分库分表解决的问题
单表数据量过大带来的性能和存储容量的限制的问题:
- 索引效率下降
- 读写瓶颈
- 存储容量限制
- 事务性能问题
分库分表架构
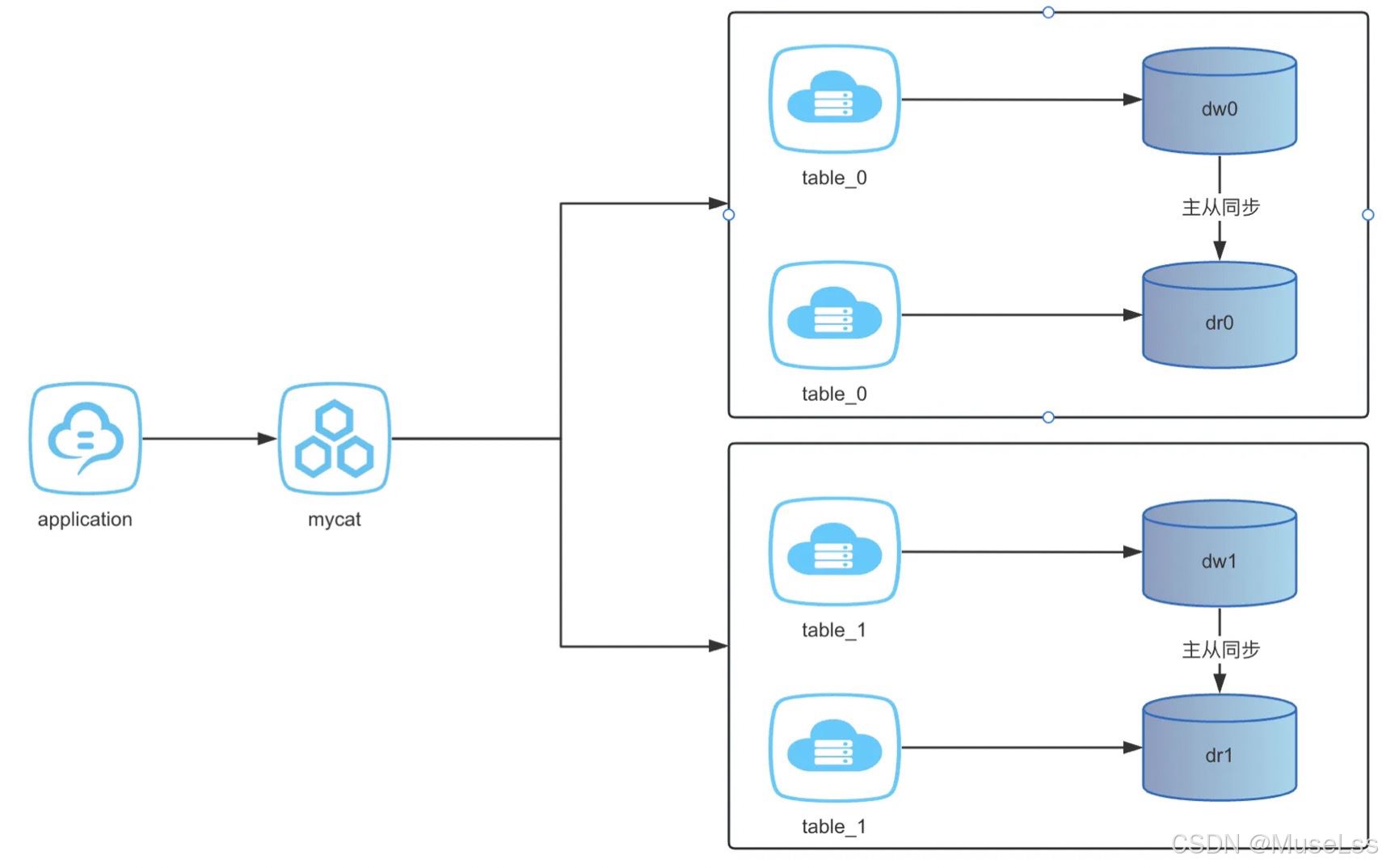
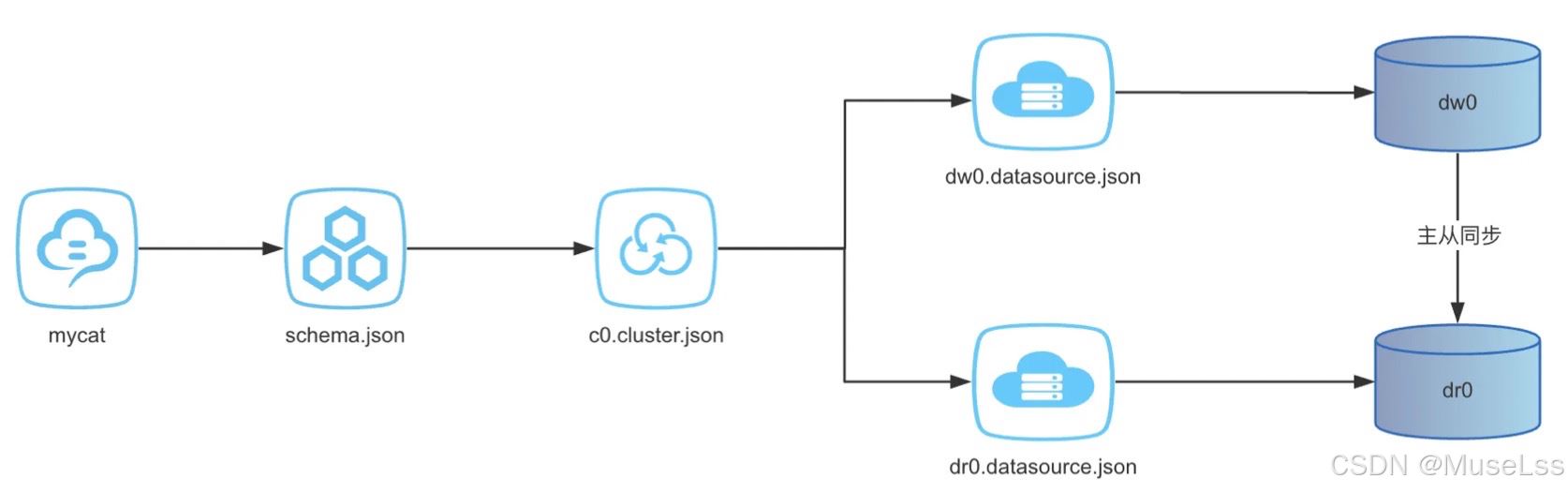
- 再搭建一对主从复制节点,3307主节点,3309从节点
- 配置数据源 dw1 , dr1,
- 创建集群c1
- 创建逻辑库 create database clusterdb;
- 创建广播表 broadcast代表广播表,意味着所有的数据源都会创建这张表
create table clusterdb.`dict_type` ( `id` int(11) unsigned not null auto_increment comment '主键', `type_id` int(11) not null comment '业务类型id', `name` varchar(255) default null comment '名称', primary key (`id`) using btree )engine=innodb default charset=utf8 comment='类型字典' broadcast;
添加数据
insert into clusterdb.`dict_type` values (1,1,'发货单'); insert into clusterdb.`dict_type` values (2,2,'收货单'); insert into clusterdb.`dict_type` values (3,3,'出库单'); insert into clusterdb.`dict_type` values (4,4,'入库单'); insert into clusterdb.`dict_type` values (5,5,'出室单'); insert into clusterdb.`dict_type` values (6,6,'入室单');
验证一下是否每个数据节点都有数据
创建分片库表
- 分库分片表就是把数据按照特定的算法,分配到不同的数据库表中,达到降低单表数据量过大导致的效率问题。
create table clusterdb.orders( `id` int(11) unsigned not null auto_increment comment '主键', `order_type` int(11) not null comment '业务类型id', `order_name` varchar(255) default null comment '名称', primary key (`id`) using btree )engine=innodb default charset=utf8 dbpartition by mod_hash(id) tbpartition by mod_hash(id) tbpartitions 1 dbpartitions 2; insert into clusterdb.orders values(1,1,'test1'); insert into clusterdb.orders values(2,1,'test2'); insert into clusterdb.orders values(3,2,'test3'); insert into clusterdb.orders values(4,3,'test4'); insert into clusterdb.orders values(5,3,'test5'); insert into clusterdb.orders values(6,4,'test6'); insert into clusterdb.orders values(7,5,'test7'); insert into clusterdb.orders values(8,5,'test8'); insert into clusterdb.orders values(9,5,'test9'); insert into clusterdb.orders values(10,5,'test10');
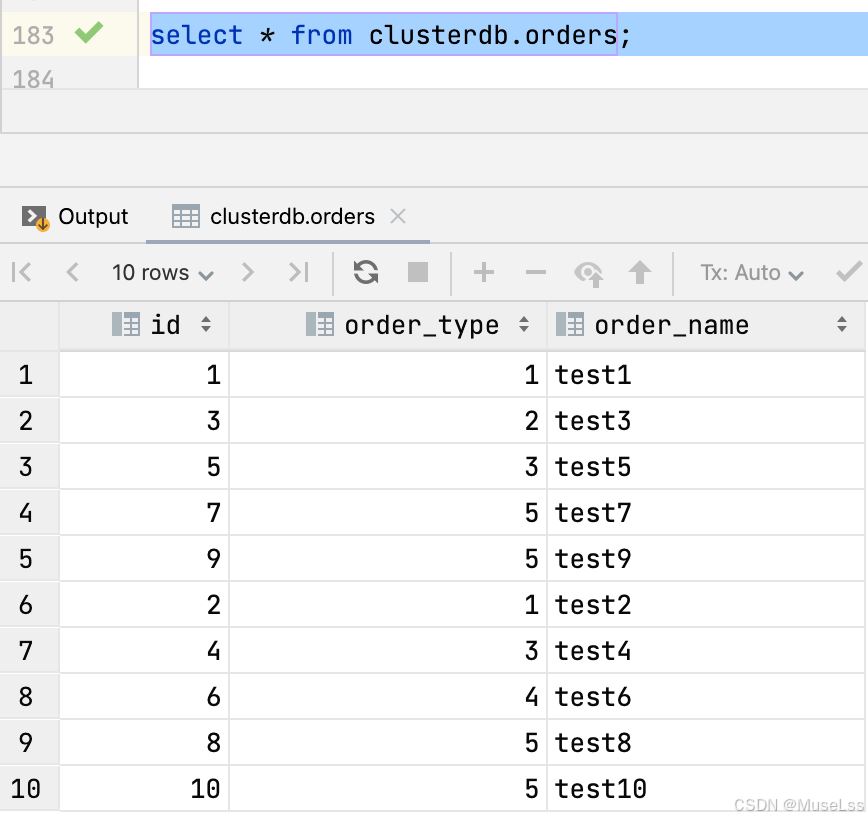
验证结果
在mycat进行查询 select * from clusterdb.orders; 能得到全部的结果
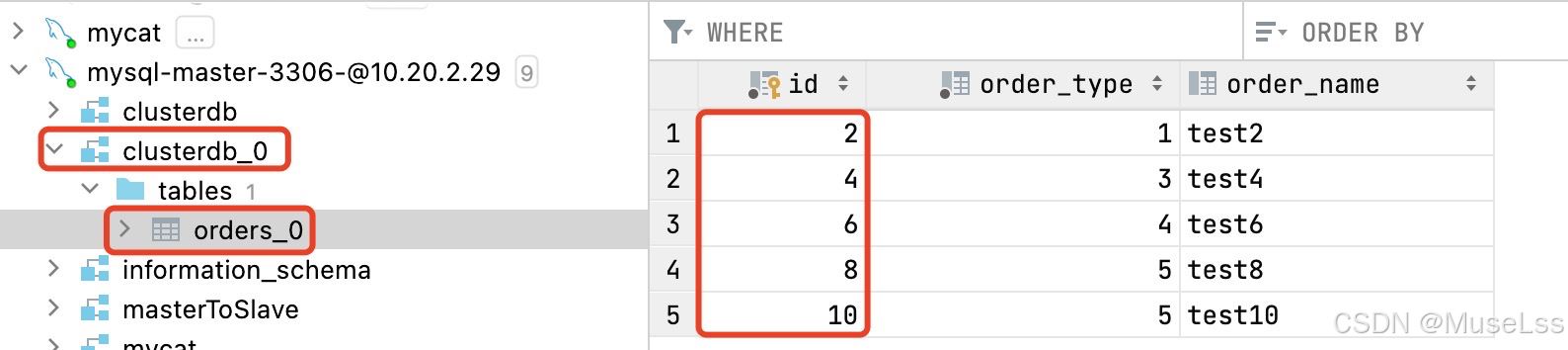
主节点1,自动创建clusterdb_0 orders_0 并且存放的是id偶数的数据
主节点2,自动创建clusterdb_1 orders_1 并且存放的id是基数的数据
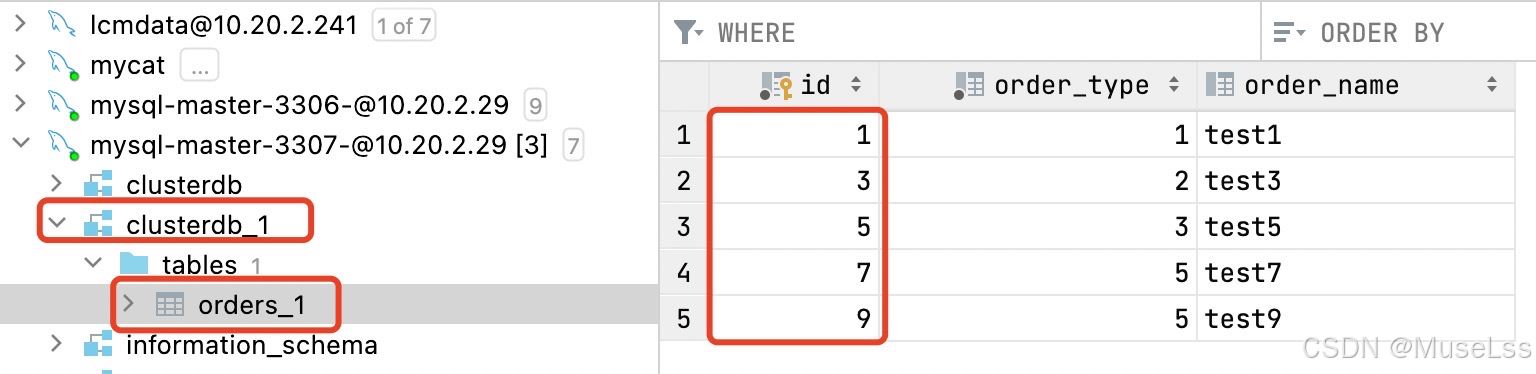
到这里分库分表就成功啦~~
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。






发表评论