 1.5}}"
increment: "10"
- action: "execute_sql"
target: "database"
args:
sql: "kill query processlist where time > 300 and state = 'sleep'"
coolingperiod: "30m"第七章 金融级监控标准:合规性、可靠性与审计
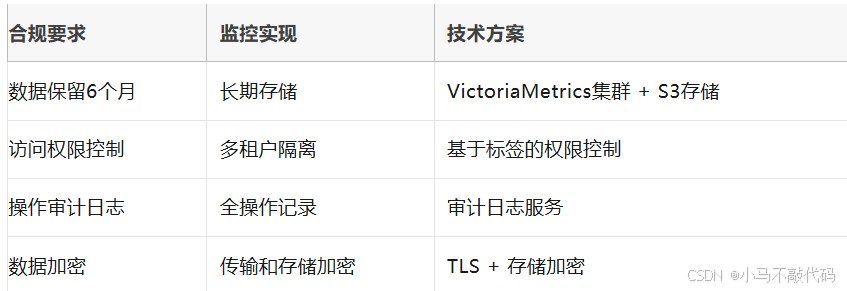
7.1 金融行业监控合规要求
金融行业的监控系统需要满足严格的合规性要求,包括数据保留策略、访问控制、审计日志等方面。
金融监控合规性矩阵:
7.2 高可用部署架构
金融级监控系统需要实现99.99%的高可用性,这需要通过多活部署、自动故障转移等机制来保证。
// 高可用监控代理
public class highavailabilityagent {
private final list<prometheusclient> prometheusclients;
private final healthchecker healthchecker;
private final loadbalancer loadbalancer;
/**
* 高可用查询方法
*/
public queryresult haquery(string query, long timeoutms) {
list<prometheusclient> healthyclients = prometheusclients.stream()
.filter(healthchecker::ishealthy)
.collect(collectors.tolist());
if (healthyclients.isempty()) {
throw new monitoringexception("no healthy prometheus instances available");
}
// 使用负载均衡策略选择实例
prometheusclient selectedclient = loadbalancer.select(healthyclients);
try {
return selectedclient.executequery(query, timeoutms);
} catch (exception e) {
// 标记实例不健康并重试
healthchecker.markunhealthy(selectedclient);
return haquery(query, timeoutms); // 递归重试
}
}
// 负载均衡策略
private prometheusclient selectclient(list<prometheusclient> clients) {
// 基于最少活跃请求的负载均衡
return clients.stream()
.min(comparator.comparingint(prometheusclient::getactiverequests))
.orelsethrow(() -> new illegalstateexception("no clients available"));
}
}7.3 监控系统自监控
监控系统自身也需要被严格监控,确保其健康和可靠运行:
# 监控系统自监控规则
groups:
- name: monitoring-system
rules:
- alert: prometheusscrapefailing
expr: up{job=~"prometheus.*"} == 0
for: 5m
labels:
severity: critical
component: monitoring
annotations:
summary: "prometheus实例抓取失败"
description: "prometheus实例 {{ $labels.instance }} 无法抓取指标"
- alert: alertmanagernotconnected
expr: alertmanager_cluster_health_score != 1
for: 2m
labels:
severity: warning
component: alerting
annotations:
summary: "alertmanager集群健康状态异常"
description: "alertmanager集群健康得分为 {{ $value }}"
- alert: victoriametricshighmemoryusage
expr: process_resident_memory_bytes{job=~"victoriametrics.*"} /
machine_memory_bytes > 0.8
for: 10m
labels:
severity: warning
component: storage
annotations:
summary: "victoriametrics内存使用率过高"
description: "victoriametrics实例 {{ $labels.instance }} 内存使用率超过80%"第八章 未来演进:aiops与智能监控
8.1 智能异常检测
传统的阈值告警往往无法适应复杂的业务场景,智能异常检测通过机器学习算法自动发现异常模式:
// 智能异常检测服务
@service
public class anomalydetectionservice {
private final timeseriesanalyzer timeseriesanalyzer;
private final modeltrainer modeltrainer;
private final map<string, detectionmodel> models;
/**
* 训练检测模型
*/
public void trainmodel(string metricname, list<datapoint> historicaldata) {
detectionmodel model = modeltrainer.train(historicaldata, createtrainingconfig());
models.put(metricname, model);
// 保存模型到持久化存储
savemodel(metricname, model);
}
/**
* 检测异常点
*/
public anomalydetectionresult detectanomalies(string metricname, list<datapoint> currentdata) {
detectionmodel model = models.get(metricname);
if (model == null) {
throw new modelnottrainedexception(metricname);
}
return model.detect(currentdata);
}
// 异常检测配置
private trainingconfig createtrainingconfig() {
return trainingconfig.builder()
.algorithm(algorithm.isolation_forest)
.sensitivity(0.8)
.windowsize(1440) // 24小时数据点
.seasonality(seasonality.daily)
.build();
}
}8.2 根因定位与影响分析
当发生故障时,快速定位根本原因和评估影响范围至关重要:
8.3 预测性监控与容量规划
通过历史数据分析和机器学习预测未来趋势,实现预测性监控和智能容量规划:
// 容量预测服务
@service
public class capacityforecastingservice {
private final timeseriesforecaster forecaster;
private final resourceusagecollector usagecollector;
/**
* 生成容量预测报告
*/
public capacityforecast generateforecast(string resourcetype, int forecastdays) {
// 收集历史使用数据
list<usagedata> historicaldata = usagecollector.collecthistoricaldata(
resourcetype,
localdate.now().minusdays(90), // 90天历史数据
localdate.now()
);
// 训练预测模型
forecastmodel model = forecaster.trainmodel(historicaldata);
// 生成预测
return model.forecast(forecastdays);
}
/**
* 获取扩容建议
*/
public scalingrecommendation getscalingrecommendation(string resourcetype) {
capacityforecast forecast = generateforecast(resourcetype, 30);
double currentcapacity = getcurrentcapacity(resourcetype);
double predictedpeak = forecast.getpeakusage();
double safetymargin = 0.3; // 30%安全边际
if (predictedpeak > currentcapacity * (1 - safetymargin)) {
return new scalingrecommendation(
resourcetype,
scalingdirection.scale_up,
calculaterequiredcapacity(predictedpeak, safetymargin),
forecast.getpeakdate()
);
}
return scalingrecommendation.noaction(resourcetype);
}
}结语:构建面向未来的智能监控体系
通过本文的深入探讨,我们全面解析了从基础监控到智能运维的完整演进路径。现代监控系统已经远远超越了简单的指标收集和告警发送,发展成为集成了存储优化、智能分析、自动修复和预测预警的综合性平台。
关键演进方向:
架构弹性化:从单机部署到分布式集群,支持水平扩展和自动容灾
分析智能化:从阈值告警到机器学习驱动的异常检测和根因分析
运维自动化:从人工处理到基于规则的自动修复和自愈系统
能力全面化:从基础设施监控到全栈可观测性,包括日志、追踪和指标
实施建议:
从实际业务需求出发,优先解决最关键的可观测性痛点
采用渐进式演进策略,避免大规模重构带来的风险
建立监控标准规范,确保各个系统和团队的一致性
重视监控数据的质量,垃圾数据无法产生有价值的洞察
培养团队的数据驱动文化,让监控洞察真正影响决策和行动
到此这篇关于springboot告警闭环之prometheus+alertmanager详解的文章就介绍到这了,更多相关springboot prometheus alertmanager告警内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!






发表评论