python读写csv文件
csv文件介绍
csv(comma separated values)全称逗号分隔值文件是一种简单、通用的文件格式,被广泛的应用于应用程序(数据库、电子表格等)数据的导入和导出以及异构系统之间的数据交换。因为csv是纯文本文件,不管是什么操作系统和编程语言都是可以处理纯文本的,而且很多编程语言中都提供了对读写csv文件的支持,因此csv格式在数据处理和数据科学中被广泛应用。
csv文件有以下特点:
- 纯文本,使用某种字符集(如ascii、unicode、gb2312)等);
- 由一条条的记录组成(典型的是每行一条记录);
- 每条记录被分隔符(如逗号、分号、制表符等)分隔为字段(列);
- 每条记录都有同样的字段序列。
将数据写入csv文件
案例1:电商订单数据导出
import csv
from datetime import datetime
import random
# 模拟电商订单数据
def generate_order_data(num_orders):
"""
生成指定数量的订单数据。
参数:
num_orders (int): 要生成的订单数量。
返回:
list: 包含所有生成订单数据的列表。
"""
orders = []
for i in range(1, num_orders + 1):
order_id = f"ord{1000 + i}"
customer_id = f"cust{random.randint(100, 999)}"
product_id = f"prod{random.randint(1000, 9999)}"
quantity = random.randint(1, 5)
price = round(random.uniform(10, 100), 2)
order_date = datetime.now().strftime("%y-%m-%d %h:%m:%s")
status = random.choice(["pending", "shipped", "delivered", "cancelled"])
orders.append([order_id, customer_id, product_id, quantity, price, order_date, status])
return orders
# 写入csv文件
def export_orders_to_csv(orders, filename):
"""
将订单数据导出到csv文件。
参数:
orders (list): 包含订单数据的列表。
filename (str): 要写入的csv文件名。
"""
headers = ["order id", "customer id", "product id", "quantity", "price", "order date", "status"]
with open(filename, mode='w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(headers)
writer.writerows(orders)
print(f"成功导出 {len(orders)} 条订单数据到 {filename}")
# 使用示例
if __name__ == "__main__":
num_orders = 50
orders = generate_order_data(num_orders)
export_orders_to_csv(orders, "orders_export.csv")案例2:学生成绩管理系统
# 导入csv模块,用于读取和写入csv文件
import csv
# 导入random模块,用于生成随机数
import random
# 导入faker模块,用于生成假数据
from faker import faker
# 初始化faker生成假数据
fake = faker('zh_cn')
# 生成学生成绩数据
def generate_student_grades(num_students):
students = []
for _ in range(num_students):
student_id = f"stu{fake.unique.random_number(digits=5)}" # 生成唯一的5位数字学号
name = fake.name() # 生成假姓名
class_name = f"{random.randint(1, 6)}年级{random.randint(1, 12)}班" # 生成假班级
chinese = random.randint(60, 100) # 生成假语文成绩
math = random.randint(50, 100) # 生成假数学成绩
english = random.randint(55, 100) # 生成假英语成绩
science = random.randint(65, 100) # 生成假科学成绩
total = chinese + math + english + science # 计算总分
average = round(total / 4, 1) # 计算平均分
students.append([student_id, name, class_name, chinese, math, english, science, total, average]) # 将学生成绩添加到列表中
return students
# 导出成绩到csv
def export_grades_to_csv(students, filename):
headers = ["学号", "姓名", "班级", "语文", "数学", "英语", "科学", "总分", "平均分"] # 定义csv文件头
with open(filename, mode='w', newline='', encoding='utf-8-sig') as file: # utf-8-sig解决excel中文乱码
writer = csv.writer(file)
writer.writerow(headers) # 写入文件头
writer.writerows(students) # 写入学生成绩数据
print(f"成功导出 {len(students)} 名学生成绩到 {filename}") # 输出成功导出学生成绩的提示信息
# 使用示例
if __name__ == "__main__":
num_students = 30 # 定义学生数量
students = generate_student_grades(num_students) # 生成学生成绩数据
export_grades_to_csv(students, "student_grades.csv") # 导出成绩到csv文件从csv文件读取数据
案例1:读取电商订单数据并进行分析
import csv
from collections import defaultdict
def analyze_orders(csv_file):
"""
分析订单数据
读取csv文件中的订单信息,并进行统计分析
参数:
csv_file (str): 订单数据的csv文件路径
返回:
无
"""
# 初始化统计变量
total_orders = 0
total_revenue = 0.0
status_counts = defaultdict(int)
product_sales = defaultdict(int)
try:
# 打开csv文件并读取订单数据
with open(csv_file, mode='r', encoding='utf-8') as file:
reader = csv.dictreader(file)
for row in reader:
total_orders += 1
quantity = int(row['quantity'])
price = float(row['price'])
total_revenue += quantity * price
status = row['status']
status_counts[status] += 1
product_id = row['product id']
product_sales[product_id] += quantity
# 打印分析结果
print(f"订单总数: {total_orders}")
print(f"总销售额: ¥{total_revenue:.2f}")
print("\n订单状态分布:")
for status, count in status_counts.items():
print(f"{status}: {count} 单 ({count / total_orders:.1%})")
print("\n最畅销产品top3:")
top_products = sorted(product_sales.items(), key=lambda x: x[1], reverse=true)[:3]
for product, sales in top_products:
print(f"{product}: {sales} 件")
except filenotfounderror:
print(f"错误: 文件 {csv_file} 未找到")
except exception as e:
print(f"读取文件时出错: {e}")
# 使用示例
if __name__ == "__main__":
analyze_orders("orders_export.csv")案例2:读取学生成绩并计算统计指标
import csv
import statistics
def analyze_student_grades(csv_file):
grades = {
'语文': [],
'数学': [],
'英语': [],
'科学': []
}
class_stats = defaultdict(lambda: {
'count': 0,
'total': 0,
'scores': []
})
try:
with open(csv_file, mode='r', encoding='utf-8-sig') as file:
reader = csv.dictreader(file)
for row in reader:
# 收集各科目成绩
grades['语文'].append(int(row['语文']))
grades['数学'].append(int(row['数学']))
grades['英语'].append(int(row['英语']))
grades['科学'].append(int(row['科学']))
# 按班级统计
class_name = row['班级']
class_stats[class_name]['count'] += 1
total_score = int(row['总分'])
class_stats[class_name]['total'] += total_score
class_stats[class_name]['scores'].append(total_score)
# 计算并打印各科目统计信息
print("各科目成绩统计:")
for subject, scores in grades.items():
print(f"{subject}:")
print(f" 平均分: {statistics.mean(scores):.1f}")
print(f" 最高分: {max(scores)}")
print(f" 最低分: {min(scores)}")
print(f" 中位数: {statistics.median(scores)}")
# 计算并打印班级统计信息
print("\n班级成绩统计:")
for class_name, stats in class_stats.items():
avg = stats['total'] / stats['count']
print(f"{class_name}:")
print(f" 平均总分: {avg:.1f}")
print(f" 最高总分: {max(stats['scores'])}")
print(f" 最低总分: {min(stats['scores'])}")
print(f" 人数: {stats['count']}")
except filenotfounderror:
print(f"错误: 文件 {csv_file} 未找到")
except exception as e:
print(f"处理成绩数据时出错: {e}")
# 使用示例
if __name__ == "__main__":
analyze_student_grades("student_grades.csv")python读写excel文件
excel简介
excel 是 microsoft(微软)为使用 windows 和 macos 操作系统开发的一款电子表格软件。excel 凭借其直观的界面、出色的计算功能和图表工具,再加上成功的市场营销,一直以来都是最为流行的个人计算机数据处理软件。当然,excel 也有很多竞品,例如 google sheets、libreoffice calc、numbers 等,这些竞品基本上也能够兼容 excel,至少能够读写较新版本的 excel 文件,当然这些不是我们讨论的重点。掌握用 python 程序操作 excel 文件,可以让日常办公自动化的工作更加轻松愉快,而且在很多商业项目中,导入导出 excel 文件都是特别常见的功能。
python 操作 excel 需要三方库的支持,如果要兼容 excel 2007 以前的版本,也就是xls格式的 excel 文件,可以使用三方库xlrd和xlwt,前者用于读 excel 文件,后者用于写 excel 文件。如果使用较新版本的 excel,即xlsx格式的 excel 文件,可以使用openpyxl库,当然这个库不仅仅可以操作excel,还可以操作其他基于 office open xml 的电子表格文件。
基于xlwt和xlrd操作 excel 文件
命令安装这两个三方库以及配合使用的工具模块xlutils
pip install xlwt xlrd xlutils
读excel文件
例如在当前文件夹下有一个名为“阿里巴巴2020年股票数据.xls”的 excel 文件,如果想读取并显示该文件的内容,可以通过如下所示的代码来完成。
# 导入csv模块,用于读取和写入csv文件
import csv
# 导入defaultdict模块,用于创建一个默认值的字典
from collections import defaultdict
def analyze_orders(csv_file):
"""
分析订单数据
读取csv文件中的订单信息,并进行统计分析
参数:
csv_file (str): 订单数据的csv文件路径
返回:
无
"""
# 初始化统计变量
total_orders = 0
total_revenue = 0.0
status_counts = defaultdict(int)
product_sales = defaultdict(int)
try:
# 打开csv文件并读取订单数据
with open(csv_file, mode='r', encoding='utf-8') as file:
reader = csv.dictreader(file)
for row in reader:
total_orders += 1
quantity = int(row['quantity'])
price = float(row['price'])
total_revenue += quantity * price
status = row['status']
status_counts[status] += 1
product_id = row['product id']
product_sales[product_id] += quantity
# 打印分析结果
print(f"订单总数: {total_orders}")
print(f"总销售额: ¥{total_revenue:.2f}")
print("\n订单状态分布:")
for status, count in status_counts.items():
print(f"{status}: {count} 单 ({count / total_orders:.1%})")
print("\n最畅销产品top3:")
top_products = sorted(product_sales.items(), key=lambda x: x[1], reverse=true)[:3]
for product, sales in top_products:
print(f"{product}: {sales} 件")
except filenotfounderror:
print(f"错误: 文件 {csv_file} 未找到")
except exception as e:
print(f"读取文件时出错: {e}")
# 使用示例
if __name__ == "__main__":
analyze_orders("orders_export.csv")写excel文件
写入 excel 文件可以通过xlwt 模块的workbook类创建工作簿对象,通过工作簿对象的add_sheet方法可以添加工作表,通过工作表对象的write方法可以向指定单元格中写入数据,最后通过工作簿对象的save方法将工作簿写入到指定的文件或内存中。下面的代码实现了将5 个学生 3 门课程的考试成绩写入 excel 文件的操作。
import random
import xlwt
student_names = ['关羽', '张飞', '赵云', '马超', '黄忠']
scores = [[random.randrange(50, 101) for _ in range(3)] for _ in range(5)]
# 创建工作簿对象(workbook)
wb = xlwt.workbook()
# 创建工作表对象(worksheet)
sheet = wb.add_sheet('一年级二班')
# 添加表头数据
titles = ('姓名', '语文', '数学', '英语')
for index, title in enumerate(titles):
sheet.write(0, index, title)
# 将学生姓名和考试成绩写入单元格
for row in range(len(scores)):
sheet.write(row + 1, 0, student_names[row])
for col in range(len(scores[row])):
sheet.write(row + 1, col + 1, scores[row][col])
# 保存excel工作簿
wb.save('考试成绩表.xls')调整单元格样式
在写excel文件时,我们还可以为单元格设置样式,主要包括字体(font)、对齐方式(alignment)、边框(border)和背景(background)的设置,xlwt对这几项设置都封装了对应的类来支持。要设置单元格样式需要首先创建一个xfstyle对象,再通过该对象的属性对字体、对齐方式、边框等进行设定,例如在上面的例子中,如果希望将表头单元格的背景色修改为黄色,可以按照如下的方式进行操作。
header_style = xlwt.xfstyle()
pattern = xlwt.pattern()
pattern.pattern = xlwt.pattern.solid_pattern
# 0 - 黑色、1 - 白色、2 - 红色、3 - 绿色、4 - 蓝色、5 - 黄色、6 - 粉色、7 - 青色
pattern.pattern_fore_colour = 5
header_style.pattern = pattern
titles = ('姓名', '语文', '数学', '英语')
for index, title in enumerate(titles):
sheet.write(0, index, title, header_style)如果希望为表头设置指定的字体,可以使用font类并添加如下所示的代码。
font = xlwt.font() # 字体名称 font.name = '华文楷体' # 字体大小(20是基准单位,18表示18px) font.height = 20 * 18 # 是否使用粗体 font.bold = true # 是否使用斜体 font.italic = false # 字体颜色 font.colour_index = 1 header_style.font = font
注意:上面代码中指定的字体名(font.name)应当是本地系统有的字体,例如在我的电脑上有名为“华文楷体”的字体。
如果希望表头垂直居中对齐,可以使用下面的代码进行设置。
align = xlwt.alignment() # 垂直方向的对齐方式 align.vert = xlwt.alignment.vert_center # 水平方向的对齐方式 align.horz = xlwt.alignment.horz_center header_style.alignment = align
如果希望给表头加上黄色的虚线边框,可以使用下面的代码来设置。
borders = xlwt.borders()
props = (
('top', 'top_colour'), ('right', 'right_colour'),
('bottom', 'bottom_colour'), ('left', 'left_colour')
)
# 通过循环对四个方向的边框样式及颜色进行设定
for position, color in props:
# 使用setattr内置函数动态给对象指定的属性赋值
setattr(borders, position, xlwt.borders.dashed)
setattr(borders, color, 5)
header_style.borders = borders如果要调整单元格的宽度(列宽)和表头的高度(行高),可以按照下面的代码进行操作。
# 设置行高为40px
sheet.row(0).set_style(xlwt.easyxf(f'font:height {20 * 40}'))
titles = ('姓名', '语文', '数学', '英语')
for index, title in enumerate(titles):
# 设置列宽为200px
sheet.col(index).width = 20 * 200
# 设置单元格的数据和样式
sheet.write(0, index, title, header_style)公式计算
对于前面打开的“阿里巴巴2020年股票数据.xls”文件,如果要统计全年收盘价(close字段)的平均值以及全年交易量(volume字段)的总和,可以使用excel的公式计算即可。我们可以先使用xlrd读取excel文件夹,然后通过xlutils三方库提供的copy函数将读取到的excel文件转成workbook对象进行写操作,在调用write方法时,可以将一个formula对象写入单元格。
实现公式计算的代码如下所示。
import xlrd
import xlwt
from xlutils.copy import copy
wb_for_read = xlrd.open_workbook('阿里巴巴2020年股票数据.xls')
sheet1 = wb_for_read.sheet_by_index(0)
nrows, ncols = sheet1.nrows, sheet1.ncols
wb_for_write = copy(wb_for_read)
sheet2 = wb_for_write.get_sheet(0)
sheet2.write(nrows, 4, xlwt.formula(f'average(e2:e{nrows})'))
sheet2.write(nrows, 6, xlwt.formula(f'sum(g2:g{nrows})'))
wb_for_write.save('阿里巴巴2020年股票数据汇总.xls')三方库openpyxl如何进行 excel 文件操作
pip install openpyxl
openpyxl的优点在于,当我们打开一个 excel 文件后,既可以对它进行读操作,又可以对它进行写操作,而且在操作的便捷性上是优于xlwt和xlrd的。此外,如果要进行样式编辑和公式计算,使用openpyxl也远比上一个章节我们讲解的方式更为简单,而且openpyxl还支持数据透 视和插入图表等操作,功能非常强大。有一点需要再次强调,openpyxl并不支持操作 office 2007 以前版本的 excel 文件。
读取excel文件
例如在当前文件夹下有一个名为“阿里巴巴2020年股票数据.xlsx”的 excel 文件,如果想读取并显示该文件的内容
import datetime
import openpyxl
# 加载一个工作簿 ---> workbook
wb = openpyxl.load_workbook('阿里巴巴2020年股票数据.xlsx')
# 获取工作表的名字
print(wb.sheetnames)
# 获取工作表 ---> worksheet
sheet = wb.worksheets[0]
# 获得单元格的范围
print(sheet.dimensions)
# 获得行数和列数
print(sheet.max_row, sheet.max_column)
# 获取指定单元格的值
print(sheet.cell(3, 3).value)
print(sheet['c3'].value)
print(sheet['g255'].value)
# 获取多个单元格(嵌套元组)
print(sheet['a2:c5'])
# 读取所有单元格的数据
for row_ch in range(2, sheet.max_row + 1):
for col_ch in 'abcdefg':
value = sheet[f'{col_ch}{row_ch}'].value
if type(value) == datetime.datetime:
print(value.strftime('%y年%m月%d日'), end='\t')
elif type(value) == int:
print(f'{value:<10d}', end='\t')
elif type(value) == float:
print(f'{value:.4f}', end='\t')
else:
print(value, end='\t')
print()注意:openpyxl获取指定的单元格有两种方式,一种是通过cell方法,需要注意,该方法的行索引和列索引都是从1开始的,这是为了照顾用惯了 excel 的人的习惯;另一种是通过索引运算,通过指定单元格的坐标,例如c3、g255,也可以取得对应的单元格,再通过单元格对象的value属性,就可以获取到单元格的值。通过上面的代码,相信大家还注意到了,可以通过类似sheet['a2:c5']或sheet['a2':'c5']这样的切片操作获取多个单元格,该操作将返回嵌套的元组,相当于获取到了多行多列。
写excel文件
import random
import openpyxl
# 第一步:创建工作簿(workbook)
wb = openpyxl.workbook()
# 第二步:添加工作表(worksheet)
sheet = wb.active
sheet.title = '期末成绩'
titles = ('姓名', '语文', '数学', '英语')
for col_index, title in enumerate(titles):
sheet.cell(1, col_index + 1, title)
names = ('关羽', '张飞', '赵云', '马超', '黄忠')
for row_index, name in enumerate(names):
sheet.cell(row_index + 2, 1, name)
for col_index in range(2, 5):
sheet.cell(row_index + 2, col_index, random.randrange(50, 101))
# 第四步:保存工作簿
wb.save('考试成绩表.xlsx')调整样式和公式计算
在使用openpyxl操作 excel 时,如果要调整单元格的样式,可以直接通过单元格对象(cell对象)的属性进行操作。单元格对象的属性包括字体(font)、对齐(alignment)、边框(border)等,具体的可以参考openpyxl的官方文档。在使用openpyxl时,如果需要做公式计算,可以完全按照 excel 中的操作方式来进行,具体的代码如下所示。
import openpyxl
from openpyxl.styles import font, alignment, border, side
# 对齐方式
alignment = alignment(horizontal='center', vertical='center')
# 边框线条
side = side(color='ff7f50', style='mediumdashed')
wb = openpyxl.load_workbook('考试成绩表.xlsx')
sheet = wb.worksheets[0]
# 调整行高和列宽
sheet.row_dimensions[1].height = 30
sheet.column_dimensions['e'].width = 120
sheet['e1'] = '平均分'
# 设置字体
sheet.cell(1, 5).font = font(size=18, bold=true, color='ff1493', name='华文楷体')
# 设置对齐方式
sheet.cell(1, 5).alignment = alignment
# 设置单元格边框
sheet.cell(1, 5).border = border(left=side, top=side, right=side, bottom=side)
for i in range(2, 7):
# 公式计算每个学生的平均分
sheet[f'e{i}'] = f'=average(b{i}:d{i})'
sheet.cell(i, 5).font = font(size=12, color='4169e1', italic=true)
sheet.cell(i, 5).alignment = alignment
wb.save('考试成绩表.xlsx')生成统计图表
通过openpyxl库,可以直接向 excel 中插入统计图表,具体的做法跟在 excel 中插入图表大体一致。我们可以创建指定类型的图表对象,然后通过该对象的属性对图表进行设置。当然,最为重要的是为图表绑定数据,即横轴代表什么,纵轴代表什么,具体的数值是多少。最后,可以将图表对象添加到表单中,具体的代码如下所示。
from openpyxl import workbook
from openpyxl.chart import barchart, reference
from openpyxl.chart.label import datalabellist
def create_sales_report():
# 创建一个只写模式的workbook
wb = workbook(write_only=true)
sheet = wb.create_sheet(title="季度销售报告")
# 准备销售数据 - 2023年各季度家电销售数据(单位:万元)
header = ["产品类别", "第一季度", "第二季度", "第三季度", "第四季度", "年度总计"]
products = [
["空调", 320, 580, 650, 280, 0],
["冰箱", 280, 310, 290, 350, 0],
["洗衣机", 190, 210, 230, 300, 0],
["电视机", 450, 380, 420, 550, 0],
["小家电", 180, 160, 200, 240, 0]
]
# 计算年度总计
for product in products:
product[5] = sum(product[1:5])
# 向工作表中写入数据
sheet.append(header)
for row in products:
sheet.append(row)
# 创建柱状图
chart = barchart()
chart.type = "col" # 柱状图
chart.style = 13 # 样式
chart.title = "2023年家电销售季度对比(万元)"
chart.y_axis.title = "销售额(万元)"
chart.x_axis.title = "产品类别"
chart.legend.position = "b" # 图例在底部
# 设置数据范围(不包括总计列)
data = reference(sheet, min_col=2, min_row=1, max_col=5, max_row=6)
# 设置分类范围
cats = reference(sheet, min_col=1, min_row=2, max_row=6)
# 添加数据到图表
chart.add_data(data, titles_from_data=true)
chart.set_categories(cats)
# 添加数据标签
chart.datalabels = datalabellist()
chart.datalabels.showval = true # 显示数值
# 将图表添加到工作表(从a8单元格开始)
sheet.add_chart(chart, "a8")
# 创建第二个图表 - 年度总计对比
chart2 = barchart()
chart2.type = "bar" # 条形图(横向)
chart2.style = 11
chart2.title = "2023年家电销售年度总计对比"
chart2.x_axis.title = "销售额(万元)"
chart2.y_axis.title = "产品类别"
# 设置数据范围(只包含总计列)
data2 = reference(sheet, min_col=6, min_row=1, max_row=6)
# 设置分类范围(与第一个图表相同)
chart2.add_data(data2, titles_from_data=true)
chart2.set_categories(cats)
chart2.datalabels = datalabellist()
chart2.datalabels.showval = true
# 将第二个图表添加到工作表(从a25单元格开始)
sheet.add_chart(chart2, "a25")
# 保存excel文件
wb.save("家电销售报告_2023.xlsx")
print("销售报告已生成: 家电销售报告_2023.xlsx")
if __name__ == "__main__":
create_sales_report()运行上面的代码,打开生成的 excel 文件,效果如下图所示
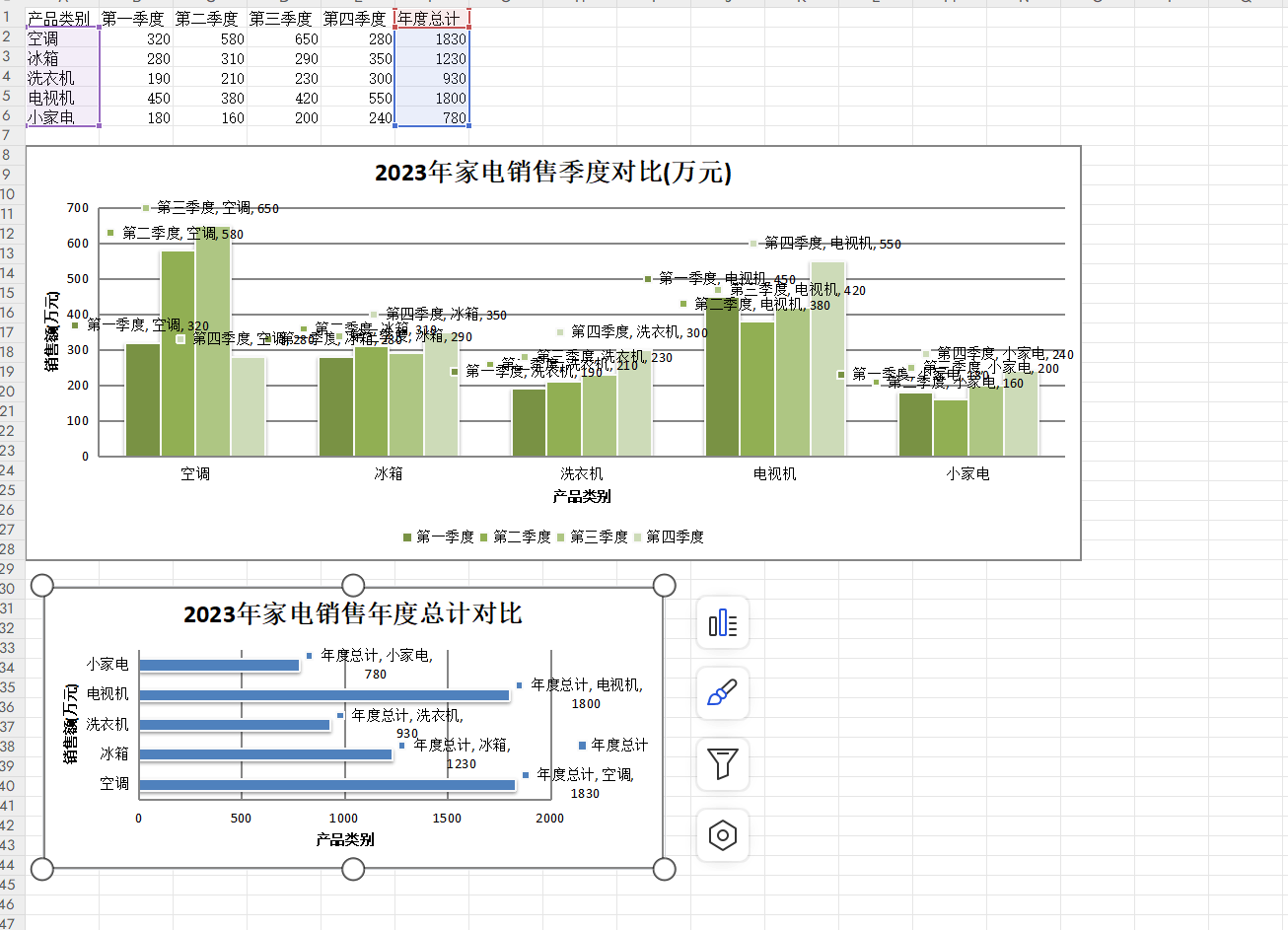
以上就是python处理csv文件与excel文件的技巧分享的详细内容,更多关于python处理文件的资料请关注代码网其它相关文章!





发表评论