1.简介
这是一个python文件去重的工具,市面上很多检测重复工具的软件,都是要付费或者要破解的。于是就想着能不能自己做一个后台每时每刻都可以自己去重的工具。虽然市面上很多检测重复工具的软件. 但是这个工具使用环境和那些工具很不一样。 别的工具删重复文件, 都是扫描,自己删除.。需要人工值守.。这边的工具扫描删除不需要人工值守,并且可以后台运行。这边设置好了,就可以吃着火锅唱着歌干别的去了。只要电脑不断电可以一直运行操作。别的软件必须得等扫描完,才能做下一步操作,这个是本质区别。
2.工具功能
1 通过检测md5,来判断是否有文件重复,检测过后,可以自行选择删除或者不删除,.或者移动到回收站还是直接删除。
2 循环检测指定目录的重复文件,只要是新生成了重复文件,就会立刻被删除。
3 删除默认会保留最早的文件。
**注:**只要文件属性不一样,即使文件名一样也能查重成功。
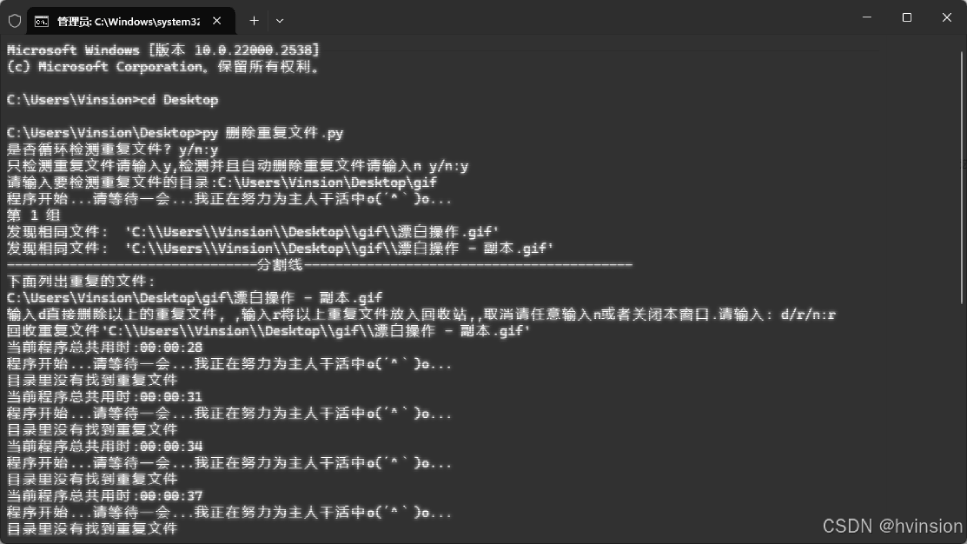
3.运行效果
4.相关源码
import sys, os, filecmp
import time
from win32com.shell import shell,shellcon
def deltorecyclebin(filename):
#print('deltorecyclebin', filename)
# os.remove(filename) #直接删除文件,不经过回收站
res= shell.shfileoperation((0,shellcon.fo_delete,filename,none, shellcon.fof_silent | shellcon.fof_allowundo | shellcon.fof_noconfirmation,none,none)) #删除文件到回收站
#print(res)
# if not res[1]:
# os.system('del '+filename)
#清理重复文件
def md5(fname, chunk_size=1024):
import hashlib
hash = hashlib.md5()
with open(fname, "rb") as f:
chunk = f.read(chunk_size)
while chunk:
hash.update(chunk)
chunk = f.read(chunk_size)
return hash.hexdigest()
def check_for_duplicates(dufilelist):
sizes = {}
hashes = {}
duplicates = []
# traverse all the files and store their size in a reverse index map
# 遍历所有文件并将其大小存储在反向索引映射中
files_count = 0
#print(dufilelist)
for s in dufilelist:
for root, _dirs, files in os.walk(s, topdown=true, onerror=none, followlinks=false):
files_count += len(files)
for f in files:
file = os.path.join(root, f)
size = os.stat(file).st_size
if size not in sizes:
sizes[size] = []
sizes[size].append(file)
#print("traversed {} files".format(files_count))
# remove empty files from the size map
# 从大小映射中删除空文件
if 0 in sizes:
del sizes[0]
# remove files with unique sizes from the size map
# 从大小映射中删除具有唯一大小的文件
for (key, value) in list(sizes.items()):
if len(value) == 1:
del sizes[key]
# traverse the size map and enrich it with hashes
# 遍历大小映射并用哈希值丰富它
for (size, files) in sizes.items():
for file in files:
try:
hash = md5(file)
except:
continue
tuple = (size, hash)
if tuple not in hashes:
hashes[tuple] = []
hashes[tuple].append(file)
# remove files with unique (size, hash) tuple in hash map
# 删除哈希映射中具有唯一(大小,哈希)元组的文件
for (key, value) in list(hashes.items()):
if len(value) == 1:
del hashes[key]
# compare file pairs
# 比较文件对
for possible_list in hashes.values():
#print(possible_list)
#这里把文件按着时间排序:
if possible_list:
# 注意,这里使用lambda表达式,将文件按照最后修改时间顺序升序排列
# os.path.getmtime() 函数是获取文件最后修改时间
# os.path.getctime() 函数是获取文件最后创建时间
possible_list = sorted(possible_list,key=lambda x: os.path.getctime(x))
while possible_list:
first = possible_list[0]
copy = [first]
for other in possible_list[1:]:
if filecmp.cmp(first, other, shallow=false):
copy.append(other)
for c in copy:
possible_list.remove(c)
duplicates.append(copy)
#print(duplicates)
# print duplicates
# 打印相同
groupready=[]
for _i, group in enumerate(duplicates):
print("第 " + str(int(_i) + 1) + " 组")
assert len(group) > 1
#print("%r:" % (i + 1))
if onlyprint:
for d in group:
pass
print("发现相同文件: %r" % (d))
for d in group[1:]:
groupready.append(d)
#print("全部要删除的文件: "+str(groupready))
else:
if filedelete:
for d in group[1:]:
os.remove(d)
print("直接删除重复文件%r" % (d))
else:
for d in group[1:]:
deltorecyclebin(d)
print("回收重复文件%r" % (d))
if not duplicates:
print("目录里没有找到重复文件")
if len(groupready)>0:
print("--------------------------------分割线------------------------------------------")
print("下面列出重复的文件:")
for num in groupready:
print(num)
reback=input("输入d直接删除以上的重复文件, ,输入r将以上重复文件放入回收站,,取消请任意输入n或者关闭本窗口.请输入: d/r/n:")
if reback=="d":
for num in groupready:
os.remove(num)
print("直接删除重复文件%r" % (num))
elif reback=="r":
for num in groupready:
deltorecyclebin(num)
print("回收重复文件%r" % (num))
else:
print("取消操作")
if __name__ == "__main__":
loopinfo=input("是否循环检测重复文件? y/n:")
if loopinfo=="y":
loopinfoable=-1
else:
loopinfoable=1
onlyprintable=input("只检测重复文件请输入y,检测并且自动删除重复文件请输入n y/n:")
if onlyprintable=="y":
onlyprint=true
else:
onlyprint=false
filedeleteable=input("重复文件放入回收站请输入y ,直接删除重复文件请输入n y/n:")
if filedeleteable=="y":
filedelete=false #是否强制删除
else:
filedelete=true #是否强制删除
filepath=input("请输入要检测重复文件的目录:")
time_start=time.time()
while loopinfoable:
loopinfoable=loopinfoable-1
print("程序开始...请等待一会...我正在努力为主人干活中o(´^`)o...")
dufilelist=[filepath]
check_for_duplicates(dufilelist)
#下面是计算时间
time_end=time.time()
seconds=time_end-time_start
m, s = divmod(seconds, 60)
h, m = divmod(m, 60)
print('当前程序总共用时:%02d:%02d:%02d' % (h, m, s))
if loopinfoable!=0: #不循环
time.sleep(3)
input("程序结束,按回车退出")
到此这篇关于使用python实现文件查重功能的文章就介绍到这了,更多相关python文件查重内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论