迭代器(iterator)是一种常见的设计模式,它提供了一种统一的访问集合元素的方式,同时隐藏了集合的内部实现细节。
注意⚠️:蓝色为继承、黄色为接口实现。
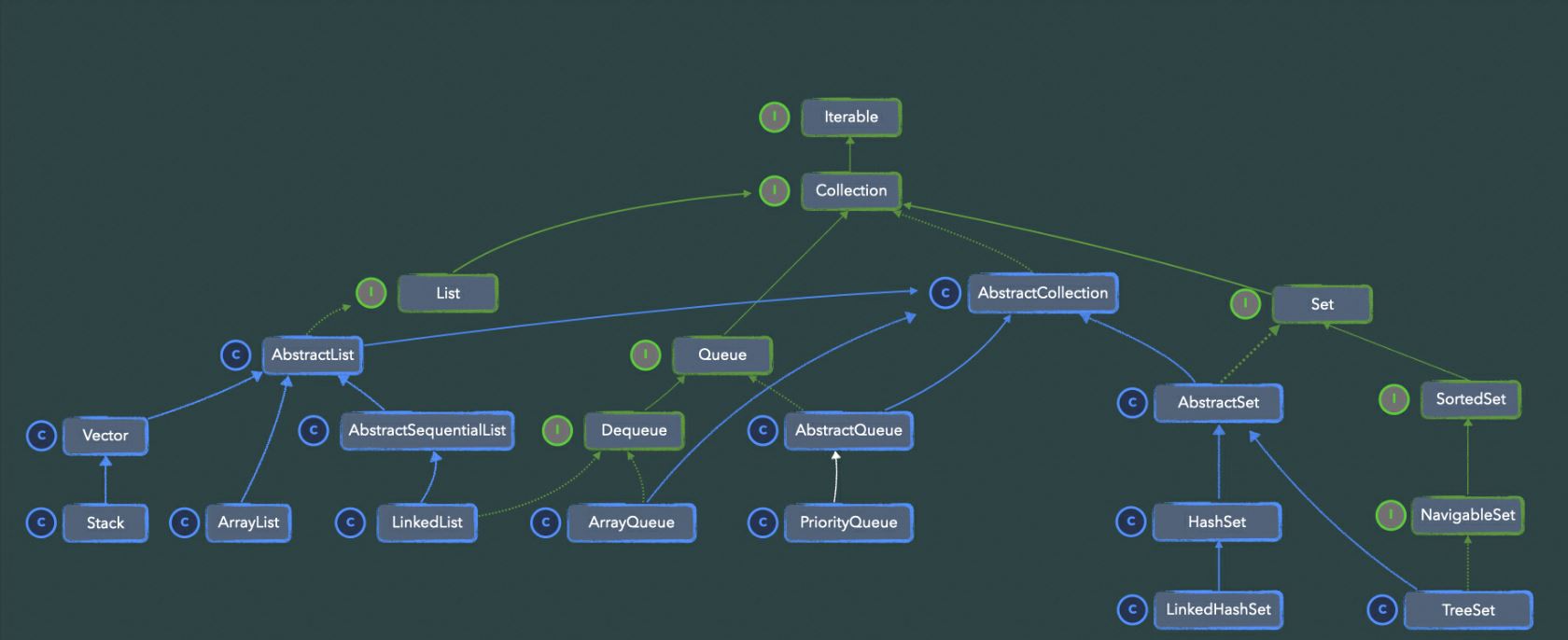
由上图可知:
- 1、 在集合的顶端为iterable接口。
- 2、对于abstractlist<e> extends abstractcollection<e>,两者均属于抽象类分别实现list接口和collection接口。而list接口继承于collection接口。
- 3、关于其他子实现均实现abstractlist,abstractcollection。
- 4、对于queue接口。和list一样,继承collection接口。
1、迭代器(iterator)
迭代器是一种对象,它允许你按顺序访问一个聚合对象(如列表、树、图等)中的元素,而无需暴露集合的内部结构。
1.1、结构
关于collection接口,继承于iterable接口。
java 的集合框架(如list、set)均实现了iterator接口,通过iterator()方法返回迭代器:
代码示例如下:
public interface collection<e> extends iterable<e> {}
public interface iterable<t> {
iterator<t> iterator();
}通过迭代器模式,可以将集合的遍历逻辑与集合本身的实现解耦,从而提高代码的灵活性和可维护性。
1.2、常用方法
它通常包含以下核心方法:
- hasnext():判断是否还有下一个元素。
- next():获取下一个元素。
- remove()(可选):删除当前元素。
代码示例:
list<string> list = arrays.aslist("a", "b", "c");
iterator<string> iterator = list.iterator();
while (iterator.hasnext()) {
system.out.println(iterator.next());
}
1.3、本质
迭代器被归类java设计模式里面的行为型设计模式(behavioral design pattern),定义了对象之间的交互方式。
它的核心思想是:
解耦遍历逻辑与数据结构,使客户端无需关心数据的存储方式即可统一访问元素。
1、解耦集合与遍历逻辑
- 传统方式:直接通过索引遍历集合(如数组),客户端需要知道集合的内部结构(如数组长度)。
- 迭代器方式:客户端只需调用hasnext()和next(),无需关心集合是数组、链表还是树。
2、统一访问接口
- 不同类型的集合(如list、set、map)可以提供自己的迭代器实现,客户端通过统一的iterator接口操作。
3、支持多种遍历方式
- 迭代器可以定义不同的遍历策略(如正向、逆向、深度优先搜索等),而集合本身不需要修改。
4、提高代码复用性
- 迭代器模式将遍历逻辑抽象为独立的对象,可以被多个集合复用。
1.4、自定义迭代器
// 自定义集合
class mycollection implements iterable<integer> {
private list<integer> data = new arraylist<>();
public void add(int value) {
data.add(value);
}
@override
public iterator<integer> iterator() {
return new myiterator();
}
// 自定义迭代器
private class myiterator implements iterator<integer> {
private int index = 0;
@override
public boolean hasnext() {
return index < data.size();
}
@override
public integer next() {
return data.get(index++);
}
}
}
总结

2、迭代器模式的组成
2.1、迭代器模式角色
1、抽象迭代器(iterator):
定义了遍历聚合对象所需的方法,包括hashnext()和next()方法等,用于遍历聚合对象中的元素。
2、具体迭代器(concrete iterator):
它是实现迭代器接口的具体实现类,负责具体的遍历逻辑。它保存了当前遍历的位置信息,并可以根据需要向前或向后遍历集合元素。
3、抽象聚合器(aggregate):
一般是一个接口,提供一个iterator()方法,例如java中的collection接口,list接口,set接口等。
4、具体聚合器(concreteaggregate):
就是抽象容器的具体实现类,比如list接口的有序列表实现arraylist,list接口的链表实现linklist,set接口的哈希列表的实现hashset等。
2.2、uml 类图
如下所示:

2.3、举例
下面以班级名单为例,解释一下迭代器模式。
- 抽象迭代器:studentiterator
- 具体迭代器:studentlistiterator
- 抽象聚合器:studentaggregate
- 具体聚合器:classlist
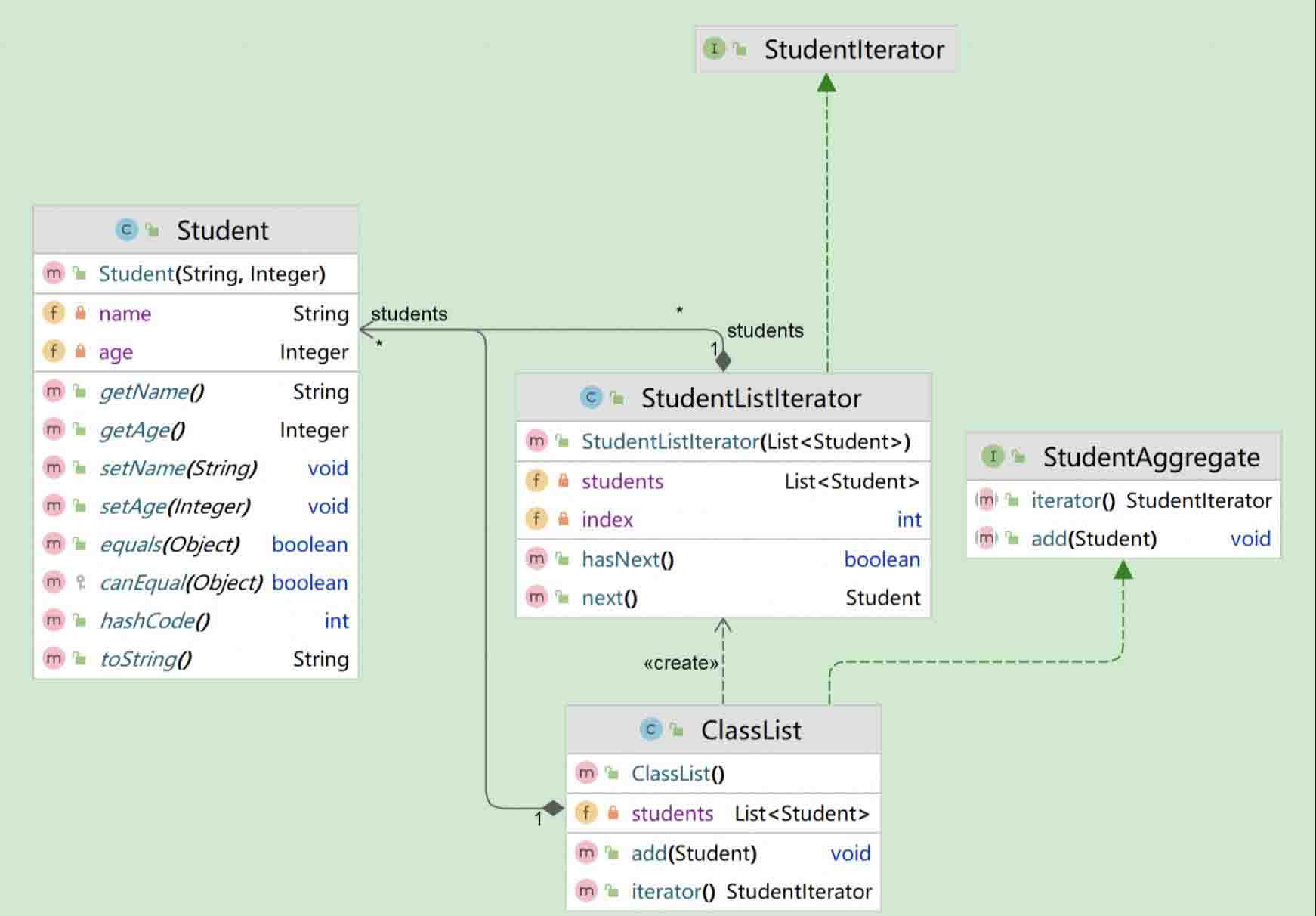
1、student——学生实体类
首先定义一个学生类,用来表示学生信息。
如下图所示:
/**
* @author created by njy on 2023/6/25
* 学生实体类
*/
@data
public class student {
private string name;
private integer age;
public student(string name,integer age){
this.age=age;
this.name=name;
}
}2、studentiterator——抽象迭代器(iterator)
创建一个抽象迭代器(学生迭代器)并继承iterator接口(java.util包下的iterator)。
如下所示:
import java.util.iterator;
/**
* @author created by njy on 2023/6/25
* 抽象迭代器(iterator):学生迭代器
* 实现iterator接口
* 负责定义访问和遍历元素的接口,例如提供hasnext()和next()方法。
*/
public interface studentiterator extends iterator<student> {
}3、studentlistiterator——具体迭代器(concrete iterator)
在这个具体迭代器中,实现抽象迭代器,重写hashnext()和next()方法。
如下所示:
/**
* @author created by njy on 2023/6/25
* 具体迭代器(concrete iterator):
* 实现抽象迭代器定义的接口,负责实现对元素的访问和遍历。
*/
public class studentlistiterator implements studentiterator{
private list<student> students;
private int index;
public studentlistiterator(list<student> students) {
this.students = students;
this.index = 0;
}
//检查是否还有下一个元素
@override
public boolean hasnext() {
return (index < students.size());
}
//返回下一个元素
@override
public student next() {
if (!hasnext()) {
throw new nosuchelementexception();
}
student student = students.get(index);
index++;
return student;
}
}4、studentaggregate——抽象聚合器(aggregate)
定义一个抽象聚合器,并定义一个iterator()方法,用于创建具体的迭代器对象。
如下所示:
/**
* @author created by njy on 2023/6/25
* 抽象聚合器(aggregate):学生聚合器
* 提供创建迭代器的接口,例如可以定义一个iterator()方法。
*/
public interface studentaggregate {
//用于创建具体的迭代器对象
studentiterator iterator();
void add(student student);
}5、classlist——具体聚合器(concrete aggregate)
实现抽象聚合器定义的接口,负责创建具体的迭代器对象。
如下所示:
/**
* @author created by njy on 2023/6/25
* 具体聚合器(concreteaggregate):班级列表
* 实现抽象聚合器定义的接口,负责创建具体的迭代器对象,并返回该对象。
*/
public class classlist implements studentaggregate{
private list<student> students = new arraylist<>();
//创建迭代器对象
@override
public studentiterator iterator() {
return new studentlistiterator(students);
}
//向班级名单中添加学生信息
@override
public void add(student student) {
students.add(student);
}
}6、testiterator
/**
* @author created by njy on 2023/6/25
* 迭代器模式测试类
*/
@springboottest
public class testiterator {
@test
void testiterator(){
classlist classlist = new classlist();
// 添加学生信息
classlist.add(new student("张三", 18));
classlist.add(new student("李四", 19));
classlist.add(new student("王五", 20));
// 获取迭代器,遍历学生信息
studentiterator iterator = classlist.iterator();
while(iterator.hasnext()) {
student student = iterator.next();
system.out.println("学生姓名:" + student.getname() + ",学生年龄:" + student.getage());
}
}
}
输出:
学生姓名:张三,学生年龄:18
学生姓名:李四,学生年龄:19
学生姓名:王五,学生年龄:203、实际应用
1、集合框架中的迭代器:
在java中,集合包括list、set、map等等,每个集合类中都提供了一个获取迭代器的方法,例如list提供的iterator()方法、set提供的iterator()方法等等。
通过获取对应的迭代器对象,可以对集合中的元素进行遍历和访问。
代码示例:
import java.util.*;
public class collectioniteratorexample {
public static void main(string[] args) {
list<string> list = arrays.aslist("a", "b", "c");
iterator<string> iterator = list.iterator();
while (iterator.hasnext()) {
system.out.println(iterator.next());
}
}
}
2、jdbc中的resultset对象:
在java中,如果需要对数据库中的数据进行遍历和访问,可以使用jdbc操作数据库。
jdbc中,查询结果集使用resultset对象来表示,通过使用resultset的next()方法,就可以像使用迭代器一样遍历和访问查询结果中的数据。
代码示例:
import java.sql.*;
import java.util.iterator;
public class jdbciteratorexample {
public static void main(string[] args) {
string url = "jdbc:mysql://localhost:3306/mydb";
string user = "root";
string password = "password";
try (connection conn = drivermanager.getconnection(url, user, password);
statement stmt = conn.createstatement();
resultset rs = stmt.executequery("select id, name from users")) {
// 使用自定义迭代器遍历 resultset
iterator<user> useriterator = new resultsetiterator<>(rs);
while (useriterator.hasnext()) {
user user = useriterator.next();
system.out.println(user);
}
} catch (sqlexception e) {
e.printstacktrace();
}
}
// 自定义迭代器
static class resultsetiterator<t> implements iterator<t> {
private final resultset rs;
private final rowmapper<t> rowmapper;
public resultsetiterator(resultset rs) throws sqlexception {
this.rs = rs;
this.rowmapper = (rs1) -> {
user user = new user();
user.setid(rs1.getint("id"));
user.setname(rs1.getstring("name"));
return user;
};
}
@override
public boolean hasnext() throws sqlexception {
return rs.next();
}
@override
public t next() throws sqlexception {
return rowmapper.maprow(rs);
}
}
// 辅助类
static class user {
private int id;
private string name;
// getters and setters
@override
public string tostring() {
return "user{" + "id=" + id + ", name='" + name + '\'' + '}';
}
}
interface rowmapper<t> {
t maprow(resultset rs) throws sqlexception;
}
}
3、文件读取:
在java中,我们可以使用bufferedreader类来读取文本文件。bufferedreader类提供了一个方法readline()来逐行读取文件内容。
bufferedreader在内部使用了迭代器模式来逐行读取文本文件的内容。
代码示例:
import java.io.*;
import java.util.iterator;
public class fileiteratorexample {
public static void main(string[] args) {
string filepath = "example.txt";
try (filereader reader = new filereader(filepath);
bufferedreader bufferedreader = new bufferedreader(reader)) {
// 使用自定义迭代器遍历文件
iterator<string> lineiterator = new lineiterator(bufferedreader);
while (lineiterator.hasnext()) {
system.out.println(lineiterator.next());
}
} catch (ioexception e) {
e.printstacktrace();
}
}
// 自定义迭代器
static class lineiterator implements iterator<string> {
private final bufferedreader reader;
private string nextline;
public lineiterator(bufferedreader reader) throws ioexception {
this.reader = reader;
this.nextline = reader.readline();
}
@override
public boolean hasnext() {
try {
return nextline != null || (nextline = reader.readline()) != null;
} catch (ioexception e) {
throw new runtimeexception("读取文件时出错", e);
}
}
@override
public string next() {
if (!hasnext()) {
throw new illegalstateexception("没有更多行");
}
string currentline = nextline;
try {
nextline = reader.readline();
} catch (ioexception e) {
throw new runtimeexception("读取文件时出错", e);
}
return currentline;
}
}
}
4、优缺点
4.1、优点
1、隐藏集合实现细节
- 客户端无需知道集合是链表、数组还是其他结构,只需通过迭代器操作。
2、支持并发修改
- 某些迭代器(如 java 的concurrenthashmap的弱一致性迭代器)可以处理并发修改,避免concurrentmodificationexception。可参考:集合中的并发修改异常及处理方式
3、灵活的遍历方式
- 例如,可以为树结构定义深度优先或广度优先的迭代器。
4、代码简洁性
- 使用迭代器可以避免重复编写遍历逻辑(如手动管理索引)。
4.2、缺点
- 增加了代码复杂度:需要额外定义迭代器类。
- 性能开销:对于简单集合(如数组),直接遍历可能更高效。
总结
迭代器模式是 java 集合框架的核心设计之一,也是许多高级数据结构(如树、图)遍历的基础。通过理解其原理,可以更高效地设计和实现符合要求的集合类。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。





发表评论