1、背景
随着ai的快速发展,越来越多的ai应用诞生了,但是ai也有响应慢的问题,一般不能够即时响应,为了优化用户体验,现在大部分ai应用都是实现了打字机的效果,那么这种效果是如何实现的呢?今天我们先看一下后端的实现逻辑。
代码流程是后端发出请求,请求智能体或ai模型暴露的流式接口,然后返回一个流式接口。
为什么不直接前端请求ai接口,因为有的ai接口在前端直接请求,可能会出现跨域问题。因为ai接口返回的响应中没有包含跨域的access-control-allow-origin。
2、实现步骤
1、引入依赖
<dependency>
<groupid>org.springframework.boot</groupid>
<artifactid>spring-boot-starter-webflux</artifactid>
</dependency>2、使用webclient发起对ai接口请求
代码中的url,请求头、请求体或者请求方法都可以按照对应的ai接口文档进行替换。
webclient webclient = webclient.create();
flux<string> resultflux = webclient.post()
.uri(url) //请求url
.header(httpheaders.content_type, mediatype.application_json_value)
.header(httpheaders.authorization, "bearer "+ api_key) // 添加认证头部
.bodyvalue(requestbody)//请求体
.retrieve()
.bodytoflux(string.class); //返回流式结果3、启动类需要添加@enableasync注解
4、如果工程中有过滤器,需要进行配置
我的工程启动后报错
async support must be enabled on a servlet and for all filters involved in async request processing. this is done in java code using the servlet api or by adding "<async-supported>true</async-supported>" to servlet and filter declarations in web.xml.
大概意思是异步支持必须在servlet和所有的过滤器中被标注成是enabled
servlet和filter声明:如果您使用的是基于xml的配置,可以在web.xml文件中的servlet和filter声明中添加<async-supported>true</async-supported>元素来启用异步支持
<servlet>
<servlet-name>myservlet</servlet-name>
<servlet-class>com.example.myasyncservlet</servlet-class>
<async-supported>true</async-supported>
</servlet>
<filter>
<filter-name>myfilter</filter-name>
<filter-class>com.example.myasyncfilter</filter-class>
<async-supported>true</async-supported>
</filter>如果您使用的是基于注解的配置或java配置类,可以通过实现javax.servlet.servlet接口并覆盖isasyncsupported()方法返回true,或者通过@webservlet和@webfilter注解的asyncsupported属性来设置。我使用的是这种方式
@webservlet(urlpatterns = "/async", asyncsupported = true)
public class myasyncservlet extends httpservlet {
// ...
}
@webfilter(urlpatterns = "/*", asyncsupported = true)
public class myasyncfilter implements filter {
// ...
}5、postman发送请求后结果
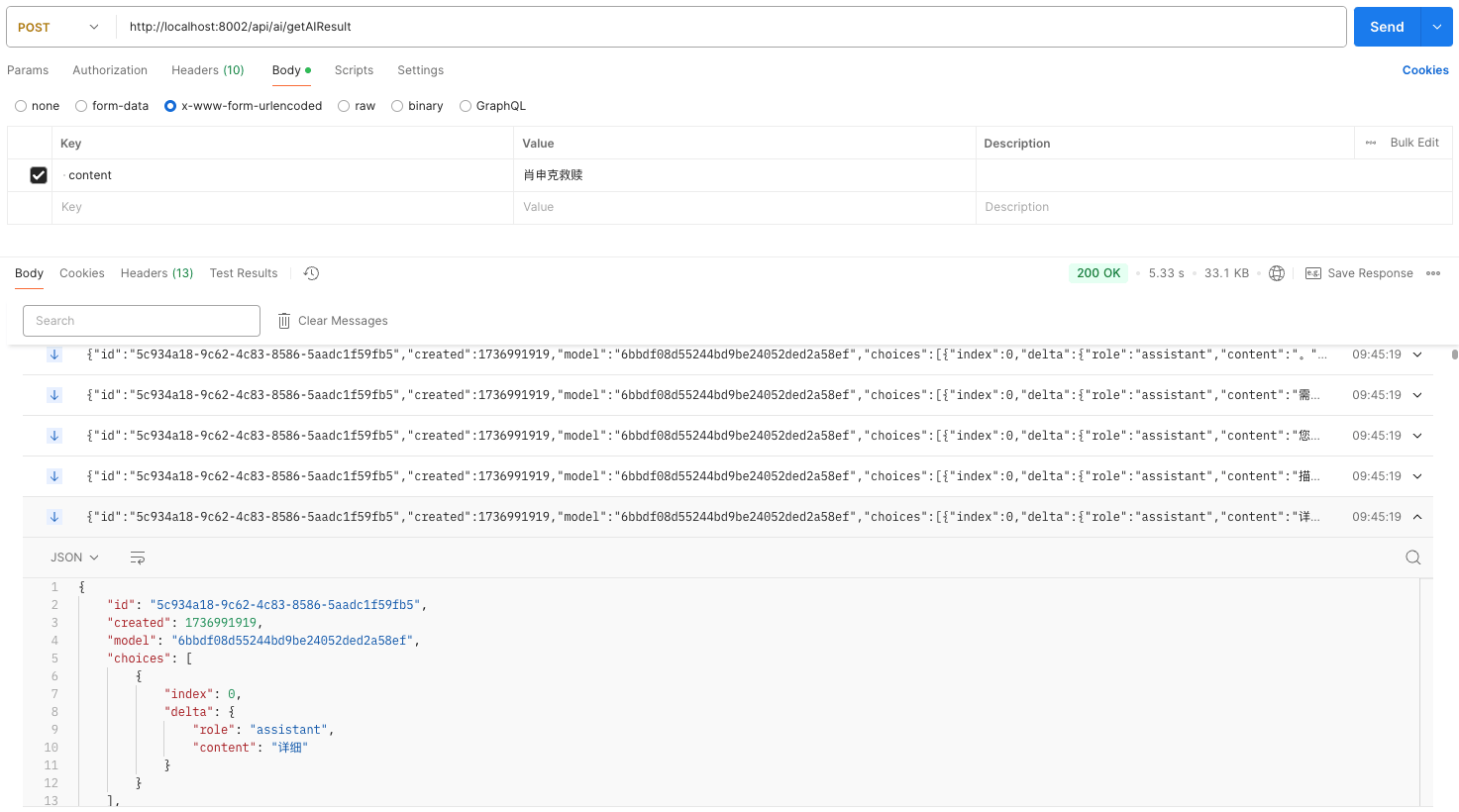
controller类接口
@requestmapping(method = requestmethod.post, value = "/getairesult",produces = mediatype.text_event_stream_value)
flux<string> getairesult(@requestbody string content){
// 构建请求体
hashmap<string, object> requestbody = new hashmap<>();
requestbody.put("model", "6bbdf08d55244bd9be24052ded2a58ef");
requestbody.put("context",0);
requestbody.put("stream", true);
list<hashmap<string, string>> messages = new arraylist<>();
hashmap<string, string> message = new hashmap<>();
message.put("role", "user");
message.put("content", content);
messages.add(message);
requestbody.put("messages", messages);
webclient webclient = webclient.create();
flux<string> resultflux = webclient.post()
.uri(url)
.header(httpheaders.content_type, mediatype.application_json_value)
.header(httpheaders.authorization, "bearer "+ api_key) // 添加认证头部
.bodyvalue(requestbody)
.retrieve()
.bodytoflux(string.class);
// 输出响应结果
// // 订阅响应以触发实际的 http 请求
// resultflux.subscribe(
// response -> system.out.println("response received: " + response),
// error -> system.err.println("error occurred: " + error.getmessage())
// );
return resultflux;
}3、使用技术介绍
webflux
webflux模块是spring 5引入的一部分,旨在提供一种新的方式来构建响应式的web应用程序。它允许你以异步和非阻塞的方式处理http请求,这在处理高并发场景时可以显著提高性能。
webflux的特点
- 非阻塞i/o:与传统的servlet api不同,webflux使用的是非阻塞i/o模型,这意味着它可以更有效地利用线程资源。
- 反应式编程:webflux内置了对反应式编程的支持,主要通过reactor库实现,使得编写和处理异步代码更加容易。
- 函数式路由:除了注解驱动的控制器,webflux还提供了函数式路由api,让你能够以声明性的方式定义路由规则。
以上来自ai内容生成,看完一头雾水,下方给出介绍
非阻塞i/o
含义:非阻塞i/o(non-blocking i/o)是一种编程模型,它允许应用程序在等待某些操作完成时不会被阻塞。与传统的servlet api(如spring mvc)相比,webflux采用了基于事件和回调的非阻塞i/o模型。
- 传统servlet api (阻塞i/o):在传统的servlet环境中,每个http请求都会分配一个线程来处理。如果这个处理过程包含了一个长时间运行的操作(例如数据库查询或网络调用),那么该线程会被阻塞直到操作完成。这意味着线程不能用来处理其他请求,从而降低了服务器的效率。
- webflux (非阻塞i/o):webflux使用了netty这样的异步网络框架,它们可以在不阻塞线程的情况下执行i/o操作。当一个请求涉及到耗时的任务时,它不会阻塞当前的线程;相反,任务完成后会触发相应的回调函数继续处理。这种方式使得单个线程可以处理多个并发请求,极大地提高了资源利用率和服务的吞吐量。
反应式编程
含义:反应式编程(reactive programming)是一种面向数据流和变化传播的编程范式。它强调的是通过声明式的代码来描述数据流的变化,并能够对这些变化做出响应。webflux内置了对反应式编程的支持,主要通过project reactor库实现,这是spring 5引入的一个核心特性。
- reactor库:reactor提供了两个核心类型——
mono和flux,分别表示0到1个元素的异步序列和0到n个元素的异步序列。开发者可以使用这些类型来构建复杂的异步逻辑,而不需要显式地管理线程或同步问题。 - 好处:
- 简化异步编程:通过组合操作符(如
map,flatmap,filter等),你可以轻松地创建复杂的异步工作流,同时保持代码的简洁性和可读性。 - 错误处理:reactor还提供了一套强大的错误处理机制,比如
onerrorresume、retry等,使得处理异常情况更加直观。 - 背压支持:对于生产者-消费者模式中的流量控制,reactor实现了背压(backpressure),确保系统不会因为过载而崩溃。
- 简化异步编程:通过组合操作符(如
函数式路由
含义:函数式路由是webflux提供的另一种定义http端点的方式,除了传统的注解驱动控制器之外。它允许你以一种声明性的、函数式的方式来配置路由规则,这在某些情况下可能比注解更灵活、更具表达力。
- routerfunction和handlerfunction:在函数式路由中,
routerfunction用于定义路由匹配逻辑,而handlerfunction则负责处理实际的请求。两者结合在一起,可以非常清晰地表达出“如果路径匹配,则执行某个处理器”的意图。
到此这篇关于用spring boot轻松实现流式ai输出的文章就介绍到这了,更多相关spring boot流式ai输出内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论