1. 背景介绍
1.1 目的和范围
本文旨在教授读者如何使用python的beautifulsoup库从网页中提取链接并进行深入分析。内容涵盖从基础安装到高级应用的全过程,包括html解析原理、链接提取技术、数据清洗和分析方法。
1.2 预期读者
本文适合以下读者:
- 希望学习网页爬虫技术的python开发者
- 需要从网页提取结构化数据的数据分析师
- 对网络数据采集感兴趣的研究人员
- 希望自动化网页内容处理的it专业人士
1.3 文档结构概述
文章将从beautifulsoup基础开始,逐步深入到链接提取和分析的高级技术,最后通过实际案例展示完整应用流程。
1.4 术语表
1.4.1 核心术语定义
- html解析:将html文档转换为可操作的对象树的过程
- dom树:文档对象模型,表示html文档的树状结构
- css选择器:用于选择html元素的模式匹配语法
- xpath:另一种在xml/html文档中定位节点的语言
1.4.2 相关概念解释
- 网页爬虫:自动浏览网页并提取数据的程序
- 数据清洗:处理原始数据使其适合分析的过程
- 正则表达式:用于模式匹配的强大文本处理工具
1.4.3 缩略词列表
- html:超文本标记语言
- url:统一资源定位符
- dom:文档对象模型
- api:应用程序编程接口
2. 核心概念与联系
beautifulsoup是一个python库,用于从html和xml文档中提取数据。它创建了一个解析树,便于用户浏览和搜索文档内容。
html解析过程可以分为以下几个步骤:
- 获取html文档(通过请求或本地文件)
- 使用beautifulsoup解析html
- 构建dom树结构
- 遍历或搜索dom树提取链接
- 对提取的链接进行分析处理
beautifulsoup支持多种解析器,包括:
- html.parser(python内置)
- lxml(速度快,功能强)
- html5lib(最接近浏览器解析方式)
3. 核心算法原理 & 具体操作步骤
3.1 安装 beautifulsoup
pip install beautifulsoup4 pip install requests # 用于获取网页内容
3.2 基本链接提取
from bs4 import beautifulsoup
import requests
# 获取网页内容
url = "https://example.com"
response = requests.get(url)
html_content = response.text
# 解析html
soup = beautifulsoup(html_content, 'html.parser')
# 提取所有链接
links = []
for link in soup.find_all('a'):
href = link.get('href')
if href: # 确保href属性存在
links.append(href)
print(f"found {len(links)} links:")
for link in links[:10]: # 打印前10个链接
print(link)
3.3 高级链接提取技术
3.3.1 使用css选择器
# 提取特定css类的链接
special_links = soup.select('a.special-class')
# 提取特定区域的链接
nav_links = soup.select('nav a')
# 提取特定id下的链接
footer_links = soup.select('#footer a')
3.3.2 使用正则表达式过滤链接
import re # 只提取包含特定模式的链接 pattern = re.compile(r'\.pdf$') # 匹配pdf文件 pdf_links = [link for link in links if pattern.search(link)]
3.3.3 处理相对链接
from urllib.parse import urljoin
base_url = "https://example.com"
absolute_links = [urljoin(base_url, link) if not link.startswith('http') else link for link in links]
4. 数学模型和公式 & 详细讲解 & 举例说明
4.1 链接分析的基本指标
4.1.1 链接数量统计
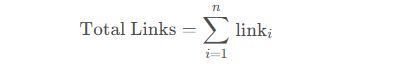
4.1.2 链接类型分布
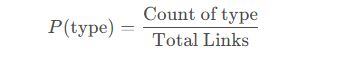
4.1.3 链接深度分析
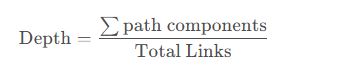
4.2 pagerank算法简介
虽然beautifulsoup本身不实现pagerank,但提取的链接可以用于pagerank计算:
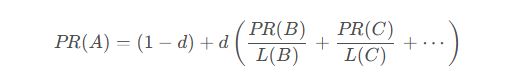
其中:
- p r ( a ) pr(a) pr(a) 是页面a的pagerank值
- d d d 是阻尼系数(通常设为0.85)
- l ( b ) l(b) l(b) 是页面b的出链数量
5. 项目实战:代码实际案例和详细解释说明
5.1 开发环境搭建
建议使用python 3.7+和以下库:
- beautifulsoup4
- requests
- pandas (数据分析)
- matplotlib (可视化)
5.2 源代码详细实现和代码解读
5.2.1 完整链接提取与分析脚本
import requests
from bs4 import beautifulsoup
from urllib.parse import urlparse, urljoin
import pandas as pd
import matplotlib.pyplot as plt
from collections import counter
def extract_links(url):
"""提取指定url的所有链接"""
try:
response = requests.get(url, timeout=10)
response.raise_for_status()
except requests.exceptions.requestexception as e:
print(f"error fetching {url}: {e}")
return []
soup = beautifulsoup(response.text, 'html.parser')
base_url = f"{urlparse(url).scheme}://{urlparse(url).netloc}"
links = []
for link in soup.find_all('a'):
href = link.get('href')
if href and not href.startswith('javascript'):
absolute_url = urljoin(base_url, href) if not href.startswith('http') else href
links.append(absolute_url)
return links
def analyze_links(links):
"""分析链接数据"""
# 创建dataframe
df = pd.dataframe(links, columns=['url'])
# 解析url组件
df['domain'] = df['url'].apply(lambda x: urlparse(x).netloc)
df['path'] = df['url'].apply(lambda x: urlparse(x).path)
df['extension'] = df['path'].apply(lambda x: x.split('.')[-1] if '.' in x.split('/')[-1] else '')
# 统计信息
domain_counts = df['domain'].value_counts()
extension_counts = df['extension'].value_counts()
return df, domain_counts, extension_counts
def visualize_data(domain_counts, extension_counts):
"""可视化分析结果"""
plt.figure(figsize=(12, 6))
# 域名分布
plt.subplot(1, 2, 1)
domain_counts[:10].plot(kind='bar') # 显示前10个最多出现的域名
plt.title('top 10 domains')
plt.xlabel('domain')
plt.ylabel('count')
# 文件类型分布
plt.subplot(1, 2, 2)
extension_counts[:5].plot(kind='pie', autopct='%1.1f%%')
plt.title('file type distribution')
plt.tight_layout()
plt.show()
if __name__ == "__main__":
target_url = "https://www.python.org"
print(f"extracting links from {target_url}...")
links = extract_links(target_url)
print(f"found {len(links)} links")
df, domain_counts, extension_counts = analyze_links(links)
visualize_data(domain_counts, extension_counts)
# 保存结果
df.to_csv('extracted_links.csv', index=false)
print("analysis complete. results saved to extracted_links.csv")
5.3 代码解读与分析
extract_links函数:
- 使用requests获取网页内容
- 使用beautifulsoup解析html
- 提取所有标签的href属性
- 将相对url转换为绝对url
analyze_links函数:
- 使用pandas创建dataframe存储链接数据
- 解析url的各个组件(域名、路径、扩展名)
- 统计域名和文件类型的出现频率
visualize_data函数:
- 使用matplotlib创建可视化图表
- 显示域名分布和文件类型分布
主程序:
- 指定目标url
- 调用上述函数完成整个流程
- 保存结果到csv文件
6. 实际应用场景
6.1 网站地图生成
自动提取网站所有链接,生成xml格式的网站地图,帮助搜索引擎索引网站内容。
6.2 竞争分析
分析竞争对手网站的链接结构,了解其内容策略和外链建设情况。
6.3 内容审计
检查网站中的死链、错误链接或不符合规范的链接。
6.4 安全扫描
识别网站中可能存在的敏感信息泄露(如管理后台链接)。
6.5 学术研究
收集网络数据用于社会学、传播学等领域的网络分析研究。
总结:未来发展趋势与挑战
发展趋势
- ai增强的解析:结合机器学习提高html解析的鲁棒性
- 实时爬取:流式处理技术的应用
- 分布式爬虫:处理大规模网站的高效方法
- 无头浏览器集成:更好处理javascript渲染的页面
主要挑战
- 反爬虫技术:越来越多的网站采用复杂反爬措施
- 法律合规:数据采集的合法性和道德问题
- 动态内容:单页应用(spa)带来的解析困难
- 数据质量:从非结构化数据中提取准确信息的挑战
附录:常见问题与解答
q1: 如何处理javascript动态加载的内容?
a: beautifulsoup只能解析静态html,对于js动态内容,可以考虑:
- 使用selenium等浏览器自动化工具
- 分析网站api直接获取数据
- 使用requests-html等支持js渲染的库
q2: 爬取网站时如何避免被封禁?
a: 建议采取以下措施:
- 设置合理的请求间隔
- 轮换user-agent头部
- 使用代理ip池
- 遵守robots.txt规则
- 尽量在非高峰时段爬取
q3: 提取的链接数据如何存储和分析?
a: 常见方案包括:
- 存储到csv/json文件
- 导入数据库(mysql, mongodb)
- 使用pandas进行数据分析
- 使用networkx进行网络分析
q4: beautifulsoup和scrapy有什么区别?
a: 主要区别:
- beautifulsoup是html解析库,专注于解析和提取
- scrapy是完整爬虫框架,包含调度、下载、处理等全套功能
- 小型项目用beautifulsoup+requests足够,大型项目建议用scrapy
以上就是python使用beautifulsoup实现网页链接的提取与分析的详细内容,更多关于python beautifulsoup网页链接的资料请关注代码网其它相关文章!





发表评论