1. 数据统计基础与环境配置
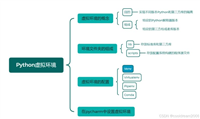
1.1 python数据科学生态系统
python在数据统计领域的强大主要得益于其丰富的库生态系统:
# 核心数据分析库
import pandas as pd
import numpy as np
# 数据可视化库
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as px
# 统计分析库
import scipy.stats as stats
from scipy import stats
import statsmodels.api as sm
from statsmodels.formula.api import ols
# 机器学习库
from sklearn.preprocessing import standardscaler
from sklearn.linear_model import linearregression
# 其他实用库
import warnings
warnings.filterwarnings('ignore')
1.2 环境配置与安装
# 推荐使用conda或pip安装必要包
"""
pip install pandas numpy matplotlib seaborn plotly
pip install scipy statsmodels scikit-learn
pip install jupyter notebook # 交互式环境
"""
# 设置中文字体显示
plt.rcparams['font.sans-serif'] = ['simhei'] # 用来正常显示中文标签
plt.rcparams['axes.unicode_minus'] = false # 用来正常显示负号
# 设置绘图样式
plt.style.use('seaborn-v0_8')
sns.set_palette("husl")
2. 数据获取与加载
2.1 从不同数据源加载数据
import pandas as pd
import numpy as np
import sqlite3
import requests
import json
class dataloader:
def __init__(self):
self.data_sources = {}
def load_csv(self, file_path, **kwargs):
"""加载csv文件"""
try:
df = pd.read_csv(file_path, **kwargs)
self.data_sources['csv'] = df
print(f"成功加载csv文件,数据形状: {df.shape}")
return df
except exception as e:
print(f"加载csv文件失败: {e}")
return none
def load_excel(self, file_path, sheet_name=0):
"""加载excel文件"""
try:
df = pd.read_excel(file_path, sheet_name=sheet_name)
self.data_sources['excel'] = df
print(f"成功加载excel文件,数据形状: {df.shape}")
return df
except exception as e:
print(f"加载excel文件失败: {e}")
return none
def load_sql(self, query, db_path):
"""从sql数据库加载数据"""
try:
conn = sqlite3.connect(db_path)
df = pd.read_sql_query(query, conn)
conn.close()
self.data_sources['sql'] = df
print(f"成功从sql加载数据,数据形状: {df.shape}")
return df
except exception as e:
print(f"从sql加载数据失败: {e}")
return none
def load_api(self, url, params=none):
"""从api接口加载数据"""
try:
response = requests.get(url, params=params)
if response.status_code == 200:
data = response.json()
df = pd.dataframe(data)
self.data_sources['api'] = df
print(f"成功从api加载数据,数据形状: {df.shape}")
return df
else:
print(f"api请求失败,状态码: {response.status_code}")
return none
except exception as e:
print(f"从api加载数据失败: {e}")
return none
# 使用示例
loader = dataloader()
# 加载示例数据集
from sklearn.datasets import load_iris, load_boston
iris = load_iris()
iris_df = pd.dataframe(iris.data, columns=iris.feature_names)
iris_df['target'] = iris.target
2.2 数据基本信息查看
def explore_data(df, sample_size=5):
"""
全面探索数据集基本信息
"""
print("=" * 50)
print("数据集基本信息探索")
print("=" * 50)
# 基本形状信息
print(f"数据形状: {df.shape}")
print(f"行数: {df.shape[0]}")
print(f"列数: {df.shape[1]}")
# 数据类型信息
print("\n数据类型信息:")
print(df.dtypes)
# 数据预览
print(f"\n前{sample_size}行数据:")
print(df.head(sample_size))
print(f"\n后{sample_size}行数据:")
print(df.tail(sample_size))
# 统计摘要
print("\n数值列统计摘要:")
print(df.describe())
# 缺失值信息
print("\n缺失值统计:")
missing_info = pd.dataframe({
'缺失数量': df.isnull().sum(),
'缺失比例': df.isnull().sum() / len(df) * 100
})
print(missing_info)
# 唯一值信息
print("\n分类变量唯一值统计:")
categorical_cols = df.select_dtypes(include=['object']).columns
for col in categorical_cols:
print(f"{col}: {df[col].nunique()} 个唯一值")
return {
'shape': df.shape,
'dtypes': df.dtypes,
'missing_info': missing_info
}
# 在iris数据集上应用
info = explore_data(iris_df)
3. 数据清洗与预处理
3.1 缺失值处理
class datacleaner:
def __init__(self, df):
self.df = df.copy()
self.cleaning_log = []
def detect_missing_values(self):
"""检测缺失值"""
missing_stats = pd.dataframe({
'missing_count': self.df.isnull().sum(),
'missing_percentage': (self.df.isnull().sum() / len(self.df)) * 100,
'data_type': self.df.dtypes
})
# 高缺失率列
high_missing_cols = missing_stats[missing_stats['missing_percentage'] > 50].index.tolist()
self.cleaning_log.append({
'step': '缺失值检测',
'details': f"发现 {len(high_missing_cols)} 个高缺失率列(>50%)"
})
return missing_stats, high_missing_cols
def handle_missing_values(self, strategy='auto', custom_strategy=none):
"""处理缺失值"""
df_clean = self.df.copy()
missing_stats, high_missing_cols = self.detect_missing_values()
# 删除高缺失率列
if high_missing_cols:
df_clean = df_clean.drop(columns=high_missing_cols)
self.cleaning_log.append({
'step': '删除高缺失率列',
'details': f"删除列: {high_missing_cols}"
})
# 处理剩余缺失值
for col in df_clean.columns:
if df_clean[col].isnull().sum() > 0:
if strategy == 'auto':
# 自动选择策略
if df_clean[col].dtype in ['float64', 'int64']:
# 数值列用中位数填充
fill_value = df_clean[col].median()
df_clean[col].fillna(fill_value, inplace=true)
method = f"中位数填充 ({fill_value})"
else:
# 分类列用众数填充
fill_value = df_clean[col].mode()[0] if not df_clean[col].mode().empty else 'unknown'
df_clean[col].fillna(fill_value, inplace=true)
method = f"众数填充 ({fill_value})"
elif strategy == 'custom' and custom_strategy:
# 自定义策略
if col in custom_strategy:
fill_value = custom_strategy[col]
df_clean[col].fillna(fill_value, inplace=true)
method = f"自定义填充 ({fill_value})"
self.cleaning_log.append({
'step': '缺失值填充',
'column': col,
'method': method,
'filled_count': self.df[col].isnull().sum()
})
self.df = df_clean
return df_clean
def remove_duplicates(self):
"""删除重复行"""
initial_count = len(self.df)
self.df = self.df.drop_duplicates()
removed_count = initial_count - len(self.df)
self.cleaning_log.append({
'step': '删除重复行',
'removed_count': removed_count,
'remaining_count': len(self.df)
})
return self.df
def handle_outliers(self, method='iqr', threshold=3):
"""处理异常值"""
df_clean = self.df.copy()
numeric_cols = df_clean.select_dtypes(include=[np.number]).columns
outliers_info = {}
for col in numeric_cols:
if method == 'iqr':
# iqr方法
q1 = df_clean[col].quantile(0.25)
q3 = df_clean[col].quantile(0.75)
iqr = q3 - q1
lower_bound = q1 - 1.5 * iqr
upper_bound = q3 + 1.5 * iqr
outliers = df_clean[(df_clean[col] < lower_bound) | (df_clean[col] > upper_bound)]
outlier_count = len(outliers)
# 缩尾处理
df_clean[col] = np.where(df_clean[col] < lower_bound, lower_bound, df_clean[col])
df_clean[col] = np.where(df_clean[col] > upper_bound, upper_bound, df_clean[col])
elif method == 'zscore':
# z-score方法
z_scores = np.abs(stats.zscore(df_clean[col]))
outlier_count = len(df_clean[z_scores > threshold])
# 使用中位数和标准差进行稳健的异常值处理
median = df_clean[col].median()
mad = stats.median_abs_deviation(df_clean[col])
df_clean[col] = np.where(z_scores > threshold, median, df_clean[col])
outliers_info[col] = outlier_count
self.cleaning_log.append({
'step': '异常值处理',
'method': method,
'outliers_info': outliers_info
})
self.df = df_clean
return df_clean
def get_cleaning_report(self):
"""生成清洗报告"""
print("数据清洗报告")
print("=" * 30)
for log in self.cleaning_log:
print(f"{log['step']}:")
for key, value in log.items():
if key != 'step':
print(f" {key}: {value}")
print()
# 使用示例
# 创建有缺失值和异常值的测试数据
np.random.seed(42)
test_data = pd.dataframe({
'a': np.random.normal(0, 1, 100),
'b': np.random.normal(10, 2, 100),
'c': np.random.choice(['x', 'y', 'z'], 100),
'd': np.random.exponential(2, 100)
})
# 人为添加缺失值和异常值
test_data.loc[10:15, 'a'] = np.nan
test_data.loc[20:25, 'b'] = np.nan
test_data.loc[5, 'a'] = 100 # 异常值
test_data.loc[6, 'b'] = 100 # 异常值
cleaner = datacleaner(test_data)
cleaned_data = cleaner.handle_missing_values()
cleaned_data = cleaner.remove_duplicates()
cleaned_data = cleaner.handle_outliers()
cleaner.get_cleaning_report()
3.2 数据转换与编码
class datatransformer:
def __init__(self, df):
self.df = df.copy()
self.transformation_log = []
def encode_categorical(self, columns=none, method='onehot'):
"""分类变量编码"""
df_encoded = self.df.copy()
if columns is none:
categorical_cols = df_encoded.select_dtypes(include=['object']).columns
else:
categorical_cols = columns
for col in categorical_cols:
if method == 'onehot':
# one-hot编码
dummies = pd.get_dummies(df_encoded[col], prefix=col)
df_encoded = pd.concat([df_encoded, dummies], axis=1)
df_encoded.drop(col, axis=1, inplace=true)
encoding_type = "one-hot编码"
elif method == 'label':
# 标签编码
from sklearn.preprocessing import labelencoder
le = labelencoder()
df_encoded[col] = le.fit_transform(df_encoded[col])
encoding_type = "标签编码"
elif method == 'target':
# 目标编码(需要目标变量)
if 'target' in df_encoded.columns:
target_mean = df_encoded.groupby(col)['target'].mean()
df_encoded[col] = df_encoded[col].map(target_mean)
encoding_type = "目标编码"
self.transformation_log.append({
'step': '分类变量编码',
'column': col,
'method': encoding_type
})
self.df = df_encoded
return df_encoded
def scale_numerical(self, columns=none, method='standard'):
"""数值变量标准化"""
from sklearn.preprocessing import standardscaler, minmaxscaler, robustscaler
df_scaled = self.df.copy()
if columns is none:
numerical_cols = df_scaled.select_dtypes(include=[np.number]).columns
else:
numerical_cols = columns
scaler = none
if method == 'standard':
scaler = standardscaler()
scaling_type = "标准化(z-score)"
elif method == 'minmax':
scaler = minmaxscaler()
scaling_type = "最小最大缩放"
elif method == 'robust':
scaler = robustscaler()
scaling_type = "稳健缩放"
if scaler:
df_scaled[numerical_cols] = scaler.fit_transform(df_scaled[numerical_cols])
self.transformation_log.append({
'step': '数值变量缩放',
'columns': list(numerical_cols),
'method': scaling_type
})
self.df = df_scaled
return df_scaled, scaler
def create_features(self):
"""特征工程"""
df_featured = self.df.copy()
numerical_cols = df_featured.select_dtypes(include=[np.number]).columns
# 创建多项式特征
from sklearn.preprocessing import polynomialfeatures
if len(numerical_cols) >= 2:
poly = polynomialfeatures(degree=2, include_bias=false, interaction_only=true)
poly_features = poly.fit_transform(df_featured[numerical_cols[:2]]) # 取前两个数值列
poly_feature_names = poly.get_feature_names_out(numerical_cols[:2])
poly_df = pd.dataframe(poly_features, columns=poly_feature_names)
df_featured = pd.concat([df_featured, poly_df], axis=1)
self.transformation_log.append({
'step': '特征工程',
'type': '多项式特征',
'features_created': list(poly_feature_names)
})
# 创建统计特征
for col in numerical_cols:
df_featured[f'{col}_zscore'] = stats.zscore(df_featured[col])
df_featured[f'{col}_rank'] = df_featured[col].rank()
self.transformation_log.append({
'step': '特征工程',
'type': '统计特征',
'features_created': [f'{col}_zscore' for col in numerical_cols] +
[f'{col}_rank' for col in numerical_cols]
})
self.df = df_featured
return df_featured
# 使用示例
transformer = datatransformer(iris_df)
transformed_data, scaler = transformer.scale_numerical(method='standard')
transformer.create_features()
4. 描述性统计分析
4.1 基本统计量计算
class descriptivestatistics:
def __init__(self, df):
self.df = df
self.numerical_cols = df.select_dtypes(include=[np.number]).columns
self.categorical_cols = df.select_dtypes(include=['object']).columns
def basic_stats(self):
"""计算基本统计量"""
stats_summary = {}
for col in self.numerical_cols:
data = self.df[col].dropna()
stats_summary[col] = {
'count': len(data),
'mean': np.mean(data),
'median': np.median(data),
'std': np.std(data),
'variance': np.var(data),
'min': np.min(data),
'max': np.max(data),
'range': np.max(data) - np.min(data),
'q1': np.percentile(data, 25),
'q3': np.percentile(data, 75),
'iqr': np.percentile(data, 75) - np.percentile(data, 25),
'skewness': stats.skew(data),
'kurtosis': stats.kurtosis(data),
'cv': (np.std(data) / np.mean(data)) * 100 if np.mean(data) != 0 else np.inf
}
return pd.dataframe(stats_summary).t
def categorical_stats(self):
"""分类变量统计"""
cat_stats = {}
for col in self.categorical_cols:
data = self.df[col].dropna()
value_counts = data.value_counts()
cat_stats[col] = {
'count': len(data),
'unique_count': len(value_counts),
'mode': value_counts.index[0] if len(value_counts) > 0 else none,
'mode_frequency': value_counts.iloc[0] if len(value_counts) > 0 else 0,
'mode_percentage': (value_counts.iloc[0] / len(data)) * 100 if len(value_counts) > 0 else 0,
'entropy': stats.entropy(value_counts) # 信息熵
}
return pd.dataframe(cat_stats).t
def distribution_test(self):
"""分布检验"""
distribution_results = {}
for col in self.numerical_cols:
data = self.df[col].dropna()
# 正态性检验
shapiro_stat, shapiro_p = stats.shapiro(data) if len(data) < 5000 else (np.nan, np.nan)
normaltest_stat, normaltest_p = stats.normaltest(data)
distribution_results[col] = {
'shapiro_stat': shapiro_stat,
'shapiro_p': shapiro_p,
'normaltest_stat': normaltest_stat,
'normaltest_p': normaltest_p,
'is_normal_shapiro': shapiro_p > 0.05 if not np.isnan(shapiro_p) else none,
'is_normal_normaltest': normaltest_p > 0.05
}
return pd.dataframe(distribution_results).t
def correlation_analysis(self):
"""相关性分析"""
corr_matrix = self.df[self.numerical_cols].corr()
# 三种相关系数
pearson_corr = self.df[self.numerical_cols].corr(method='pearson')
spearman_corr = self.df[self.numerical_cols].corr(method='spearman')
kendall_corr = self.df[self.numerical_cols].corr(method='kendall')
return {
'pearson': pearson_corr,
'spearman': spearman_corr,
'kendall': kendall_corr
}
def generate_report(self):
"""生成完整的描述性统计报告"""
print("描述性统计分析报告")
print("=" * 50)
# 基本统计量
print("\n1. 数值变量基本统计量:")
basic_stats_df = self.basic_stats()
print(basic_stats_df.round(4))
# 分类变量统计
if len(self.categorical_cols) > 0:
print("\n2. 分类变量统计:")
cat_stats_df = self.categorical_stats()
print(cat_stats_df.round(4))
# 分布检验
print("\n3. 分布检验结果:")
dist_test_df = self.distribution_test()
print(dist_test_df.round(4))
# 相关性分析
print("\n4. pearson相关系数矩阵:")
corr_results = self.correlation_analysis()
print(corr_results['pearson'].round(4))
return {
'basic_stats': basic_stats_df,
'categorical_stats': cat_stats_df if len(self.categorical_cols) > 0 else none,
'distribution_test': dist_test_df,
'correlation': corr_results
}
# 使用示例
desc_stats = descriptivestatistics(iris_df)
report = desc_stats.generate_report()
4.2 高级统计分析
class advancedstatistics:
def __init__(self, df):
self.df = df
self.numerical_cols = df.select_dtypes(include=[np.number]).columns
def outlier_detection(self, method='multiple'):
"""异常值检测"""
outlier_results = {}
for col in self.numerical_cols:
data = self.df[col].dropna()
outliers = {}
# iqr方法
q1 = np.percentile(data, 25)
q3 = np.percentile(data, 75)
iqr = q3 - q1
lower_bound = q1 - 1.5 * iqr
upper_bound = q3 + 1.5 * iqr
iqr_outliers = data[(data < lower_bound) | (data > upper_bound)]
outliers['iqr'] = {
'count': len(iqr_outliers),
'percentage': (len(iqr_outliers) / len(data)) * 100,
'values': iqr_outliers.tolist()
}
# z-score方法
z_scores = np.abs(stats.zscore(data))
zscore_outliers = data[z_scores > 3]
outliers['zscore'] = {
'count': len(zscore_outliers),
'percentage': (len(zscore_outliers) / len(data)) * 100,
'values': zscore_outliers.tolist()
}
# 修正z-score方法(对异常值更稳健)
median = np.median(data)
mad = stats.median_abs_deviation(data)
modified_z_scores = 0.6745 * (data - median) / mad
mod_z_outliers = data[np.abs(modified_z_scores) > 3.5]
outliers['modified_zscore'] = {
'count': len(mod_z_outliers),
'percentage': (len(mod_z_outliers) / len(data)) * 100,
'values': mod_z_outliers.tolist()
}
outlier_results[col] = outliers
return outlier_results
def normality_tests(self):
"""正态性检验综合"""
normality_results = {}
for col in self.numerical_cols:
data = self.df[col].dropna()
tests = {}
# shapiro-wilk检验(适合小样本)
if len(data) < 5000:
shapiro_stat, shapiro_p = stats.shapiro(data)
tests['shapiro_wilk'] = {
'statistic': shapiro_stat,
'p_value': shapiro_p,
'is_normal': shapiro_p > 0.05
}
# d'agostino's k^2检验
k2_stat, k2_p = stats.normaltest(data)
tests['dagostino'] = {
'statistic': k2_stat,
'p_value': k2_p,
'is_normal': k2_p > 0.05
}
# anderson-darling检验
anderson_result = stats.anderson(data, dist='norm')
tests['anderson_darling'] = {
'statistic': anderson_result.statistic,
'critical_values': anderson_result.critical_values,
'significance_level': anderson_result.significance_level,
'is_normal': anderson_result.statistic < anderson_result.critical_values[2] # 5%显著性水平
}
# kolmogorov-smirnov检验
ks_stat, ks_p = stats.kstest(data, 'norm', args=(np.mean(data), np.std(data)))
tests['kolmogorov_smirnov'] = {
'statistic': ks_stat,
'p_value': ks_p,
'is_normal': ks_p > 0.05
}
normality_results[col] = tests
return normality_results
def confidence_intervals(self, confidence=0.95):
"""置信区间计算"""
ci_results = {}
for col in self.numerical_cols:
data = self.df[col].dropna()
n = len(data)
mean = np.mean(data)
std_err = stats.sem(data)
# t分布的置信区间
ci = stats.t.interval(confidence, n-1, loc=mean, scale=std_err)
# 使用bootstrap计算置信区间
bootstrap_ci = self._bootstrap_ci(data, confidence=confidence)
ci_results[col] = {
'sample_size': n,
'mean': mean,
'std_error': std_err,
f'ci_{confidence}': ci,
'bootstrap_ci': bootstrap_ci,
'ci_width': ci[1] - ci[0]
}
return ci_results
def _bootstrap_ci(self, data, n_bootstrap=1000, confidence=0.95):
"""bootstrap置信区间"""
bootstrap_means = []
for _ in range(n_bootstrap):
bootstrap_sample = np.random.choice(data, size=len(data), replace=true)
bootstrap_means.append(np.mean(bootstrap_sample))
alpha = (1 - confidence) / 2
lower = np.percentile(bootstrap_means, alpha * 100)
upper = np.percentile(bootstrap_means, (1 - alpha) * 100)
return (lower, upper)
def generate_advanced_report(self):
"""生成高级统计报告"""
print("高级统计分析报告")
print("=" * 50)
# 异常值检测
print("\n1. 异常值检测结果:")
outlier_results = self.outlier_detection()
for col, methods in outlier_results.items():
print(f"\n{col}:")
for method, result in methods.items():
print(f" {method}: {result['count']} 个异常值 ({result['percentage']:.2f}%)")
# 正态性检验
print("\n2. 正态性检验综合结果:")
normality_results = self.normality_tests()
for col, tests in normality_results.items():
print(f"\n{col}:")
for test_name, result in tests.items():
is_normal = result.get('is_normal', false)
status = "正态" if is_normal else "非正态"
print(f" {test_name}: p={result.get('p_value', 0):.4f} ({status})")
# 置信区间
print("\n3. 置信区间分析:")
ci_results = self.confidence_intervals()
for col, result in ci_results.items():
print(f"\n{col}:")
print(f" 均值: {result['mean']:.4f}")
print(f" 95%置信区间: [{result['ci_0.95'][0]:.4f}, {result['ci_0.95'][1]:.4f}]")
print(f" bootstrap ci: [{result['bootstrap_ci'][0]:.4f}, {result['bootstrap_ci'][1]:.4f}]")
return {
'outliers': outlier_results,
'normality': normality_results,
'confidence_intervals': ci_results
}
# 使用示例
advanced_stats = advancedstatistics(iris_df)
advanced_report = advanced_stats.generate_advanced_report()
以上就是从入门到实战详解python数据统计的完全指南的详细内容,更多关于python数据统计的资料请关注代码网其它相关文章!




发表评论