1.#{} 和 ${}的使用
1.1数据准备
1.1.1.mysql数据准备
(1)创建数据库:
create database mybatis_study default character set utf8mb4;
(2)使用数据库
-- 使⽤数据数据 use mybatis_study;
(3)创建用户表
-- 创建表[⽤⼾表] create table `user_info` ( `id` int ( 11 ) not null auto_increment, `username` varchar ( 127 ) not null, `password` varchar ( 127 ) not null, `age` tinyint ( 4 ) not null, `gender` tinyint ( 4 ) default '0' comment '1-男 2-⼥ 0-默认', `phone` varchar ( 15 ) default null, `delete_flag` tinyint ( 4 ) default 0 comment '0-正常, 1-删除', `create_time` datetime default now(), `update_time` datetime default now() on update now(), primary key ( `id` ) ) engine = innodb default charset = utf8mb4;
(4)添加用户信息
-- 添加⽤⼾信息 insert into mybatis_study.user_info( username, `password`, age, gender, phone ) values ( 'admin', 'admin', 18, 1, '18612340001' ); insert into mybatis_study.user_info( username, `password`, age, gender, phone ) values ( 'zhangsan', 'zhangsan', 18, 1, '18612340002' ); insert into mybatis_study.user_info( username, `password`, age, gender, phone ) values ( 'lisi', 'lisi', 18, 1, '18612340003' ); insert into mybatis_study.user_info( username, `password`, age, gender, phone ) values ( 'wangwu', 'wangwu', 18, 1, '18612340004' );
1.1.2.创建对应的实体类
实体类的属性名与表中的字段名⼀⼀对应
@data
public class userinfo {
private integer id;
private string username;
private string password;
private integer age;
private integer gender;
private string phone;
private integer deleteflag;
private date createtime;
private date updatetime;
}
注意:在实际开发中不管什么实体类都要设置删除标志、创建时间、修改时间
1.2 获取integer类型
1.2.1 #{}
mapper接口:
@mapper
public interface userinfomapper {
// 获取参数中的 userid
@select("select * from user_info where id = #{userid} ")
userinfo querybyid(@param("userid") integer id);
测试代码:
@slf4j
@springboottest //启动sring 容器
class userinfomappertest {
@test
void querybyid() {
userinfo result = userinfomapper.querybyid(8);
log.info(result.tostring());
}
}
运行结果:

通过日志可以发现,?进行占位,传的参数进行绑定到占位符。
1.2.2 ${}
mapper接口:
@mapper
public interface userinfomapper {
// 获取参数中的 userid
@select("select * from user_info where id = ${userid} ")
userinfo querybyid(@param("userid") integer id);
测试代码:
@slf4j
@springboottest //启动sring 容器
class userinfomappertest {
@test
void querybyid() {
userinfo result = userinfomapper.querybyid(8);
log.info(result.tostring());
}
}
运行结果:

通过日志可以发现,sql命令是完整的,因为,该方法是把字符串拼接在一起执行的。
1.3 获取string类型
1.3.1 #{}
mapper接口:
@mapper
public interface userinfomapper {
// 获取参数中的 username
@select("select * from user_info where username = #{username} ")
list<userinfo> querybyusername( string username);
测试代码:
@slf4j
@springboottest //启动sring 容器
class userinfomappertest {
@autowired
private userinfomapper usermapper;
@test
void querybyusername() {
usermapper.querybyusername("lisi");
}
}
运行结果:

通过日志可以发现,?进行占位,传的参数进行绑定到占位符。
1.3.2 ${}
mapper接口:
@mapper
public interface userinfomapper {
// 获取参数中的 username
@select("select * from user_info where username = ${username} ")
list<userinfo> querybyusername( string username);
测试代码:
@slf4j
@springboottest //启动sring 容器
class userinfomappertest {
@autowired
private userinfomapper usermapper;
@test
void querybyusername() {
usermapper.querybyusername("lisi");
}
}
运行结果:报错


从sql语句中明显的看到where username 后面的字符串没有引号,导致报错。
因为,${}直接把字符内容直接放进sql语句中而没有加单引号。
修改后的mapper接口:
@mapper
public interface userinfomapper {
// 获取参数中的 username
@select("select * from user_info where username = '${username}' ")
userinfo querybyusername( string username);

2.#{} 和 ${}的区别
2.1 预编译sql和即时sql的执行过程
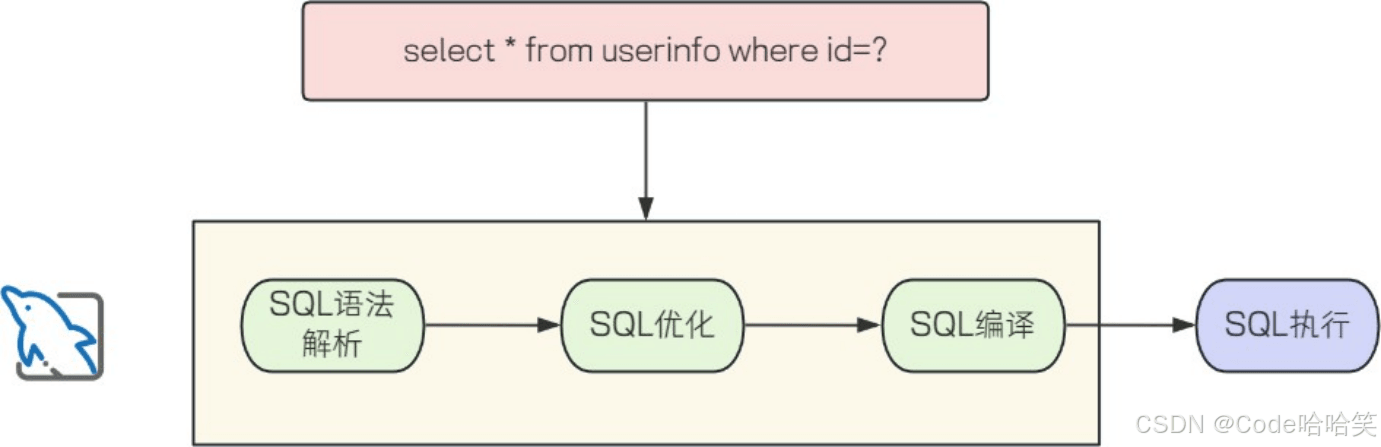
2.1.1 预编译sql执行过程
#{}是预编译sql。
第一步:数据库客户端(如 jdbc 驱动)将 sql 模板发送到数据库服务器。
// sql模版
preparedstatement pstmt = connection.preparestatement("select * from user where id = ? and name = ?");
第二步:sql 预编译
(1)数据库解析 sql 模板,生成执行计划(包括语法检查、语义分析、优化等),并缓存该计划。
(2)此时,占位符 ? 的具体值尚未填充,数据库只处理 sql 的结构。
第三步:客户端通过 preparedstatement 的方法设置参数值
//参数值以二进制形式单独发送到数据库,不会直接拼接到 sql 中,避免了 sql 注入 pstmt.setint(1, 123); // 绑定 id pstmt.setstring(2, "alice"); // 绑定 name
第四步:sql 执行
(1)数据库使用缓存的执行计划,将绑定参数代入执行计划,直接运行查询或更新操作。
(2)如果相同的 sql 模板再次执行(仅参数不同),数据库可复用缓存的执行计划,减少编译开销。
2.1.2 即时ql执行过程
${}是即时sql。
第一步:sql 语句拼接
select * from user order by ${columnname}
//如果 columnname = "age"
//生成
select * from user order by age; drop table user;
第二步:sql 发送到数据库
客户端将拼接好的完整 sql 字符串通过 statement 或类似接口发送到数据库
statement stmt = connection.createstatement(); resultset rs = stmt.executequery(sql);
第三步:sql解析与编译
语法解析:检查 sql 语句的语法是否正确。
语义分析:验证表名、列名等是否存在,权限是否足够。
优化:生成执行计划,选择最优的查询路径。
第四步:sql执行
数据库根据生成的执行计划执行 sql,完成查询或更新操作。
2.2性能比较
预编译sql(#{})性能更高:
绝⼤多数情况下, 某⼀条 sql 语句可能会被反复调⽤执⾏, 或者每次执⾏的时候只有个别的值不同(⽐如 select 的 where ⼦句值不同, update 的 set ⼦句值不同, insert 的 values 值不同). 如果每次都需要经过上⾯的语法解析, sql优化、sql编译等,则效率就明显不⾏了
预编译sql,编译⼀次之后会将编译后的sql语句缓存起来,后⾯再次执⾏这条语句时,不会再次编译 (只是输⼊的参数不同), 省去了解析优化等过程, 以此来提⾼效率
预编译sql(#{})更安全(防⽌sql注⼊):
由于没有对⽤⼾输⼊进⾏充分检查,⽽sql⼜是拼接⽽成,在⽤⼾输⼊参数时,在参数中添加⼀些 sql关键字,达到改变sql运⾏结果的⽬的,也可以完成恶意攻击。
2.3 排序举例
排序需要用到sql的关键字asc 和desc,把该两个关键字设置为参数时需要用到${},因为#{}会把asc 和desc认为是字符串
2.3.1 #{}
mapper接口:
@mapper
public interface userinfomapper {
@select("select * from userinfo order by username #{flag}")
list<userinfo> findall(string flag);
}
测试代码
@slf4j
@springboottest //启动sring 容器
class userinfomappertest {
@autowired
private userinfomapper usermapper;
@test
void findall() {
usermapper.findall("asc");
}
}
运行结果:

2.3.2 #{}
mapper接口:
@mapper
public interface userinfomapper {
@select("select * from userinfo order by username ${flag}")
list<userinfo> findall(string flag);
}
测试代码
@slf4j
@springboottest //启动sring 容器
class userinfomappertest {
@autowired
private userinfomapper usermapper;
@test
void findall() {
usermapper.findall("asc");
}
}
运行结果:
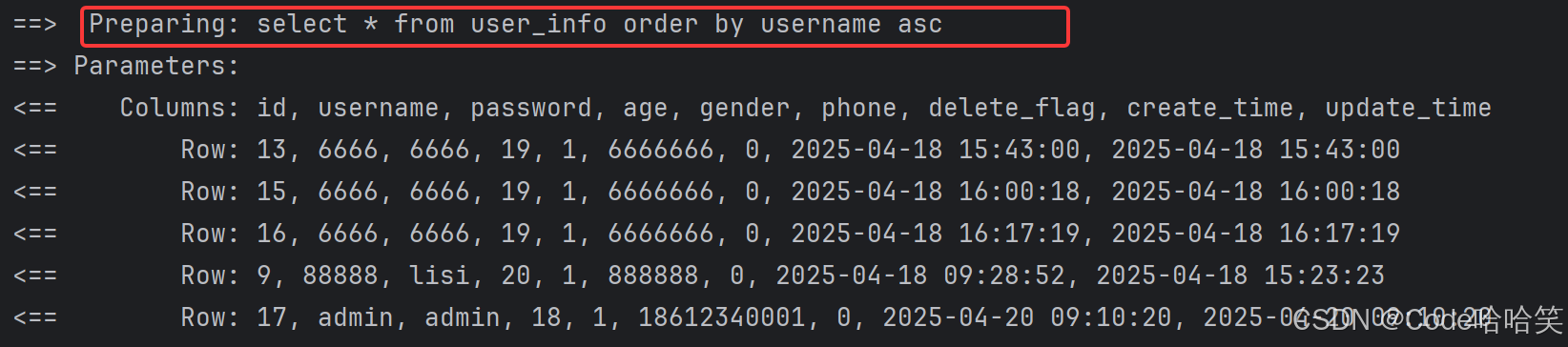
2.4 like 查询
2.4.1 #{}
mapper接口:
@mapper
public interface userinfomapper {
@select("select * from user_info where username like '%#{s}%'")
list<userinfo> querylike(string s);
}
测试代码:
@slf4j
@springboottest //启动sring 容器
class userinfomappertest {
@autowired
private userinfomapper usermapper;
@test
void querylike() {
string s = "6";
usermapper.querylike(s);
}
}
运行结果:

把 #{} 改成 可以正确查出来 , 但是 {} 可以正确查出来, 但是可以正确查出来,但是{}存在sql注⼊的问题, 所以不能直接使⽤ ${}.解决办法: 使⽤ mysql 的内置函数 concat() 来处理,实现代码如下:
修改后的mapper接口:
@mapper
public interface userinfomapper {
@select("select * from user_info where username like concat('%',#{s},'%') ")
list<userinfo> querylike(string s);
运行结果:

2.4.2 ${}
mapper接口:
@mapper
public interface userinfomapper {
@select("select * from user_info where username like '%${s}%' ")
list<userinfo> querylike(string s);
}
测试代码:
@slf4j
@springboottest //启动sring 容器
class userinfomappertest {
@autowired
private userinfomapper usermapper;
@test
void querylike() {
string s = "6";
usermapper.querylike(s);
}
}
运行结果:

3.什么是sql注入?
sql注⼊:是通过操作输⼊的数据来修改事先定义好的sql语句,以达到执⾏代码对服务器进⾏攻击的⽅法。
举例:
下面定义的接口是由username得到该username的信息
mapper接口:
@mapper
public interface userinfomapper {
// 获取参数中的 username
@select("select * from user_info where username = ${username} ")
list<userinfo> querybyusername( string username);
可以通过输入' or username='来获取该表中所有人的信息
测试代码:
@slf4j
@springboottest //启动sring 容器
class userinfomappertest {
@autowired
private userinfomapper usermapper;
@test
void querybyusername() {
usermapper.querybyusername("lisi");
}
}
运行结果:
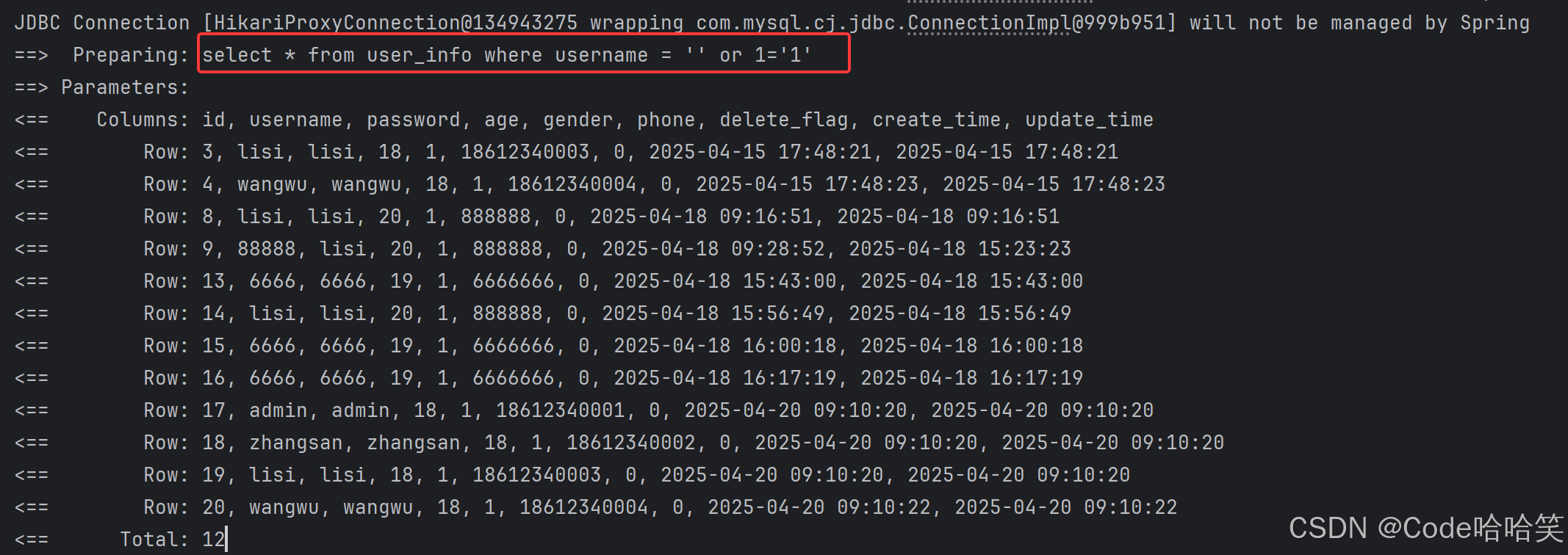
可以看出来, 查询的数据越界了接口的定义。所以⽤于查询的字段,尽量使⽤#{}预查询的⽅式
sql注⼊是⼀种⾮常常⻅的数据库攻击⼿段, sql注⼊漏洞也是⽹络世界中最普遍的漏洞之⼀。
4.数据库连接池
4.1介绍
数据库连接池负责分配、管理和释放数据库连接,它允许应⽤程序重复使⽤⼀个现有的数据库连接,⽽不是再重新建⽴⼀个.
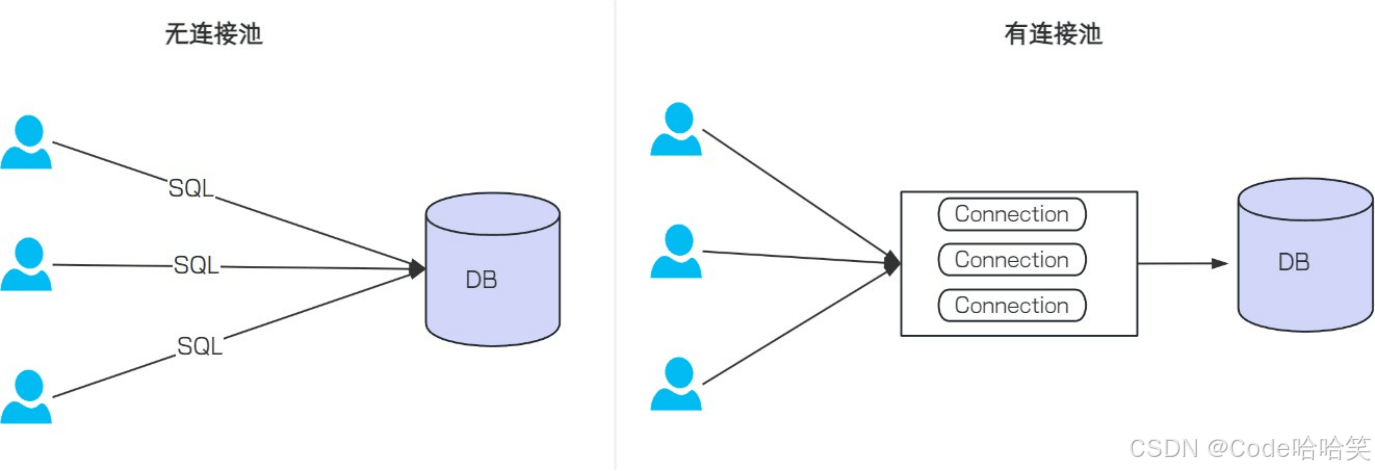
没有使⽤数据库连接池的情况: 每次执⾏sql语句, 要先创建⼀个新的连接对象, 然后执⾏sql语句, sql语句执⾏完, 再关闭连接对象释放资源. 这种重复的创建连接, 销毁连接⽐较消耗资源
使⽤数据库连接池的情况: 程序启动时, 会在数据库连接池中创建⼀定数量的connection对象, 当客⼾请求数据库连接池, 会从数据库连接池中获取connection对象, 然后执⾏sql, sql语句执⾏完, 再把 connection归还给连接池.
优点:
1.减少了⽹络开销
2.资源重⽤
3.提升了系统的性能
4.2使⽤
常⻅的数据库连接池:
- c3p0
- dbcp
- druid
- hikari
⽬前⽐较流⾏的是 hikari, druid
hikari : springboot默认使⽤的数据库连接池

hikari 是⽇语"光"的意思(ひかり), hikari也是以追求性能极致为⽬标
druid
如果我们想把默认的数据库连接池切换为druid数据库连接池, 只需要引⼊相关依赖即可
<dependency> <groupid>com.alibaba</groupid> <artifactid>druid-spring-boot-3-starter</artifactid> <version>1.2.21</version> </dependency>
如果springboot版本为2.x, 使⽤druid-spring-boot-starter 依赖
<dependency> <groupid>com.alibaba</groupid> <artifactid>druid-spring-boot-starter</artifactid> <version>1.1.17</version> </dependency>
druid连接池是阿⾥巴巴开源的数据库连接池项⽬
功能强⼤,性能优秀,是java语⾔最好的数据库连接池之⼀
到此这篇关于深入解析springboot中#{} 和 ${}的使用的文章就介绍到这了,更多相关springboot中#{} 和 ${}内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论