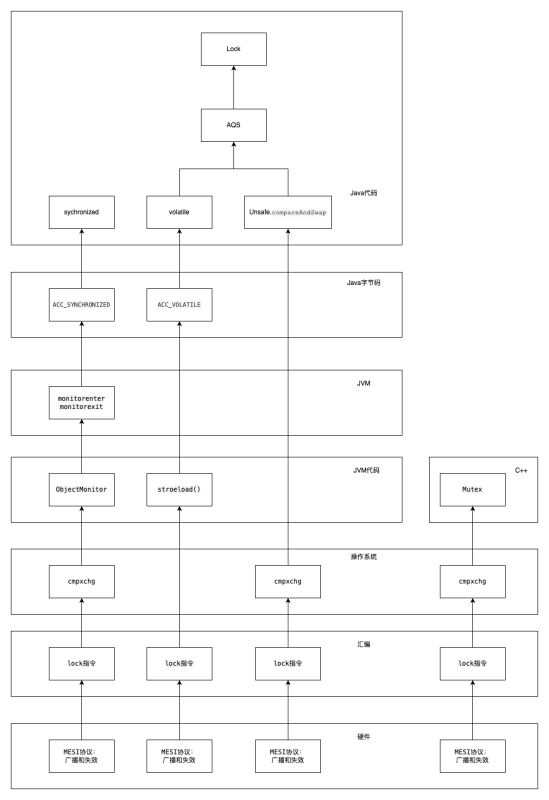
1. 概览
从java代码级别到硬件级别各层都是如何实现的
2. synchronized
2.1 字节码层面
使用javap -verbose <class文件>可以查看到字节码信息,其中synchronized方法会有flags:acc_synchronized,此时字节码中不会包含monitorenter和moniotrexit,jvm会自动加
public synchronized void syncmethod(); flags: acc_public, acc_synchronized
使用``javap -verbose <class文件>`编译一个带synchronized块的代码可以看到字节码中的monitorenter和moniotrexit
0: new #2 // 创建一个新的object实例 3: dup 4: invokespecial #1 // 调用object的构造函数 7: astore_1 // 将引用存储到局部变量1(lock) 8: aload_1 // 将局部变量1(lock)加载到操作数栈 9: monitorenter // 进入monitor 10: ... // 同步块体的字节码 : aload_1 : monitorexit // 退出monitor : ...
2.2 jvm层面
源码可以在github上面查看
monitorenter底层是由jvm的代码objectmonitor来实现的
objectmonitor() {
// 多线程竞争锁进入时的单向链表
objectwaiter * volatile _cxq;
//处于等待锁block状态的线程,会被加入到该列表
objectwaiter * volatile _entrylist;
// _header是一个markoop类型,markoop就是对象头中的mark word
volatile markoop _header;
// 抢占该锁的线程数,约等于waitset.size + entrylist.size
volatile intptr_t _count;
// 等待线程数
volatile intptr_t _waiters;
// 锁的重入次数
volatile intptr_ _recursions;
// 监视器锁寄生的对象,锁是寄托存储于对象中
void* volatile _object;
// 指向持有objectmonitor对象的线程
void* volatile _owner;
// 处于wait状态的线程,会被加入到_waitset
objectwaiter * volatile _waitset;
// 操作waitset链表的锁
volatile int _waitsetlock;
// 嵌套加锁次数,最外层锁的_recursions属性为0
volatile intptr_t _recursions;
}2.2.1 enter方法
整个方法比较长,但我们了解的无锁、偏向锁、轻量级锁、重量级锁都可以看到,核心方法是atomic::cmpxchg_ptr,这个是cas操作
| 锁 | 方法 | 描述 |
|---|---|---|
| 偏向锁 | atomic::cmpxchg_ptr | 将owner替换为当前线程,成功则获取到锁 |
| 轻量级锁 | tryspin->atomic::cmpxchg_ptr | 不断自旋将owner替换为当前线程,成功则获取到锁 |
| 重量级锁 | enteri>atomic::cmpxchg_ptr | park然后将owner替换为当前线程,成功则获取到锁 |
void attr objectmonitor::enter(traps) {
// the following code is ordered to check the most common cases first
// and to reduce rts->rto cache line upgrades on sparc and ia32 processors.
thread * const self = thread ;
void * cur ;
// 无锁cas 转为 偏向锁
cur = atomic::cmpxchg_ptr (self, &_owner, null) ;
if (cur == null) {
// either assert _recursions == 0 or explicitly set _recursions = 0.
assert (_recursions == 0 , "invariant") ;
assert (_owner == self, "invariant") ;
// consider: set or assert owneristhread == 1
return ;
}
// 可重入锁
if (cur == self) {
// todo-fixme: check for integer overflow! bugid 6557169.
_recursions ++ ;
return ;
}
if (self->is_lock_owned ((address)cur)) {
assert (_recursions == 0, "internal state error");
_recursions = 1 ;
// commute owner from a thread-specific on-stack basiclockobject address to
// a full-fledged "thread *".
_owner = self ;
owneristhread = 1 ;
return ;
}
// we've encountered genuine contention.
assert (self->_stalled == 0, "invariant") ;
self->_stalled = intptr_t(this) ;
// try one round of spinning *before* enqueueing self
// and before going through the awkward and expensive state
// transitions. the following spin is strictly optional ...
// note that if we acquire the monitor from an initial spin
// we forgo posting jvmti events and firing dtrace probes.
// 自旋获取锁
if (knob_spinearly && tryspin (self) > 0) {
assert (_owner == self , "invariant") ;
assert (_recursions == 0 , "invariant") ;
assert (((oop)(object()))->mark() == markoopdesc::encode(this), "invariant") ;
self->_stalled = 0 ;
return ;
}
assert (_owner != self , "invariant") ;
assert (_succ != self , "invariant") ;
assert (self->is_java_thread() , "invariant") ;
javathread * jt = (javathread *) self ;
assert (!safepointsynchronize::is_at_safepoint(), "invariant") ;
assert (jt->thread_state() != _thread_blocked , "invariant") ;
assert (this->object() != null , "invariant") ;
assert (_count >= 0, "invariant") ;
// prevent deflation at stw-time. see deflate_idle_monitors() and is_busy().
// ensure the object-monitor relationship remains stable while there's contention.
atomic::inc_ptr(&_count);
eventjavamonitorenter event;
{ // change java thread status to indicate blocked on monitor enter.
javathreadblockedonmonitorenterstate jtbmes(jt, this);
dtrace_monitor_probe(contended__enter, this, object(), jt);
if (jvmtiexport::should_post_monitor_contended_enter()) {
jvmtiexport::post_monitor_contended_enter(jt, this);
}
osthreadcontendstate osts(self->osthread());
threadblockinvm tbivm(jt);
self->set_current_pending_monitor(this);
// todo-fixme: change the following for(;;) loop to straight-line code.
for (;;) {
jt->set_suspend_equivalent();
// cleared by handle_special_suspend_equivalent_condition()
// or java_suspend_self()
// 重量级锁
enteri (thread) ;
省略.......
}2.2.2 cmpxchg_ptr
上面的锁都用了这个方法cmpxchg_ptr,这个和java中的cas是类似的,那它又是怎么实现的呢
其中cmpxchg是linux操作系统的函数,执行了一段汇编指令,并且有lock前缀
// 多核心多cpu前面就要加lock
#define lock_if_mp(mp) "cmp $0, " #mp "; je 1f; lock; 1: "
inline intptr_t atomic::cmpxchg_ptr(intptr_t exchange_value, volatile intptr_t* dest, intptr_t compare_value) {
return (intptr_t)cmpxchg((jlong)exchange_value, (volatile jlong*)dest, (jlong)compare_value);
}
inline jlong atomic::cmpxchg (jlong exchange_value, volatile jlong* dest, jlong compare_value) {
bool mp = os::is_mp();
__asm__ __volatile__ (lock_if_mp(%4) "cmpxchgq %1,(%3)"
: "=a" (exchange_value)
: "r" (exchange_value), "a" (compare_value), "r" (dest), "r" (mp)
: "cc", "memory");
return exchange_value;
}3. volatile
3.1 字节码层面
static volatile int greaterthansevencnt;
descriptor: i
flags: acc_static, acc_volatile3.2 jvm层面
可以看到判断是否是volatile字段,是的话最后会有orderaccess::storeload(); , 就是就是storeload屏障
case(_putfield):
case(_putstatic):
{
// .... 省略若干行
// ....
// now store the result 现在要开始存储结果了
// constantpoolcacheentry* cache; -- cache是常量池缓存实例
// cache->is_volatile() -- 判断是否有volatile访问标志修饰
int field_offset = cache->f2_as_index();
if (cache->is_volatile()) { // ****重点判断逻辑****
// volatile变量的赋值逻辑
if (tos_type == itos) {
obj->release_int_field_put(field_offset, stack_int(-1));
} else if (tos_type == atos) {// 对象类型赋值
verify_oop(stack_object(-1));
obj->release_obj_field_put(field_offset, stack_object(-1));
orderaccess::release_store(&byte_map_base[(uintptr_t)obj >> cardtablemodrefbs::card_shift], 0);
} else if (tos_type == btos) {// byte类型赋值
obj->release_byte_field_put(field_offset, stack_int(-1));
} else if (tos_type == ltos) {// long类型赋值
obj->release_long_field_put(field_offset, stack_long(-1));
} else if (tos_type == ctos) {// char类型赋值
obj->release_char_field_put(field_offset, stack_int(-1));
} else if (tos_type == stos) {// short类型赋值
obj->release_short_field_put(field_offset, stack_int(-1));
} else if (tos_type == ftos) {// float类型赋值
obj->release_float_field_put(field_offset, stack_float(-1));
} else {// double类型赋值
obj->release_double_field_put(field_offset, stack_double(-1));
}
// *** 写完值后的storeload屏障 ***
orderaccess::storeload();
} else {
// 非volatile变量的赋值逻辑
if (tos_type == itos) {
obj->int_field_put(field_offset, stack_int(-1));
} else if (tos_type == atos) {
verify_oop(stack_object(-1));
obj->obj_field_put(field_offset, stack_object(-1));
orderaccess::release_store(&byte_map_base[(uintptr_t)obj >> cardtablemodrefbs::card_shift], 0);
} else if (tos_type == btos) {
obj->byte_field_put(field_offset, stack_int(-1));
} else if (tos_type == ltos) {
obj->long_field_put(field_offset, stack_long(-1));
} else if (tos_type == ctos) {
obj->char_field_put(field_offset, stack_int(-1));
} else if (tos_type == stos) {
obj->short_field_put(field_offset, stack_int(-1));
} else if (tos_type == ftos) {
obj->float_field_put(field_offset, stack_float(-1));
} else {
obj->double_field_put(field_offset, stack_double(-1));
}
}
update_pc_and_tos_and_continue(3, count);
}进入orderaccess源码可以看到,直接执行了一段汇编指令,并且有lock前缀
inline void orderaccess::storeload() { fence(); }
inline void orderaccess::fence() {
if (os::is_mp()) {
// always use locked addl since mfence is sometimes expensive
#ifdef amd64
__asm__ volatile ("lock; addl $0,0(%%rsp)" : : : "cc", "memory");
#else
__asm__ volatile ("lock; addl $0,0(%%esp)" : : : "cc", "memory");
#endif
}
}4. lock指令
在上面的分析中,最底层都设计到汇编层面的lock指令,这个指令有什么作用呢?
根据汇编参考文档ia-32 assembly language reference manual
the lock # signal is asserted during execution of the instruction following the lock prefix. this signal can be used in a multiprocessor system to ensure exclusive use of shared memory while lock # is asserted. the bts instruction is the read-modify-write sequence used to implement test-and-run. the lock prefix works only with the instructions listed here. if a lock prefix is used with any other instructions, an undefined opcode trap is generated.
lock是一个指令前缀,用于多核处理器系统不使用共享内存
那么它又是怎么让其他核心不访问共享内存,有两种方法
- 锁内存总线,也就是说执行这条指令的时候,其他的核心都不能在访问内存了
- 锁缓存行,现在cpu本身是有多级缓存的,而这些缓存是如何保持一致的,由mesi来支持,mesi协议可以保证其他核心不使用内存,或者换一种说法,可以使用,但被修改的内容会失效
5. mesi协议
现代cpu多核架构中为了协调快速的cpu运算和相对较慢的内存读写速度之间的矛盾,在cpu和内存之间引入了cpu cache:
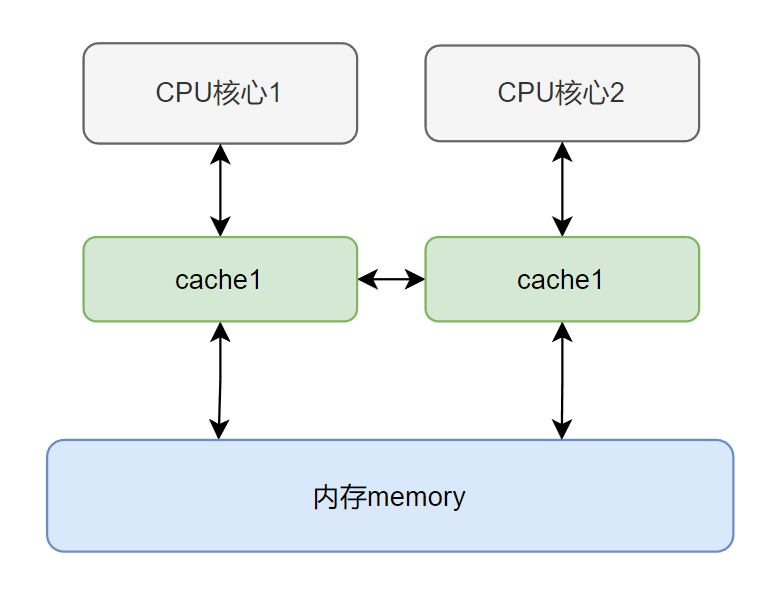
mesi协议下,缓存行(cache line)有四种状态来保证缓存的一致性
- 已修改modified (m) 缓存行是脏的,与主存的值不同。如果别的cpu内核要读主存这块数据,该缓存行必须回写到主存,状态变为共享(s)
- 独占exclusive (e) 缓存行只在当前缓存中,但是干净的(clean)–缓存数据同于主存数据。当别的缓存读取它时,状态变为共享;当前写数据时,变为已修改状态。
- 共享shared (s) 缓存行也存在于其它缓存中且是干净的。缓存行可以在任意时刻抛弃。
- 无效invalid (i) 缓存行是无效的,需要从主内存中读取最新值
每次要修改缓存,如果缓存行状态为 s 的话都要先发一个 invalidate 的广播,再等其他 cpu 将缓存行设置为无效后返回 invalidate ack 才能写到 cache 中,因为这样才能保证缓存的一致性
但是如果 cpu 频繁地修改数据,就会不断地发送广播消息,cpu 只能被动同步地等待其他 cpu 的消息,显然会对执行效率产生影响
为了解决此问题,工程师在 cpu 和 cache 之间又加了一个 store buffer,同时在cache和总线之间添加了invalidate queue
这个buffer可以让广播和收广播的处理异步化,效率当然会变高,但强一致性变为了最终一致性
lock指令是cpu硬件工程师给程序员留的一个口子,把对mesi协议的优化(store buffer, invalidate queue)禁用,暂时以同步方式工作,使得对于该关键字的mesi协议退回强一致性状态
6. 总结
分析到此:
所有的并发问题可以概括为,多个核心同时修改内存数据,导致结果不符合预期
解决并发问题的方法可以概括为,同一时间只能让一个核心修改内存,但有多种手段,例如锁总线、或者广播让其他核心失效
7. 其他问题
既然sychronized的和volatile底层实现是一样的,那么volatile为什么没有原子性呢?
在于锁定的范围,volatile修饰的是一个字段,只能保证读和写是原子性的,但读出来、在计算、写入分为三步则不是原子性的。
sychronized底层也用了volatile的,但它的锁定范围是程序员指定的,这个范围之间的代码是原子的
cas volatile变量开始锁定 任意程序代码 cas volatile变量释放锁定
现在一般推荐使用java的atomic类,他是通过cas来实现的,它和sychronized的区别是什么?
cas不能单独使用,需要加自旋操作,本身是一个乐观锁
sychronized本身结合了乐观锁和悲观锁,悲观锁会让线程park然后重试,不会消耗cpu,而乐观锁但不断消耗cpu
8. 对比
在阅读objectmonitor代码时,发现有很熟悉的感觉
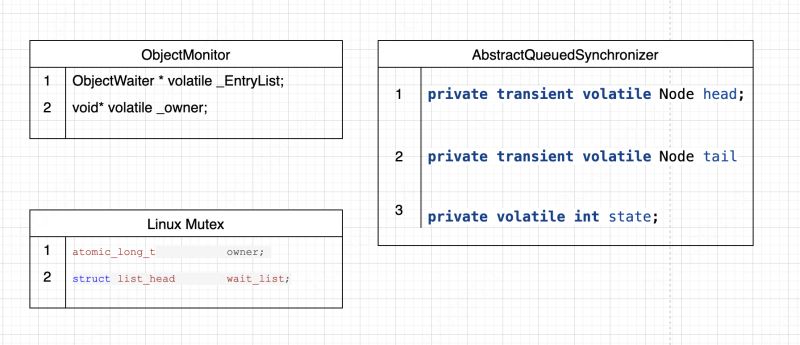
发现这些锁的数据结果都是类似的,一个volatile变量加一个等待队列
参考
【2】java多线程:objectmonitor源码解读(3)
【4】聊聊cpu的lock指令
【5】12 张图看懂 cpu 缓存一致性与 mesi 协议,真的一致吗?
【8】浅析mutex实现原理
【9】cas你以为你真的懂?
【10】x86 lock 指令前缀
【11】linux mutex机制分析
到此这篇关于java的volatile和sychronized底层实现原理解析的文章就介绍到这了,更多相关java volatile和sychronized底层内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论