前言
在 java 编程的广阔天地里,集合框架是开发者们不可或缺的得力工具。其中,hashset以其独特的去重特性,成为处理不重复元素场景的首选。今天,咱们就深入探究一下hashset集合元素的去重操作,通过具体的代码示例,揭开它那神秘的面纱。

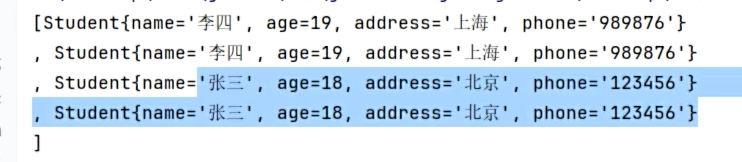
结果:

一、认识 hashset:独特的 “去重小能手”
hashset是 java 集合框架中set接口的一个实现类,它的主要特点就是不允许存储重复的元素。这就好比一个神奇的收纳盒,不管你往里面放多少东西,相同的物品只会被保留一份。从底层实现来看,hashset是基于hashmap来实现的,它利用哈希表的特性来快速定位和存储元素,从而高效地实现去重功能。
二、hashset 的去重原理
在深入代码之前,先了解一下hashset的去重原理。当我们向hashset中添加一个元素时,hashset会先调用该元素的hashcode()方法,计算出该元素的哈希码。哈希码就像是元素的一个 “数字指纹”,通过这个 “指纹” 可以快速定位元素在哈希表中的存储位置。如果两个元素的哈希码相同,hashset会进一步调用equals()方法来判断这两个元素是否相等。只有当两个元素的哈希码相同且equals()方法返回true时,hashset才会认为这两个元素是重复的,不会将第二个元素添加进去。
三、代码示例:直观感受 hashset 的去重魅力
1. 添加基本数据类型包装类元素
import java.util.hashset;
import java.util.set;
public class hashsetprimitivewrapperexample {
public static void main(string[] args) {
set<integer> numberset = new hashset<>();
numberset.add(10);
numberset.add(20);
numberset.add(10); // 尝试添加重复元素
system.out.println("hashset中的元素: " + numberset);
}
}在上述代码中,我们创建了一个hashset来存储integer类型的元素。首先添加了10和20,然后再次尝试添加10。运行程序后,你会发现输出结果中10只出现了一次,这就是hashset的去重效果。
2. 添加自定义类元素
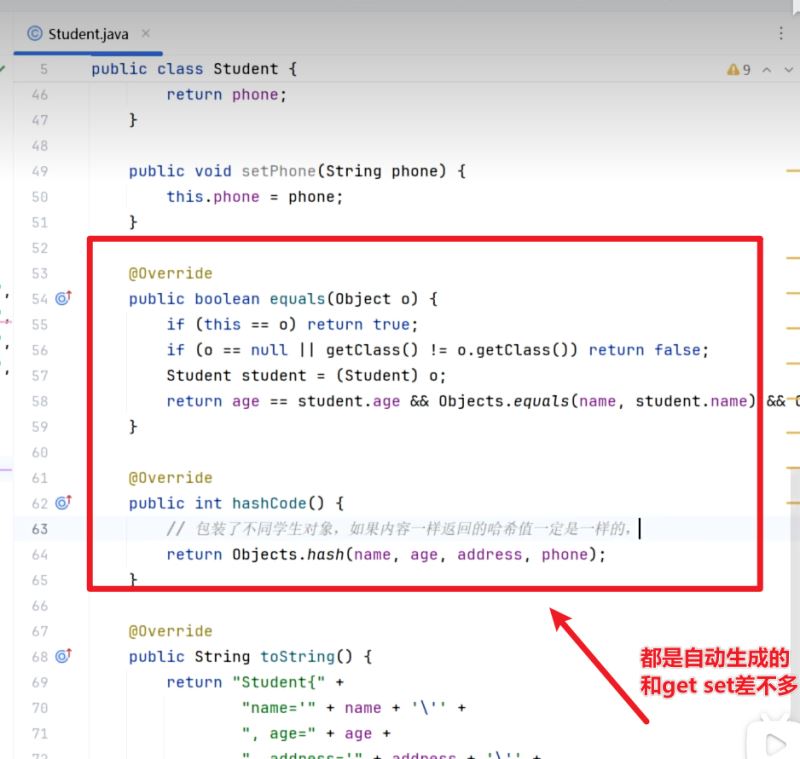
当我们尝试向hashset中添加自定义类的对象时,情况会稍微复杂一些。因为默认情况下,自定义类继承自object类,其hashcode()和equals()方法的实现并不能满足我们的去重需求。所以,我们需要在自定义类中重写这两个方法。
import java.util.hashset;
import java.util.set;
class person {
private string name;
private int age;
public person(string name, int age) {
this.name = name;
this.age = age;
}
@override
public boolean equals(object o) {
if (this == o) return true;
if (o == null || getclass()!= o.getclass()) return false;
person person = (person) o;
return age == person.age && name.equals(person.name);
}
@override
public int hashcode() {
int result = 17;
result = 31 * result + name.hashcode();
result = 31 * result + age;
return result;
}
@override
public string tostring() {
return "person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
public class hashsetcustomclassexample {
public static void main(string[] args) {
set<person> personset = new hashset<>();
person person1 = new person("alice", 25);
person person2 = new person("bob", 30);
person person3 = new person("alice", 25); // 尝试添加重复元素
personset.add(person1);
personset.add(person2);
personset.add(person3);
system.out.println("hashset中的person对象: " + personset);
}
}
在这个例子中,我们定义了一个person类,并在其中重写了equals()和hashcode()方法。通过合理的实现,hashset能够准确判断两个person对象是否重复。运行程序后,你会发现person3并没有被添加到hashset中,因为它与person1在逻辑上是重复的。
四、hashset 去重的注意事项
- 重写 equals () 和 hashcode () 方法的一致性:在自定义类中重写
equals()和hashcode()方法时,一定要确保它们的逻辑是一致的。如果两个对象通过equals()方法比较相等,那么它们的hashcode()方法返回值也必须相同;反之,如果两个对象的hashcode()方法返回值相同,它们不一定相等,但通过equals()方法比较应该有合理的逻辑判断。 - 哈希碰撞的影响:虽然哈希表的设计使得哈希碰撞(即不同元素具有相同的哈希码)的概率较低,但仍然可能发生。当哈希碰撞发生时,
hashset会通过equals()方法进一步判断元素是否相等。过多的哈希碰撞可能会影响hashset的性能,因此在设计hashcode()方法时,要尽量使哈希码分布均匀,减少碰撞的发生。
五、总结
通过今天的探索,我们深入了解了 java 中hashset集合元素的去重操作。从基本数据类型包装类到自定义类,hashset都能凭借其独特的去重原理,高效地处理重复元素。掌握hashset的去重特性,不仅能让我们在处理不重复数据时更加得心应手,还能帮助我们优化程序性能。在实际编程中,根据具体需求合理使用hashset,并注意去重过程中的一些细节,将为我们的代码增添更多的稳定性和高效性。希望大家在今后的 java 编程之旅中,能够熟练运用hashset的去重功能,创造出更加优秀的程序。如果在学习过程中遇到任何问题,欢迎随时交流,让我们一起在 java 编程的世界里不断进步。
以上就是java中hashset集合元素去重的操作代码的详细内容,更多关于java hashset集合去重的资料请关注代码网其它相关文章!




发表评论