前言
本文主要介绍了进程的优先级及其调度算法:
一、进程优先级
我们计算机里面一般只有一个cpu用来处理进程数据,所以对于进程获得cpu的使用权需要一种重要调度指标,而进程优先级就是这种指标,它用来决定一个进程能够优先获得cpu时间、内存等系统资源。
1.1 基本概念
- cpu资源分配的先后顺序,就是指进程的优先权(priority)。
- 优先权⾼的进程有优先执⾏权利。配置进程优先权对多任务环境的linux很有⽤,可以改善系统性能。
- 还可以把进程运⾏到指定的cpu上,这样⼀来,把不重要的进程安排到某个cpu,可能会改善系统整体性能。
1.2 查看系统进程
在linux或者unix系统中,⽤ps ‒l 命令则会类似输出以下⼏个内容:

- ps -l命令用于显示当前终端上的所有进程的详细信息。
- ps -al命令则更加全面,它显示了系统中所有用户的所有进程(包括其他用户的进程)的详细信息。与ps -l相比,ps -al的输出包含了更多进程的信息,并且不受当前终端的限制。
我们很容易注意到其中的⼏个重要信息,有下:
- uid : 代表执⾏者的⾝份
- pid : 代表这个进程的代号
- ppid :代表这个进程是由哪个进程发展衍⽣⽽来的,亦即⽗进程的代号
- pri :代表这个进程可被执⾏的优先级,其值越⼩越早被执⾏默认为80
- ni :代表这个进程的nice值
1.3 pri和ni
pri也还是⽐较好理解的,即进程的优先级,或者通俗点说就是程序被cpu执⾏的先后顺序,此值越⼩进程的优先级别越⾼
那ni呢?就是我们所要说的nice值了,其表⽰进程可被执⾏的优先级的修正数值
pri值越⼩越快被执⾏,那么加⼊nice值后,将会使得pri变为:pri(new)=pri(oldest)+nice(这意味着我们修改进程优先级的时候,无论中间的pri怎么改变,都会会以最开始的pri值作为基准值去改变)
这样,当nice值为负值的时候,那么该程序将会优先级值将变⼩,即其优先级会变⾼,则其越快被执⾏
所以,调整进程优先级,在linux下,就是调整进程nice值
nice其取值范围是-20⾄19,⼀共40个级别。(当我们调整的nice值超过这个区间的时候,会以区间里面的最低或最高值作为nice值)
需要强调⼀点的是,进程的nice值不是进程的优先级,他们不是⼀个概念,但是进程nice值会影响到进程的优先级变化。可以理解nice值是进程优先级的修正数据
1.4 调整优先级
虽然一般情况下我们是不需要调整优先级的,不过我们仍然需要了解如何调整优先级。
使用下面的命令都需要管理者的身份。
1.4.1 top命令
top命令更改已存在进程的nice:
- top
- 进⼊top后按“r”‒>输⼊进程pid‒>输⼊nice值
- 按”q“退出,及修改完成
1.4.2 nice命令
nice命令用于在启动一个新进程时指定其优先级,即进程的“nice值”。nice值是一个整数,范围从-20(最高优先级)到19(最低优先级),默认情况下,大多数进程的nice值为0。
语法:
- nice [选项] [nice值] 命令 [参数]
参数:
- -n 或 --adjustment:指定nice值的增量或减量。
- -h 或 --help:显示帮助信息。
- -v 或 --version:显示版本信息。
1.4.3 renice命令
renice命令用于修改已经运行的进程的优先级。
语法:
- renice [选项] 优先级 进程id
选项:
- -n:指定要改变的优先级值,取值范围为-20到19。
- -g:指定要调整优先级的进程组id。
- -u:指定要调整优先级的用户名。
- -p:指定要调整优先级的进程id(默认)。
- -h 或 --help:显示帮助信息。
- -v 或 --version:显示版本信息。
二、进程切换
2.1 补充概念
竞争性:系 统进程数⽬众多,⽽cpu资源只有少量,甚⾄1个,所以进程之间是具有竞争属性的。为了⾼效完成任务,更合理竞争相关资源,便具有了优先级
独⽴性: 多进程运⾏,需要独享各种资源,多进程运⾏期间互不⼲扰
并⾏: 多个进程在多个cpu下分别,同时进⾏运⾏,这称之为并⾏
并发: 多个进程在⼀个cpu下采⽤进程切换的⽅式,在⼀段时间之内,让多个进程都得以推进,称之为并发
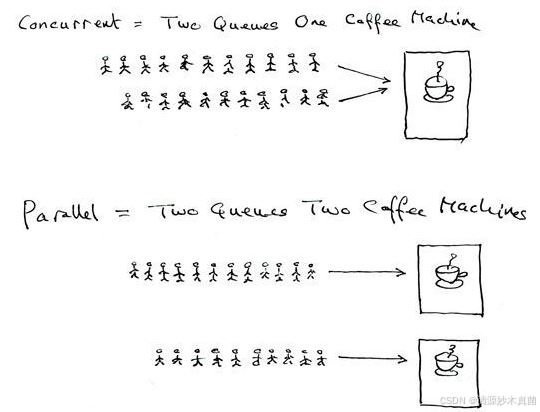
2.2 进程的运行和切换步骤(重要)
在进程运行的过程中会有个时间片的概念,是操作系统进行进程调度时分配给每个进程的一段固定时间。这么做一部分上是为了防止某个进程卡死的情况,例如某个进程调度的时候代码内部有个while(1)函数导致一直运行。及时的切换到运行队列里其它进程是很有必要的
时间片内,进程可以执行其代码、访问内存和进行输入输出操作。当进程的时间片用完时,操作系统会暂停该进程的执行,并将其保存到某种状态(通常是通过进程控制块pcb),然后切换到另一个进程的时间片。
切换步骤:
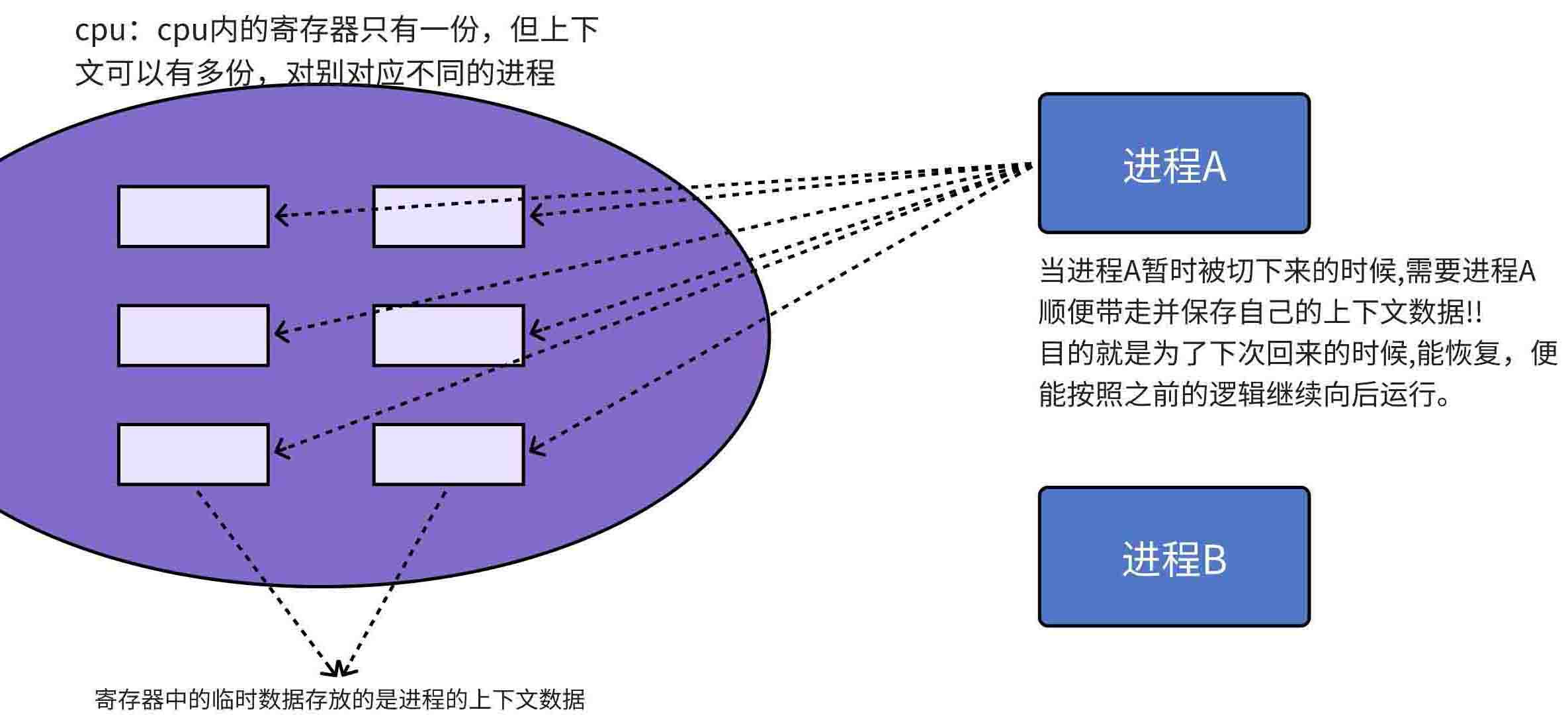
- 一个时间片结束的进程但是还没被cpu执行完其内部的所有代码数据,从cpu内被剥离下来
- 此时进程内临时运行的数据(比如执行到代码的哪一行了,其中变量的一些数据等)会被保存下来(通常是保存到进程的私有堆栈,也就是保存在task_struct本身,及task_struct里面会定义一个或多个变量或指针来存储自己寄存器里面的信息),及cpu内寄存器里面的内容(当前进程的上下文数据)会被保存到某个指定的地方
- 这样子寄存器就可以处理新的进程的数据了,而旧的进程可以重新链入运行队列
- 当恢复到这个进程的时候,就会把前一次本进程被中止时的中间数据再恢复到cpu寄存器里面去
二、linux2.6内核进程o(1)调度队列(重要)
操作系统是如何根据优先级来开展的调度呢?
一个cpu一个运行队列
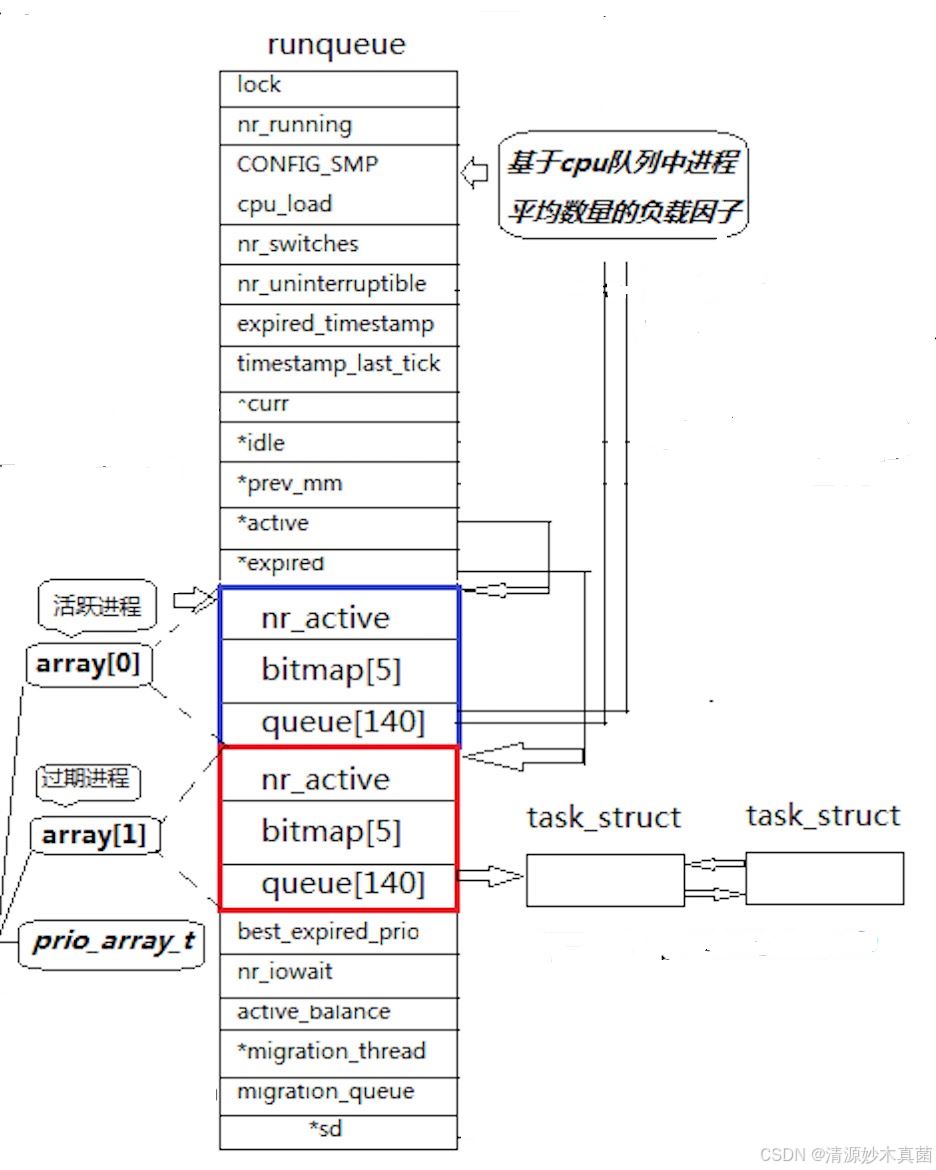
其中queue的类型为struct task_struct队列中的[0-99]为实时优先级我们不做考虑,而[100-139]则是我们进程的优先级序列。
2.1 基本过程
在linux2.6内核中,每个cpu都拥有一个独立的运行队列(run_queue)。
运行队列用于管理和调度该cpu上的所有可运行进程。
task_struct结构体:
- 在linux内核中,每个进程都有一个对应的task_struct结构体,用于存储该进程的所有信息。
- 它会被链入运行队列中,在运行队列中,task_struct结构体通过指针数组来维护不同优先级的进程队列。
- 其下的run 对应上面active ,wait对应expired ,running对应活跃进程,waiting对应过期进程
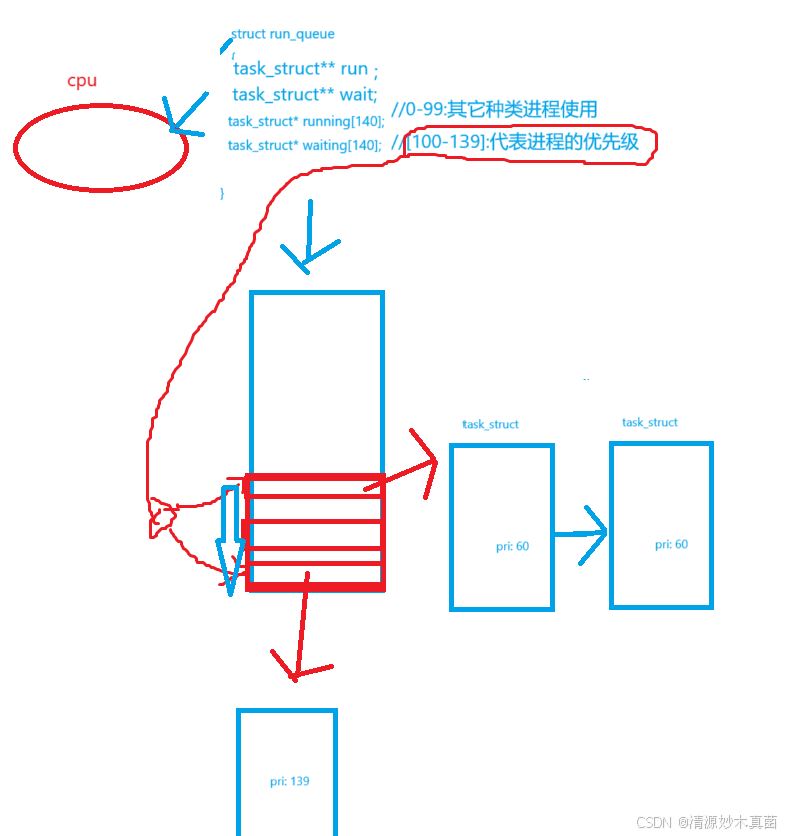
这是一个类似哈希链地址法的指针数组,遍历这个指针数组从上到下,从左到右就完成了对进程的优先级的调度!!!
除此之外我们在running下设计了个waiting,这么做的目的是
当我们遍历这个指针数组的时候,可能会有新的task_struct插入进来,或者一个进程时间片结束后进程还没被cpu处理完,那么此时就会进入到waiting里面,当running这个指针数组遍历完的时候,利用位图(bitmap)判断指针数据这个队列是否为空,然后只需要交换上面图片中的run和wait两者指向指针的地址,就能继续调度未处理完数据或者新的task_struct了!
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。




发表评论