python中的列表、元组、字典、集合有时包含大量的数据,而这样的变量在主流编辑器pycharm中并不能像matlab那样直接可视化显示出来亦或直接打印、复制粘贴。如下图是一张图片的像素点数据:
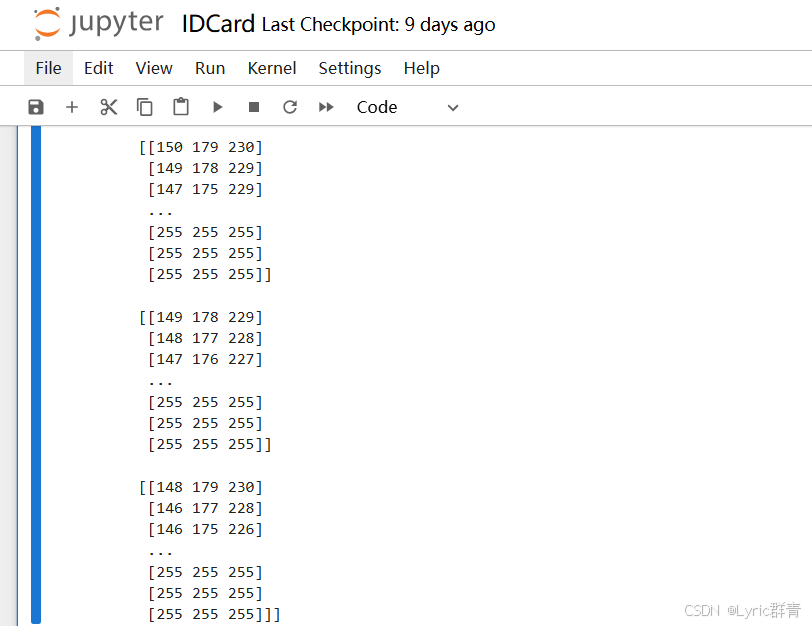
因此我们需要将这些变量的数值输出到excel中,方便后续使用。
大致需要3个包:numpy、pandas和openpyxl,如果用anaconda有的版本已经自带:
一.列表list
import pandas as pd
data=[[1,2,3,4,5],[6,7,8,9,10]]
df = pd.dataframe(data)
print(df)
df.to_excel('d:\\output1.xlsx', index=false)注意:
- openyxl不需要导入,只要安装了就可以;但必须导入pandas
- 路径及文件名需要自己写,但是一定要用双反斜杠——因为 \ 作为转义符会抵消一个~
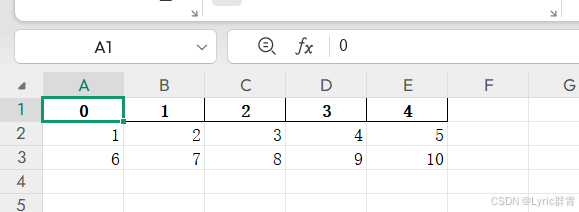
实际上,此处调用pandas包将原始数据变为dataframe型的数据,因为上述只有数值,没有定义行列,因此列标默认从0开始设置,用户可以自行设置行列名:
import pandas as pd
data=[[1,2,3,4,5],[6,7,8,9,10]]
df = pd.dataframe(data,
index=['1行','2行'],
columns=['1列','2列','3列','4列','5列'])
print(df)
df.to_excel('d:\\output5.xlsx', index=false)需要注意的是,参数名必须严格写index和columns~

另外可以设置index和columns的布尔值,选择性保留行列标签(默认为真):
import pandas as pd
data=[[1,2,3,4,5],[6,7,8,9,10]]
df = pd.dataframe(data,
index=['1行','2行'],
columns=['1列','2列','3列','4列','5列'])
print(df)
df.to_excel('d:\\output6.xlsx')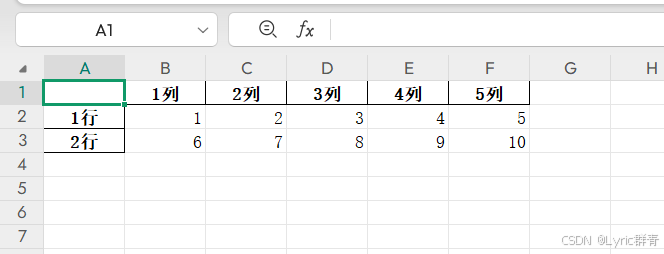
二.字典dict
import pandas as pd
data = {'队名': ['拜仁慕尼黑', '勒沃库森', '多特蒙德'],
'所在州': ['巴伐利亚','北莱茵-威斯特法伦', '北莱茵-威斯特法伦'],
'排名': [1, 2, 10]}
df = pd.dataframe(data)
print(df)
df.to_excel('d:\\output2.xlsx', index=false)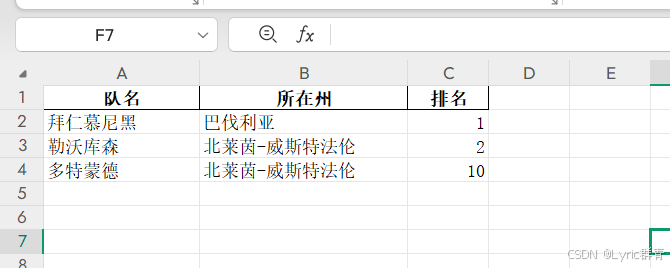
三.集合set
import pandas as pd
data={1,2,3,4,5}
df = pd.dataframe(data)
print(df)
df.to_excel('d:\\output3.xlsx', index=false)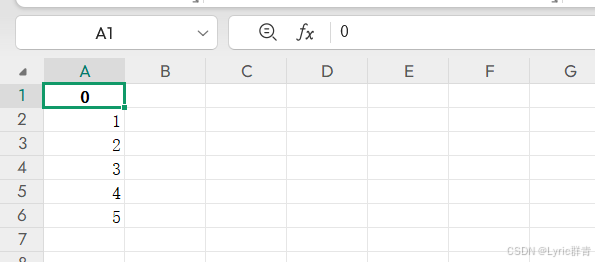
四.元组tuple
import pandas as pd
data=(1,3,2,5)
df = pd.dataframe(data)
print(df)
df.to_excel('d:\\output4.xlsx', index=false)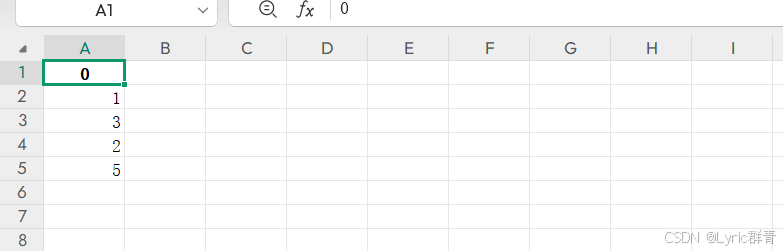
总的来说,往往大量的数据处理主要用到的还是字典和列表~
到此这篇关于python多种数据类型输出为excel文件的文章就介绍到这了,更多相关python输出为excel文件内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!



发表评论