问题:主从延迟与写后读不一致
在典型的 mysql 主从架构下,所有写操作都会直接进入主库,而读操作大多分流到从库,从而实现读写分离,缓解主库压力。
然而 mysql 的复制机制是异步的:主库先写入 binlog,从库 i/o 线程拉取到 relay log,再交由 sql 线程顺序回放。这个链路包含网络传输与多步处理,因此天然会引入延迟。当网络抖动、主库写入量过大或从库执行能力不足时,延迟可能进一步加剧。
这种延迟在大多数场景下可以容忍,但在涉及 写后立即读 的业务时问题尤为突出。例如,用户刚下单立刻查询订单详情,如果读请求被路由到了从库,就可能读到旧数据,造成一致性问题。在过去一年,公司内部就发生过 6 起因主从延迟导致的线上事故,几乎全部由这种场景触发。由于问题往往跨接口、跨服务,难以在代码评审或测试阶段提前发现,最终只能紧急切换为“强制读主”兜底,恢复过程耗时且影响业务稳定。
为了监控和判断主从延迟,mysql 提供了一个常用指标:seconds_behind_master。
seconds_behind_master 的计算方式
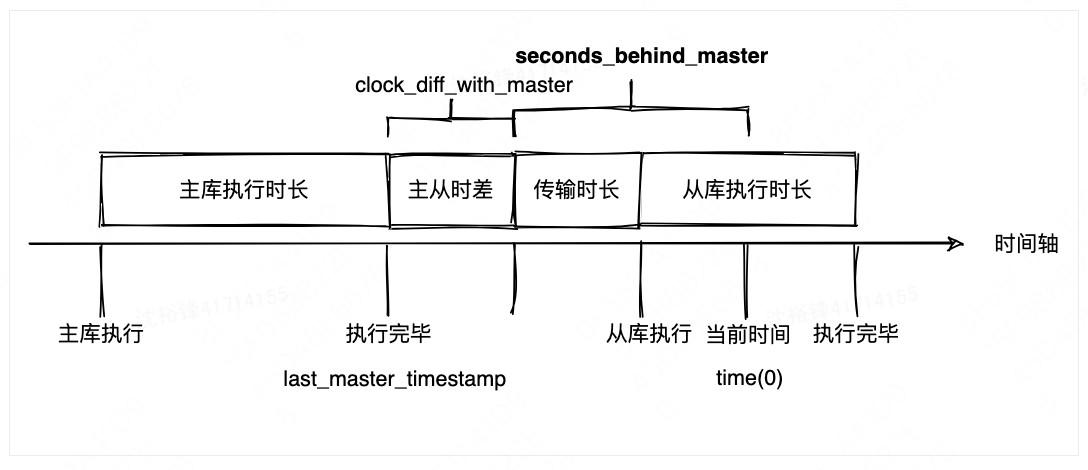
根据 mysql 官方文档与源码,seconds_behind_master 的计算公式如下:
seconds_behind_master = 从库当前系统时间 (time(0)) - sql 线程正在执行的 event 时间戳 (last_master_timestamp) - 主从系统时间差 (clock_diff_with_master)
其中:
- last_master_timestamp:主库 binlog event 的时间戳,随复制传到从库。
- 如果
binlog_format=statement,则last_master_timestamp = 主库开始执行的时间戳 + exec_time - 如果
binlog_format=row,则last_master_timestamp = 主库开始执行的时间戳。
- 如果
- clock_diff_with_master:主从系统时间差,i/o 线程启动时会在主库执行
select unix_timestamp()获取,只计算一次,之后复用,直到 i/o 线程重启。如果启动后手动修改了服务器时间,这个差值不会更新,可能导致计算结果失真。 - time(0):从库当前系统时间。
源码中还定义了结果判定规则:
- sql 与 i/o 线程均运行且空闲 → 延迟结果为
0。此时从库已经把 relay log 中的事件全部回放完毕,i/o 线程又保持着和主库的连接,因此从库已经与主库保持同步,没有新的 event 需要应用,延迟自然为 0。 - sql 线程未运行 → 延迟为
null。如果 sql 线程没有运行(例如被管理员手动stop slave sql_thread,或因错误导致中止),那么从库根本没有在执行任何 event。此时返回数值型延迟没有意义,因此直接返回 null 来提醒用户“复制中断”。 - sql 线程空闲但 i/o 线程未运行 → 延迟为
null。这种情况下,sql 线程虽然没有待执行的 relay log(看起来像“追上了”),但 i/o 线程已经停止,不再从主库获取新的 binlog。这意味着复制链路实际上中断了。如果继续返回 0,会给人错误的印象,好像一切正常,所以 mysql 设计为返回 null 来明确告警。 - 计算结果为负数 → 强制归零。按照公式
seconds_behind_master = time(0) - last_master_timestamp - clock_diff_with_master,如果主从时间不同步,或者事务时间戳落在未来(例如 binlog 被修改、系统时间漂移等),计算结果可能出现负数。但“延迟”为负数在逻辑上没有意义,所以源码中用max(0, time_diff)强制将其归零,避免误导。
局限性
虽然 seconds_behind_master 在多数场景下能反映延迟情况,但在生产环境中,它仍存在明显的局限。下面结合实际场景进行说明。
延迟为 0 并不代表没有延迟
- 场景:在主从架构中,i/o 线程负责从主库拉取 binlog 并写入 relay log,sql 线程再从 relay log 中读取并回放。如果主从之间网络较慢,i/o 线程就可能长期落后主库,积压大量尚未传输的 binlog。
- 表现:当 sql 线程把 relay log 消费完时,
show slave status会显示seconds_behind_master = 0,似乎表示“没有延迟”。 - 实际情况:从库虽然追上了 i/o 线程,但 i/o 线程本身离主库最新的 binlog 可能还有几十 mb,甚至几分钟的差距。换句话说,从库与主库之间仍存在显著延迟,只是指标无法体现。
- 风险:业务层可能基于延迟值为 0 做出“主从一致”的判断,结果读到的数据却仍是旧的,造成写后读不一致。
系统时间修改会导致失真
- 场景:在运维过程中,dba 可能会因为时区调整、ntp 时间同步异常、手工校准等原因修改主库或从库的系统时间。
- 表现:
seconds_behind_master的计算依赖于 binlog 事件的时间戳(来自主库)和从库当前的系统时间。一旦系统时间被修改,这两者的对应关系就会被破坏,延迟值可能出现异常,甚至出现负数。 - 源码处理:mysql 为避免出现“负延迟”,源码中使用
max(0, time_diff)强制将负数归零。 - 结果:这会导致监控曲线突然出现“不合理的断层”,让运维人员无法正确评估延迟情况。
- 例子:主库时间向前拨快 5 分钟 → 从库计算出的延迟会瞬间飙升;主库时间向后拨慢 5 分钟 → 从库计算出的延迟可能变成负数,最后被归零,看起来好像“没有延迟”。
长事务导致延迟值波动
- 场景:主库执行一个耗时数分钟的大事务,例如大批量的
insert或update。 - 表现:在事务执行期间,binlog 中多个 event 的时间戳可能相同(通常是事务开始时的时间戳)。sql 线程在从库上回放这些 event 时,
seconds_behind_master会不断增大,因为从库当前时间与事务开始时间的差值在拉大。一旦事务提交,从库应用完成,延迟值瞬间归零。 - 结果:监控曲线会出现典型的“逐渐升高 → 瞬间清零”的模式,容易被误判为网络抖动或系统故障。
- 例子:某个大事务从 10:00:00 开始,主库执行 5 分钟才提交。从库在 10:04:59 时仍在执行该事务,延迟值可能显示接近 300 秒;但到 10:05:00 一提交,延迟值直接归零,看似“延迟消失”,实际却只是事务执行完毕。
statement 与 row 格式差异
mysql 的 binlog 格式有 statement 和 row,两种模式下 seconds_behind_master 的计算逻辑不同。
statement 格式:记录的是 sql 语句本身,例如:delete from t where id=1。binlog 中会包含 exec_time 字段,表示该语句在主库执行所花的时间。从库计算 last_master_timestamp 时,会在主库开始执行的时间戳上加上 exec_time。
- 结果:延迟值被“平滑”掉,实际延迟被低估。
- 例子:某条 delete 在主库执行耗时 9 秒,从库在 18 秒后才执行到这一 event。按理应该显示 18 秒延迟,但由于公式减去了 9 秒,最终只显示 9 秒。
row 格式:记录的是行级变更数据,例如:delete_rows event,而不是 sql 语句。binlog 不包含 exec_time,所以从库的延迟计算直接基于事务开始时间戳。
- 结果:延迟值更接近真实情况。
- 例子:同样的事务,从库在 24 秒后执行,延迟显示 24 秒,与实际差距一致。
- 对比总结:在短事务场景下,两种格式差异不大;在长事务或复杂 sql 场景下,statement 模式会严重低估延迟值,row 模式更准确。
在 mysql 的 binlog 里,不管是 statement 模式还是 row 模式,数据变更都会被写成一条条 event。
event 就是 binlog 里的“记录单元”,包含 header(时间戳、server_id、位置等)和 body(具体内容)。
在 row 格式 下,binlog 记录的是行级变更事件(如 delete_rows event),这些事件不包含 exec_time 字段,所以 seconds_behind_master 的计算完全依赖于事件 header 中的 timestamp。对于一个事务来说,绝大多数 row events 的时间戳等于事务开始时刻,只有最后的 xid_event 才标记提交时间。因此,在长事务场景下,延迟值会随着事务执行逐渐升高,而在提交时瞬间归零。
例子
statement 格式大事务案例
主库执行语句
begin;
insert into t_user (name, age)
values ('alice', 20), ('bob', 25), ('cathy', 30), ... 共 100 万行;
commit;
binlog 内容(statement 模式)
# at 100
# 250914 10:00:00 server id 1 end_log_pos 200 crc32 0xaaaa
begin
# at 200
# 250914 10:00:00 server id 1 end_log_pos 300 crc32 0xbbbb
# query thread_id=11 exec_time=300 error_code=0
set timestamp=1726298400/*!*/; -- 事务开始时间 (10:00:00)
insert into t_user (name, age)
values ('alice',20),('bob',25),('cathy',30), ... 共 100万行
/*!*/;
# at 5000
# 250914 10:05:00 server id 1 end_log_pos 5100 crc32 0xcccc
xid = 12345
commit;特点
exec_time=300秒,binlog 记录了主库执行这条 sql 的耗时。- 从库在计算
last_master_timestamp时:
last_master_timestamp = 10:00:00 + 300s = 10:05:00
- 所以在从库回放时,不管过程多长,最终 sbm 显示偏小(会被 exec_time 矫正)。
- 结果:真实延迟可能几百秒,但 sbm 看起来更“温和”。
row 格式大事务案例
主库执行语句
begin;
insert into t_user (name, age) values ('alice', 20);
insert into t_user (name, age) values ('bob', 25);
...
insert into t_user (name, age) values ('user1000000', 99);
commit;binlog 内容(row 模式)
# at 100 # 250914 10:00:00 server id 1 end_log_pos 200 crc32 0xaaaa begin # at 200 # 250914 10:00:00 server id 1 end_log_pos 250 crc32 0xbbbb ### insert into `test`.`t_user` ### set ### @1=1, @2='alice', @3=20 # at 250 # 250914 10:00:00 server id 1 end_log_pos 300 crc32 0xcccc ### insert into `test`.`t_user` ### set ### @1=2, @2='bob', @3=25 -- ... 中间还有 999,998 条 write_rows_event ... -- 注意:所有 row event 的时间戳都是 10:00:00 # at 5000000 # 250914 10:05:00 server id 1 end_log_pos 5000100 crc32 0xdddd xid = 12345 commit;
特点
- 所有 row events 的时间戳都是事务 开始时的 10:00:00。
- 从库 sql 线程回放这些 row event 时:
- 在 10:04:59 还在执行 →
sbm = 10:04:59 - 10:00:00 = 299 秒 - 一旦遇到
xid_event(10:05:00) →sbm = 10:05:00 - 10:05:00 = 0 - 结果:延迟曲线先逐渐升高,再在提交瞬间清零。
对比总结:
- statement:有
exec_time,sbm 往往被低估,延迟曲线更“平滑”。 - row:事件时间戳基本等于事务开始时间,延迟曲线会拉高再瞬间归零,更容易表现出“抖动”。
总结
seconds_behind_master 是 mysql 提供的一个延迟指标,但其计算方式决定了它并不能完全反映真实延迟。在网络抖动、系统时间漂移或长事务场景下,它可能显示为 0 或出现异常波动;在 statement 格式下可能被低估,在 row 格式下更接近真实;
因此,在数据库架构和业务逻辑设计中,不能单纯依赖这一指标。线上常见做法是:借助 pt-heartbeat 或 mysql 8.0 performance_schema 原生方案进行更可靠的延迟监控;或在业务层结合 插件化拦截、配置化强制读主、长事务拆分 等措施,主动规避写后读不一致风险。
尽管 seconds_behind_master 存在一定的局限性,但在大多数场景下,它依然能够较为准确地反映主从复制的延迟情况。
参考
[2] seconds_behind_master 的局限性及如何监控主从延迟
[3] mysql 复制延迟 seconds_behind_master 究竟是如何计算的
到此这篇关于深入理解mysql主从架构中的seconds_behind_master指标的文章就介绍到这了,更多相关mysql seconds_behind_master指标内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论