一、什么是执行计划?
执行计划是由oracle数据库系统生成的,它描述了sql语句的执行方式,包括sql语句的执行顺序、使用的索引、表之间的连接方式等等。执行计划可以通过多种方式获取,如使用explain plan语句、使用sql trace功能、使用sql developer等工具。
二、执行计划的目的
查看 oracle 的执行计划的目的是为了了解 sql 查询或语句在数据库中的执行方式和性能表现。执行计划是一个详细的指南,它描述了 oracle 数据库是如何执行查询的,包括使用哪些索引、连接顺序、使用何种算法等等。
通过查看执行计划,可以识别出潜在的性能问题或优化机会。执行计划提供了查询优化器在决定如何执行查询时所做的选择的信息,可以帮助开发人员或数据库管理员了解查询的成本和效率,并根据需要进行调整和优化。
执行计划可以揭示查询中存在的性能瓶颈、慢查询或未充分利用索引的情况。它还可以帮助开发人员理解查询的执行顺序,以及可能引起性能下降的地方。通过分析执行计划,可以确定是否需要调整查询、添加索引、重写查询逻辑或优化数据库结构,以提高查询性能和响应时间。
总结为以下几点:
- 1. 了解sql语句的执行方式,帮助开发人员和dba分析sql语句的性能瓶颈。
- 2. 查看sql语句的执行效率,帮助开发人员和dba优化sql语句的性能。
- 3. 了解数据库的物理结构,如索引、表之间的连接方式等。
- 4. 帮助开发人员和dba了解oracle数据库的执行策略,以便于更好地进行数据库设计和优化。
三、获取执行计划信息
查询 oracle 的执行计划可以提供以下信息:
3.1访问路径(access path):
执行计划显示了查询如何访问表或索引,包括全表扫描、索引扫描、索引范围扫描等。这可以帮助确定数据是如何被检索的。
3.2连接顺序(join order):
如果查询涉及多个表的连接操作,执行计划将显示连接的顺序。这对于优化查询的性能很重要,因为不同的连接顺序可能会导致不同的性能。
3.3连接类型(join type):
执行计划指示了连接操作使用的连接类型,如内连接、外连接或半连接。这对于了解查询中不同连接操作的性能影响很有帮助。
3.4过滤条件(filter predicates):
执行计划会显示应用在表或索引访问上的过滤条件。这可以帮助确认查询中的过滤逻辑是否被正确地应用。
3.5排序操作(sort operations):
如果查询涉及排序操作,执行计划将显示排序的方式和排序所使用的算法。这对于优化排序操作的性能很有帮助。
3.6聚合操作(aggregation operations):
如果查询包含聚合函数(如 sum、avg、count 等),执行计划将显示聚合操作的方式和执行方法。
3.7数据库统计信息(statistics):
执行计划可以提供表、索引或列的统计信息,如行数、唯一值数量等。这对于优化查询计划选择和索引设计很重要。
通过分析执行计划,可以确定查询中的性能瓶颈和优化机会,了解查询的执行方式,以及根据需要进行调整和优化的方法。
四、执行计划的执行顺序
oracle执行计划的执行顺序是从上往下,从右往左。也就是说,执行计划的最底部是最后执行的操作,而最顶部是最先执行的操作。左边的操作优先级低于右边的操作,也就是说,右边的操作先执行,左边的操作后执行。
口诀:
- 缩进最深的,最先执行
- 缩进深度相同的,先上后下
五、执行计划的存储区
主要包括以下几个部分:
- 1. 表操作符:表示对表的操作,如全表扫描、索引扫描等。
- 2. 连接操作符:表示对表之间的连接操作,如hash join、nested loops join等。
- 3. 过滤操作符:表示对结果集进行过滤的操作,如where、having等。
- 4. 访问操作符:表示对数据的访问操作,如index、table等。
- 5. 排序操作符:表示对结果集进行排序的操作,如order by、group by等。
- 6. 其他操作符:表示其他类型的操作符,如union、intersect等。
执行计划中的每个操作符都有对应的存储区,用于存储该操作符的执行结果。执行计划中的每个操作符都有自己的任务和目的,它们通过组合形成完整的sql语句执行计划,最终实现对数据的查询和操作。
六、执行计划的执行步骤
- 1. sql解析:将sql语句进行语法解析,确定语句的语义和结构。
- 2. 查询优化:优化器根据sql语句和数据库的统计信息,选择最优的执行计划。
- 3. 执行计划生成:根据查询优化产生的最优执行计划,生成执行计划树。
- 4. 执行计划执行:按照执行计划树的顺序,执行各个操作步骤,包括表扫描、索引扫描、排序、聚合等。
- 5. 结果返回:将执行结果返回给客户端。
- 6. 监控和调优:根据执行计划的执行情况,对性能进行监控和调优,如调整参数、优化sql语句等。
七、执行计划中各字段的描述
7.1、基本字段(总是可用的)
- id 执行计划中每一个操作(行)的标识符。如果数字前面带有星号,意味着将在随后提供这行包含的谓词信息
- operation 对应执行的操作。也叫行源操作
- name 操作的对象名称
7.2、查询优化器评估信息
- rows(e-rows) 预估操作返回的记录条数
- bytes(e-bytes) 预估操作返回的记录字节数
- tempspc 预估操作使用临时表空间的大小
- cost(%cpu) 预估操作所需的开销。在括号中列出了cpu开销的百分比。注意这些值是通过执行计划计算出来的。
换句话说,父操作的开销包含子操作的开销
- time 预估执行操作所需要的时间(hh:mm:ss)
7.3、分区(仅当访问分区表时下列字段可见)
- pstart 访问的第一个分区。如果解析时不知道是哪个分区就设为 key,key(i),key(mc),key(or),key(sq)
- pstop 访问的最后一个分区。如果解析时不知道是哪个分区就设为key,key(i),key(mc),key(or),key(sq)
7.4、并行和分布式处理(仅当使用并行或分布式操作时下列字段可见)
- inst 在分布式操作中,指操作使用的数据库链接的名字
- tq 在并行操作中,用于从属线程间通信的表队列
- in-out 并行或分布式操作间的关系
- pq distrib 在并行操作中,生产者为发送数据给消费者进行的分配
7.5、运行时统计(当设定参数statistics_level为all或使用gather_plan_statistics提示时,下列字段可见)
- starts 指定操作执行的次数
- a-rows 操作返回的真实记录数
- a-time 操作执行的真实时间(hh:mm:ss.ff)
7.6、i/o 统计(当设定参数statistics_level为all或使用gather_plan_statistics提示时,下列字段可见)
- buffers 执行期间进行的逻辑读操作数量
- reads 执行期间进行的物理读操作数量
- writes 执行期间进行的物理写操作数量
7.7、内存使用统计
- omem 最优执行所需内存的预估值
- 1mem 一次通过(one-pass)执行所需内存的预估值
- 0/1/m 最优/一次通过/多次通过(multipass)模式操作执行的次数
- used-mem 最后一次执行时操作使用的内存量
- used-tmp 最后一次执行时操作使用的临时空间大小。这个字段必须扩大1024倍才能和其他衡量内存的字段一致(比如,32k意味着32mb)
- max-tmp 操作使用的最大临时空间大小。这个字段必须扩大1024倍才能和其他衡量内存的字段一致(比如,32k意味着32mb)
八、查看执行计划语法
在oracle数据库中,可以通过使用“explain plan”命令来查看查询语句的执行计划。下面是详细的使用方法及实例说明:
8.1. 基本语法
explain plan for select * from table_name where condition;
8.2. 查看执行计划
select * from table(dbms_xplan.display);
九、实例说明
假设我们有一个表“employees”,包含员工的基本信息,我们要查询薪水大于5000的员工信息。我们可以使用以下命令来查看查询语句的执行计划:
explain plan for select * from employees where salary > 5000;
执行上述命令后,可以通过以下命令来查看执行计划:
select * from table(dbms_xplan.display);
查询结果中会显示查询语句的执行计划,包括每个操作的类型、所涉及的表或索引、所需的成本等信息。例如,查询结果可能如下所示:
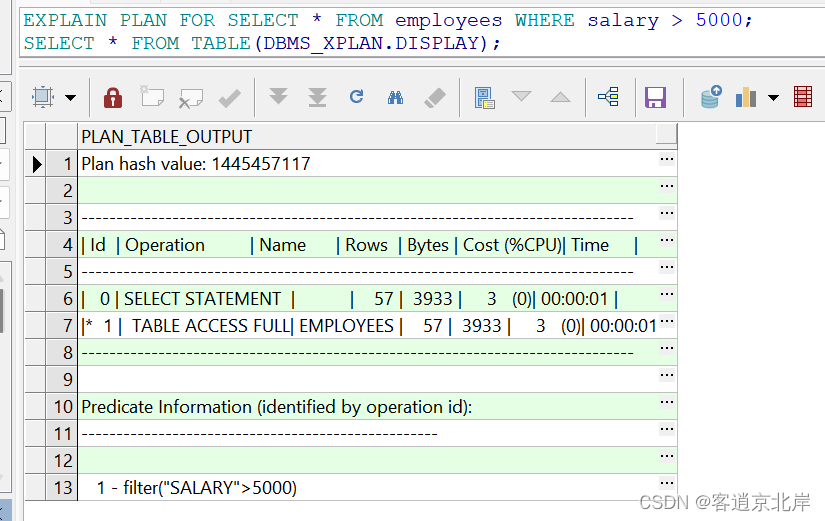
备注(不用上滑了,纳多费劲呀,我懂你累!!):
- 1. id:查询语句中每个操作的唯一标识符,可以通过id来查看操作之间的关系。
- 2. operation:查询语句中每个操作的类型,例如full table scan、index scan等。
- 3. name:表示操作所涉及的表或索引的名称。
- 4. rows:表示操作所涉及的行数或估计的行数。
- 5. bytes:表示操作所涉及的字节数或估计的字节数。
- 6. cost:表示操作所需的成本,包括cpu成本和i/o成本。
- 7.time:表示操作所需的时间。
解释:
full table scan 和 index scan 都是一种查询表数据的方式。
full table scan 是一种全表扫描的方法,即当我们的查询条件不能使用索引进行查找时,oracle就会对整个包含了表数据的数据块进行扫描,从而获取需要的数据。
index scan(也被称为index range scan)则利用了表上的索引,查询时只扫描符合指定范围条件的索引结构,从而快速定位到匹配的记录。如果查询条件可以使用索引,则选择index scan 可以大大提高查询性能。
总结:full table scan 通常发生在没有使用索引或索引不能完全匹配查询条件的情况下,数据查询速度相对较慢;index scan 则利用索引有序性,可快速定位满足查询条件的数据行,并且查询速度更快。
分析以上结果:
①id为0的操作为select statement,表示整个查询语句的执行计划;
②id为1的操作为table access full,表示对表“employees”进行全表扫描。
③predicate information (identified by operation id) 表示操作所用到的谓词信息,其中 operation id 表示当前操作的 id 号,谓词信息包括过滤条件、连接条件等。
predicate information 中的谓词信息对于理解 sql 查询的执行计划非常重要。它告诉我们查询优化器是如何使用索引、过滤条件等对数据进行筛选和连接的。通过分析 predicate information,可以发现 sql 查询中的性能瓶颈,从而进行优化。
例如:
- 如果 predicate information 中显示的是 index (range scan) 则表示查询优化器使用了索引进行范围扫描。
- 如果 predicate information 中显示的是 filter,则表示查询优化器使用了过滤条件来筛选数据。
- 如果 predicate information 中显示的是 join,则表示查询优化器使用了连接条件来连接多个表。
④1 - filter("salary">5000) 表示当前操作是对表进行过滤操作,过滤条件为 "salary">5000,即薪资大于 5000 的记录。
这个操作通常出现在 select 语句中,用于筛选符合条件的记录。在执行计划中,这个操作通常出现在表扫描、索引扫描等操作之后,用于进一步筛选数据。
在执行计划中,filter 操作的代价通常比较小,因为它只是对已经扫描的记录进行进一步筛选,而不需要进行额外的磁盘 io 操作。但是,如果 filter 操作出现在操作树的顶部,代价可能会比较大,因为它需要读取整个表或索引,并将不符合条件的记录过滤掉。
在 sql 查询的优化过程中,通常要尽量减少 filter 操作的出现,可以通过添加索引、修改查询条件等方式来避免 filter 操作的出现。
我们可以通过这些信息来了解查询语句的执行计划及其效率,从而进行优化。
十、plsql developer中的f5
依旧是查询表“employees”薪水大于5000的员工信息,我们可以使用快捷键f5来查看查询语句的执行计划,如下图所示:
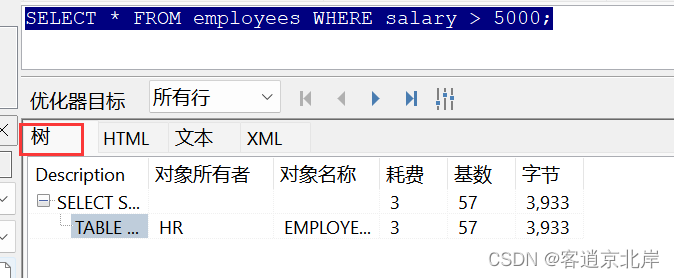
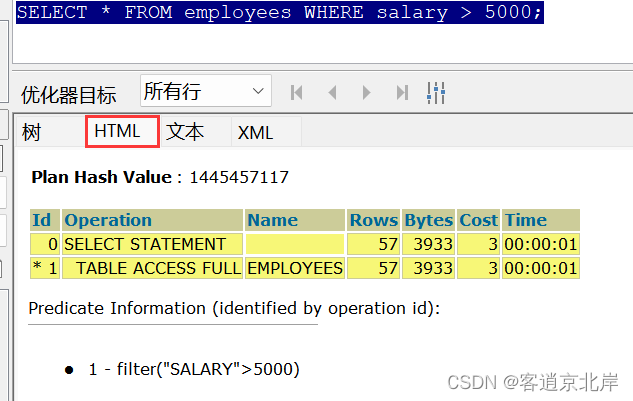
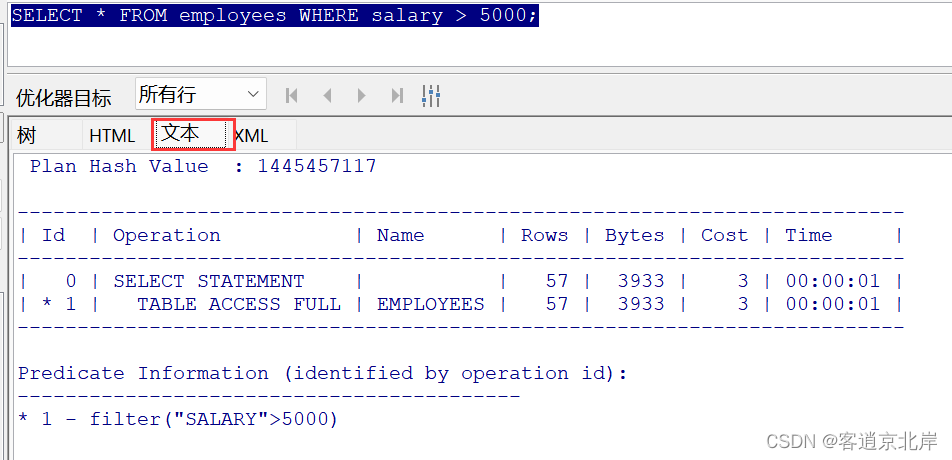
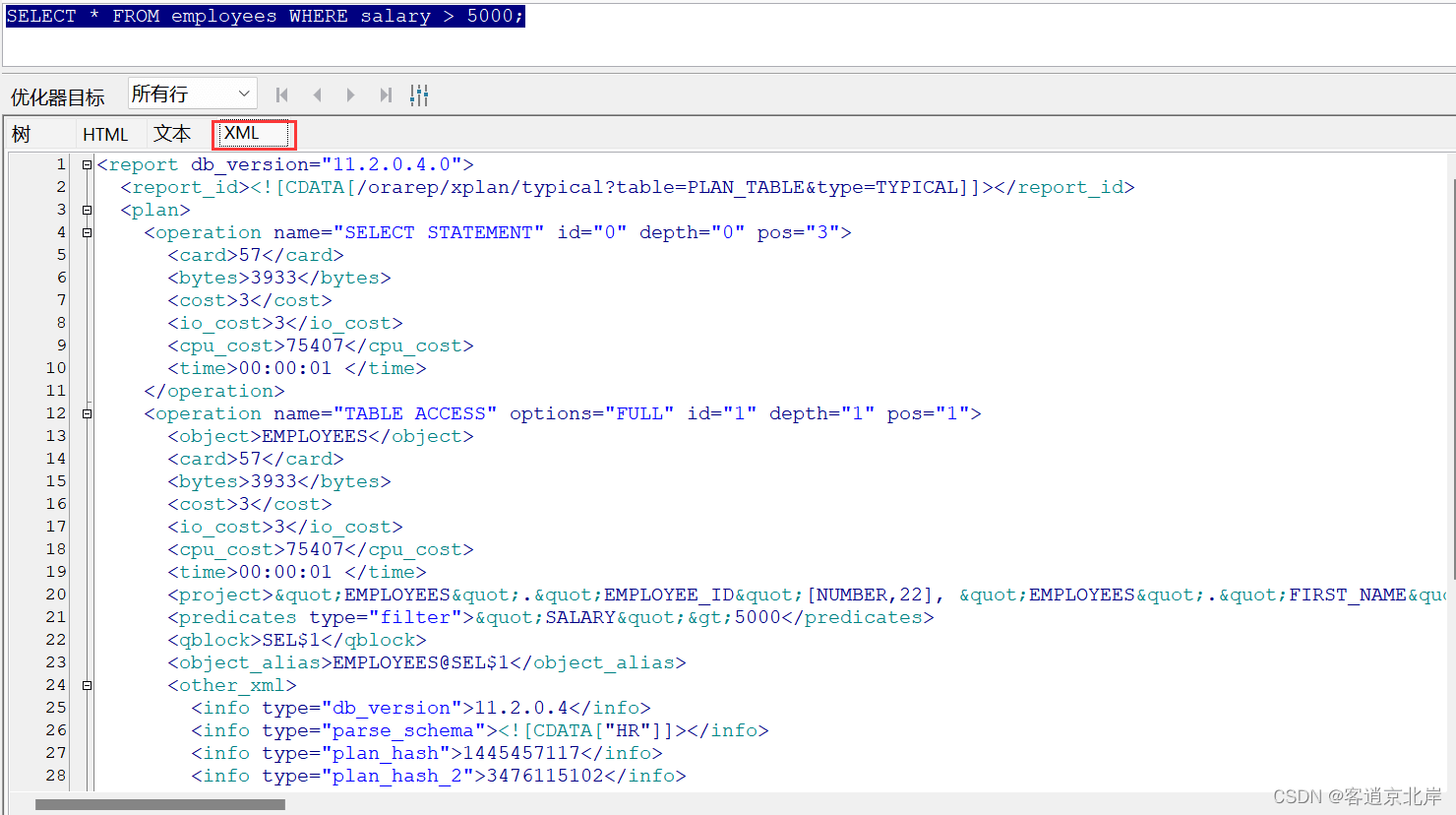
通过切换不同的展示格式,我们可以看到各种信息,但是展示结果与使用explain plan for语句是一样的,这种方式可以更加的快捷方便!
上面的例子相对来说展示结果比较单一,接下来举用下面的例子再描述以下,已知员工表employees和部门表departments,现要求查询出员工薪资为6000的员工信息和部门信息,我们可以用快捷键f5查看下他的执行计划:
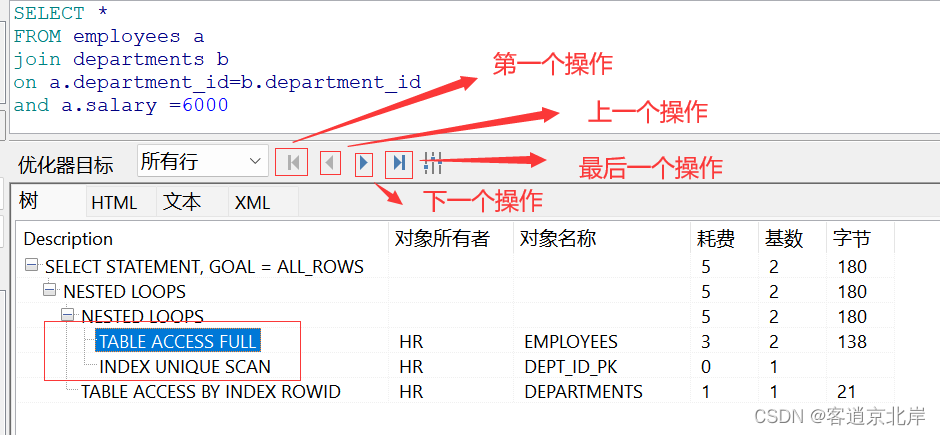
①在上途中我们发现table access full 时,通常意味着该查询使用了 full table scan 的方式来访问表。上面有提到了这个方式,但我还是要再唠叨一下:
full table scan 是一种全表扫描的方法,即当我们的查询条件不能使用索引进行查找时,oracle就会对整个包含了表数据的数据块进行扫描,从而获取需要的数据。此时, oracle 就会选择使用 table access full 操作符。
如果查询中使用了 table access full 而没有使用索引,则可能导致查询速度相对较慢,对于较大的表来说,这种方法可能会产生很高的 i/o 成本和 cpu 成本,不利于系统性能。
注意:
在实际应用中,尽可能避免使用 full table scan,可以考虑使用合适的索引或优化查询语句等方式提高查询性能。
②在执行计划中,还发现了index unique scan ,它表示对于一个唯一索引或主键索引的范围查找方式。
当查询语句中包含了对唯一索引或主键索引字段的等值(=)条件时,在执行计划中就会显示 index unique scan 操作。这种方法可以非常快速地定位到需要查询的行,并且不会产生重复数据输出。
与普通索引扫描不同的是,index unique scan 确保查询结果最多只有一行记录,因为唯一索引或主键索引本身就定义了数据行的唯一性。因此,如果我们可以通过索引的方式找到精确匹配的数据,则最好使用 index unique scan 以提高查询效率。
总之,index unique scan 是一种高效的查询方式,适用于对于唯一索引或主键索引进行查询的场景。同时,建立合适的索引也是提高查询性能的重要手段之一。
③在执行计划中,还发现了table access by index rowid ,它表示通过索引行 id 进行表数据访问的操作。一般而言,使用该操作符需要经过以下步骤:
- 1. 根据查询语句中的条件,找到合适的索引;
- 2. 使用索引查找所需的数据行的 rowid;
- 3. 根据 step 2 中获取的 rowid 值,从表中取出对应的数据行。
这个操作符与其他操作符最大的区别在于,它不是针对索引进行数据访问,而是针对实际的数据表进行访问。因此,table access by index rowid 可以通过索引快速定位到需要的数据行,并根据 rowid 直接访问表数据,从而提高查询的效率。
注意:
在使用 table access by index rowid 时,如果表的数据分散在多个磁盘块中,就可能会产生很高的 i/o 成本和 cpu 成本,导致查询性能下降。因此,在进行优化时,应尽量避免物理磁盘 io 操作的数量,可以通过内存或者调整磁盘布局等方式来改善性能。
④在本文章的第四节【四、执行计划的执行顺序】提到了执行顺序,那么我们在上图的树结构--耗费就可以知道他们的执行顺序是怎样排序的,如果不清楚,我们九可以点击图中标记的三角提示进行查看。
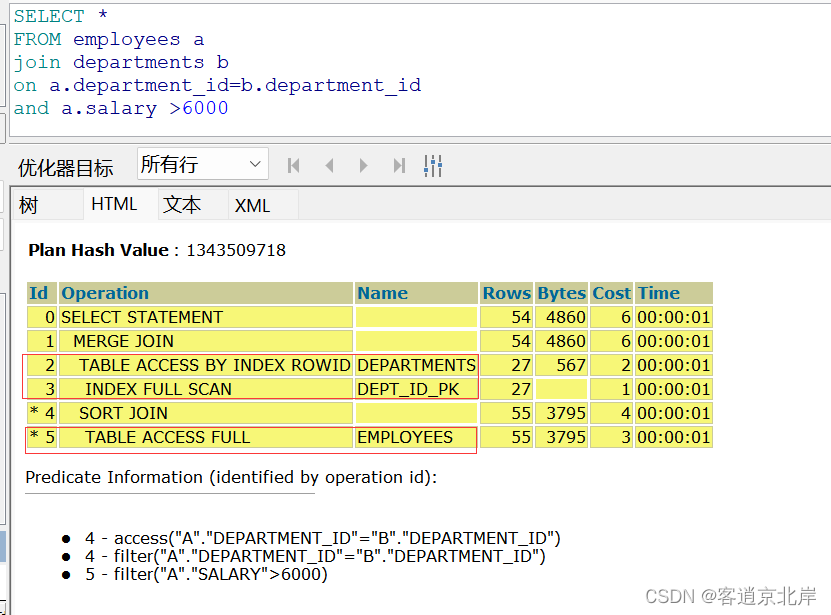
通过html框图我们可以清楚知道索引扫描的索引名字,全表扫描的表名,分别扫描了多少行,预估多少个字节,cpu的消耗和操作执行消耗的时间等信息。

文本图的展示与explain plan for语句执行结果大致一样,不再过多描述。
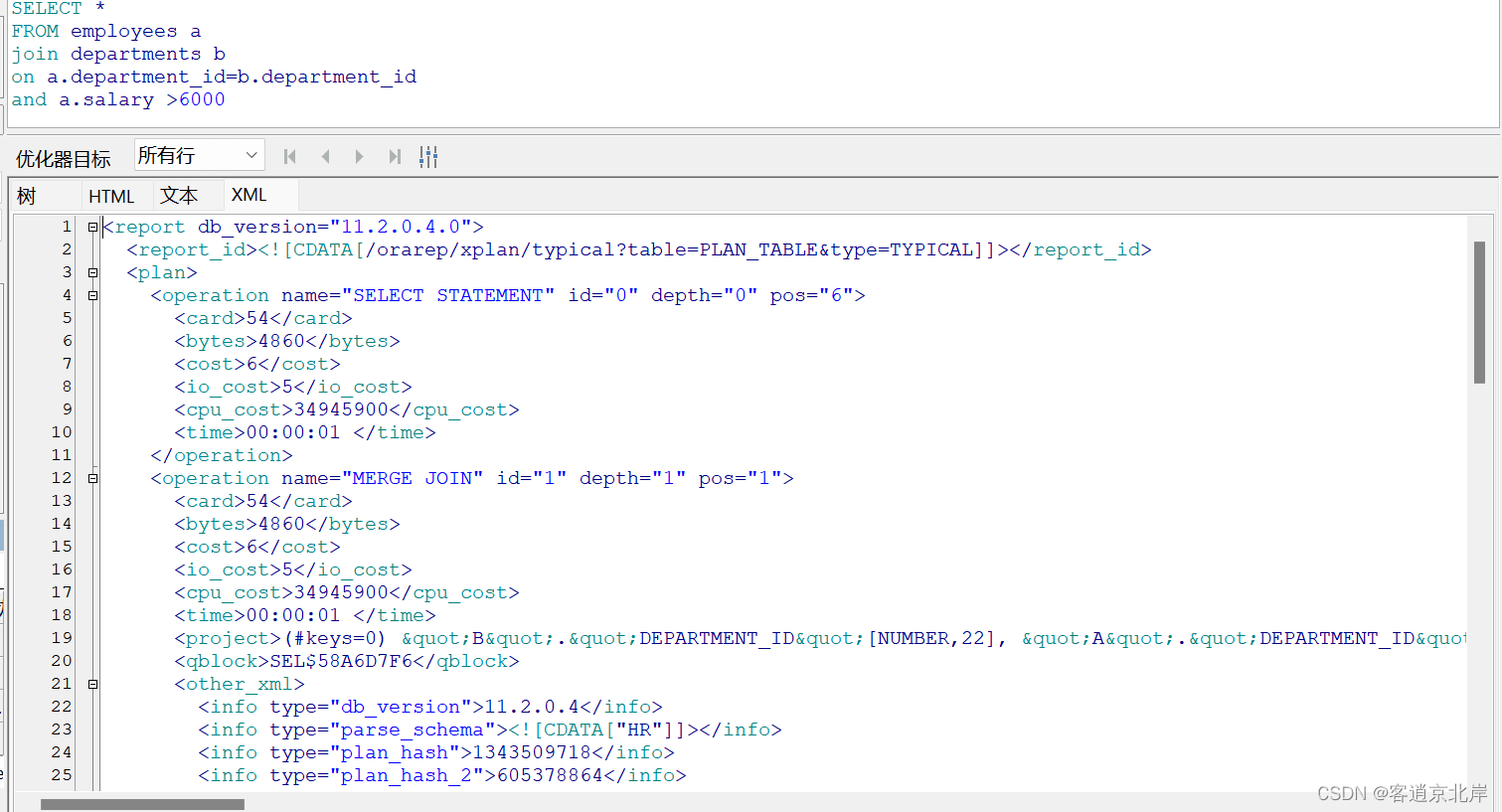
上面也有展示了此图,大家一定很好奇它是干什么的,哈哈哈!!!不急,下面给你简单描述一下情况!
在 oracle sql developer 中,使用快捷键 f5 可以查看 sql 语句的执行计划。这个操作会打开一个新窗口,展示查询 sql 的执行计划图表与一些统计信息。
如果我们在执行计划窗口中选择了“explain plan(xml format)”,那么窗口下方将会展示该查询语句的 xml 执行计划,其中包括了多个执行计划步骤及其相应的输入、输出参数和所涉及的对象等信息。
oracle 数据库管理系统使用 xml 格式来表示执行计划,这种格式的优点是可读性好,易于在不同平台之间进行传输和共享。通过查看 xml 执行计划,我们可以更深入地了解查询的执行细节,帮助我们分析和优化查询性能问题。
到此这篇关于oracle查看执行计划的实现的文章就介绍到这了,更多相关oracle查看执行计划内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!


发表评论