常用的正则表达式匹配符
[a-z] //匹配 a到z任意一个字符
[a-z] //匹配 a到z任意一个字符
[0-9] //匹配 0到9任意一个数字
[^a-z] //匹配 不是a到z任意一个字符
[^a-z] //匹配 不是a到z任意一个字符
[^0-9] //匹配 不是0到9任意一个数字
[abcd] //匹配 abcd中的任意一个字符
abc //匹配 abc字符串区分大小写
(?i)abc //匹配 abc字符串不区分大小写
a(?i)bc //匹配 abc字符串后面的bc不区分大小写
a((?i)b)c //匹配 abc字符串中间的b不区分大小写
\\d //匹配数字字符,等价于 [0-9]。
\\d //匹配非数字字符,等价于 [^0-9]
\\w //匹配字母、数字或下划线,等价于 [a-za-z0-9_]
\\w //匹配非字母、数字或下划线,等价于 [^a-za-z0-9_]
\\s //匹配空白字符(包括空格、制表符、换行符等)
\\s //匹配非空白字符(包括空格、制表符、换行符等)\s的反义
. //匹配出\n外的任意字符,如果向匹配.字符本身,可以使用\\.
| //选择匹配符,例如 ab|bc 表示匹配ab或者bc的字符串
* //指定字符重复0次或n次(无要求)零到多 示例 (abc)* 匹配输入 abc,abcabcabc
+ //指定字符重复1次或n次(至少一次) 示例 m+(abc)* 以至少1个m开头,后接任意个abc的字符串 匹配输入 m,mabc,mabcabc,mmabc
? //指定字符重复0次或1次(最多一次) 示例 m+abc? 以至少一个m开头,后接ab或者abc的字符串 匹配输入 mab,mabc,mmmab,mmabc
{n} //只能输入n个字符 [abcd]{3} 由abcd中字母组成的任意长度为3的字符串 匹配输入 abc,dbc,adc
{n,} //指定至少n个匹配 示例 [abcd]{3,} 说明:由abcd中字母组成的任意长度不小于3的字符串
{n,m} //指定至少n个但不多于m个匹配 示例 [abcd]{3,5} 说明:由abcd中字母组成的任意长度不小于3,不大于5的字符串
^ //指定起始字符 示例 ^[0-9]+[a-z]* 说明:以至少1个数字开头,后接任意个小写字母的字符串 匹配输入:123,6aa,555edf
$ //指定结束符 示例 ^[0-9]\\-[a-z]+$ 说明:以1个数字开头后连接字符 "-" ,并以至少1个小写字母结尾的字符串 匹配输入:1-a
\\b //匹配目标字符串的边界 示例 han\\b 说明:这里说的字符串边界指的是子串间有空格,或者是目标字符串的结束文字 匹配输入:asfasdffate asdfafate
\\b //匹配目标字符串的非边界 示例 han\\b 说明:和\b的含义刚刚相反 匹配输入:fateafadsfafa fateafadsfasdf
(pattern) //非命名捕获。捕获匹配的子字符串,编号为零的第一个捕获的是由整个正则表达式模式匹配的文本,其他捕获结果则根据左括号的顺序从1开始自动编号
(?<name> pattern) //命名捕获。将匹配的子字符串捕获到一个组名称或编号名称中,用于name的字符串不能包含任何标点符号,并且不能以数字开头
(?:pattern) //匹配 pattern 但不捕获该匹配的子表达式,即它是一个非捕获匹配,不存储供以后使用的匹配。这对于用“or”字符(||)组合模式部件的情况很有用。例如,'industr'(?:y|lies)是对‘industry|industries'更经济的表达式
(?=pattren) //它是一个非捕获匹配。例如,‘windows(?=95|98|nt|2000)'匹配“windows 2000”中的"windows",但不匹配“windows 3.1”中的“windows”
(?!pattren) //该表达式匹配不处于匹配 pattren 的字符串的起始点的搜索字符串。它是一个非捕获匹配。例如,‘windows(?!95|98|nt|2000)'匹配“windows 3.1”中的"windows",但不匹配“windows 2000”中的“windows”
//注意点:java默认是遵循贪婪匹配的,比如一个字符串为 2009 编写的正则表达式为 \\d+ 最后在程序执行后 结果为 2009 (优先匹配到数量多的 即2009)
//如果不想遵循贪婪匹配,可以在对应的正则表达式后添加?符号 例如 \\d+? 匹配上面的结果就为2 0 0 9
//当创建pattern对象时,指定pattern.case_insensitive,表示匹配字符串是不区分字母大小写的
pattern pattern = pattern.compile(regstr,pattern.case_insensitive);
matcher matcher = pattern.matcher(str);
//非命名分组和命名分组的代码验证
public class test {
public static void main(string[] args) {
string str = "mioyuimugi1989fateafadsfasdf1999 ";
//非命名分组
// string regstr = "(\\d\\d)(\\d\\d)";//匹配连续的4个数字
//命名分组
string regstr = "(?<g1>\\d\\d)(?<g2>\\d\\d)";//匹配连续的4个数字
pattern pattern = pattern.compile(regstr);
matcher matcher = pattern.matcher(str);
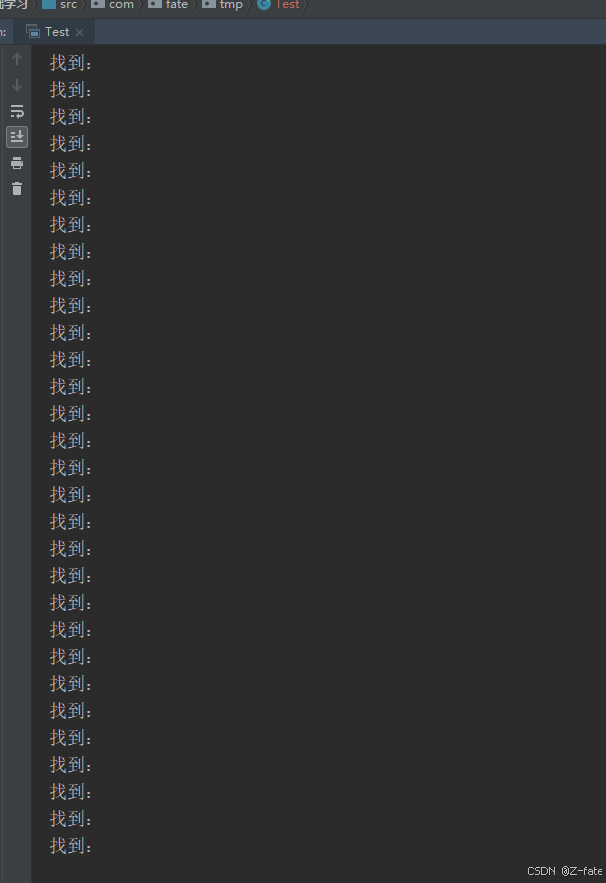
while(matcher.find()) {
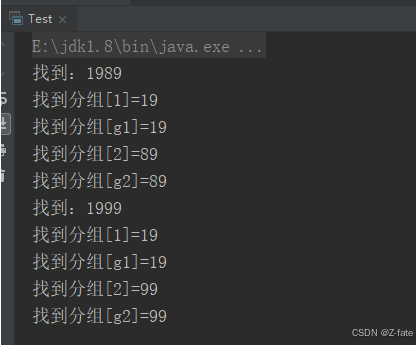
system.out.println("找到:"+matcher.group(0));
system.out.println("找到分组[1]="+matcher.group(1));
system.out.println("找到分组[g1]="+matcher.group("g1"));
system.out.println("找到分组[2]="+matcher.group(2));
system.out.println("找到分组[g2]="+matcher.group("g2"));
}
}
}
运行结果截图:
public class test {
public static void main(string[] args) {
//非捕获分组 (?:pattern) 代码演示如下
//不能使用 matcher.group(1)
string str = "轻音少女2009 轻音少女2010 轻音少女2011";
string regexp = "轻音少女(?:2009|2010|2011)";
pattern pattern = pattern.compile(regexp);
matcher matcher = pattern.matcher(str);
while (matcher.find()) {
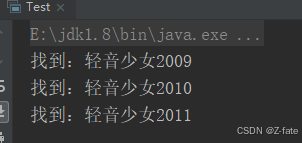
system.out.println("找到:"+matcher.group(0));
}
}
}
运行结果截图:
public class test {
public static void main(string[] args) {
//非捕获分组 (?!pattern) 代码演示如下
//不能使用 matcher.group(1)
string str = "轻音少女2009 轻音少女2010 轻音少女2011 轻音少女2025";
string regexp = "轻音少女(?!2009|2010|2011)";
pattern pattern = pattern.compile(regexp);
matcher matcher = pattern.matcher(str);
while (matcher.find()) {
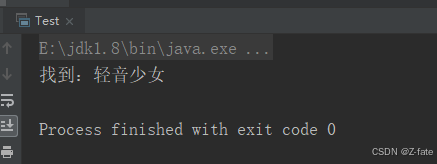
system.out.println("找到:"+matcher.group(0));//该模式下匹配到的是轻音少女2025
}
}
}
运行结果截图:
public class test {
public static void main(string[] args) {
//默认贪婪匹配和非贪婪匹配的区别和演示
string str = "轻音少女2009 轻音少女2010 轻音少女2011 轻音少女2025";
string regexp = "\\d+";//默认贪婪匹配
pattern pattern = pattern.compile(regexp);
matcher matcher = pattern.matcher(str);
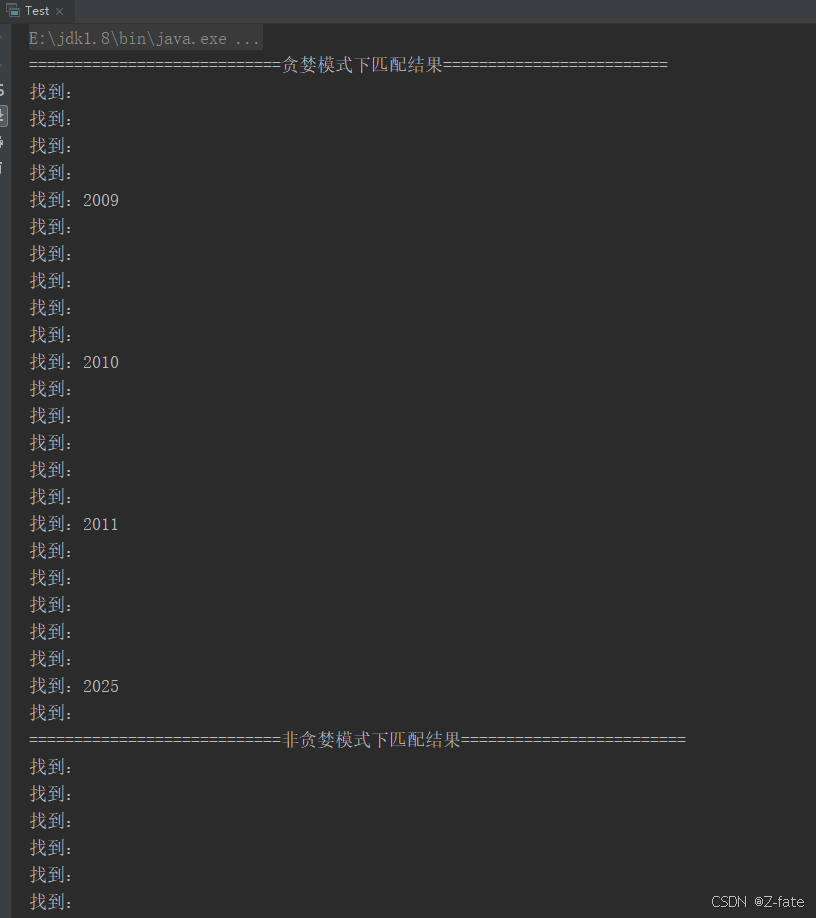
system.out.println("============================贪婪模式下匹配结果=========================");
while (matcher.find()) {
system.out.println("找到:"+matcher.group(0));
}
regexp = "\\d+?";//改成了非贪婪匹配
pattern = pattern.compile(regexp);
matcher = pattern.matcher(str);
system.out.println("============================非贪婪模式下匹配结果=========================");
while (matcher.find()) {
system.out.println("找到:"+matcher.group(0));
}
}
}
运行结果截图:

public class test {
public static void main(string[] args) {
//默认贪婪匹配和非贪婪匹配的区别和演示
string str = "轻音少女2009 轻音少女2010 轻音少女2011 轻音少女2025";
string regexp = "\\d*";//默认贪婪匹配
pattern pattern = pattern.compile(regexp);
matcher matcher = pattern.matcher(str);
system.out.println("============================贪婪模式下匹配结果=========================");
while (matcher.find()) {
system.out.println("找到:"+matcher.group(0));
}
regexp = "\\d*?";//改成了非贪婪匹配
pattern = pattern.compile(regexp);
matcher = pattern.matcher(str);
system.out.println("============================非贪婪模式下匹配结果=========================");
while (matcher.find()) {
system.out.println("找到:"+matcher.group(0));
}
}
}
运行结果截图:
正则表达式常用的类
java.util.regex 包主要包括以下三个类 pattern类、matcher类和patternsyntaxexception
pattern类
- pattern对象时一个正则表达式对象,pattern类没有公共构造方法,要构建一个pattern对象,需要调用其公共静态方法,它返回一个pattern对象,该方法结束一个正则表达式作为它的一个参数,比如:pattern p = pattern.compile(pattern);
matcher类
- mattcher对象时对输入字符串进行解释和匹配的引擎。与pattern类一样,matcher也没有公共构造方法,你需要调用pattern对象的matcher方法来获得一个matcher对象
patternsyntaxexception类
- patternsyntaxexception是一个非强制异常类,它表示一个正则表达式模式中的语法错误。
分组、捕获、反向引用
分组
- 我们可以用圆括号组成一个比较复杂的匹配模式,那么一个圆括号的部分我们可以看作一个子表达式/一个分组
捕获
- 把正则表达式中子表达式/分组匹配的内容,保存到内存中以数字编号或显式命名的组里,方便后面引用,从左向右,以分组的左括号为标志,第一个出现的分组的组号为1,第二个为1,以此类推。组0代表的是整个正则式。
反向引用
- 圆括号的内容被捕获后,可以在这个括号后被使用,从而写出一个比较实用的匹配模式,这个我们称之为方向引用,这种引用即可以是在正则表达式内部,也可以是在正则表达式外部,内部反向引用\分组号,外部反向引用 $分组号。
反向引用题型案例
要匹配两个连续的相同的数字。
string reg = "(\\d)\\1";
要匹配五个连续的相同数字。
string reg = "(\\d)\\1{4}";要匹配个位与千位相同,十位与百位相同的数 5225,1551。
string reg = "(\\d)(\\d)\\2\\1";
请在字符串中检索商品编号,形式如:12321-333999111这样的号码,要求满足前面是一个五位数,然后一个-号,然后是一个九位数,连续的每三位要相同。
string reg = "\\d{5}-(\\d)\\1{2}(\\d)\\2{2}(\\d)\\3{2}";
正则表达式应用实例
要求编写符合下面要求格式的正则表达式
汉字
string regexp ="^[\\u4e00-\\u9fff]+$";//注意编码,该正则表达式是在utf-8上实现的
邮政编码
要求:是1-9开头的一个六位数。比如:123890
string regexp = "^[1-9]\\d{5}$";qq号码
要求:是1-9开头的一个(5位数-10位数)比如:12389,1345687,187698765
string regexp = "^[1-9]\\d{4,9}$";手机号码
要求:必须以13,14,15,18 开头的11位数,比如 13588889999
string regexp = "^1(?:3|4|5|8)\\d{9}$";检查请求的url地址是否符合格式
public class test { public static void main(string[] args) { string url = "https://www.bilibili.com/video/bv1eq4y1e79w?spm_id_from=333.788.player.switch&vd_source=008f4bb261040622b4b9810f1577d84a&p=17"; /** * 思路: * 1,最前面的可能是 https:// 或http:// 或没有 -> ((http|https)://)? * 2,中间www.bilibili.com 可以拆分成两个部分 即 xxx. 和 后面的 xxx * 其中xxs包含的字符可能有数字,大小写字母,下划线和- 前后两个部分都可能含有一个或多个 -> ([\\w-]\.)+([\\w-])+ * 3, 最后的一个部分以/开头,后面包含的字符可能有数字,下划线,大小写英语和一些特殊字符(包括?.#=-%&) */ string regexp = "((http|https)://)?([\\w-]+\\.)+[\\w-]+(\\/[\\w-/?.#%&=]*)?";//注意当[.?]情况时.?符号匹配的就是本身 pattern pattern = pattern.compile(regexp); matcher matcher = pattern.matcher(url); if (matcher.find()) { system.out.println("满足格式="+matcher.group(0)); } else { system.out.println("不满足格式"); } //以下为整体匹配 system.out.println(pattern.matches(regexp,url)); } }注意当[.?]情况时.?符号匹配的就是本身
运行结果截图:

6. 经典的结巴程序
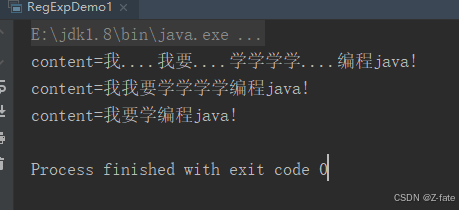
把类似:“我…我要…学学学学…编程java!”通过正则表达式 修改成"我要学编程java"
public class regexpdemo1 { public static void main(string[] args) { string content = "我....我要....学学学学....编程java!"; system.out.println("content="+content); //1 去除所有的. 使用\\. string reg = "\\."; content = content.replaceall(reg,""); system.out.println("content="+content); //2 (1) 找到所有的叠词 (.)\\1+ // (2) 对找到的引用进行反向引用替换$1 content = pattern.compile("(.)\\1+").matcher(content).replaceall("$1"); //或者如下面一行代码 //content = content.replaceall("(.)\\1+","$1"); system.out.println("content="+content); } }运行结果截图:
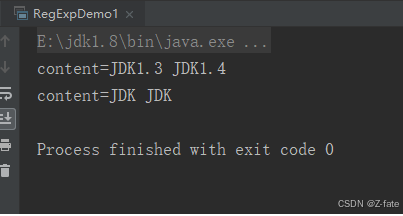
7. 将该"jdk1.3 jdk1.4"中的jdk1.3和jdk1.4全面替换成jdk
public class regexpdemo1 {
public static void main(string[] args) {
string content = "jdk1.3 jdk1.4";
system.out.println("content="+content);
content = content.replaceall("(jdk)(?:1.3|1.4)","$1");
system.out.println("content="+content);
}
}
运行结果截图:
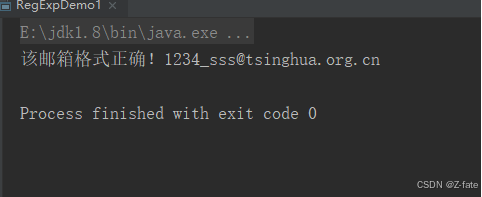
验证电子邮件格式是否合法(要求如下)
只能有一个@
@前面是用户名,可以是a-z,a-z,0-9 _字符
@后面的是域名,并且域名只能是英语字母,比如sohu.com 或者tsinghua.org.cn
写出对应的正则表达式,验证输入的字符串是否满足规则
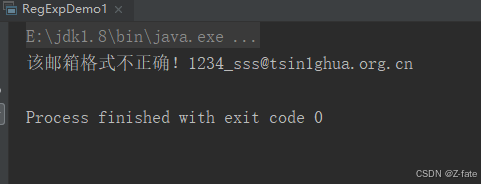
public class regexpdemo1 { public static void main(string[] args) { //验证邮箱格式是否正确 //1. 只能有一个@ //2. @前面是用户名,可以是a-z,a-z,0-9 _字符 //3. @后面的是域名,并且域名只能是英语字母,比如sohu.com 或者tsinghua.org.cn string regexp = "^[\\w-]+@([a-za-z]+\\.)+[a-za-z]+$";//因为是进行匹配,建议将前后的定位符加上 string emailstr = "1234_sss@tsinghua.org.cn"; if (emailstr.matches(regexp)) {//该方法是进行整体匹配的 system.out.println("该邮箱格式正确!"+emailstr); } else { system.out.println("该邮箱格式不正确!"+emailstr); } } }运行结果截图:
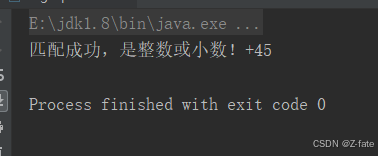
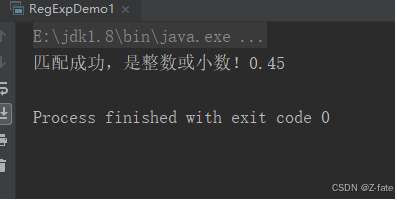
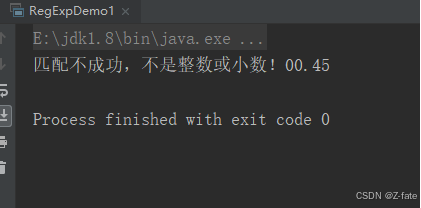
要求验证是不是整数或者小数
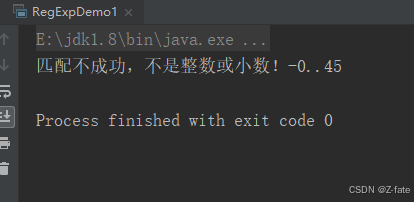
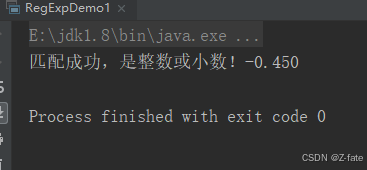
- 注意:该题要考虑正数和负数 比如:123 +123 -345 34.89 -87.9 -0.001 0.45 等 不符合要的数据实例 --123 ++123 0035 01.01
public class regexpdemo1 {
public static void main(string[] args) {
//要求验证是不是整数或者小数
//注意:该题要考虑正数和负数 比如:123 -345 34.89 -87.9 -0.001 0.45 等
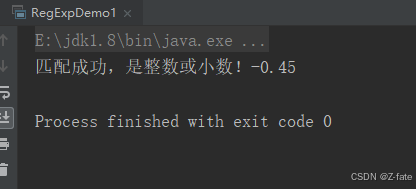
string numstr = "+45";
string regexp = "^[-+]?([1-9]\\d*|0)(\\.\\d+)?$";
if (numstr.matches(regexp)) {
system.out.println("匹配成功,是整数或小数!"+numstr);
} else {
system.out.println("匹配不成功,不是整数或小数!"+numstr);
}
}
}
运行结果截图:
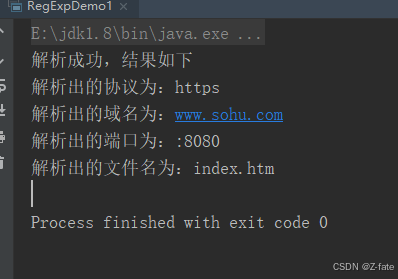
对一个url进行解析 例如 https://www.sohu.com:8080/abc/index.htm
. 要求得到的协议是什么? http
域名是什么? ww.sohu.com
端口是什么? 8080
文件名是什么?index.htm
public class regexpdemo1 { public static void main(string[] args) { string url = "https://www.sohu.com:8080/abc/index.htm"; //如果有其他情况或者一些特殊字符什么的,可以对正则表达式内容进行适当的调整 string regexp = "^(?<g1>[a-za-z]+)://(?<g2>([\\w-]+\\.)+[\\w-]+)(?<g3>:[\\d]{1,5})/[\\w-/?.#%&=]*/(?<g4>[\\w-]+(\\.[\\w]+))?$"; pattern pattern = pattern.compile(regexp); matcher matcher = pattern.matcher(url); if (matcher.find()) { system.out.println("解析成功,结果如下"); system.out.println("解析出的协议为:"+matcher.group("g1")); system.out.println("解析出的域名为:"+matcher.group("g2")); system.out.println("解析出的端口为:"+matcher.group("g3")); system.out.println("解析出的文件名为:"+matcher.group("g4")); } else { system.out.println("解析失败"); } } }运行结果截图:
总结
到此这篇关于javase正则表达式用法总结大全的文章就介绍到这了,更多相关javase正则表达式内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!



发表评论