前一篇写的是markdown格式的文本内容转换保存为word文档,是假定已经有一个现成的markdown格式的文本,然后直接转换保存为word文档,不过在开发中,通常情况下,数据是从数据库中获取,拿到的数据映射到java对象上,这一篇就是处理如何将java对象数据生成为markdown文本。
添加maven依赖:
<!-- excel工具 练习的项目自身的依赖-->
<dependency>
<groupid>org.apache.poi</groupid>
<artifactid>poi-ooxml</artifactid>
<version>4.1.2</version>
</dependency>
<!-- 新添加的依赖-->
<!-- markdown格式转换为html -->
<dependency>
<groupid>org.commonmark</groupid>
<artifactid>commonmark</artifactid>
<version>0.21.0</version>
</dependency>
<!-- poi-tl和poi-tl-plugin-markdown是处理markdown格式转换为word格式,处理只处理markdown转换为html,只需要commonnark依赖即可-->
<dependency>
<groupid>com.deepoove</groupid>
<artifactid>poi-tl</artifactid>
<version>1.10.1</version>
</dependency>
<dependency>
<groupid>com.deepoove</groupid>
<artifactid>poi-tl-plugin-markdown</artifactid>
<version>1.0.3</version>
</dependency>1.首先编写一个markdown的语法生成的处理类:
package com.xiaomifeng1010.common.markdown;
import org.apache.commons.lang3.stringutils;
import java.util.*;
/**
* @author xiaomifeng1010
* @version 1.0
* @date: 2024-09-21 20:50
* @description
*/
public class markdownhandler {
// ~ apis
// -----------------------------------------------------------------------------------------------------------------
public static sectionbuilder of() {
return new sectionbuilder(new section(section.type.normal, null, null, null, 0));
}
// ~ public classes & public constants & public enums
// -----------------------------------------------------------------------------------------------------------------
public enum style {
normal("normal"), bold("bold"), italic("italic"),
red("red"), green("green"), gray("gray"), yellow("gold"), blue("blue");
private final string name;
style(string name) {
this.name = name;
}
public string getname() {
return name;
}
}
public static class fonts {
public static final fonts empty = fonts.of("");
private final string text;
// ~ private fields
// -------------------------------------------------------------------------------------------------------------
private set<style> styles = collections.emptyset();
private fonts(string text, style... style) {
this.text = text != null ? text : "";
if (style != null) {
this.styles = new hashset<>(arrays.aslist(style));
}
}
// ~ public methods
// -------------------------------------------------------------------------------------------------------------
public static fonts of(string text) {
return new fonts(text, style.normal);
}
public static fonts of(string text, style... style) {
return new fonts(text, style);
}
public boolean isempty() {
return this.text == null || this.text.isempty();
}
@override
public string tostring() {
if (styles.contains(style.normal)) {
return text;
}
string last = text;
for (style style : styles) {
last = parsestyle(last, style);
}
return last;
}
// ~ private methods
// -------------------------------------------------------------------------------------------------------------
private string parsestyle(string text, style style) {
if (text == null || style == null) {
return text;
}
switch (style) {
case normal:
break;
case bold:
return "**" + text + "**";
case italic:
return "*" + text + "*";
case red:
case green:
case blue:
case yellow:
return "<font color='" + style.getname() + "'>" + text + "</font>";
}
return text;
}
}
/**
* 代表一行,可以是一个普通文本或一个k-v(s)数据
*/
public static class metadata {
// ~ public constants
// -------------------------------------------------------------------------------------------------------------
public static final string default_separator = ":";
public static final string default_value_separator = " | ";
public static final string link_template = "[%s▸](%s)";
// ~ private fields
// -------------------------------------------------------------------------------------------------------------
private final type type;
private final fonts text;
private final collection<fonts> values;
private final string separator = default_separator;
private final string valueseparator = default_value_separator;
public metadata(fonts text) {
this(text, null);
}
public metadata(type type) {
this(type, null, null);
}
public metadata(fonts text, collection<fonts> values) {
this(type.normal, text, values);
}
public metadata(type type, fonts text, collection<fonts> values) {
this.type = type;
this.text = text;
this.values = values;
}
@override
public string tostring() {
return generatestring(this.valueseparator);
}
/**
* generate one line
*/
private string generatestring(string valueseparator) {
boolean hasvalues = values != null && !values.isempty();
boolean hastext = text != null && !text.isempty();
stringjoiner joiner = new stringjoiner(valueseparator);
string ret = "";
switch (type) {
case normal:
if (hastext && hasvalues) {
values.foreach(v -> joiner.add(v.tostring()));
ret = text + separator + joiner;
} else if (!hastext && hasvalues) {
values.foreach(v -> joiner.add(v.tostring()));
ret = joiner.tostring();
} else if (hastext) {
ret = text.tostring();
}
break;
case link:
if (hastext && hasvalues) {
fonts fonts = values.stream().findfirst().orelse(null);
if (fonts == null) {
break;
}
ret = string.format(link_template, text, fonts);
} else if (!hastext && hasvalues) {
fonts url = values.stream().findfirst().orelse(null);
if (url == null) {
break;
}
ret = string.format(link_template, url, url);
} else if (hastext) {
ret = string.format(link_template, text, text);
}
break;
case link_list:
if (hastext && hasvalues) {
ret = text + separator + generatelinklist(values);
} else if (!hastext && hasvalues) {
ret = generatelinklist(values);
} else if (hastext) {
ret = string.format(link_template, text, text);
}
break;
case br:
ret = "
";
}
return ret;
}
// ~ private methods
// -------------------------------------------------------------------------------------------------------------
private string generatelinklist(collection<fonts> values) {
if (values == null || values.isempty()) {
return "";
}
object[] valuearr = values.toarray();
stringjoiner linklist = new stringjoiner(valueseparator);
for (int i = 0; i + 1 < valuearr.length; i += 2) {
linklist.add(string.format(link_template, valuearr[i], valuearr[i + 1]));
}
boolean ispairnum = (valuearr.length % 2) == 0;
if (!ispairnum) {
string lasturl = valuearr[valuearr.length - 1].tostring();
linklist.add(string.format(link_template, lasturl, lasturl));
}
return linklist.tostring();
}
private enum type {
/** only plain text, plain text list with a name */
normal,
/**
* text : link name
* values: index 0 is url if existed.
*/
link, link_list,
br,
}
}
// ~ private class & private implements
// -----------------------------------------------------------------------------------------------------------------
private static class section {
private final int depth;
private type type;
private object data;
private section parent;
private list<section> children;
private section(type type, object data, section parent, list<section> children, int depth) {
this.type = type;
this.data = data;
this.parent = parent;
this.children = children;
this.depth = depth;
}
// ~ public methods
// -------------------------------------------------------------------------------------------------------------
public void addchild(section child) {
lazyinitchildren();
children.add(child);
}
public boolean childisempty() {
return children == null || children.isempty();
}
// ~ private methods
// -------------------------------------------------------------------------------------------------------------
private stringbuilder parse(stringbuilder latestdata) {
switch (type) {
case link:
case normal:
latestdata.append('\n').append(parsedata(""));
return latestdata;
case big_title:
latestdata.append('\n').append(parsedata("# "));
return latestdata;
case title:
latestdata.append('\n').append(parsedata("##### "));
return latestdata;
case subtitle:
latestdata.append('\n').append(parsedata("### "));
return latestdata;
case ref:
return parserefsection(latestdata);
case code:
stringbuilder codeblock = new stringbuilder(latestdata.length() + 10);
codeblock.append("\n```").append(latestdata).append("\n```");
return codeblock;
case order_list:
return parseorderlistsection(latestdata);
case un_order_list:
return parseunorderlistsection(latestdata);
case table:
return parsetablesection(latestdata);
case br:
return latestdata.append(parsedata(""));
}
return latestdata;
}
private string parsedata(string prefix) {
if (data == null) {
return "";
}
return prefix + data;
}
private stringbuilder parserefsection(stringbuilder latestdata) {
char[] chars = latestdata.tostring().tochararray();
if (chars.length <= 0) {
return latestdata;
}
stringbuilder data = new stringbuilder(chars.length * 2);
if (chars[0] != '\n') {
data.append("> ");
}
char last = 0;
for (char c : chars) {
if (last == '\n') {
data.append("> ");
}
data.append(c);
last = c;
}
return data;
}
private stringbuilder parseorderlistsection(stringbuilder latestdata) {
char[] chars = latestdata.tostring().tochararray();
if (chars.length <= 0) {
return latestdata;
}
stringbuilder data = new stringbuilder(chars.length * 2);
string padding = string.join("", collections.ncopies(depth * 4, " "));
int order = 1;
if (chars[0] != '\n') {
data.append(padding).append(order++).append(". ");
}
char last = 0;
for (char c : chars) {
if (last == '\n' && c != '\n' && c != ' ') {
data.append(padding).append(order++).append(". ");
}
data.append(c);
last = c;
}
return data;
}
private stringbuilder parseunorderlistsection(stringbuilder latestdata) {
char[] chars = latestdata.tostring().tochararray();
if (chars.length <= 0) {
return latestdata;
}
stringbuilder data = new stringbuilder(chars.length * 2);
string padding = string.join("", collections.ncopies(depth * 4, " "));
if (chars[0] != '\n') {
data.append(padding).append("- ");
}
char last = 0;
for (char c : chars) {
if (last == '\n' && c != '\n' && c != ' ') {
data.append(padding).append("- ");
}
data.append(c);
last = c;
}
return data;
}
private stringbuilder parsetablesection(stringbuilder latestdata) {
if (data != null) {
object[][] tabledata = (object[][]) data;
if (tabledata.length > 0 && tabledata[0].length > 0) {
stringjoiner titles = new stringjoiner(" | "), extras = new stringjoiner(" | ");
for (object t : tabledata[0]) {
titles.add(t != null ? t.tostring() : "");
extras.add("-");
}
latestdata.append("\n\n").append(titles).append('\n').append(extras);
for (int i = 1; i < tabledata.length; i++) {
stringjoiner datajoiner = new stringjoiner(" | ");
for (int j = 0; j < tabledata[i].length; j++) {
datajoiner.add(tabledata[i][j] != null ? tabledata[i][j].tostring() : "");
}
latestdata.append('\n').append(datajoiner);
}
}
}
return latestdata.append('\n');
}
private void lazyinitchildren() {
if (children == null) {
children = new arraylist<>();
}
}
// ~ getter & setter
// -------------------------------------------------------------------------------------------------------------
public type gettype() {
return type;
}
public void settype(type type) {
this.type = type;
}
public object getdata() {
return data;
}
public void setdata(object data) {
this.data = data;
}
public section getparent() {
return parent;
}
public void setparent(section parent) {
this.parent = parent;
}
public list<section> getchildren() {
return children;
}
public void setchildren(list<section> children) {
this.children = children;
}
public int getdepth() {
return depth;
}
private enum type {
/**
* data is {@link metadata} and plain text
*/
normal,
/**
* data is {@link metadata} and h2
*/
big_title,
/**
* data is {@link metadata} and h3
*/
title,
/**
* data is {@link metadata} and h4
*/
subtitle,
/**
* data is {@code null}, content is children
*/
ref,
/**
* data is {@code null}, content is children
*/
code,
/**
* data is matrix, aka string[][]
*/
table,
/**
* data is {@code null}, content is children
*/
order_list,
/**
* data is {@code null}, content is children
*/
un_order_list,
/**
* data is {@link metadata}
*/
link,
br
}
}
public static class sectionbuilder {
private static final mdparser parser = new mdparser();
/**
* first is root
*/
private final section cursec;
/**
* code, ref curr -> par
*/
private section parentsec;
/**
* init null
*/
private sectionbuilder parentbuilder;
private sectionbuilder(section cursec) {
this.cursec = cursec;
}
private sectionbuilder(section cursec, section parentsec, sectionbuilder parentbuilder) {
this.cursec = cursec;
this.parentsec = parentsec;
this.parentbuilder = parentbuilder;
}
// ~ public methods
// -------------------------------------------------------------------------------------------------------------
public sectionbuilder text(string text) {
return text(text, (string) null);
}
public sectionbuilder text(string name, string value) {
if (name != null) {
collection<fonts> values
= value != null ? collections.singletonlist(fonts.of(value)) : collections.emptylist();
cursec.addchild(new section(section.type.normal,
new metadata(metadata.type.normal, fonts.of(name, (style) null), values),
cursec, null, cursec.getdepth()));
}
return this;
}
public sectionbuilder text(string text, style... style) {
if (text != null) {
cursec.addchild(new section(section.type.normal, new metadata(fonts.of(text, style)), cursec,
null, cursec.getdepth()));
}
return this;
}
public sectionbuilder text(collection<string> values) {
if (values != null && !values.isempty()) {
text(null, values);
}
return this;
}
public sectionbuilder text(string name, collection<string> values) {
if (values == null || values.size() <= 0) {
return text(name);
}
return text(name, null, values);
}
public sectionbuilder text(string name, style valuestyle, collection<string> values) {
if (values == null || values.size() <= 0) {
return text(name);
}
if (valuestyle == null) {
valuestyle = style.normal;
}
list<fonts> ele = new arraylist<>(values.size());
for (string value : values) {
ele.add(fonts.of(value, valuestyle));
}
cursec.addchild(new section(section.type.normal, new metadata(fonts.of(name), ele), cursec, null,
cursec.getdepth()));
return this;
}
public sectionbuilder bigtitle(string title) {
if (stringutils.isnotblank(title)) {
cursec.addchild(new section(section.type.big_title, new metadata(fonts.of(title)), cursec,
null, cursec.getdepth()));
}
return this;
}
public sectionbuilder title(string title) {
return title(title, style.normal);
}
public sectionbuilder title(string title, style color) {
if (stringutils.isnotblank(title)) {
cursec.addchild(new section(section.type.title, new metadata(fonts.of(title, color)),
cursec, null, cursec.getdepth()));
}
return this;
}
public sectionbuilder title(string title, fonts... label) {
return title(title, null, label);
}
public sectionbuilder title(string title, style titlecolor, fonts... label) {
if (stringutils.isnotblank(title)) {
if (titlecolor == null) {
titlecolor = style.normal;
}
list<fonts> labellist = label != null ? arrays.aslist(label) : collections.emptylist();
cursec.addchild(new section(section.type.title, new metadata(fonts.of(title, titlecolor), labellist),
cursec, null, cursec.getdepth()));
}
return this;
}
public sectionbuilder subtitle(string title) {
if (stringutils.isnotblank(title)) {
cursec.addchild(new section(section.type.subtitle, new metadata(fonts.of(title)),
cursec, null, cursec.getdepth()));
}
return this;
}
public sectionbuilder ref() {
section refsection = new section(section.type.ref, null, cursec, new arraylist<>(), cursec.getdepth());
cursec.addchild(refsection);
return new sectionbuilder(refsection, cursec, this);
}
public sectionbuilder endref() {
return this.parentbuilder != null ? this.parentbuilder : this;
}
public tabledatabuilder table() {
return new tabledatabuilder(cursec, this);
}
public sectionbuilder link(string url) {
return link(null, url);
}
public sectionbuilder link(string name, string url) {
if (stringutils.isblank(name)) {
name = url;
}
if (stringutils.isnotblank(url)) {
metadata links = new metadata(metadata.type.link, fonts.of(name),
collections.singletonlist(fonts.of(url)));
cursec.addchild(new section(section.type.normal, links, cursec, null, cursec.getdepth()));
}
return this;
}
public sectionbuilder links(map<string, string> urlmappings) {
return links(null, urlmappings);
}
public sectionbuilder links(string name, map<string, string> urlmappings) {
if (urlmappings != null && !urlmappings.isempty()) {
list<fonts> serialurlinfos = new arraylist<>();
for (map.entry<string, string> entry : urlmappings.entryset()) {
string key = entry.getkey();
string value = entry.getvalue();
serialurlinfos.add(fonts.of(key != null ? key : ""));
serialurlinfos.add(fonts.of(value != null ? value : ""));
}
fonts wrappedname = stringutils.isnotblank(name) ? fonts.of(name) : fonts.empty;
metadata linksgroup = new metadata(metadata.type.link_list, wrappedname, serialurlinfos);
cursec.addchild(new section(section.type.normal, linksgroup, cursec, null, cursec.getdepth()));
}
return this;
}
public sectionbuilder ol() {
int depth = (cursec.gettype() == section.type.order_list || cursec.gettype() == section.type.un_order_list)
? cursec.getdepth() + 1
: cursec.getdepth();
section orderlistsec = new section(section.type.order_list, null, cursec, new arraylist<>(), depth);
cursec.addchild(orderlistsec);
return new sectionbuilder(orderlistsec, cursec, this);
}
public sectionbuilder endol() {
return this.parentbuilder != null ? this.parentbuilder : this;
}
public sectionbuilder ul() {
int depth = (cursec.gettype() == section.type.order_list || cursec.gettype() == section.type.un_order_list)
? cursec.getdepth() + 1
: cursec.getdepth();
section unorderlistsec = new section(section.type.un_order_list, null, cursec, new arraylist<>(), depth);
cursec.addchild(unorderlistsec);
return new sectionbuilder(unorderlistsec, cursec, this);
}
public sectionbuilder endul() {
return this.parentbuilder != null ? this.parentbuilder : this;
}
public sectionbuilder code() {
section codesec = new section(section.type.code, null, cursec, new arraylist<>(), cursec.getdepth());
cursec.addchild(codesec);
return new sectionbuilder(codesec, cursec, this);
}
public sectionbuilder endcode() {
return this.parentbuilder != null ? this.parentbuilder : this;
}
public sectionbuilder br() {
cursec.addchild(new section(section.type.br, new metadata(metadata.type.br), parentsec, null,
cursec.getdepth()));
return this;
}
public string build() {
return parser.parse(cursec);
}
}
public static class tabledatabuilder {
private final section parentsec;
private final sectionbuilder parentbuilder;
private object[][] tabledata;
private tabledatabuilder(section parentsec, sectionbuilder parentbuilder) {
this.parentsec = parentsec;
this.parentbuilder = parentbuilder;
}
// ~ public methods
// -------------------------------------------------------------------------------------------------------------
public tabledatabuilder data(object[][] table) {
if (table != null && table.length > 0 && table[0].length > 0) {
tabledata = table;
}
return this;
}
public tabledatabuilder data(object[] title, object[][] data) {
if (title == null && data != null) {
return data(data);
}
if (data != null && data.length > 0 && data[0].length > 0) {
int mincol = math.min(title.length, data[0].length);
tabledata = new object[data.length + 1][mincol];
tabledata[0] = arrays.copyofrange(title, 0, mincol);
for (int i = 0; i < data.length; i++) {
tabledata[i + 1] = arrays.copyofrange(data[i], 0, mincol);
}
}
return this;
}
public sectionbuilder endtable() {
parentsec.addchild(new section(section.type.table, tabledata, parentsec, null, parentsec.getdepth()));
return parentbuilder;
}
}
private static class mdparser {
// ~ public methods
// -------------------------------------------------------------------------------------------------------------
public string parse(section sec) {
section root = findroot(sec);
return doparse(root, root).tostring().trim();
}
// ~ private methods
// -------------------------------------------------------------------------------------------------------------
private section findroot(section sec) {
if (sec.getparent() == null) {
return sec;
}
return findroot(sec.getparent());
}
private stringbuilder doparse(section cur, section root) {
if (cur == null) {
return null;
}
if (cur.childisempty()) {
return cur.parse(new stringbuilder());
}
stringbuilder childdata = new stringbuilder();
for (section child : cur.getchildren()) {
stringbuilder part = doparse(child, root);
if (part != null) {
childdata.append(part);
}
}
return cur.parse(childdata).append(cur.getparent() == root ? '\n' : "");
}
}
}有了通用的markdown语法生成处理类,则可以根据项目要求,再次封装需要生成的对应的文档中的各类元素对象,比如生成有序列表,无序列表,文档首页标题,副标题,链接,图像,表格等
2. 所以再写一个生成类,里边附带了测试方法
package com.xiaomifeng1010.common.markdown.todoc;
import com.xiaomifeng1010.common.markdown.markdownhandler;
import com.xiaomifeng1010.common.utils.markdownutil;
import lombok.data;
import org.apache.commons.collections4.collectionutils;
import java.util.arraylist;
import java.util.arrays;
import java.util.list;
/**
* @author xiaomifeng1010
* @version 1.0
* @date: 2024-09-27 18:08
* @description
*/
public class javatomarkdowngenerator {
public static void main(string[] args) {
string thewholemarkdowncontent = "";
// 生成一个简单的多元素的word文档
javatomarkdowngenerator javatomarkdowngenerator = new javatomarkdowngenerator();
// 首页大标题;注意每部分元素之间一定要换行,不然最后输出到word文档中的时候就会变成带有markdown语法的文本了,
// 比如经济环境分析后边没加"\n\r",那么在word文档中就会变成带有#的目录,会变成 "经济环境分析###目录" 这样子
string title = javatomarkdowngenerator.generatetitle("经济环境分析")+"\n\r";
// 首页目录
string catalog = javatomarkdowngenerator.generatecatalog()+"\n\r";
// 插入项目本地的logo图片
// 注意企业项目中不要直接放在resources目录下,因为获取的路径放在markdown的图片类型的语法中(最终是这样:),
// 在转换word时候还是无法通过路径找到图片,linux系统获取文件需要通过流读取,路径的方式会提示找不到文件,windows系统不受影响
// 所以可以将需要插入到markdown中的图片上传到oss中,然后获取oss的图片的完整地址,网络超链接的形式,再插入到markdown中,
// 这样在转换成word时候,会从网络上下载,以流的方式插入到word中
string imgpath = javatomarkdowngenerator.class.getresource("/static/canton.jpg").getpath();
string logo = javatomarkdowngenerator.resloveimg(imgpath, "logo")+"\n\r";
thewholemarkdowncontent = title + catalog + logo;
// 插入正文
list<list<string>> datalist = new arraylist<>();
// java实践中一般是一个java对象,从数据库查询出来的一个list集合,需要循环获取对象,然后添加到datalist中
// 模拟数据库中查询出来数据
employee employee = new employee();
list<employee> employeelist = employee.getemployees();
if (collectionutils.isnotempty(employeelist)) {
for (employee employee1 : employeelist) {
list<string> list = new arraylist<>();
list.add(employee1.getname());
list.add(employee1.getsex());
list.add(employee1.getage());
list.add(employee1.getheight());
datalist.add(list);
}
string firsttable= javatomarkdowngenerator.generatetable(datalist, "表格1","姓名", "性别", "芳龄", "身高");
thewholemarkdowncontent=thewholemarkdowncontent + firsttable;
}
// 直接拼接一段富文本,因为网页上新增填写内容的时候,有些参数输入是使用的markdown富文本编辑器
string markdowncontent = "\n# 一级标题\n" +
"## 二级标题\n" +
"### 三级标题\n" +
"#### 四级标题\n" +
"##### 五级标题\n" +
"###### 六级标题\n" +
"## 段落\n" +
"这是一段普通的段落。\n" +
"## 列表\n" +
"### 无序列表\n" +
"- 项目1\n" +
"- 项目2\n" +
"- 项目3\n" +
"### 有序列表\n" +
"1. 项目1\n" +
"2. 项目2\n" +
"3. 项目3\n" +
"## 链接\n" +
"[百度](https://www.baidu.com)\n" +
"## 图片\n" +
"\n" +
"## 表格\n" +
"| 表头1 | 表头2 | 表头3 |\n" +
"|-------|-------|-------|\n" +
"| 单元格1 | 单元格2 | 单元格3 |\n" +
"| 单元格4 | 单元格5 | 单元格6 |";
thewholemarkdowncontent=thewholemarkdowncontent+markdowncontent;
markdownutil.todoc(thewholemarkdowncontent,"test228");
system.out.println(catalog);
}
/**
* 使用markdown的有序列表实现生成目录效果
* @return
*/
public string generatecatalog(){
string md = markdownhandler.of()
.subtitle("目录")
// 不要加ref方法,可以正常生成markdown文本,但是在转换成word内容的时候,commonmark会报错
// org.commonmark.node.orderedlist cannot be cast to org.commonmark.node.paragra
// .ol()
.text("文档介绍")
// .endol()
.ol()
.text("经济环境")
.ol()
.text("1.1 全球化背景")
.text("1.2 通缩问题产生的原因")
.text("1.3 如何应对通缩")
.text("1.4 国家实施的财政政策和货币政策")
.endol()
.endol()
.ol()
.text("失业问题")
.ol()
.text("2.1 失业率的概念")
.text("2.2 如何统计失业率")
.text("2.3 如何提升就业率")
.endol()
.endol()
.ol()
.text("理财投资")
.ol()
.text("3.1 理财投资的重要性")
.text("3.2 如何选择理财投资产品")
.text("3.3 理财投资的风险管理")
.endol()
.endol()
.build();
return md;
}
/**
* 生成表格
* @paramjatalist
@paramtablehead
@return
**/
public string generatetable(list<list<string>> datalist, string tabletitle, string... tablehead){
// 添加表头(表格第一行,列标题)
datalist.add( 0, arrays.aslist(tablehead));
string[][] data=datalist.stream().map(list->list.toarray(new string[0])).toarray(string[][]::new);
string markdowncontent = markdownhandler.of()
.title(tabletitle)
.table()
.data(data)
.endtable()
.build();
return markdowncontent;
}
/**
* 文档首页大标题效果
* @param title
* @return
*/
public string generatetitle(string title){
return markdownhandler.of().bigtitle(title).build();
}
/**
* 处理图片
* @param imgpath
* @param imgname
* @return
*/
string resloveimg(string imgpath,string imgname){
return "";
}
}
@data
class employee{
private string name;
private string sex;
private string age;
// 身高
private string height;
// 体重
private string weight;
// 籍贯
private string nativeplace;
// 职位
private string position;
// 薪资
private string salary;
/**
* 模拟从数据库中查出多条数据
* @return
*/
public list<employee> getemployees(){
list<employee> employees = new arraylist<>();
for (int i = 0; i < 10; i++) {
employee employee = new employee();
employee.setname("张三" + i);
employee.setsex("男");
employee.setage("18" + i);
employee.setheight("180" + i);
employee.setweight("70" + i);
employee.setnativeplace("北京" + i);
employee.setposition("java开发" + i);
employee.setsalary("10000" + i);
employees.add(employee);
}
return employees;
}
}
测试main方法会调用markdownutil,用于生成word文档保存在本地,或者通过网络进行下载保存。
3.markdownutil工具类:
package com.xiaomifeng1010.common.utils;
import com.deepoove.poi.xwpftemplate;
import com.deepoove.poi.config.configure;
import com.deepoove.poi.data.style.*;
import com.deepoove.poi.plugin.markdown.markdownrenderdata;
import com.deepoove.poi.plugin.markdown.markdownrenderpolicy;
import com.deepoove.poi.plugin.markdown.markdownstyle;
import lombok.experimental.utilityclass;
import lombok.extern.slf4j.slf4j;
import org.apache.poi.xwpf.usermodel.xwpftable;
import org.apache.poi.xwpf.usermodel.xwpftablecell;
import org.commonmark.node.node;
import org.commonmark.parser.parser;
import org.commonmark.renderer.html.htmlrenderer;
import org.springframework.core.io.classpathresource;
import javax.servlet.http.httpservletresponse;
import java.io.file;
import java.io.ioexception;
import java.io.inputstream;
import java.net.urlencoder;
import java.nio.charset.standardcharsets;
import java.util.hashmap;
import java.util.map;
/**
* @author xiaomifeng1010
* @version 1.0
* @date: 2024-08-24 17:23
* @description
*/
@utilityclass
@slf4j
public class markdownutil {
/**
* markdown转html
*
* @param markdowncontent
* @return
*/
public string markdowntohtml(string markdowncontent) {
parser parser = parser.builder().build();
node document = parser.parse(markdowncontent);
htmlrenderer renderer = htmlrenderer.builder().build();
string htmlcontent = renderer.render(document);
log.info(htmlcontent);
return htmlcontent;
}
/**
* 将markdown格式内容转换为word并保存在本地
*
* @param markdowncontent
* @param outputfilename
*/
public void todoc(string markdowncontent, string outputfilename) {
log.info("markdowncontent:{}", markdowncontent);
markdownrenderdata code = new markdownrenderdata();
code.setmarkdown(markdowncontent);
markdownstyle style = markdownstyle.newstyle();
style = setmarkdownstyle(style);
code.setstyle(style);
// markdown样式处理与word模板中的标签{{md}}绑定
map<string, object> data = new hashmap<>();
data.put("md", code);
configure config = configure.builder().bind("md", new markdownrenderpolicy()).build();
try {
// 获取classpath
string path = markdownutil.class.getclassloader().getresource("").getpath();
log.info("classpath:{}", path);
//由于部署到linux上后,程序是从jar包中去读取resources下的文件的,所以需要使用流的方式读取,所以获取流,而不是直接使用文件路径
// 所以可以这样获取 inputstream resourceasstream = markdownutil.class.getclassloader().getresourceasstream("");
// 建议使用spring的工具类来获取,如下
classpathresource resource = new classpathresource("markdown" + file.separator + "markdown_template.docx");
inputstream resourceasstream = resource.getinputstream();
xwpftemplate.compile(resourceasstream, config)
.render(data)
.writetofile(path + "out_markdown_" + outputfilename + ".docx");
} catch (ioexception e) {
log.error("保存为word出错");
}
}
/**
* 将markdown转换为word文档并下载
*
* @param markdowncontent
* @param response
* @param filename
*/
public void convertanddownloadworddocument(string markdowncontent, httpservletresponse response, string filename) {
log.info("markdowncontent:{}", markdowncontent);
markdownrenderdata code = new markdownrenderdata();
code.setmarkdown(markdowncontent);
markdownstyle style = markdownstyle.newstyle();
style = setmarkdownstyle(style);
code.setstyle(style);
// markdown样式处理与word模板中的标签{{md}}绑定
map<string, object> data = new hashmap<>();
data.put("md", code);
configure configure = configure.builder().bind("md", new markdownrenderpolicy()).build();
try {
filename=urlencoder.encode(filename, standardcharsets.utf_8.name());
//由于部署到linux上后,程序是从jar包中去读取resources下的文件的,所以需要使用流的方式读取,所以获取流,而不是直接使用文件路径
// 所以可以这样获取 inputstream resourceasstream = markdownutil.class.getclassloader().getresourceasstream("");
// 建议使用spring的工具类来获取,如下
classpathresource resource = new classpathresource("markdown" + file.separator + "markdown_template.docx");
inputstream resourceasstream = resource.getinputstream();
response.setheader("content-disposition", "attachment; filename=" + urlencoder.encode(filename, "utf-8") + ".docx");
// contenttype不设置也是也可以的,可以正常解析到
response.setcontenttype("application/vnd.openxmlformats-officedocument.wordprocessingml.document;charset=utf-8");
xwpftemplate template = xwpftemplate.compile(resourceasstream, configure)
.render(data);
template.writeandclose(response.getoutputstream());
} catch (ioexception e) {
log.error("下载word文档失败:{}", e.getmessage());
}
}
/**
* 设置转换为word文档时的基本样式
* @param style
* @return
*/
public markdownstyle setmarkdownstyle(markdownstyle style) {
// 一定设置为false,不然生成的word文档中各元素前边都会加上有层级效果的一串数字,
// 比如一级标题 前边出现1 二级标题出现1.1 三级标题出现1.1.1这样的数字
style.setshowheadernumber(false);
// 修改默认的表格样式
// table header style(表格头部,通常为表格顶部第一行,用于设置列标题)
rowstyle headerstyle = new rowstyle();
cellstyle cellstyle = new cellstyle();
// 设置表格头部的背景色为灰色
cellstyle.setbackgroundcolor("cccccc");
style textstyle = new style();
// 设置表格头部的文字颜色为黑色
textstyle.setcolor("000000");
// 头部文字加粗
textstyle.setbold(true);
// 设置表格头部文字大小为12
textstyle.setfontsize(12);
// 设置表格头部文字垂直居中
cellstyle.setvertalign(xwpftablecell.xwpfvertalign.center);
cellstyle.setdefaultparagraphstyle(paragraphstyle.builder().withdefaulttextstyle(textstyle).build());
headerstyle.setdefaultcellstyle(cellstyle);
style.settableheaderstyle(headerstyle);
// table border style(表格边框样式)
borderstyle borderstyle = new borderstyle();
// 设置表格边框颜色为黑色
borderstyle.setcolor("000000");
// 设置表格边框宽度为3px
borderstyle.setsize(3);
// 设置表格边框样式为实线
borderstyle.settype(xwpftable.xwpfbordertype.single);
style.settableborderstyle(borderstyle);
// 设置普通的引用文本样式
paragraphstyle quotestyle = new paragraphstyle();
// 设置段落样式
quotestyle.setspacingbeforelines(0.5d);
quotestyle.setspacingafterlines(0.5d);
// 设置段落的文本样式
style quotetextstyle = new style();
quotetextstyle.setcolor("000000");
quotetextstyle.setfontsize(8);
quotetextstyle.setitalic(true);
quotestyle.setdefaulttextstyle(quotetextstyle);
style.setquotestyle(quotestyle);
return style;
}
public static void main(string[] args) {
string markdowncontent = "# 一级标题\n" +
"## 二级标题\n" +
"### 三级标题\n" +
"#### 四级标题\n" +
"##### 五级标题\n" +
"###### 六级标题\n" +
"## 段落\n" +
"这是一段普通的段落。\n" +
"## 列表\n" +
"### 无序列表\n" +
"- 项目1\n" +
"- 项目2\n" +
"- 项目3\n" +
"### 有序列表\n" +
"1. 项目1\n" +
"2. 项目2\n" +
"3. 项目3\n" +
"## 链接\n" +
"[百度](https://www.baidu.com)\n" +
"## 图片\n" +
"\n" +
"## 表格\n" +
"| 表头1 | 表头2 | 表头3 |\n" +
"|-------|-------|-------|\n" +
"| 单元格1 | 单元格2 | 单元格3 |\n" +
"| 单元格4 | 单元格5 | 单元格6 |";
todoc(markdowncontent, "test23");
}
}
4.最终的输出效果
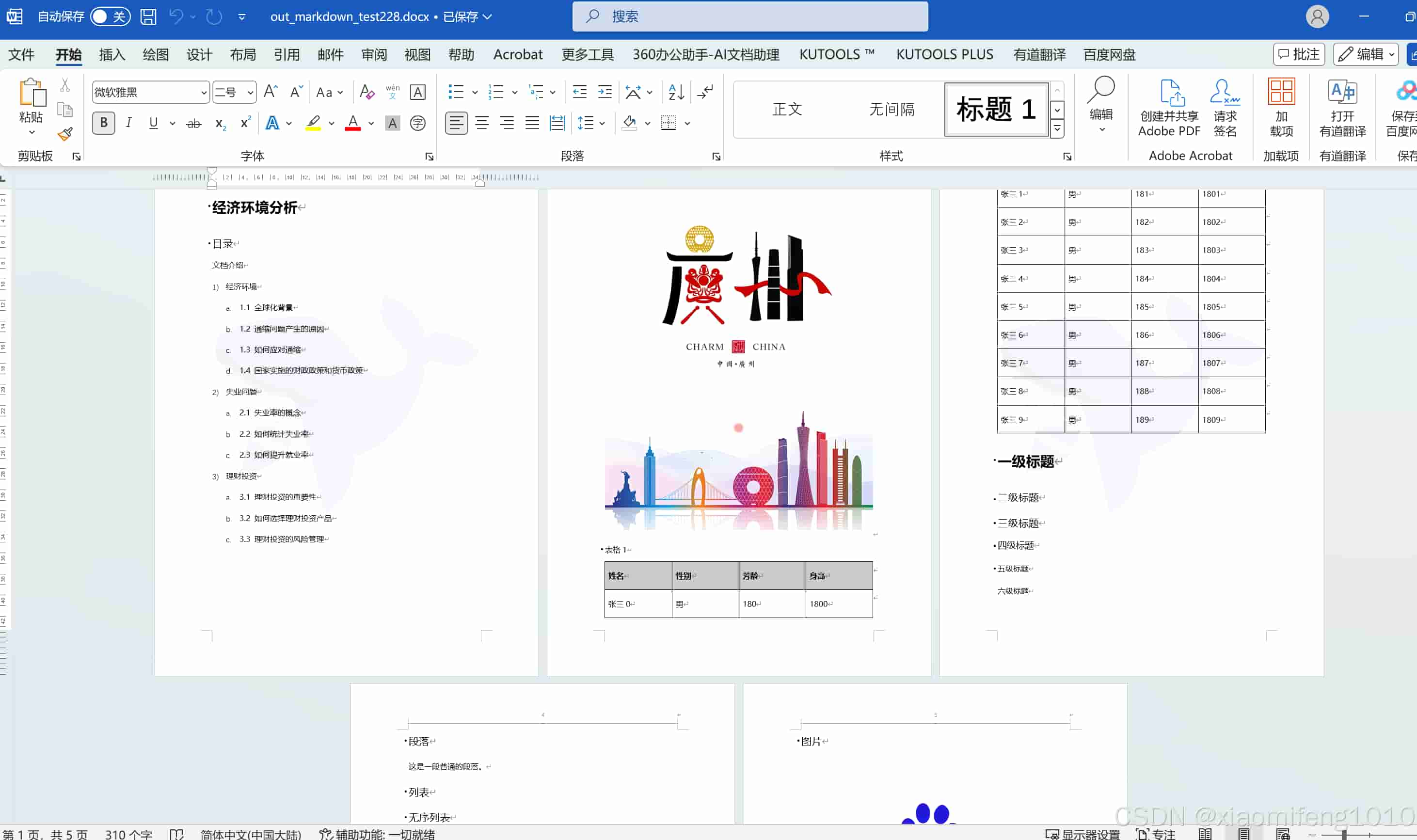
注意在生成有序列表或者无序列表时候不要加ref方法,因为加了ref方法虽然可以正常生成markdown文本,但是在转换成word内容的时候,commonmark会报错org.commonmark.node.orderedlist cannot be cast to org.commonmark.node.paragra
还有一个注意事项,就是换行不要直接调用br()方法,因为转换的时候,在word文档中转换不了,直接生成了“<br>” 这样的文字,所以直接在markdown文本中使用"\n"来换行
总结
到此这篇关于java生成markdown格式内容的文章就介绍到这了,更多相关java生成markdown格式内容内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!

发表评论