redis分布式锁
如果追求高可用性(ap) 就采用redis
如果追求高一致性(cp) 就采用zookeeper
加锁方式
set lockkey uniqueid nx px expiretime
lockkey可以根据业务自己定义(如订单)uniqueid是为了不解错锁(uniqueid可以是session id 或者线程id等)
怎么会解错锁?举个小案例吧
- s1 获得lock,ttl时间5s,实际执行了7s
- s2 获得lock,ttl时间5s,实际执行了4s
如果没有uniqueid s1在第7s的时候解锁,或解了s2的锁
nx代表当前不存在锁的时候才能加锁成功px毫秒过期时间,如果是秒就用es
解锁方式
通过lua脚本实现原子操作,先进行uniqueid对比操作,如果相同,则执行del解锁操作
if redis.call("get",keys[1]) == argv[1]
then
return redis.call("del",keys[1])
else
return 0
end续期
当分布式锁到达了超时时间,但是业务并没有完成,则将对锁进行续期
s1 获得lock,ttl时间5s,实际执行了7s,如果没有续期那么s1后2秒就没有锁
续期的两种方式:
- 开启一个后台守护线程,每隔3秒对key设置ttl时间5s进行续期,当主线程执行完操作之后,对key进行解锁,那么守护进行也随之消亡
- 采用异步任务,获得锁后,把所有锁的线程放到一个map里,然后每隔几秒进行轮询,如果客户端还持有锁(即map中还存在),就延长ttl时间
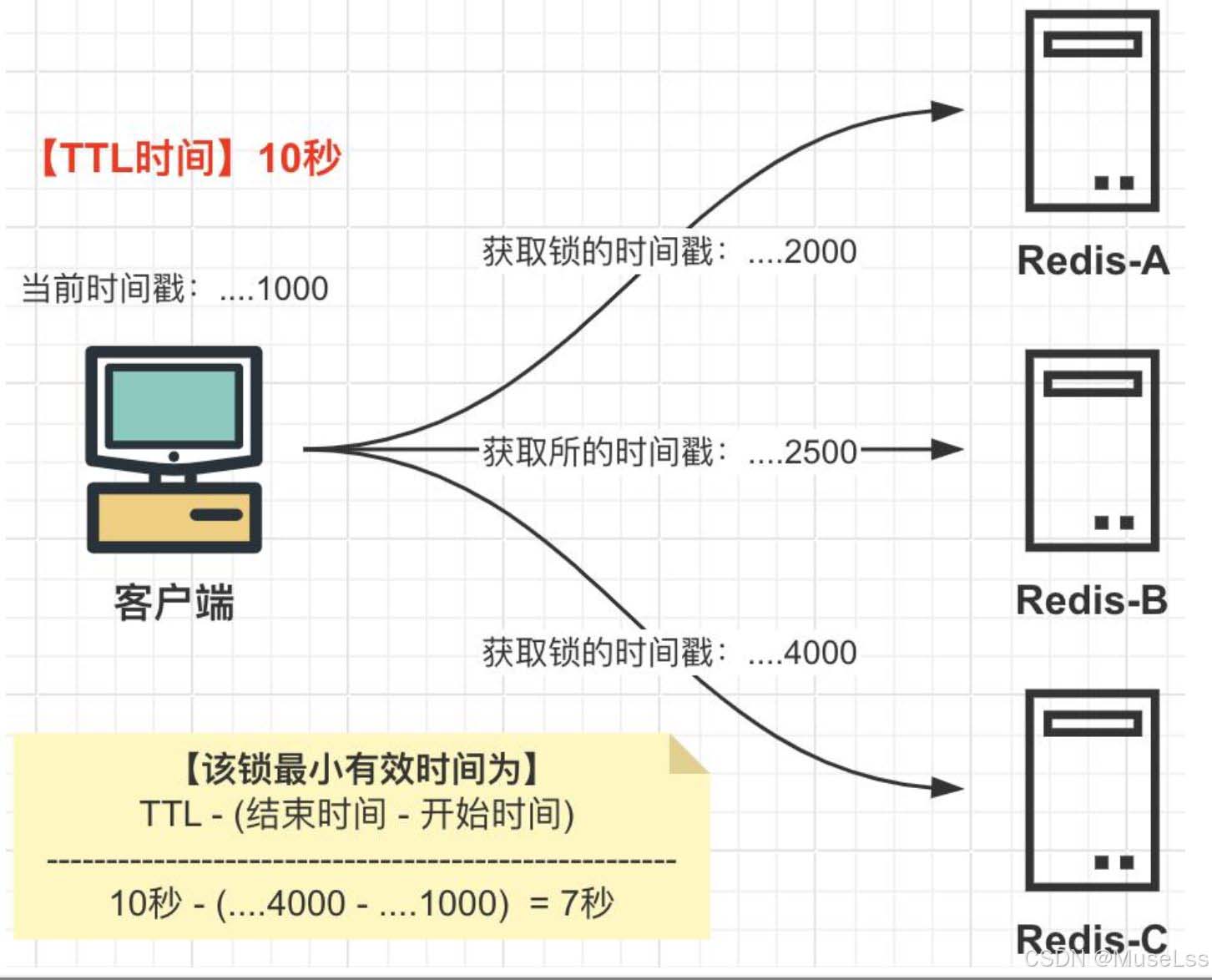
redlock算法对应的场景 主节点挂掉后,lockkey还未同步到从节点,导致从节点上没有lockkey(发生概率很小,面试官喜欢在ap模型里解决cp模型的问题)
- 对3个完全独立的redis主服务器一次获得锁(一般要基数个,为了少数服从多数)
- 如图请求时间4000-1000=3s小于ttl时间5s,并且至少有半数(大于2个)获得锁,才算真正获得锁
缺点(已废弃,不常用,因此只学习算法思想)
- 复杂度高,需要设计一些算法去实现
- 不可靠,如果redis主服务器宕机,会影响到锁的使用(即少数服从多数会受影响)
- 性能瓶颈,需要访问多个redis实例
- 另外最要命的是还需要求所有redis主服务器的系统时间一致性
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。






发表评论