引言
在数据处理、文档数字化及图像内容分析等开发场景中,光学字符识别(ocr)技术常被用于将图像中的文字转化为可编辑、可搜索的文本格式。spire.ocr for python 作为 python 生态中的一款 ocr 类库,可实现图片文本提取及文字位置定位,适用于发票信息处理、表单数据解析、截图内容提取等场景,以下从技术特性、实现步骤及应用方向展开介绍。
一、核心技术特性
spire.ocr for python 支持 jpg、png、bmp、tiff 四种主流图像格式,在功能设计上具备以下技术特点:
- 文本坐标提取能力:可直接获取文字的 x/y 轴位置、宽度与高度,为后续图像标注、文本区域定位提供数据支持。
- 低依赖部署:无需额外配置环境或安装底层库,安装后即可直接调用,降低入门门槛。
- 多语言识别支持:涵盖英语、中文、日语、韩语、德语、法语等常用语言,可根据识别场景切换目标语言。
二、ocr文字识别功能实现流程
步骤 1:环境准备与安装
打开电脑的命令提示符(windows)或终端(macos/linux),输入以下 pip 命令,一键完成安装:
pip install spire.ocr
模型要求:点击下载对应的 ocr 模型文件(windows系统、linux系统、 macos系统 )。解压后保存至本地路径,后续配置时需引用该路径。
步骤 2:模块导入
在 python 脚本中导入类库核心模块,用于初始化 ocr 扫描实例及配置参数:
from spire.ocr import * # 导入ocr核心功能模块
步骤 3:配置 ocr 依赖项
创建 ocr 扫描对象并设置关键参数,包括模型文件路径与识别语言,参数配置错误会导致识别功能无法正常运行:
# 初始化ocr扫描实例 scanner = ocrscanner() # 配置引擎参数 configureoptions = configureoptions() # 模型文件本地路径(需根据实际保存位置修改) configureoptions.modelpath = "f:\\ocr model\\win-x64" # 识别语言设置(支持"chinese"、"english"、"japanese"等) configureoptions.language = "chinese" # 应用配置参数 scanner.configuredependencies(configureoptions
步骤 4:文本提取与坐标获取
指定目标图像文件路径,执行扫描操作后,可提取文本内容及每个文本块的位置信息:
# 目标图像路径(替换为实际图像文件路径)
target_image = "模板.png"
# 执行ocr扫描
scanner.scan(target_image)
# 获取扫描结果
ocr_result = scanner.text
# 提取文本块内容与位置信息
blocks_info = [
f'文本内容: "{block.text}"\n'
f'位置坐标: (x={block.box.x}, y={block.box.y})\n'
f'文本块尺寸: 宽度{block.box.width} x 高度{block.box.height}\n'
f'---------------------------------\n'
for block in ocr_result.blocks # 遍历文本块
]
# 打印提取结果(也可根据需求输出至日志或控制台)
print("\n".join(blocks_info))
步骤 5:结果持久化存储
若需留存识别结果,可将文本内容与坐标信息写入本地文件,需指定 utf-8 编码避免中文乱码:
# 写入txt文件(追加模式,避免覆盖已有内容)
with open("ocr文字识别.txt", 'a', encoding='utf-8') as file:
file.write('\n'.join(blocks_info) + '\n\n')
读取结果:
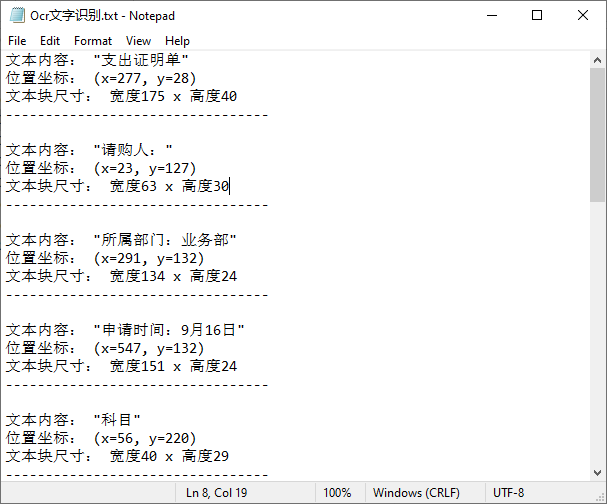
三、进阶应用与批量处理
1. 批量图像识别实现
针对多图像文件处理场景,可通过遍历文件夹实现批量 ocr 操作,提升处理效率:
import os
image_dir = r'images/'
for filename in os.listdir(image_dir):
if filename.endswith(('.png', '.jpg', '.jpeg')):
scanner.scan(os.path.join(image_dir, filename))
# ocr识别图片文本
2. 文本坐标的技术应用方向
文本块坐标参数可支撑以下技术场景实现:
- 图像文本标注:结合 pil、opencv 等图像处理库,根据坐标在原图中绘制矩形框,标注出识别到的文本(比如做数据标注工具);
- 文档结构分析:通过标题、正文、表格等文本块的坐标分布,判断文档内容层级与布局结构;
- 关联数据提取:在结构化文档(如表单、发票)处理中,根据关键信息(如金额、项目名称)的坐标,关联提取对应字段数据。
四、常见问题与处理建议
- 模型路径错误:需确认modelpath参数与实际模型文件保存路径一致,注意不同操作系统的路径分隔符差异;
- 文本乱码问题:写入文件时需显式指定
encoding="utf-8",避免中文及特殊字符乱码; - 识别准确率波动:识别效果受图像质量影响较大,建议使用清晰度高、文字方向正的图像;若识别特定语言,需确保language参数与目标语言匹配。
以上就是python利用spire.ocr for python实现从图片中提取文本和坐标的详细内容,更多关于python ocr图片中提取文本和坐标的资料请关注代码网其它相关文章!




发表评论