数据缺失通常有两种情况:
- 空,none等,在pandas是nan(和np的nan一样)
- 另一种就是0
1.为nan数据的处理
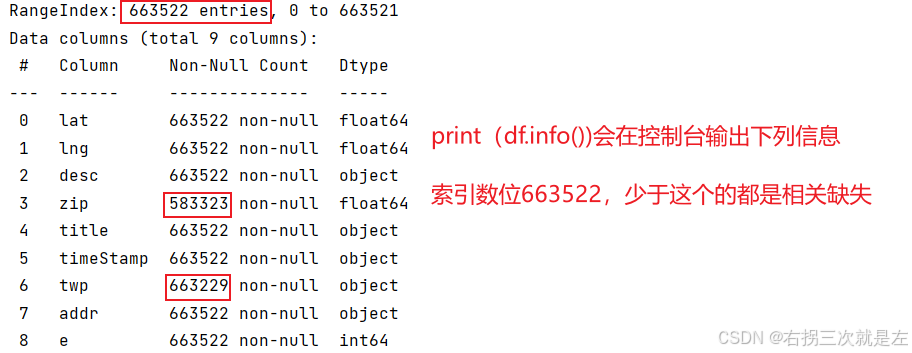
1.判断这列有没有nan
has_nan = df['age'].isnull().any() print(has_nan)
或者直接在控制台根据数据进行判断
2.处理方式
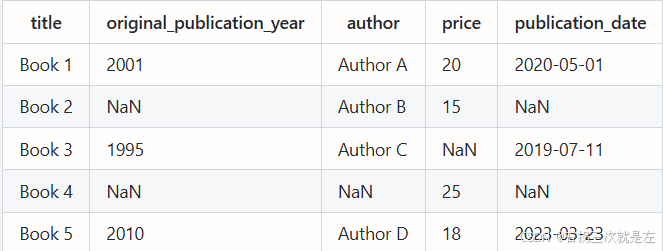
假设我 操作的是original_publication_year这一列,如何操作才能得到过滤后的显示样式
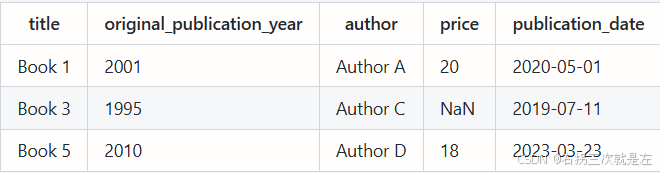
处理方式1:只考虑单列
df2 = df[pd.notnull(df["original_publication_year"])
这行代码的目的是 去除 original_publication_year 列中含有 nan 值的行,并生成一个新的 dataframe(df2),包含了所有 original_publication_year 列中不含 nan 值的行。
3. df["original_publication_year"] 是获取 df 数据框中的 original_publication_year 这一列。
4. pd.notnull(df["original_publication_year")用于检查数据中的每个元素是否不是 nan。返回一个布尔值的 series.
true 的行会被保留;
false 的行会被排除(book2何book4被去除)。
5. 返回一个所有 original_publication_year 列中不是nan 的行新的dataframe
处理方式2:删除nan所在的行
dropna(axis=0,how='any',inplace=false)
any表示有就删,all表示全部是nan才删
inplace表示是否进行原地修改
处理方式3:填充数据
mean_value = df["original_publication_year"].mean() # 计算均值 df_filled=df["original_publication_year"].fillna(mean_value)
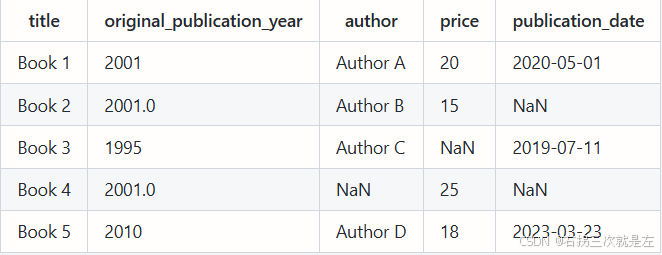
t.fillna(t.mean()) #填充均值 t["列名"]=t["列名"].fillna(t["列名"].mean()) #单独对某一列进行操作 t.fiallna(t.median()) #填充中值 t.fillna(0)
2:为0数据的处理
t[t==0]=np.nan # 赋值为nan # 当然并不是每次为0的数据都需要处理 # 计算平均值等情况,nan是不参与计算的,但是0会的
设置成nan后用处理nan的方法处理。
到此这篇关于pandas数据缺失的处理办法解决的文章就介绍到这了,更多相关pandas数据缺失内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!



发表评论