clip(contrastive language–image pretraining)是 openai 提出的 多模态模型,可以将图像和文本映射到同一个嵌入空间中,从而实现图文匹配、零样本分类、图文检索等任务。
虽然 openai 没有单独发布一个叫 clip 的官方 python 库,但社区版本如 open_clip, clip from openai, clip-as-service 等都被广泛使用。以下主要介绍:
- openai 官方 clip
- 社区版
open-clip(支持更多模型)
1. 安装 openai 官方 clip
pip install git+https://github.com/openai/clip.git
依赖:torch、numpy, pil
2. 快速使用示例
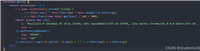
import clip
import torch
from pil import image
# 加载模型和预处理方法
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("vit-b/32", device=device)
# 加载图像并预处理
image = preprocess(image.open("cat.jpg")).unsqueeze(0).to(device)
# 编写文本描述
text = clip.tokenize(["a photo of a cat", "a photo of a dog"]).to(device)
# 提取特征并计算相似度
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
logits_per_image, logits_per_text = model(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
print("label probabilities:", probs)
3. 模型选项
支持的模型有:
"vit-b/32":最快,最常用"vit-b/16":更大更准"rn50"、"rn101":基于 resnet
4. 文本编码
text = ["a photo of a banana", "a dog", "a car"]
tokens = clip.tokenize(text).to(device)
with torch.no_grad():
text_features = model.encode_text(tokens)
5. 图像编码
from pil import image
image = image.open("example.jpg")
image_input = preprocess(image).unsqueeze(0).to(device)
with torch.no_grad():
image_features = model.encode_image(image_input)
6. 相似度比较
import torch.nn.functional as f # 余弦相似度 similarity = f.cosine_similarity(image_features, text_features) print(similarity)
7. 零样本图像分类
labels = ["a dog", "a cat", "a car"]
text_inputs = clip.tokenize([f"a photo of {label}" for label in labels]).to(device)
with torch.no_grad():
text_features = model.encode_text(text_inputs)
image_features = model.encode_image(image)
# 归一化
image_features /= image_features.norm(dim=-1, keepdim=true)
text_features /= text_features.norm(dim=-1, keepdim=true)
# 相似度得分
logits = (image_features @ text_features.t)
pred = logits.argmax().item()
print(f"predicted label: {labels[pred]}")
8. 与其他库对比
| 特性 | clip | blip / flamingo | bert / gpt |
|---|---|---|---|
| 图文对齐 | 是 | 是 | 否 |
| 多模态能力 | 强(图像 + 文本) | 更强(支持生成) | 弱 |
| 零样本能力 | 强 | 强 | 无 |
| 适合任务 | 图文检索、匹配、分类 | 生成描述、问答、vqa | 语言任务 |
9. 更强大:open_clip
open_clip 是社区支持的更强版本,支持更多预训练模型(如 laion 提供的):
pip install open_clip_torch
import open_clip
model, preprocess, tokenizer = open_clip.create_model_and_transforms('vit-b-32', pretrained='laion2b_s34b_b79k')
10. 总结
| 功能 | 方法 |
|---|---|
| 加载模型 | clip.load() |
| 文本编码 | model.encode_text() |
| 图像编码 | model.encode_image() |
| 图文相似度 | model(image, text) 或余弦相似度 |
| 图像分类(零样本) | 文本描述嵌入后选最大相似度 |
| 支持模型 | "vit-b/32", "vit-b/16" 等 |
clip 是现代多模态 ai 模型的典范,可广泛应用于图像检索、图文分类、图像问答、跨模态搜索等场景。它在“零样本”条件下也能表现良好,是构建通用图文理解系统的强大工具。
到此这篇关于python中clip多模态模型的库的实现的文章就介绍到这了,更多相关python clip多模态模型内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!



发表评论