引言
在日常工作中,我们经常需要从pdf文档中提取文本内容。虽然市面上有不少相关工具,但它们要么功能过于复杂,要么使用不够方便。本文将介绍如何使用python开发一个简单实用的pdf文本提取工具,该工具具有图形界面,操作简单直观。
c:\pythoncode\new\gettxtfrompdffromx2y.py
全部代码
import wx
import pypdf2
import os
class pdfconverterframe(wx.frame):
def __init__(self):
super().__init__(parent=none, title='pdf to txt converter', size=(500, 300))
self.pdf_path = ''
self.initui()
def initui(self):
panel = wx.panel(self)
vbox = wx.boxsizer(wx.vertical)
# 文件选择按钮
file_btn = wx.button(panel, label='选择pdf文件')
file_btn.bind(wx.evt_button, self.onchoosefile)
vbox.add(file_btn, 0, wx.all | wx.center, 5)
# 显示所选文件路径
self.path_text = wx.textctrl(panel, style=wx.te_readonly)
vbox.add(self.path_text, 0, wx.all | wx.expand, 5)
# 页面范围输入
hbox1 = wx.boxsizer(wx.horizontal)
start_label = wx.statictext(panel, label='开始页码:')
self.start_page = wx.spinctrl(panel, value='1', min=1)
end_label = wx.statictext(panel, label='结束页码:')
self.end_page = wx.spinctrl(panel, value='1', min=1)
hbox1.add(start_label, 0, wx.all | wx.center, 5)
hbox1.add(self.start_page, 0, wx.all, 5)
hbox1.add(end_label, 0, wx.all | wx.center, 5)
hbox1.add(self.end_page, 0, wx.all, 5)
vbox.add(hbox1, 0, wx.all | wx.center, 5)
# 生成按钮
generate_btn = wx.button(panel, label='生成txt')
generate_btn.bind(wx.evt_button, self.ongenerate)
vbox.add(generate_btn, 0, wx.all | wx.center, 5)
# 状态显示
self.status_text = wx.textctrl(panel, style=wx.te_multiline | wx.te_readonly)
vbox.add(self.status_text, 1, wx.all | wx.expand, 5)
panel.setsizer(vbox)
self.centre()
def onchoosefile(self, event):
with wx.filedialog(self, "选择pdf文件", wildcard="pdf files (*.pdf)|*.pdf",
style=wx.fd_open | wx.fd_file_must_exist) as filedialog:
if filedialog.showmodal() == wx.id_cancel:
return
self.pdf_path = filedialog.getpath()
self.path_text.setvalue(self.pdf_path)
# 更新最大页码
try:
with open(self.pdf_path, 'rb') as file:
pdf = pypdf2.pdfreader(file)
max_pages = len(pdf.pages)
self.start_page.setmax(max_pages)
self.end_page.setmax(max_pages)
self.end_page.setvalue(max_pages)
self.status_text.setvalue(f"pdf文件共 {max_pages} 页")
except exception as e:
self.status_text.setvalue(f"读取pdf文件失败: {str(e)}")
def ongenerate(self, event):
if not self.pdf_path:
wx.messagebox('请先选择pdf文件', '提示', wx.ok | wx.icon_information)
return
start = self.start_page.getvalue()
end = self.end_page.getvalue()
if start > end:
wx.messagebox('开始页码不能大于结束页码', '错误', wx.ok | wx.icon_error)
return
try:
# 生成输出文件名
output_path = os.path.splitext(self.pdf_path)[0] + '_output.txt'
with open(self.pdf_path, 'rb') as file:
pdf = pypdf2.pdfreader(file)
with open(output_path, 'w', encoding='utf-8') as output:
for page_num in range(start - 1, end):
text = pdf.pages[page_num].extract_text()
output.write(f'=== 第 {page_num + 1} 页 ===\n')
output.write(text)
output.write('\n\n')
self.status_text.setvalue(f"转换完成!\n输出文件保存在: {output_path}")
except exception as e:
self.status_text.setvalue(f"转换失败: {str(e)}")
wx.messagebox(f'转换失败: {str(e)}', '错误', wx.ok | wx.icon_error)
if __name__ == '__main__':
app = wx.app()
frame = pdfconverterframe()
frame.show()
app.mainloop()
功能需求分析
在开发之前,我们先明确工具的核心功能需求:
- 提供图形界面,方便用户操作
- 支持选择pdf文件
- 可以指定提取的页面范围
- 将提取的文本保存为txt文件
- 显示操作状态和结果
技术选型
基于上述需求,我们选择以下技术栈:
- python: 作为主要开发语言
- wxpython: 用于开发图形界面
- pypdf2: 用于处理pdf文件
wxpython是一个功能强大的gui工具包,它能够创建原生风格的界面,性能好,使用简单。pypdf2则是一个广受欢迎的pdf处理库,支持读取文本、提取页面等操作。
环境准备
在开始开发之前,需要先安装必要的库:
pip install wxpython pypdf2
详细设计和实现
1. 界面设计
我们的界面采用垂直布局,从上到下依次包含:
- 文件选择按钮
- 文件路径显示区域
- 页码范围输入区域(开始页码和结束页码)
- 生成按钮
- 状态显示区域
2. 核心代码实现
让我们一步步实现这个工具:
2.1 创建主窗口类
class pdfconverterframe(wx.frame):
def __init__(self):
super().__init__(parent=none, title='pdf to txt converter', size=(500, 300))
self.pdf_path = ''
self.initui()
这是我们的主窗口类,继承自wx.frame。在构造函数中,我们设置了窗口标题和大小,并初始化了ui。
2.2 界面初始化
def initui(self):
panel = wx.panel(self)
vbox = wx.boxsizer(wx.vertical)
# 文件选择按钮
file_btn = wx.button(panel, label='选择pdf文件')
file_btn.bind(wx.evt_button, self.onchoosefile)
vbox.add(file_btn, 0, wx.all | wx.center, 5)
# 显示所选文件路径
self.path_text = wx.textctrl(panel, style=wx.te_readonly)
vbox.add(self.path_text, 0, wx.all | wx.expand, 5)
在初始化界面时,我们使用wx.boxsizer来管理布局,这样可以确保界面元素排列整齐,并且能够适应窗口大小的变化。
2.3 文件选择功能
def onchoosefile(self, event):
with wx.filedialog(self, "选择pdf文件", wildcard="pdf files (*.pdf)|*.pdf",
style=wx.fd_open | wx.fd_file_must_exist) as filedialog:
if filedialog.showmodal() == wx.id_cancel:
return
self.pdf_path = filedialog.getpath()
self.path_text.setvalue(self.pdf_path)
文件选择对话框使用wx.filedialog实现,我们设置了文件过滤器,只显示pdf文件。当用户选择文件后,会更新显示路径,并自动获取pdf的页数信息。
2.4 转换功能实现
def ongenerate(self, event):
if not self.pdf_path:
wx.messagebox('请先选择pdf文件', '提示', wx.ok | wx.icon_information)
return
start = self.start_page.getvalue()
end = self.end_page.getvalue()
try:
output_path = os.path.splitext(self.pdf_path)[0] + '_output.txt'
with open(self.pdf_path, 'rb') as file:
pdf = pypdf2.pdfreader(file)
with open(output_path, 'w', encoding='utf-8') as output:
for page_num in range(start - 1, end):
text = pdf.pages[page_num].extract_text()
output.write(f'=== 第 {page_num + 1} 页 ===\n')
output.write(text)
output.write('\n\n')
转换功能的核心是使用pypdf2读取pdf内容,然后将文本写入新的txt文件。我们在每页内容前添加了页码标记,方便阅读。
异常处理
为了提高程序的健壮性,我们添加了完善的异常处理:
- 文件选择验证
- 页码范围验证
- 文件读写异常处理
- pdf解析异常处理
try:
# 转换操作
...
except exception as e:
self.status_text.setvalue(f"转换失败: {str(e)}")
wx.messagebox(f'转换失败: {str(e)}', '错误', wx.ok | wx.icon_error)
运行效果
程序运行后会显示一个简洁的窗口,用户可以:
- 点击"选择pdf文件"按钮选择需要处理的pdf文件
- 输入需要提取的页面范围
- 点击"生成txt"按钮开始转换
- 在状态区域查看转换结果
生成的txt文件会自动保存在原pdf文件所在的目录下,文件名为原pdf文件名加上"_output.txt"后缀。
优化建议
- 添加进度条显示转换进度
- 支持批量处理多个pdf文件
- 添加文本编码选项
- 支持更多输出格式(如word、html等)
- 添加文本提取方式的选项(按段落、按行等)
运行结果
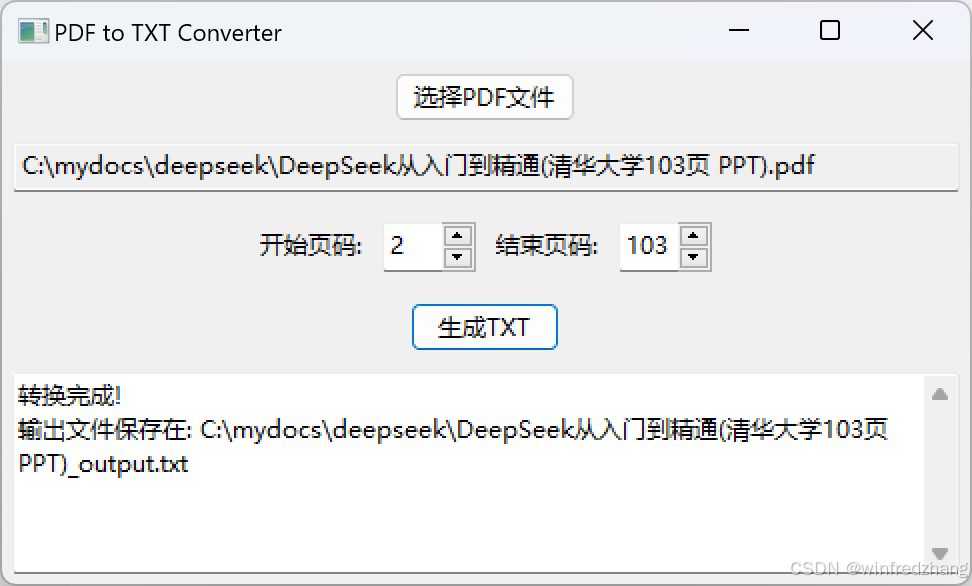
以上就是使用python开发一个pdf文本提取工具的详细内容,更多关于python pdf文本提取的资料请关注代码网其它相关文章!






发表评论