在数据库优化中,最让人头疼的事情之一莫过于精心设计的索引没有发挥作用。为什么会出现这种情况?
这篇文章带大家一起探讨一些常见原因,方便大家更好地理解mysql查询优化器是如何选择索引的,以及在出现类似问题时,可逐项进行对照排查,
以一个简单的 people 表作为例子,表结构如下:
create table `people` ( `id` bigint unsigned not null auto_increment, `first_name` varchar(50) not null, `last_name` varchar(50) not null, `state` char(2) not null, primary key (`id`), key `first_name` (`first_name`), key `state` (`state`) ) engine=innodb default charset=utf8mb4 collate=utf8mb4_unicode_ci
后续会以该表结构为基础,通过添加或删除索引来展示不同场景。
确认索引是否被使用
在分析索引未生效的原因之前,首先需要判断 mysql 是否使用了索引。可以通过 explain 命令来查看查询优化器的分析结果,了解哪些索引被考虑,以及最终选择使用了哪个索引。
例如,以下查询会试图通过 first_name 索引查找数据:
explain select * from people where first_name = 'aaron';
返回结果如下:
| id | table | type | possible_keys | key | key_len | ref | rows | filtered | extra |
|---|---|---|---|---|---|---|---|---|---|
| 1 | people | ref | first_name | first_name | 202 | const | 180 | 100.00 |
从结果中可以看到:
possible_keys表示查询优化器会考虑的索引,这里是first_name索引。key表示实际被选中的索引,也是first_name。
关于explain 的使用,可参考文末补充内容
在本例中,first_name 索引不仅被优化器考虑(considered),而且最终被选中(chosen)。这是两个相关但不同的步骤:首先,优化器会根据查询筛选可用的索引;然后,选择性能较优的索引。
确认索引是否被使用后,接下来分析一些索引未生效的常见原因。
索引未生效的原因
原因 1:另一个索引更优
当查询可以利用多个索引时,mysql 优化器会选择其中最优的索引。如果你的查询可以同时使用多个索引,但最终未选择预期的索引,很可能是因为另一个索引的效率更好。
例如,以下查询同时使用 first_name 和 state 字段:
select * from people where first_name = 'aaron' and state = 'tx';
运行 explain 后结果如下:
| id | table | type | possible_keys | key | key_len | ref | rows | filtered | extra |
|---|---|---|---|---|---|---|---|---|---|
| 1 | people | ref | first_name,state | first_name | 202 | const | 180 | 50.00 | using where |
在这个例子中,first_name 索引比 state 索引的选择性更高,因此优化器选择了 first_name 索引。
原因 2:索引的选择性和基数
索引的性能往往与选择性和基数相关:
- 基数(cardinality) 是列中不同值的数量。
- 选择性(selectivity) 是指这些值的独特程度(计算公式为
count(distinct column) / count(*))。
比如,可以通过以下查询计算基数和选择性:
select count(distinct first_name) as first_name_cardinality, count(distinct state) as state_cardinality, count(distinct first_name) / count(*) as first_name_selectivity, count(distinct state) / count(*) as state_selectivity from people;
结果如下:
| first_name_cardinality | state_cardinality | first_name_selectivity | state_selectivity |
|---|---|---|---|
| 3009 | 2 | 0.0060 | 0.0000 |
first_name字段的不同值非常多,因此选择性较高。state列选择性极低,导致通过state索引进行过滤时,效果较差。
高选择性索引通常性能较优,而低选择性索引在过滤数据时作用有限。
此外,唯一索引(如 id 的主键索引)通常具有完美选择性。
原因 3:选择性因查询而异
索引的选择性是基于整个表数据分布进行计算的,但选择性在具体查询场景中可能不一样。例如:
假如表中有 100 万行,其中 99% 的用户类型是 user,只有 1% 为 admin,总体来看 type 列选择性很低。但如果你的查询条件是 type = 'admin',此时索引的作用就很明显。
优化器会根据查询条件和数据分布动态评估索引的价值。
原因 4:过时或不准确的统计数据
mysql 的索引基数统计信息是通过随机采样维护的,可能出现因统计信息过时而导致优化器做出错误决策的情况。可以通过以下命令更新统计信息:
analyze table people;
如果统计数据采样精度不足,可以通过调整 mysql 的相关参数改善采样质量。
原因 5:表扫描更快
某些情况下,优化器会选择直接扫描整个表而不是使用索引。这可能发生在以下场景:
- 表的大小较小,表扫描成本几乎可以忽略。
- 查询需要获取大部分表数据,索引的过滤能力不足,导致索引的额外开销反而拖慢查询速度。
虽然表扫描看起来反直觉,但在特定情况下确实更高效。
原因 6:索引的结构性限制
理解索引的底层结构(如 b+ 树),有助于分析某些查询为什么无法用到索引。主要有以下几个场景:
场景 1:通配符搜索
mysql 的索引只能用于匹配字符串的前缀部分,不能用于字符串中的后缀或包含部分。例如:
- 查询
like 'aa%'可以使用索引。 - 查询
like '%ron'则无法使用索引。
如果你需要复杂的字符串搜索,可以考虑使用全文索引(fulltext index)或专门设计的数据模型。
场景 2:复合索引的左前缀规则
复合索引要求使用时遵循“左前缀”规则,例如:
alter table people add index multi (first_name, state);
- 查询条件包含
first_name和state时会正确使用索引。 - 查询条件仅包含
state时因不满足左前缀无法使用复合索引。
场景 3:连接列类型或字符集不匹配
若连接的字段类型或字符集不一致,索引将无法生效。例如:
varchar(10)和char(10)类型和长度相同,索引可用。varchar(10)和char(15)则因长度不同导致索引不可用。
确保字段定义一致是索引生效的前提。
原因 7:索引被模糊化处理
某些查询因对字段使用了函数或运算导致索引无法使用。例如:
select * from people where year(created_at) = 2023;
上述查询无法使用 created_at 索引,因为 mysql 没法直接基于函数计算进行优化。替代方案如下:
select * from people where created_at between '2023-01-01' and '2023-12-31';
通过范围查询可以正常使用索引。
原因 8:隐藏索引
mysql 支持隐藏索引,隐藏索引不会被查询优化器使用。例如:
alter table people alter index first_name invisible;
hidden 索引可以用于测试索引删除的影响,若查询性能下降可以随时恢复索引。
强制使用索引
如果你认为 mysql 优化器的决策不正确,可以通过 use index 提示优化器使用指定索引:
explain select * from people use index (state) where first_name = 'aaron' and state = 'tx';
但使用 use index 应该谨慎,因为可能在数据量增长后需要重新评估是否强制使用某索引。
知识补充
仅仅会用mysql的explain还不够,还需要会用explain analyze
在 mysql 中,explain 是一个关键字,用于了解查询执行的相关信息。本文将展示如何利用mysql explain 来解决查询中的性能问题。
虽然执行一个 explain 计划相对简单,但其输出结果并不总是直观的。只有了解其功能,才能充分利用它来实现sql语句的性能提升。
explain 与 explain analyze 的区别
当在查询的前面添加 explain 关键字时,它会解释数据库如何执行该查询以及估算的成本。
示例explain语句:

通过利用这个mysql 内部工具,可以观察到以下内容:
- 查询 id:列中总包含一个数值,用于标识该行属于哪一个 select。
- select_type:运行 select 时,mysql 将 select 查询分为简单类型和复杂类型(主要),如下表所示:
- simple:查询不包含子查询或 union;
- primary(复杂类型):复杂类型分为三大类:简单子查询、派生表(from 子句中的子查询)、union;
- delete:如果explain的是 delete,select_type 会显示 delete;
- 查询运行的表 :显示执行计划中每一步骤所涉及的表。
- 查询访问的分区 :列出访问了哪些表分区(如果表已分区)。
- 所使用的连接类型(如果有):请注意,即使查询中不包含连接,这一列也会填充。
- mysql 可以选择的索引 :列出所有可能的候选索引。
- mysql 实际使用的索引 :显示查询选择的索引,并指定索引的使用长度。
- mysql 选择的索引的长度:当 mysql 使用复合索引时,length 列是唯一能确定复合索引中的使用了多少列的方法。
- 查询访问的行数:在设计数据库实例中的索引时,需要注意 rows 列。该列显示了 mysql 为完成请求而访问的行数,这在设计索引时非常实用。查询访问的行越少,查询速度越快。
- 与索引进行比较的列
- 按指定条件过滤的行的百分比:该列显示了满足表上某些条件(如 where 子句或连接条件)的行的悲观估算百分比。将 rows 列的值乘以该百分比,可以看到 mysql 估计要与查询计划中先前的表连接的行数。
- 与查询相关的任何额外信息
总之,通过使用 explain,可以获得查询预期运行的步骤列表。
什么是 explain analyze
在 mysql 8.0.18 中,mysql 引入了 explain analyze,一个在常规 explain 查询计划工具之上的新功能。除了列出查询计划和估算的成本,explain analyze 还打印了执行计划中各个迭代器的实际成本。
示例explain analyze语句:
注意事项:explain analyze 实际上会运行查询,因此如果你不希望查询在实时数据库上运行,请不要使用 explain analyze。
对于每个迭代器,explain analyze 提供以下信息:
- 估算的执行成本(一些迭代器未被成本模型纳入,因此在估算中未包含它们)
- 估算的返回行数
- 返回第一行所需的时间
- 执行迭代器所花费的时间(包括子迭代器但不包括父迭代器),单位:毫秒。当有多个循环时,该数据会显示平均每个循环所需的时间。
- 迭代器返回的行数
- 循环的次数
mysql explain analyze 的结果会显示查询运行前规划器的估算数据(如图中黄色突出显示部分)和查询实际运行后的数据(如绿色突出显示部分)。
explain analyze 的格式
explain analyze 可用于 select 语句、多表 update 语句、delete 语句和 table 语句。它会自动选择 format=tree 并执行查询(不会向用户显示任何输出)。explain analyze 专注于查询执行的关系以及部分查询的执行顺序。
explain 输出以节点形式组织。在最低层,节点会扫描表或搜索索引;较高层的节点则操作来自低层节点的结果。
虽然 mysql cli 能以表格、制表符、垂直格式,以及漂亮或原始 json 格式打印 explain 结果,但目前 explain analyze 不支持 json 格式。
explain 和explain analyze的使用场景
当你不确定查询是否高效运行时,可以(且应)使用 explain 查询。如果你认为已经正确索引并分区了表,但查询依旧运行缓慢,则可能需要使用explain analyze了。当查询进行explain analyze之后,就需要关注的输出内容以及优化目标了。
1.索引相关列:keys、possible keys 和 key lengths
在 mysql 中处理索引时,需关注 possible_keys、key 和 key_len 列。
- possible_keys 列显示了 mysql 可以选择的索引。
- key 列显示了实际选择的索引。
- key_len 列显示了所选索引的长度。
这些信息对设计索引、为特定任务决定使用何种索引,以及处理相关问题(如选择覆盖索引的适当长度)非常实用。
2.fulltext 索引与连接
当使用 fulltext 索引确保查询参与 join 操作时,需注意 select_type 列,该列的值应为 fulltext。
3.分区
如果表已添加分区并希望查询使用这些分区,要观察 partition 列。如果 mysql 实例正在使用分区,在大多数情况下,mysql 会自动处理所有查询,而无需额外操作。如果希望查询使用特定分区,可以使用类似 select * from table_name partition(p1,p2) 的查询。
explain 的局限性
explain 是一种估算工具。它有时是一个比较准确的估算,但有时可能非常不精确。以下是一些局限性:
- explain 不会告诉你触发器、存储函数或 udf 对查询的影响。
- 它不能分析存储过程。
- 它不会展示 mysql 在查询执行期间的优化过程。
- 一些统计数据是估算值,可能非常不准确。
- 它不会区分某些具有相同名称的内容。例如,它用
filesort表示内存排序和磁盘排序,用using temporary表示内存临时表和磁盘临时表。
show warnings 语句
需要注意的一点是:如果你用 explain 的查询未正确解析,可以输入 show warnings; 查看最后一个运行的非诊断语句的信息。虽然它无法提供像 explain 那样的查询执行计划,但它可能提供关于可处理的查询片段的线索。
show warnings; 包含一些特殊标记,其中信息可能包括:
<index_lookup>(query fragment):表明如果查询正确解析会进行索引查找。<if>(condition, expr1, expr2):表明该查询特定部分有 if 条件。<primary_index_lookup>(query fragment):表明通过主键进行索引查找。<temporary table>:表明这里会创建内部表以保存临时结果(例如在连接之前的子查询中)。
mysql explain 的连接类型
mysql 手册提到 type 列显示“连接类型”,用以解释表的连接方式。但实际上更准确的说法是“访问类型”,即告诉我们 mysql 决定如何在表中找到行。
以下列出从性能最佳到最差的重要访问方式:
- null(较好):表示 mysql 在优化阶段即可解析查询,不会在执行阶段访问表或索引。
- system(较好):表为空或仅有一行记录。
- const(较好):列值可视为常量(即查询只匹配一行)。注:主键查找、唯一索引查找。
- eq_ref(较好):索引是聚簇索引,被 操作使用(索引为主键或 not null 的唯一索引)。
- ref(较好):使用等值运算符访问索引列。注:
ref_or_null是ref的变种,表示初次查找后需再查找 null 条目。 - fulltext(一般):操作(join)使用了表的 fulltext 索引。
- index(一般):扫描整个索引以找到查询匹配项。注:主要优势是无需排序;主要劣势是读取整张表成本高。
- range(一般):范围扫描为受限索引扫描,从索引某点开始返回匹配范围内的记录。注:这比全索引扫描更优。
- all(一般):mysql 为满足查询而扫描全表。
还有一些其他类型需要了解:
- index_merge:此连接类型表示使用了索引合并优化,即通过多索引联合查询单表。
- unique_subquery:此类型替代某些形式的
eq_ref。通常用于以下形式的子查询:value in (select primary_key from single_table where some_expr)。 - index_subquery:与
unique_subquery类似,但应用于非唯一索引的子查询。
explain 的 extra 列
extra 列包含其他列中未涵盖的额外信息。以下是一些重要值及其定义:
- using index:表示 mysql 将使用覆盖索引避免访问表。
- using where:mysql 服务器将在存储引擎检索行后进行行的后过滤。
- using temporary:mysql 会通过临时表保存排序结果。
- using filesort:mysql 使用外部排序来排序结果而非按照索引顺序读取行。
- range checked for each record:(index map:n),表示没有合适索引,并会对连接中的每行重新评估索引。
- using index condition:表通过访问索引元组并在读取完整表之前进行测试读取。
- backward index scan:mysql 使用降序索引完成查询。
- const row not found:表明查询的表为空。
- using index for group-by:表明 mysql 能利用某个索引优化 group by 操作。
explain 优化查询的实践示例
下面通过一个实践案例来演示一下使用 mysql explain 优化查询的方法。
1.运行初始查询
在开始之前,先创建一个数据库,并使用mysql员工样例数据库进行初始化。
通过使用多列索引和mysql explain,允许数据库引擎联合使用多列加速查询。
例如,优化下列查询:
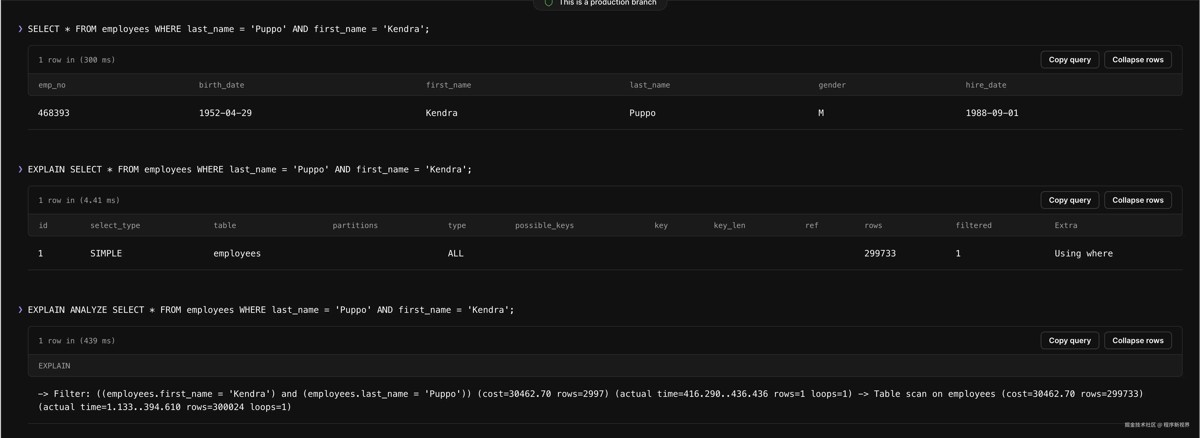
select * from employees where last_name = 'puppo' and first_name = 'kendra';
在运行该查询后,explain 的结果显示访问了 299,733 行,而这是我们需要优化以提升性能的根本原因。
优化方法 1:创建两个独立索引
一种方法是分别为 last_name 列和 first_name 列创建单独索引,但这种方式有一个问题——mysql 知道如何找到所有姓 puppo 的员工,也知道如何找到所有名为 kendra 的员工,但却无法同时高效找到名为 kendra puppo 的员工。
其他需要注意的事项:
- 当面对多个不相关的索引以及包含多个过滤条件的查询时,mysql 有几种选择可以用来处理这些情况。
- mysql 支持索引合并优化(index merge),可联合使用多个索引来执行查询。然而,这种优化有一定局限性,因此在构建索引时应该将其视为一般规则。mysql 可能会决定不使用多个索引;即使会使用,在很多情况下,多个索引的联合效果也远远不如一个专门的索引。
优化方法 2:使用多列索引
由于第一种方法的问题,我们知道需要找到一种解决方案来使用能够考虑多列的索引。这里我们可以使用多列索引来实现这一目标。
可以将其想象成一本电话簿嵌套在另一本电话簿中。首先,查阅姓氏 “puppo”,然后进入第二个目录,该目录按名字的字母顺序组织所有名为 “kendra” 的人,在这个目录中可以快速找到“kendra puppo”。
在 mysql 中,若要为 employees 表中的姓氏和名字创建多列索引,可以执行以下命令:
create index fullnames on employees(last_name, first_name);
现在,多列索引已成功创建,我们可以执行以下 select 查询来查找名字为 kendra 且姓氏为 puppo 的记录。结果将是一行数据,其中包含名为 kendra puppo 的员工信息。
使用 explain 来检查该查询是否使用了索引:

查询优化后的结果显示,索引被使用,并且只访问了一行数据来完成请求。这比优化前必须访问 299,733 行要高效得多。
总结
索引优化涉及多个方面,包括查询优化器运作、数据分布、索引结构等。了解索引未生效的原因并合理优化查询,可以显著提升数据库性能。索引虽强大,但只有正确规划和使用才能发挥最大效用。
到此这篇关于mysql索引不生效的8种原因与解决方法的文章就介绍到这了,更多相关mysql索引不生效内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论