入门案例当中的“查询所有”调用的是basemapper当中的selectlist,接下来我们从增删查改来了解basemapper接口当中的方法。
/**
* 查询所有
*/
@test
public void testselectlist(){
usermapper.selectlist(null).foreach(system.out::println);
}1.查询
根据id查询
t selectbyid(serializable id);
这个没什么好说的就是根据id查询,返回t类型的对象。注意serializable,这里使用serializable 的原因是数据库的主键类型多种多样,比如integer、long、string等,而long, integer, string 等包装类和基本类型的包装类都实现了 serializable 接口。这就使得以serializable作为参数类型的selectbyid变得很通用。
调用代码:
/**
* 根据id查询
*/
@test
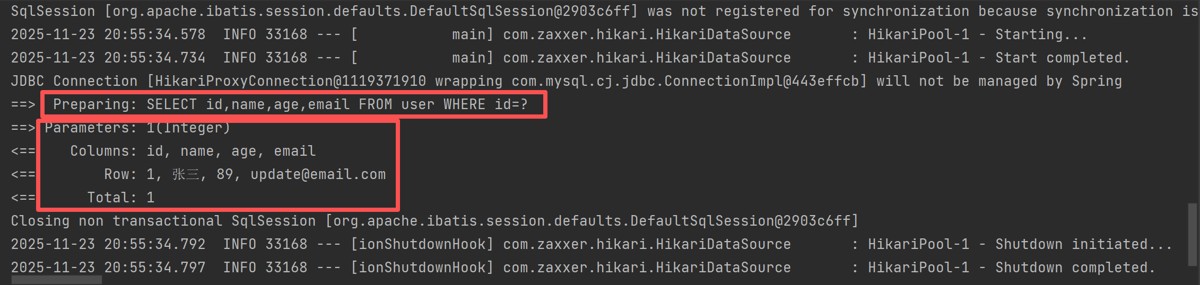
public void selectbyid(){
usermapper.selectbyid(1);
}运行结果:
根据多个id查询
list<t> selectbatchids(@param("coll") collection<? extends serializable> idlist);collection是java集合框架的根接口,list、set、queue等都实现了这个接口
? extends serializable是泛型通配符,表示"任何继承了serializable接口的类型"
所以我们传入的参数应该是实现了serializable接口的元素的集合,例如:
list<long> idlist = arrays.aslist(1l, 2l, 3l);
set<integer> idset = new hashset<>(arrays.aslist(1, 2));
list<string> idstrings = arrays.aslist("a", "b", "c");
arraylist<biginteger> bigints = new arraylist<>();selectbatchids 接收这样一个集合,返回t类对象的集合
调用代码:
/**
* 批量查询,也可以查询一个
*/
@test
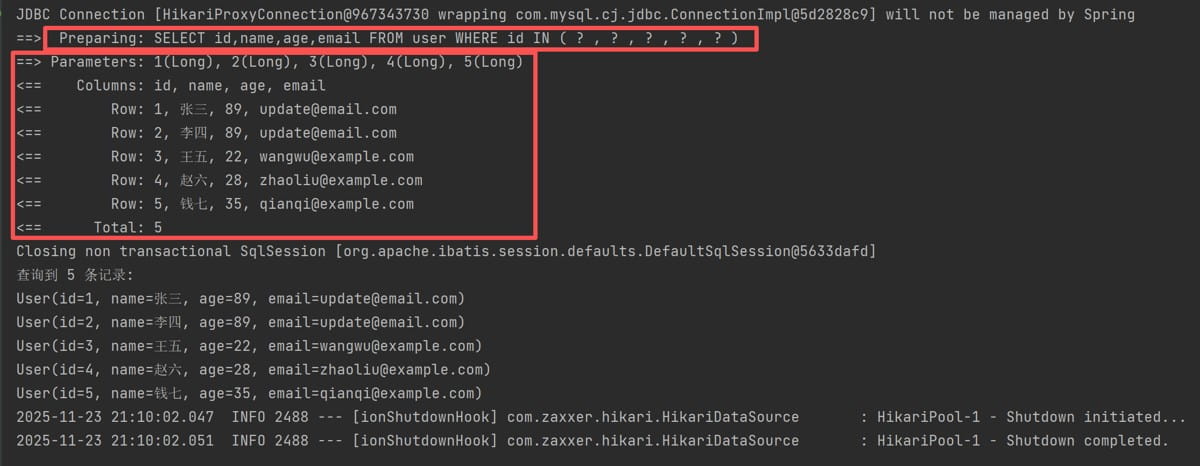
public void selectbatchbyids() {
list<long> idlist = arrays.aslist(1l, 2l, 3l, 4l, 5l);
list<user> users = usermapper.selectbatchids(idlist);
system.out.println("查询到 " + users.size() + " 条记录:");
users.foreach(system.out::println);
}运行结果:
根据字段名-值对的映射关系进行查询
list<t> selectbymap(@param("cm") map<string, object> columnmap);它接受一个字段名和对应值的map,返回所有匹配的记录。
生成的sql是 等值查询的 and 组合,类似于:
select * from table_name where column1 = ? and column2 = ? and ...;
我们要注意map当中的字段名字是数据库当中的名字而不是javabean当中的名字
调用代码:这段代码相当于查询了名字是mike并且年龄为18的所有用户,并返回它们的集合
/**
* 通过map查询用户信息
*/
@test
public void selectbymap(){
//通过map条件查询用户信息
//select id,name,age,email from user where name = ? and age = ?
map<string, object> map = new hashmap<>();
map.put("age", 18);
map.put("name", "mike");
list<user> list = usermapper.selectbymap(map);
list.foreach(system.out::println);
}运行结果:

期望返回一条记录的查询
default t selectone(@param("ew") wrapper<t> querywrapper) {
// 1. 先调用 selectlist 查询所有匹配的记录
list<t> ts = this.selectlist(querywrapper);
// 2. 检查结果列表是否不为空
if (collectionutils.isnotempty(ts)) {
// 3. 如果结果数量不等于1,抛出异常
if (ts.size() != 1) {
throw exceptionutils.mpe("one record is expected, but the query result is multiple records", new object[0]);
} else {
// 4. 如果正好只有1条记录,返回它
return ts.get(0);
}
} else {
// 5. 如果没有记录,返回null
return null;
}
}querywrapper 是 mybatis-plus 提供的查询条件封装器,用于以面向对象的方式动态构建 sql 查询条件,避免了手动拼接 sql 字符串的麻烦。有了querywrapper 之后,我们便可以使用java代码来构建sql查询条件,例如:
// 查询 name = '张三' 并且 age = 25 的用户
querywrapper<user> querywrapper = new querywrapper<>();
querywrapper.eq("name", "张三")
.eq("age", 25);
list<user> users = usermapper.selectlist(querywrapper);
// 生成sql: select * from user where name = '张三' and age = 25querywrapper还有很多复杂的用法,我们会在后面遇到。
我们可以看到selectone调用了前面的selectlist方法查询所有符合条件的记录,再检查记录条数是否是1.如果是1则返回,多余1则抛出异常,少于1则返回null
调用:这是刚好为1的情况
/**
* 查询单条记录
*/
@test
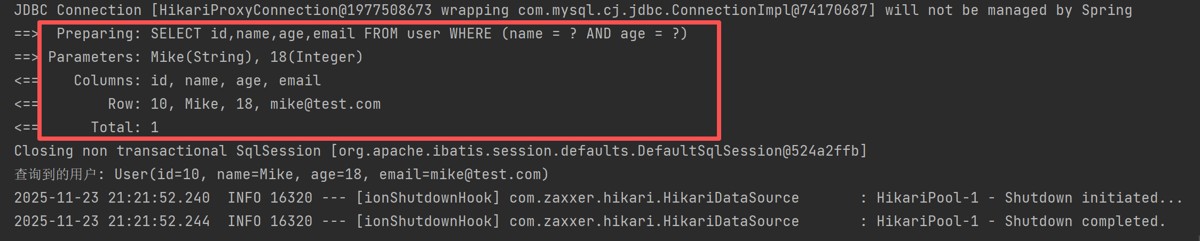
public void selectone() {
querywrapper<user> wrapper = new querywrapper<>();
wrapper.eq("name", "mike")
.eq("age", 18);
user user = usermapper.selectone(wrapper);
system.out.println("查询到的用户: " + user);
}结果:
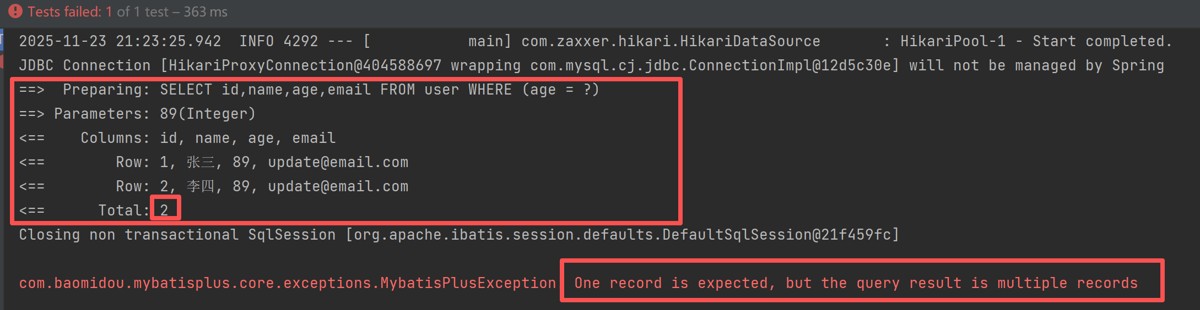
大于1的情况:
/**
* 查询单条记录
*/
@test
public void selectone() {
querywrapper<user> wrapper = new querywrapper<>();
wrapper.eq("age", 89);
user user = usermapper.selectone(wrapper);
system.out.println("查询到的用户: " + user);
}结果:
少于1的情况:
/**
* 查询单条记录
*/
@test
public void selectone() {
querywrapper<user> wrapper = new querywrapper<>();
wrapper.eq("age", 1111);
user user = usermapper.selectone(wrapper);
system.out.println("查询到的用户: " + user);
}结果:

查询符合条件的记录数
long selectcount(@param("ew") wrapper<t> querywrapper);querywrapper包装好查询条件,查询到符合条件的记录数并且返回
代码:
/**
* 查询记录数量
*/
@test
public void selectcount() {
querywrapper<user> wrapper = new querywrapper<>();
wrapper.gt("age", 20);
long count = usermapper.selectcount(wrapper);
system.out.println("年龄大于20的用户数量: " + count);
}结果:

查询所有符合条件的记录
list<t> selectlist(@param("ew") wrapper<t> querywrapper);在入门案例中,我们传入了null,也就是没有任何条件,也就是查询所有记录
这里我们传入查询条件
代码:
/**
* 查询所有符合条件的记录
*/
@test
public void testselectlist(){
querywrapper querywrapper=new querywrapper();
querywrapper.gt("age",50);
usermapper.selectlist(querywrapper).foreach(system.out::println);
}结果:
查询返回map列表
list<map<string, object>> selectmaps(@param("ew") wrapper<t> querywrapper);这个方法主要用来返回某些特定的字段,依旧是用querywrapper来构造查询条件
调用代码:
/**
* 查询返回map列表
*/
@test
public void selectmaps() {
querywrapper<user> wrapper = new querywrapper<>();
wrapper.select("id", "name", "age")
.lt("age", 30);//gt是大于,lt是小于
list<map<string, object>> maps = usermapper.selectmaps(wrapper);
system.out.println("查询结果:");
maps.foreach(system.out::println);
}这个方法当中查询了年龄小于30的用户的id,名字,年龄。
结果:
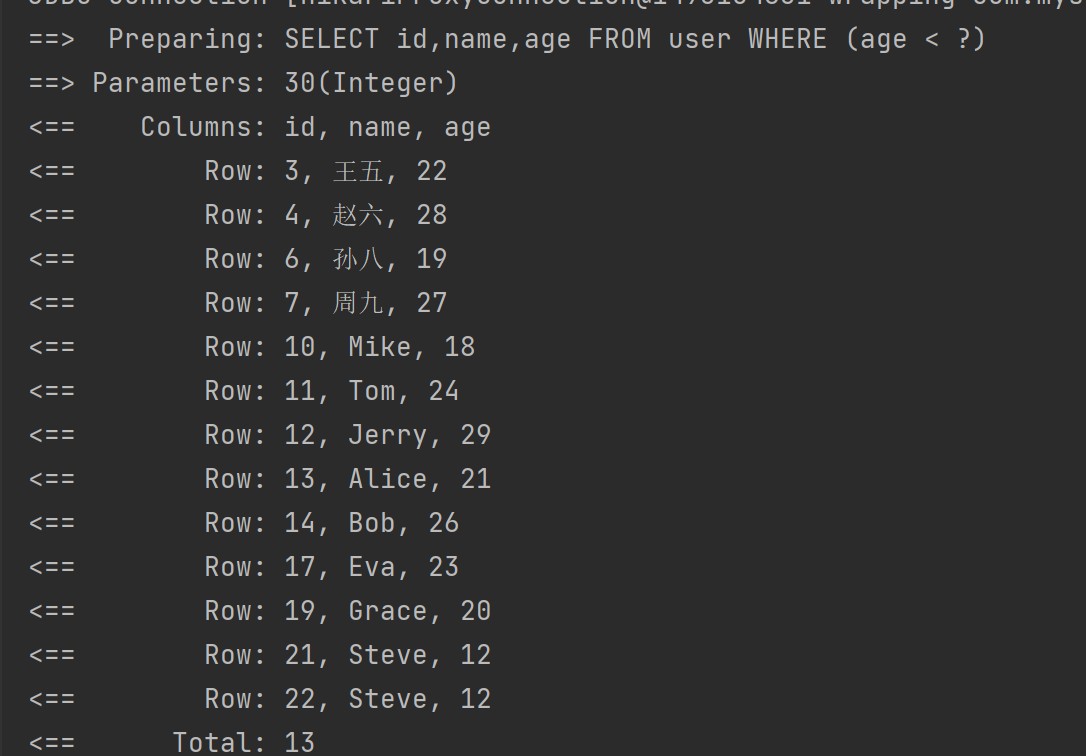
返回单个字段(一般是id)的查询
list<object> selectobjs(@param("ew") wrapper<t> querywrapper);即使我们指定了多个字段,结果也只会返回第一列
调用:
/**
* 只返回第一列的查询
*/
@test
public void selectobjs(){
querywrapper querywrapper=new querywrapper();
querywrapper.select("id","name","email")
.eq("age","12");
system.out.println("返回的数据:"+usermapper.selectobjs(querywrapper));
}结果:
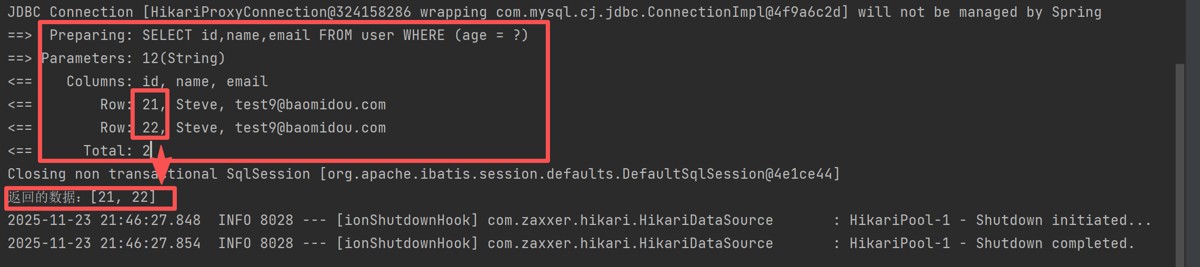
可以看到只有第一列的数据被返回,即便我们指定了name和email字段。
我们看到columns中有三个字段,那只是数据库sql执行结束的值,selectobjs只取了第一列。
分页查询
<p extends ipage<t>> p selectpage(p page, @param("ew") wrapper<t> querywrapper);泛型:<p extends ipage<t>> - 接受任何实现了 ipage<t> 接口的分页对象
ipage类:
//
// source code recreated from a .class file by intellij idea
// (powered by fernflower decompiler)
//
package com.baomidou.mybatisplus.core.metadata;
import java.io.serializable;
import java.util.list;
import java.util.function.function;
import java.util.stream.collectors;
public interface ipage<t> extends serializable {
list<orderitem> orders();
default boolean optimizecountsql() {
return true;
}
default boolean optimizejoinofcountsql() {
return true;
}
default boolean searchcount() {
return true;
}
default long offset() {
long current = this.getcurrent();
return current <= 1l ? 0l : math.max((current - 1l) * this.getsize(), 0l);
}
default long maxlimit() {
return null;
}
default long getpages() {
if (this.getsize() == 0l) {
return 0l;
} else {
long pages = this.gettotal() / this.getsize();
if (this.gettotal() % this.getsize() != 0l) {
++pages;
}
return pages;
}
}
default ipage<t> setpages(long pages) {
return this;
}
list<t> getrecords();
ipage<t> setrecords(list<t> records);
long gettotal();
ipage<t> settotal(long total);
long getsize();
ipage<t> setsize(long size);
long getcurrent();
ipage<t> setcurrent(long current);
default <r> ipage<r> convert(function<? super t, ? extends r> mapper) {
list<r> collect = (list)this.getrecords().stream().map(mapper).collect(collectors.tolist());
return this.setrecords(collect);
}
default string countid() {
return null;
}
}
参数1:p page - 分页参数对象(页码、页大小等)
参数2:@param("ew") wrapper<t> querywrapper - 查询条件
返回值:p - 包含分页数据和分页信息的结果对象
要调用这个接口,在实现它之前我们要先配置mybatisplus的分页插件:
package com.qcby.config;
import com.baomidou.mybatisplus.annotation.dbtype;
import com.baomidou.mybatisplus.extension.plugins.mybatisplusinterceptor;
import com.baomidou.mybatisplus.extension.plugins.inner.paginationinnerinterceptor;
import org.springframework.context.annotation.bean;
import org.springframework.context.annotation.configuration;
@configuration
public class mybatisplusconfig {
/**
* paginationinnerinterceptor
* 分页插件,专门处理分页查询
* 会自动在分页查询时:执行 count(*) 查询获取总记录数
* 在原 sql 上添加 limit 子句(mysql)或对应的分页语法
* 将分页结果封装到 page 对象中
*
* dbtype.mysql
* 指定数据库类型为 mysql
* mysql: limit offset(偏移量), size(页大小)
* 指定类型后插件会自动生成正确的分页 sql
*/
@bean
public mybatisplusinterceptor mybatisplusinterceptor() {
mybatisplusinterceptor interceptor = new mybatisplusinterceptor();
// 添加分页插件
interceptor.addinnerinterceptor(new paginationinnerinterceptor(dbtype.mysql));
return interceptor;
}
}调用代码:
@test
public void selectpage() {
// 1. 创建分页对象:第1页,每页10条
page<user> page = new page<>(1, 10);
// 2. 创建查询条件包装器
querywrapper<user> wrapper = new querywrapper<>();
// 3. 添加排序条件:按照age字段降序排列
wrapper.orderbydesc("age");
// 4. 执行分页查询
page<user> result = usermapper.selectpage(page, wrapper);
// 5. 输出分页信息
system.out.println("总记录数: " + result.gettotal());
system.out.println("当前页记录:");
result.getrecords().foreach(system.out::println);
}结果:

返回特定字段的分页查询
<p extends ipage<map<string, object>>> p selectmapspage(p page, @param("ew") wrapper<t> querywrapper);代码:
/**
* 分页查询返回map,相比于普通的分页查询,map可以不需要返回完整的对象,只返回部分字段
*/
@test
public void selectmapspage() {
page<map<string, object>> page = new page<>(1, 2);
querywrapper<user> wrapper = new querywrapper<>();
wrapper.select("id", "name");
page<map<string, object>> result = usermapper.selectmapspage(page, wrapper);
system.out.println("map分页结果:");
result.getrecords().foreach(system.out::println);
}结果:
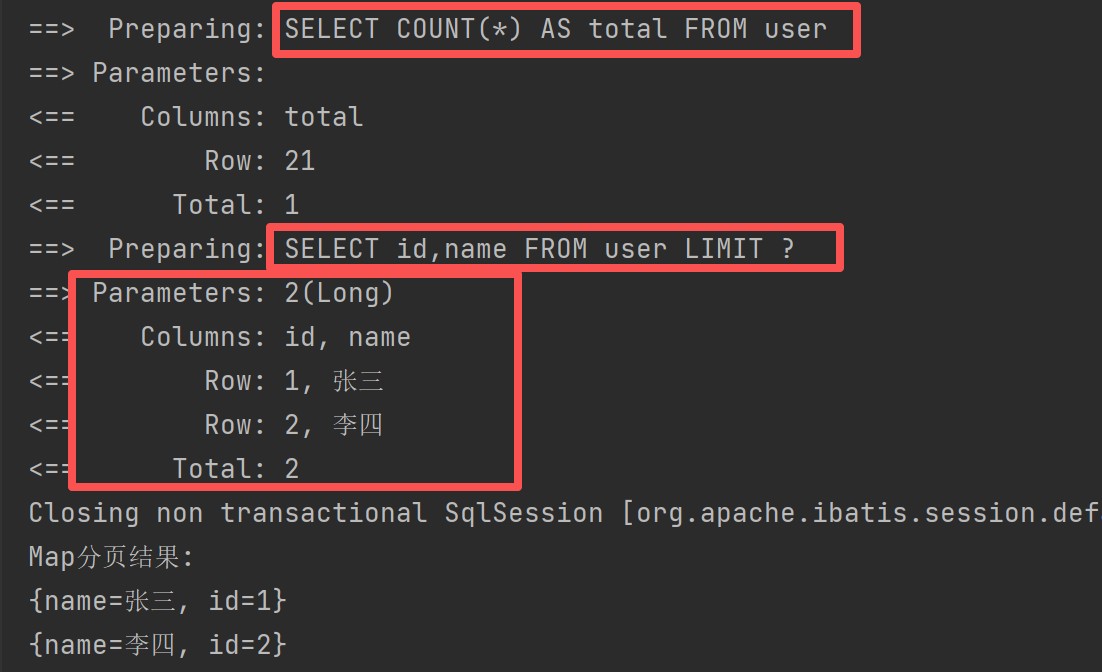
我们发现,在配置了分页插件之后,会拦截sql,并且生成两条,一条查询总记录数,一条执行分页查询。
2.增(插入)
int insert(t entity);
如果要进行批量插入也只是写循环。
调用:
/**
* 插入一条记录
*/
@test
public void insert(){
user user=new user();
user.setname("steve");
user.setage(12);
user.setemail("test9@baomidou.com");
int res=usermapper.insert(user);
system.out.println("受影响的行数:"+res);
}结果:

3.删除
根据id删除
int deletebyid(serializable id);
代码:
/**
* 根据id删除
*/
@test
public void deletebyid(){
user user=new user();
user.setid(9l);//加上l表示long类型
int res=usermapper.deletebyid(user);//也可以直接传入id值
system.out.println("受影响的行数:"+res);
}因为我的主键是long类型的所以我写了9l
结果:

传入对象删除
int deletebyid(t entity);
这个和上面的删除是类似的,只不过传入的是对象。
根据map删除
int deletebymap(@param("cm") map<string, object> columnmap);用map来构造删除条件。
调用:
/**
* 根据map删除
*/
@test
public void deletebymap(){
map<string,object> map=new hashmap<>();
map.put("name","steve");//删除名字为steve的记录
map.put("age",12);//删除年龄为12的记录
int res=usermapper.deletebymap(map);//删除名字为steve且年龄为12的记录
system.out.println("受影响的行数:"+res);
}结果:

我们发现用map构造的条件只能用and连接。
根据querywrapper删除
我们使用这种方式删除,可以构造比map更加复杂的条件。
int delete(@param("ew") wrapper<t> querywrapper);代码:
@test
public void deletewithquerywrapper(){
querywrapper<user> wrapper=new querywrapper<>();
wrapper.eq("name","steve")
.eq("age",12)
.like("email","baomidou");//删除名字为steve,12岁,邮箱名称包含baomidou的记录
// wrapper.eq("name", "steve"); // name = 'steve'
// wrapper.ne("name", "steve"); // name != 'steve'
// wrapper.gt("age", 18); // age > 18
// wrapper.ge("age", 18); // age >= 18
// wrapper.lt("age", 65); // age < 65
// wrapper.le("age", 65); // age <= 65
//模糊查询
// wrapper.like("name", "ste"); // name like '%ste%'
// wrapper.likeleft("name", "eve"); // name like '%eve'
// wrapper.likeright("name", "ste"); // name like 'ste%'
// wrapper.notlike("name", "steve"); // name not like '%steve%'
//范围查询
// wrapper.in("age", arrays.aslist(18, 19, 20)); // age in (18,19,20)
// wrapper.notin("age", arrays.aslist(60, 65, 70)); // age not in (60,65,70)
// wrapper.between("age", 18, 30); // age between 18 and 30
// wrapper.notbetween("age", 60, 100); // age not between 60 and 100
//空值判断
// wrapper.isnull("email"); // email is null
// wrapper.isnotnull("email"); // email is not null
int res=usermapper.delete(wrapper);
system.out.println("受影响的行数:"+res);
}结果:
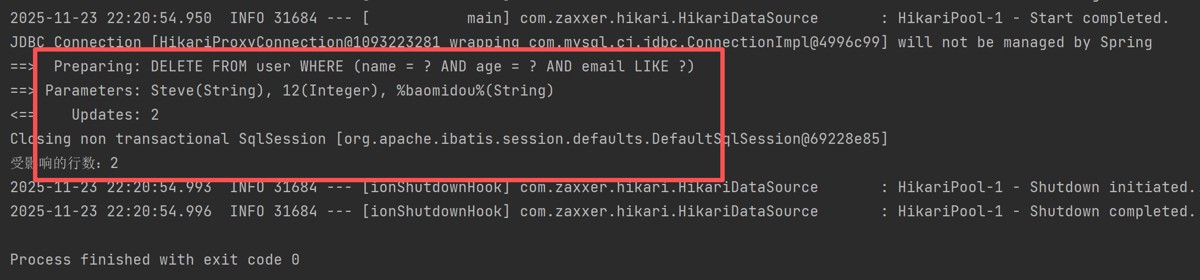
可以看到querywrapper支持非常多条件。
我们如果需要用or连接条件的话,需要用.or()来连接,例如:
wrapper.eq("name", "steve")
.or()
.eq("name", "tom"); // name='steve' or name='tom'批量删除
int deletebatchids(@param("coll") collection<? extends serializable> idlist);传入多个id删除
代码:
/**
* 删除固定的几个id,批量删除
*/
@test
public void deletebatchbyids() {
list<long> idlist = arrays.aslist(1l, 2l, 3l, 4l, 5l);
int res = usermapper.deletebatchids(idlist);
system.out.println("批量删除了 " + res + " 条记录");
}结果:我改成了20,21,23,24,25这个id序列,可以看到即使某些id不存在也不会报错

4.修改
根据id修改
int updatebyid(@param("et") t entity);代码:
/**
* 根据id修改
*/
@test
public void updatebyid(){
user user=new user();
user.setid(1l);
user.setage(99);
usermapper.updatebyid(user);
//usermapper.update(user,null);
}结果:

querywrapper修改
int update(@param("et") t entity, @param("ew") wrapper<t> updatewrapper);这个方法可以传入实体类和querywrapper混合使用,也可以只传入实体类或者只传入querywrapper。在根据id修改当中,注释的那一行就是使用的当前方法,只不过它是只传入的实体类。
只传入querywrapper:
/**
* 复杂条件wrapper修改
*/
@test
public void updatewithwrapper(){
updatewrapper<user> wrapper=new updatewrapper<>();
wrapper.set("age",89)
.set("email","update@email.com")//set设置更新字段
.eq("name","张三")//eq设置条件
.or()//or连接
.eq("name","李四");
usermapper.update(null,wrapper);
}结果:

都传入:
/**
* 两种都传入的修改
*/
@test
public void updatewithentityandwrapper(){
// 创建实体对象-设置要更新的字段值
user user = new user();
user.setname("新名字"); // 要更新的字段
user.setemail("new@email.com");
user.setage(25);
// 创建wrapper-设置更新条件
updatewrapper<user> wrapper = new updatewrapper<>();
wrapper.eq("age", 89); // 条件:年龄为89的用户
system.out.println("受影响行数:" + usermapper.update(user, wrapper));
}结果:

到此这篇关于mybatis-plus当中basemapper接口的增删查改操作的文章就介绍到这了,更多相关mybatis-plus增删查改内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论