一、了解什么是定时任务?
job是oracle的定时任务,又叫定时器,定时作业,作业定时地自动执行一些脚本,或作数据备份,或作数据提炼,或作数据库性能的优化,或作重建索引等等的工作,需要用到job。
job是一种被调度执行的任务。job可以是一个pl/sql块、一个sql语句、一个外部脚本或程序等。它们可以被定时调度执行,也可以被手动启动执行。
二、创建job
ⅰ、语法一
declare
v_job_id number;
begin
dbms_job.submit(job =>v_job_id, --job号
what =>'pro_name/dml;', --定时执行的脚本(简称你要干什么)
next_date=>sysdate+1, --第一次执行的时间
interval =>'sysdate+1/24/60' --间隔时间
);
--commit;
end;该语法是使用dbms_job包提交一个定时任务:
- 1. `declare`和`begin`是pl/sql代码块的开始和结束标志。
- 2. `v_job_id`是一个变量,用于存储job的id号。
- 3. `dbms_job.submit`是提交一个job的过程,包括以下参数:
- - `job`:job的id号,由oracle自动生成。
- - `what`:定时执行的脚本,可以是一个存储过程或sql语句。
- - `next_date`:job第一次执行的时间,可以是一个日期类型的变量或者表达式。
- - `interval`:job的执行间隔时间,可以是一个日期类型的变量或者表达式,例如`sysdate+1/24/60`表示每隔1分钟执行一次。
- 4. `commit`是一个事务提交语句,用于将提交的job保存到数据库中。
注意:
使用dbms_job提交的job只能在oracle数据库中执行,不能跨数据库执行。另外,使用dbms_job提交的job在oracle 10g及以上版本中已经被废弃,推荐使用dbms_scheduler包提交job。
比如创建定时任务,每分钟执行一次pkg_2.p1,向emp2表中插入员工编号为7788的员工信息:
declare
v1 number;
begin
dbms_job.submit(job => v1,
what => 'insert into emp2 select * from emp where empno=7788;',
next_date => sysdate,--立即执行
interval => 'sysdate+1/24/60');
commit;
end;
其中emp2表为空表,查询当前时间,然后我们执行这个定时任务
select sysdate from dual;
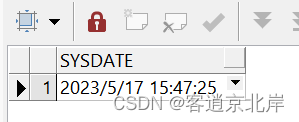
等待一段时间后,我们查看表emp2内的数据:
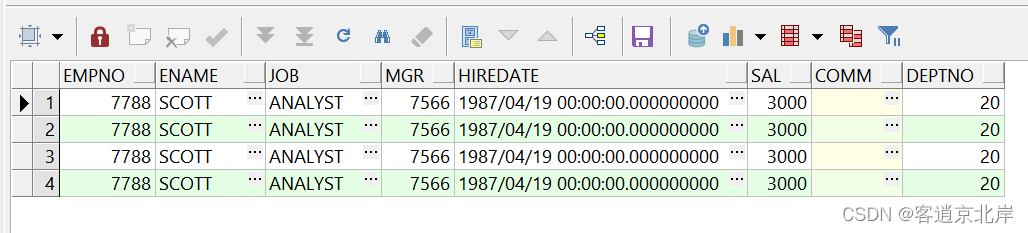
经过四分钟后,从表中可以发现有四条数据。
ⅱ、语法二:
使用dbms_scheduler包来创建和管理job,具体语法如下:
begin
dbms_scheduler.create_job (
job_name => 'job_name', -- job的名称
job_type => 'plsql_block', -- job的类型,可以是plsql_block、stored_procedure等
job_action => 'begin my_proc(); end;', -- job执行的脚本或存储过程
start_date => systimestamp, -- job开始执行的时间
repeat_interval => 'freq=daily; interval=1', -- job执行的间隔时间
enabled => true -- 是否启用job
);
end;
/dbms_scheduler包提供了丰富的job管理功能,可以设置job的执行时间、执行间隔、执行次数、执行优先级、并发控制等属性,实际应用中可以根据具体需求灵活配置。
三、查看job
select * from user_jobs;
结果如下:

从运行结果中可以知道定时任务的job编号为23,登录用户为scott等信息。
其中user_jobs是一个视图,是 oracle 数据库中的一个系统表,它用于存储由 dbms_job.submit 提交的作业(job)的信息。该表包含了提交的作业的 id 号、作业的描述、作业的下一次执行时间、作业的执行间隔时间、作业的状态等信息。用户可以查询该表来获取作业的信息,也可以使用该表来管理作业的状态、修改作业的执行时间等。
注意:
该表只能查看和管理由当前用户提交的作业,不能查看和管理其他用户提交的作业。
其实在oracle中,可以使用以下sql语句来查看定时任务job的信息:
select job_name, job_type, enabled, state, last_start_date, next_run_date from dba_scheduler_jobs;
该语句会列出所有的job,包括job的名称、类型、是否启用、状态、上次执行时间和下次执行时间等信息。其中,dba_scheduler_jobs是一个系统视图,可以查看所有的job信息。如果只需要查看当前用户的job,可以使用user_scheduler_jobs视图。
另外,也可以使用以下sql语句来查看某个job的详细信息:
select * from dba_scheduler_jobs where job_name = 'job_name';
该语句会列出指定job的所有信息,包括job的类型、执行时间、重复间隔、执行程序等。
查看定时任务job的信息只需要使用一些系统视图或者sql语句就可以轻松实现。这些信息可以帮助管理员了解定时任务的执行情况,及时发现和解决问题。
四、删除job
ⅰ、调用dbms_job.remove实现:
call dbms_job.remove(23); commit;
从上面查看job信息知道编号是23!然后调用存过 dbms_job.remove
其中dbms_job.remove是一个包名,是oracle 数据库中的一个过程,用于删除一个已经存在的作业(job)。它的语法如下:
dbms_job.remove ( job in binary_integer);
其中,job 参数表示要删除的作业的 id 号。调用该过程后,指定 id 号的作业将被从数据库中删除。
注意:
该过程只能删除由 dbms_job.submit 提交的作业,不能删除由 dbms_scheduler.submit 创建的作业。
ⅱ、使用下面语句完成job删除:
begin
dbms_scheduler.drop_job (
job_name => 'job_name', -- job的名称
force => false -- 是否强制删除job
);
end;
/其中,job_name是要删除的job的名称,force参数表示是否强制删除job。如果force参数为true,则会强制删除job及其关联的所有对象(例如,程序、链、计划等)。如果force参数为false,则只会删除job本身。
五、停止job
begin dbms_job.broken(23,true); commit; end;
上述命令即可停止job的执行。
其中dbms_job.broken 是 oracle 数据库中的一个过程,用于标记一个作业(job)为失效状态。它的语法如下:
dbms_job.broken ( job in binary_integer, broken in boolean, next_date in date default null, interval in varchar2 default null);
其中,job 参数表示要标记为失效的作业的 id 号;broken 参数表示是否将作业标记为失效状态,true 表示失效,false 表示恢复;next_date 参数表示作业下一次执行的时间;interval 参数表示作业执行的间隔时间。
调用该过程后,指定 id 号的作业将被标记为失效状态。如果 broken 参数为 true,则该作业将被标记为失效,不再执行;如果为 false,则该作业将被恢复为正常状态。如果指定了 next_date 和 interval 参数,则会更新作业的下一次执行时间和执行间隔时间。
或者使用下面命令也可以实现停止job:
begin
dbms_scheduler.stop_job (
job_name => 'job_name',
force_option => 'immediate',
commit_semantics=> 'abort');
end;其中,job_name是要停止的job的名称,force_option参数表示停止job的方式,可以为immediate或cascade。如果force_option为immediate,则会立即停止job的执行。如果force_option为cascade,则会将job及其关联的所有对象都停止。commit_semantics参数表示停止job的提交语义,可以为commit或abort。如果commit_semantics为commit,则会提交job的事务,并将job状态设置为stopped。如果commit_semantics为abort,则会回滚job的事务,并将job状态设置为broken。
六、立即执行job
call dbms_job.run(23);
dbms_job.run 是 oracle 数据库中的一个过程,用于立即执行一个作业(job)。它的语法如下:
dbms_job.run ( job in binary_integer);
其中,job 参数表示要执行的作业的 id 号。调用该过程后,指定 id 号的作业将被立即执行一次。如果该作业正在执行中,则该过程不会产生任何效果,直到该作业执行完毕后再执行一次。
注意:
该过程也是只能执行由 dbms_job.submit 提交的作业,不能执行由 dbms_scheduler.submit 创建的作业。
七、修改job
begin
dbms_scheduler.set_attribute (
name => 'job_name', -- job的名称
attribute => 'start_date', -- 要修改的属性名称
value => systimestamp + interval '1' day -- 修改后的属性值
);
end;
/该语法是使用dbms_scheduler包修改job的开始时间:
- 1. `begin`和`end`是pl/sql代码块的开始和结束标志。
- 2. `dbms_scheduler.set_attribute`是修改job属性的过程,包括以下参数:
- - `name`:job的名称。
- - `attribute`:要修改的属性名称,可以是start_date、repeat_interval、end_date等。
- - `value`:修改后的属性值,可以是一个日期类型的变量或者表达式。
- 3. `job_name`是要修改的job的名称。
- 4. `systimestamp + interval '1' day`表示将job的开始时间修改为当前时间加上1天后的时间。
- 5. `/`是pl/sql代码块的结束标志。
注意:
使用dbms_scheduler包修改job的属性时,需要保证job已经存在。如果job不存在,则需要先使用create_job过程创建job,然后再使用set_attribute过程修改job的属性。
八、job执行失败
job 执行失败可能有多种原因,例如作业的执行时间冲突、作业依赖的对象不存在或无效、作业执行时发生错误等。以下是一些常见的解决方法:
- 1. 检查作业的执行时间是否与其他作业冲突,如果冲突则需要调整作业的执行时间。
- 2. 检查作业依赖的对象是否存在或有效,如果不存在或无效则需要修复或重新创建这些对象。
- 3. 检查作业执行时是否发生了错误,如果发生了错误则需要查看错误日志或调试信息,修复错误并重新执行作业。
- 4. 检查作业的执行权限是否正确,如果权限不足则需要授权或修改作业的执行用户。
- 5. 检查作业的定时器是否正确,如果定时器不正确则需要修改作业的执行时间或执行间隔。
- 6. 检查作业的运行环境是否正确,例如作业依赖的环境变量、路径、配置文件等是否正确设置。
- 7. 如果以上方法都无法解决问题,则需要进一步分析作业执行的情况,例如查看作业的日志、调试信息、执行计划等,找出问题并修复。
总结:
解决 job 执行失败问题需要综合考虑多个因素,需要对作业的执行情况进行全面分析和细致调试,才能找到问题并解决。同时,为了避免作业执行失败,需要在设计作业时考虑各种可能的情况,并采取相应的措施来保证作业的正确执行。
如果一个作业(job)执行失败,oracle 数据库会根据作业的重试次数和重试间隔时间来进行重试。默认情况下,oracle 数据库会在作业执行失败后立即进行重试,最多重试 16 次,每次重试的间隔时间为 5 分钟。也就是说,如果一个作业执行失败,oracle 数据库会在 5 分钟后再次尝试执行该作业,如果该次执行仍然失败,则会继续重试,直到达到最大重试次数为止。
注意:
作业的重试次数和重试间隔时间可以通过 dbms_job.change 或 dbms_scheduler.set_attribute 进行修改。用户可以根据实际情况来设置作业的重试次数和重试间隔时间,以便更好地管理作业的执行。同时,如果作业的重试次数和重试间隔时间设置不当,可能会导致作业长时间无法执行或频繁重试,影响系统的稳定性和性能。因此,在设置作业的重试次数和重试间隔时间时需要慎重考虑。
通常情况下:
- 1、每次重试时间都是递增的,第一次1分钟,2分钟,4分钟,8分钟 ... 依此类推。
- 2、当超过1440分钟,也就是24小时的时候,固定的重试时间为1天。
- 3、超过16次重试后,job就会被标记为broken,next_date为4000-1-1,也就是不再进行job重试。16次重试的时间大概是7天半。
其中前两条这样设计的目的是为了避免在短时间内频繁地重试,降低系统的负载,同时也能够保证任务能够在合理的时间内得到处理。
而第三条是因为在 oracle 中,如果一个作业(job)执行失败达到最大重试次数后,该作业会被标记为 "broken" 状态,同时下一次执行时间会被设置为 4000-01-01,即不再对该作业进行重试。这是 oracle 数据库的默认行为,旨在防止无限制地重试失败的作业,避免对系统造成过大的负担和风险。
当作业被标记为 "broken" 状态后,用户可以通过调用 dbms_job.broken 过程来修改作业的状态,例如将作业恢复为正常状态、更新作业的下一次执行时间和执行间隔时间等。同时,用户也可以通过修改作业的重试次数和重试间隔时间来避免作业被标记为 "broken" 状态,以便更好地管理作业的执行。
注意:
对于那些不需要重试的作业,用户可以将其重试次数设置为 0,以避免对系统造成不必要的负担和风险。
如果oracle中出现job重复调用16次的情况,可能是由于job的重试机制导致的。为了避免这种情况,可以考虑以下几种解决办法:
- 1. 修改job的重试次数和重试时间:可以通过修改job的重试次数和重试时间来避免job出现过多的重试。可以将重试次数设置为一个较小的值,例如3次或5次,同时将重试时间设置为一个适当的值,例如每次重试之间间隔5分钟或10分钟。
- 2. 使用唯一的标识符:可以在job中使用唯一的标识符来避免重复调用。例如,可以在job中设置一个唯一的id,每次调用时检查该id是否已经存在,如果存在则不继续执行,否则执行任务。
- 3. 使用分布式锁:可以使用分布式锁来避免job重复调用。例如,可以使用redis等分布式缓存工具来实现分布式锁,每次调用job时先获取锁,执行任务完毕后释放锁,这样可以保证同一时间只有一个job在执行。
- 4. 使用数据库事务:可以使用数据库事务来避免job重复调用。例如,在job执行前先检查数据库中是否已经存在相同的记录,如果存在则回滚事务,否则执行任务并提交事务。
我们也可以创建一张空表,用来接收数据 create table t_k(id number(1)),然后创建一个存过,里面包含真实的存储过程。如下所示:
create or replace pro_写到job中 is
v_cnt number;
begin
insert into t_k(id) values(1);
commit;
select count(1) into v_cnt from t_k;
if v_cnt=1 then
pro_真实();
正确处理;
else
错误处理(比如向报错表中插入一条数据;打印错误;raise_application_error报错;发邮件)
end if;
end;
declare
v_jobid number;
begin
dbms_job.submit(job => v_jobid,
what => 'pro_写到job中',
next_date => trunc(sysdate,'dd')+3/24,--第一次执行的时间,夜里三点
interval => 'trunc(sysdate,''dd'')+1');--间隔时间,每天执行
commit;
end;九、job用法
接下来展示一个完整的job用例!!!
假设我们需要定期清理一个名为customer的表中的过期数据,使用job来实现。
1. 创建一个pl/sql块,用于清理过期数据:
create or replace procedure clean_customer_data as begin delete from customer where expiration_date < sysdate; commit; end;
2. 创建一个job,用于定期执行clean_customer_data存储过程:
begin
dbms_scheduler.create_job (
job_name => 'clean_customer_data_job',
job_type => 'stored_procedure',
job_action => 'clean_customer_data',
start_date => sysdate,
repeat_interval => 'freq=daily; interval=1',
enabled => true,
comments => '清理过期数据');
end;
其中,job_name是job的名称,job_type表示job的类型,可以为stored_procedure、plsql_block、executable等。job_action是要执行的任务,可以是存储过程、pl/sql块、外部程序等。start_date是job的开始时间,repeat_interval表示job的重复执行间隔,可以使用各种时间间隔语法。enabled表示job是否启用,comments是job的注释。
3. 检查job是否正常运行:
select job_name, state, last_start_date, next_run_date from dba_scheduler_jobs where job_name = 'clean_customer_data_job';
该语句可以查看job的状态、上次执行时间和下次执行时间等信息。
4. 如果需要停止或删除job,可以使用以下语句:
停止job:
begin
dbms_scheduler.stop_job (
job_name => 'clean_customer_data_job',
force_option => 'immediate',
commit_semantics=> 'abort');
end;
删除job:
begin
dbms_scheduler.drop_job (
job_name => 'clean_customer_data_job',
force => true);
end;
以上就是一个简单的job的使用示例,通过job可以实现各种定时任务,提高数据库的自动化管理能力。
到此这篇关于oracle中定时任务的使用(创建查看删除等)的文章就介绍到这了,更多相关oracle 定时任务内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!


发表评论