在开发web应用时,常遇到这样的需求:每天凌晨3点自动备份数据库、每10分钟抓取一次api数据、每周一9点发送周报邮件。这些看似简单的定时任务,若用time.sleep()循环实现,会面临进程崩溃后任务中断、修改时间需重启程序、多任务互相阻塞等问题。而apscheduler(advanced python scheduler)的出现,彻底解决了这些痛点。
一、apscheduler核心组件解析
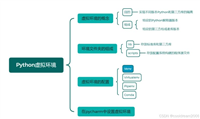
apscheduler的设计理念类似于乐高积木,通过组合四大核心组件实现灵活调度:
1. 触发器(triggers):决定任务何时执行
- datetrigger:指定具体时间点执行,如
run_date="2025-10-10 08:00:00" - intervaltrigger:固定间隔执行,如
minutes=5表示每5分钟一次 - crontrigger:类linux crontab表达式,如
hour=8, minute=30表示每天8:30执行
from apscheduler.triggers.cron import crontrigger # 每月1号凌晨2点执行 trigger = crontrigger(day=1, hour=2)
2. 执行器(executors):决定任务如何执行
- threadpoolexecutor(默认):适合io密集型任务(如http请求、数据库操作)
- processpoolexecutor:适合cpu密集型任务(如视频转码、大数据计算)
- asyncioexecutor:配合asyncio实现异步任务
from apscheduler.executors.pool import processpoolexecutor
executors = {
'default': threadpoolexecutor(20), # 线程池最大20线程
'processpool': processpoolexecutor(5) # 进程池最大5进程
}
3. 任务存储器(jobstores):保存任务状态
- 内存存储(默认):程序重启后任务丢失
- sqlalchemy存储:支持mysql/postgresql/sqlite
- mongodb存储:适合非结构化数据
- redis存储:实现分布式任务调度
from apscheduler.jobstores.sqlalchemy import sqlalchemyjobstore
jobstores = {
'default': sqlalchemyjobstore(url='sqlite:///jobs.db')
}
4. 调度器(schedulers):整合所有组件
- blockingscheduler:阻塞主线程,适合独立脚本
- backgroundscheduler:后台运行,适合web应用
- asyncioscheduler:配合asyncio使用
- geventscheduler:协程环境使用
from apscheduler.schedulers.background import backgroundscheduler
scheduler = backgroundscheduler(
jobstores=jobstores,
executors=executors,
timezone='asia/shanghai'
)
二、基础场景实战:从简单到复杂
场景1:每5秒打印一次时间(intervaltrigger)
from apscheduler.schedulers.blocking import blockingscheduler
import time
def print_time():
print(f"当前时间: {time.strftime('%y-%m-%d %h:%m:%s')}")
scheduler = blockingscheduler()
scheduler.add_job(print_time, 'interval', seconds=5)
scheduler.start()
运行效果:
当前时间: 2025-10-09 14:00:00
当前时间: 2025-10-09 14:00:05
当前时间: 2025-10-09 14:00:10
...
场景2:指定时间发送邮件(datetrigger)
from apscheduler.schedulers.blocking import blockingscheduler
import smtplib
from email.mime.text import mimetext
from datetime import datetime
def send_email():
msg = mimetext("这是定时发送的测试邮件", 'plain', 'utf-8')
msg['from'] = "your_email@qq.com"
msg['to'] = "recipient@example.com"
msg['subject'] = "apscheduler测试邮件"
with smtplib.smtp_ssl("smtp.qq.com", 465) as server:
server.login("your_email@qq.com", "your_auth_code")
server.sendmail("your_email@qq.com", ["recipient@example.com"], msg.as_string())
print("邮件发送成功")
scheduler = blockingscheduler()
# 设置2025年10月10日15点执行
scheduler.add_job(send_email, 'date', run_date=datetime(2025, 10, 10, 15, 0))
scheduler.start()
关键点:
- qq邮箱需在设置中开启smtp服务并获取授权码
run_date支持datetime对象或字符串格式
场景3:每天8:30抓取天气数据(crontrigger)
from apscheduler.schedulers.background import backgroundscheduler
import requests
def fetch_weather():
try:
response = requests.get("https://api.example.com/weather")
print(f"天气数据: {response.json()}")
except exception as e:
print(f"抓取失败: {str(e)}")
scheduler = backgroundscheduler()
# 每天8:30执行
scheduler.add_job(fetch_weather, 'cron', hour=8, minute=30)
scheduler.start()
# 保持程序运行(web应用中通常不需要)
import time
while true:
time.sleep(1)
cron表达式详解:
| 字段 | 允许值 | 特殊字符 |
|---|---|---|
| 年 | 1970-2099 | , - * / |
| 月 | 1-12 | , - * / |
| 日 | 1-31 | , - * ? / l w |
| 周 | 0-6 (0是周日) | , - * ? / l # |
| 时 | 0-23 | , - * / |
| 分 | 0-59 | , - * / |
| 秒 | 0-59 | , - * / |
三、进阶技巧:打造企业级定时任务
1. 任务持久化(避免程序重启任务丢失)
from apscheduler.jobstores.sqlalchemy import sqlalchemyjobstore
jobstores = {
'default': sqlalchemyjobstore(url='mysql://user:pass@localhost/apscheduler')
}
scheduler = backgroundscheduler(jobstores=jobstores)
# 即使程序重启,任务也会从数据库恢复
2. 动态管理任务(运行时增删改查)
# 添加任务
def dynamic_task():
print("动态添加的任务执行了")
job = scheduler.add_job(dynamic_task, 'interval', minutes=1, id='dynamic_job')
# 暂停任务
scheduler.pause_job('dynamic_job')
# 恢复任务
scheduler.resume_job('dynamic_job')
# 删除任务
scheduler.remove_job('dynamic_job')
# 获取所有任务
all_jobs = scheduler.get_jobs()
for job in all_jobs:
print(f"任务id: {job.id}, 下次执行时间: {job.next_run_time}")
3. 异常处理与日志记录
import logging
logging.basicconfig(
filename='scheduler.log',
level=logging.info,
format='%(asctime)s - %(levelname)s - %(message)s'
)
def safe_task():
try:
# 可能出错的代码
1 / 0
except exception as e:
logging.error(f"任务执行失败: {str(e)}")
raise # 重新抛出异常让apscheduler记录
scheduler.add_job(safe_task, 'interval', seconds=5)
4. 分布式任务调度(多实例协同)
# 使用redis作为任务存储和锁机制
from apscheduler.jobstores.redis import redisjobstore
from apscheduler.jobstores.base import conflictingiderror
jobstores = {
'default': redisjobstore(host='localhost', port=6379, db=0)
}
# 配合分布式锁使用(需额外实现)
def distributed_task():
try:
# 获取锁
if acquire_lock("task_lock"):
# 执行任务
print("执行分布式任务")
# 释放锁
release_lock("task_lock")
except conflictingiderror:
print("其他实例正在执行该任务")
四、常见问题解决方案
1. 时区问题导致任务未按时执行
# 明确设置时区
from pytz import timezone
scheduler = backgroundscheduler(timezone=timezone('asia/shanghai'))
# 或者在crontrigger中指定
scheduler.add_job(
my_job,
'cron',
hour=8,
minute=30,
timezone='asia/shanghai'
)
2. 任务堆积导致内存溢出
# 限制同一任务的并发实例数
scheduler.add_job(
my_job,
'interval',
minutes=1,
max_instances=3 # 最多同时运行3个实例
)
# 对于耗时任务,考虑使用进程池
executors = {
'default': processpoolexecutor(5) # 最多5个进程
}
3. web应用中集成apscheduler
flask示例:
from flask import flask
from apscheduler.schedulers.background import backgroundscheduler
app = flask(__name__)
scheduler = backgroundscheduler()
def cron_job():
print("flask应用中的定时任务执行了")
@app.route('/')
def index():
return "apscheduler与flask集成成功"
if __name__ == '__main__':
scheduler.add_job(cron_job, 'cron', minute='*/1') # 每分钟执行
scheduler.start()
app.run()
django示例:
# 在apps.py中初始化
from django.apps import appconfig
from apscheduler.schedulers.background import backgroundscheduler
class myappconfig(appconfig):
name = 'myapp'
def ready(self):
scheduler = backgroundscheduler()
scheduler.add_job(my_django_task, 'interval', hours=1)
scheduler.start()
五、性能优化建议
1.合理选择执行器:
- io密集型任务:线程池(默认10线程)
- cpu密集型任务:进程池(通常4-8进程)
- 异步任务:asyncioexecutor
2.任务拆分策略:
- 将大任务拆分为多个小任务
- 避免单个任务执行时间超过间隔时间
3.监控与告警:
def job_monitor(event):
if event.exception:
send_alert(f"任务{event.job_id}失败: {str(event.exception)}")
scheduler.add_listener(job_monitor, apscheduler.events.event_job_error)
4.资源限制:
# 限制线程池大小
executors = {
'default': threadpoolexecutor(20) # 最多20个线程
}
六、替代方案对比
| 方案 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| apscheduler | 复杂定时任务,需要持久化 | 功能全面,支持多种触发器 | 需要手动管理 |
| celery beat | 分布式任务队列 | 与celery无缝集成 | 依赖消息队列,配置复杂 |
| schedule | 简单定时任务 | 纯python实现,无需依赖 | 功能有限,不支持持久化 |
| airflow | 工作流管理 | 强大的dag支持 | 重量级,适合大数据场景 |
七、最佳实践总结
生产环境必备配置:
- 启用任务持久化(数据库存储)
- 设置合理的
max_instances - 添加全面的异常处理
- 记录详细的执行日志
开发阶段建议:
- 使用blockingscheduler快速验证
- 通过
print_jobs()方法调试任务 - 先在测试环境验证cron表达式
典型应用场景:
- 数据库备份(每天凌晨执行)
- 数据同步(每5分钟一次)
- 报表生成(每周一9点)
- 缓存清理(每小时执行)
- 通知发送(生日提醒等)
apscheduler就像一个智能的闹钟系统,它不仅能准时提醒,还能根据复杂规则灵活调整。通过合理配置四大组件,你可以轻松实现从简单的每分钟执行到复杂的每月第一个周一这样的定时任务需求。在实际项目中,建议从内存存储+线程池的简单配置开始,随着需求增长逐步引入数据库持久化和进程池执行器,最终打造出稳定可靠的企业级定时任务系统。
到此这篇关于从入门到精通详解python apscheduler实现定时任务的完整指南的文章就介绍到这了,更多相关python apscheduler定时任务内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论