mysql的批量更新和批量插入优化
如果需要批量插入和批量更新操作就需要进行sql 的优化,否则近30万条数据的插入或更新就会耗费几分钟甚至更多的时间, 此文仅批量插入和批量更新的几种优化。
- 批量插入篇(使用多条
insert语句、使用union all创建临时表、使用多个values); - 批量更新篇(使用多条
update语句、使用union all创建临时表创建临时表、使用replace into、使用insert ... on duplicate key ... update...)。
如果有需要的同僚可根据下列内容使用jdbctemplate和java反射技术将其封装。
特别提示:做批量操作时,请限制每次1000-2000条数据,以避免gc和oom。后期也会贴出相关代码,欢迎指正优化或提供其它更好的方法。
批量插入篇
1. 多条insert语句(快)
实测:50*6500行数据耗时8-12秒,如果不是手动提交事务,耗时约70-180秒
类型: insert into table_name(id,name,title) values(?, ?, ?);
常用的插入操作就是批量执行1条insert类型的sql语句,这样的语句在执行大量的插入数据时, 其效率低下就暴露出来了。
特别注意:jdbc.url需要加上:allowmultiqueries=true
jdbc.url = jdbc:mysql://127.0.0.1:3306/test?useunicode=true&characterencoding=utf-8&usessl=false&servertimezone=utc&allowmultiqueries=true
(1)sql 语句
start transaction; insert into table_name(id, name, title) values(1, '张三', '如何抵挡美食的诱惑?'); insert into table_name(id, name, title) values(2, '李四', '批判张三的《如何抵挡美食的诱惑?》'); insert into table_name(id, name, title) values(3, '王五', '会看鬼子进村的那些不堪入目的事儿'); insert into table_name(id, name, title) values(4, '赵柳', 'java该怎样高效率学习'); commit;
(2)mapper 文件的 sql
<insert id="batchsave" parametertype="java.util.list">
start transaction;
<foreach collection="list" index="index" item="item">
insert into table_name(id, name, title) values(#{item.id}, #{item.name}, #{item.title});
</foreach>
commit;
</insert>2. 多个values语句(快)
实测:50*6500行数据耗时6至10秒(与服务器的有关)
类型: insert into table_name(id, name, title) values(?, ?, ?), ..., (?, ?, ?);
(1)sql 语句
insert into table_name(id, name, title) values (1, '张三', '如何抵挡美食的诱惑?'), (2, '李四', '批判张三的《如何抵挡美食的诱惑?》'), (3, '王五', '会看鬼子进村的那些不堪入目的事儿'), (4, '赵柳', 'java该怎样高效率学习');
(2)mapper 文件的 sql
<insert id="batchsave" parametertype="java.util.list">
insert into table_name(id, name, title) values
<foreach collection="list" index="index" item="item" separator=", ">
(#{item.id}, #{item.name}, #{item.title})
</foreach>
</insert>3. 使用union all 创建临时表(快)
实测:50*6500行数据耗时6至10秒(与服务器的有关)
类型: insert into table_name(id,name,title) select ?, ?, ? union all select ?, ?, ? union all ...
union all 在这里select ?, ?, ? union all select ?, ?, ? union all ...是创建临时表的原理,先创建整张临时表到内存中,然后将整张临时表导入数据库,连接关闭时即销毁临时表,其他的不多说,可自行了解。
(1)sql 语句
insert into table_name(id, name, title) select 1, '张三', '如何抵挡美食的诱惑?' union all select 2, '李四', '批判张三的《如何抵挡美食的诱惑?》' union all select 3, '王五', '会看鬼子进村的那些不堪入目的事儿' union all select 4, '赵柳', 'java该怎样高效率学习';
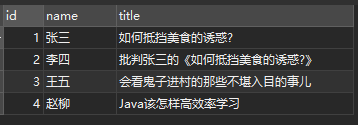
a. 创建临时表方式1 - 使用 temporary + union all
简单列举三种创建临时表的方式, 这里熟悉了temporary 、 select ?, ? ,? union all select ?, ?, ? 和 、insert into ... values(?, ?, ?), (?, ?, ?), (?, ?, ?)...之后,都可以组合创建临时表, 效率几乎差不多。个人更加偏向第二种,因为简单方便。
create temporary table tmp(id int(4) primary key,name varchar(50),title varchar(50)); select id, name, title from tmp union all select 1, '张三', '如何抵挡美食的诱惑?' union all select 2, '李四', '批判张三的《如何抵挡美食的诱惑?》' union all select 3, '王五', '会看鬼子进村的那些不堪入目的事儿' union all select 4, '赵柳', 'java该怎样高效率学习';
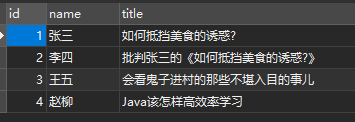
b. 创建临时表方式2 - 使用 select + union all
select id, name, title from table_name where id = -1 union all select 1, '张三', '如何抵挡美食的诱惑?' union all select 2, '李四', '批判张三的《如何抵挡美食的诱惑?》' union all select 3, '王五', '会看鬼子进村的那些不堪入目的事儿' union all select 4, '赵柳', 'java该怎样高效率学习';
c. 创建临时表方式3 - 使用 temporary + 多个insert values
create temporary table tmp(id int(4) primary key,name varchar(50),title varchar(50)); insert into tmp(id, name, title) values (1, '张三', '如何抵挡美食的诱惑?'), (2, '李四', '批判张三的《如何抵挡美食的诱惑?》'), (3, '王五', '会看鬼子进村的那些不堪入目的事儿'), (4, '赵柳', 'java该怎样高效率学习');
(2)mapper 文件的 sql
<insert id="batchsave" parametertype="java.util.list">
insert into table_name(id, name, title)
<foreach collection="list" index="index" item="item" separator=" union all ">
select #{item.id}, #{item.name}, #{item.title}
</foreach>
</insert>批量更新篇
1. 多条update语句批量更新(快)
实测:50*6500行数据耗时26-30秒,如果不是手动提交事务,耗时约70-180秒
类型: update table_name set name = ?, title = ? where id = ?;
由于批量更新存在条件判断,所以整体上时效上没有批量插入那么高(下面是手动提交事务的代码)。
特别注意:jdbc.url需要加上:allowmultiqueries=true
jdbc.url = jdbc:mysql://127.0.0.1:3306/test?useunicode=true&characterencoding=utf-8&usessl=false&servertimezone=utc&allowmultiqueries=true
(1)sql 语句
start transaction; update table_name set name = '张三', title = 'springboot如何入门' where id = 1; update table_name set name = '李四', title = 'jvm到底是怎样运行的' where id = 2; update table_name set name = '王五', title = '并发编程你需要注意什么' where id = 3; update table_name set name = '赵柳', title = '别让一时的贪成为你不努力的理由' where id = 4; commit;
(2)mapper 文件的 sql
<update id="batchupdate" parametertype="java.util.list">
start transaction;
<foreach collection="list" index="index" item="item">
update table_name set name = #{item.id}, title = #{item.title} where id = #{item.id};
</foreach>
commit;
</update >2. 创建临时表批量更新(快)
实测:50*6500行数据耗时26至28秒
(1)批量更新(使用 temporary + select … union all … select …创建临时表)
类型: create temporary table 临时表; select id, name, title from 临时表 union all select ... union all ... select ...
(a)sql 语句
这里也可以使用 union all 加上 temporary 的方式创建临时表, 详情请看批量插入篇的创建临时表的两种方式
create temporary table tmp(id int(4) primary key,name varchar(50),title varchar(50)); select id, name, title from tmp union all select 1, '张三', '如何抵挡美食的诱惑?' union all select 2, '李四', '批判张三的《如何抵挡美食的诱惑?》' union all select 3, '王五', '会看鬼子进村的那些不堪入目的事儿' union all select 4, '赵柳', 'java该怎样高效率学习'; update table_name, tmp set table_name.name=tmp.name, table_name.title= tmp.title where table_name.id = tmp.id;
(b)mapper 文件的 sql
<update id="batchupdate" parametertype="java.util.list">
create temporary table tmp(id int(4) primary key,name varchar(50),title varchar(50));
update table_name, (select id, name, title from tmp union all
<foreach collection="list" index="index" item="item" separator=" union all ">
select #{item.id}, #{item.name}, #{item.title}
</foreach>) as tmp
set table_name.name=tmp.name, table_name.title= tmp.title where table_name.id = tmp.id;
</insert>(2)批量更新(使用 temporary + insert into values(…), (…)… 创建临时表)
类型: create temporary table 临时表; insert into values(...), (...)...; update ... set ... where ...;
(a)sql 语句
这里也可以使用 union all 加上 temporary 的方式创建临时表, 详情请看批量插入篇的创建临时表的两种方式
create temporary table tmp(id int(4) primary key,name varchar(50),title varchar(50)); insert into tmp(id, name, title) values (1, '张三', '如何抵挡美食的诱惑?'), (2, '李四', '批判张三的《如何抵挡美食的诱惑?》'), (3, '王五', '会看鬼子进村的那些不堪入目的事儿'), (4, '赵柳', 'java该怎样高效率学习') ; update table_name, tmp set table_name.name=tmp.name, table_name.title= tmp.title where table_name.id = tmp.id;
(b)mapper 文件的 sql
<update id="batchupdate" parametertype="java.util.list">
create temporary table tmp(id int(4) primary key,name varchar(50),title varchar(50));
insert into tmp(id, name, title) values
<foreach collection="list" index="index" item="item" separator=",">
(#{item.id}, #{item.name}, #{item.title})
</foreach>;
update table_name, tmp set table_name.name=tmp.name, table_name.title= tmp.title where table_name.id = tmp.id;
</insert>(3)批量更新(使用 select … union all… 创建临时表)
类型: update 表名, (select ... union all ...) as tmp set ... where ...
注意: id=-1为数据库一个不存在的主键id
(a)sql 语句
update table_name, (select id, name, title from table_name where id = -1 union all select 1, '张三', '如何抵挡美食的诱惑?' union all select 2, '李四', '批判张三的《如何抵挡美食的诱惑?》' union all select 3, '王五', '会看鬼子进村的那些不堪入目的事儿' union all select 4, '赵柳', 'java该怎样高效率学习') as tmp set table_name.name=tmp.name, table_name.title= tmp.title where table_name.id = tmp.id;
(b)mapper 文件的 sql
<update id="batchupdate" parametertype="java.util.list">
update table_name, (select id, name, title from table_name where id = -1 union all
<foreach collection="list" index="index" item="item" separator=" union all ">
select #{item.id}, #{item.name}, #{item.title}
</foreach>) as tmp
set table_name.name=tmp.name, table_name.title= tmp.title where table_name.id = tmp.id;
</insert>3. replace into …批量更新(快)
实测:50*6500行数据耗时26至28秒
类型: replace into ... values (...),(...),...
(1)sql 语句
replace into table_name(id, name, title) values (1, '张三', '如何抵挡美食的诱惑?'), (2, '李四', '批判张三的《如何抵挡美食的诱惑?》'), (3, '王五', '会看鬼子进村的那些不堪入目的事儿'), (4, '赵柳', 'java该怎样高效率学习') ;
(2)mapper 文件的 sql
<update id="batchupdate" parametertype="java.util.list">
replace into table_name(id, name, title) values
<foreach collection="list" index="index" item="item" separator=",">
(#{item.id}, #{item.name}, #{item.title})
</foreach>
</update>4. insert into … on duplicate key … update …批量更新(快)
实测:50*6500行数据批量更新耗时27-29秒, 批量插入耗时9-12秒
类型: insert into ... values (...),(...),...on duplicate key ... update ...
这句类型的sql在遇到 duplicate key 时执行更新操作, 否则执行插入操作(时效略微慢一点)
(1)sql 语句
insert into table_name(id, name, title) values (1, '张三', '如何抵挡美食的诱惑?'), (2, '李四', '批判张三的《如何抵挡美食的诱惑?》'), (3, '王五', '会看鬼子进村的那些不堪入目的事儿'), (4, '赵柳', 'java该怎样高效率学习') on duplicate key update name=values(name), title=values(title);
(2)mapper 文件的 sql
<update id="batchupdate" parametertype="java.util.list">
replace into table_name(id, name, title) values
<foreach collection="list" index="index" item="item" separator=",">
(#{item.id}, #{item.name}, #{item.title})
</foreach>
on duplicate key update id= values(id);
</update>总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。


发表评论