背景
1、mysql在5.5.3版本之后增加了utf8mb4的编码,mb4就是most bytes 4的意思,专门用来兼容四字节的unicode;
2、utf8mb4是utf8的超集,除了将编码改为utf8mb4外不需要做其他转换。当然,为了节省空间,一般情况下使用utf8也就够了;
名词解释
- 字符集(character set/charset):字符的二进制编码方式;
- utf-8:是unicode的实现方式之一,其他实现方式还有utf-16,utf-32,它是一种变长的编码,一个符号使用1~4个字节表示;
- utf8:mysql中实现了utf-8编码的unicode字符集,是utf8mb3的别称,utf8编码中一个符号使用1~3个字节表示;
- utf8mb4:mysql中实现了
关系
- 1、都实现了utf-8编码中的的unicode字符集;
- 2、utf8仅支持基本多语言平面basic multilingual plane (bmp);
- 3、utf8mb4支持bmp之外的补充字符,如一些生僻的汉字,emoji字符,以及任何新增的unicode字符。
- 4、utf8一个字符最多使用3个字节存储,utf8mb4一个字符最多使用4个字节存储;
- 5、对于bpm字符,utf8和utf8mb4都使用三个字节存储;对于非bmp字符,utf8mb4使用4个字节存储,utf8不能存储非bmp字符;
- 6、innodb中默认最大可对767个字节建立索引;使用utf8的列最多可对255个字符建立索引;使用utf8mb4的最多可对191个字符建立索引;
实践
为了验证上面的理论,创建如下两个表:它们的字符集分别为utf8和utf8mb4
create table `test_utf8` ( `id` bigint(20) unsigned not null auto_increment comment '主键', `name` varchar(5) not null comment '名称', primary key (`id`) ) engine=innodb default charset=utf8 comment='测试utf8'; create table `test_utf8mb4` ( `id` bigint(20) unsigned not null auto_increment comment '主键', `name` varchar(5) not null comment '名称', primary key (`id`) ) engine=innodb default charset=utf8mb4 comment='测试utf8mb4';
向两个表中分别插入如下数据:
insert into test_utf8(name) values ('我是一颗小'), ('我是reo'), ('12345'), ('ggvdc');
insert into test_utf8mb4(name) values ('我是一颗小'), ('我是reo'), ('12345'), ('ggvdc');
insert into test_utf8mb4(name) values ('?????');查看在两种字符集下的存储长度:
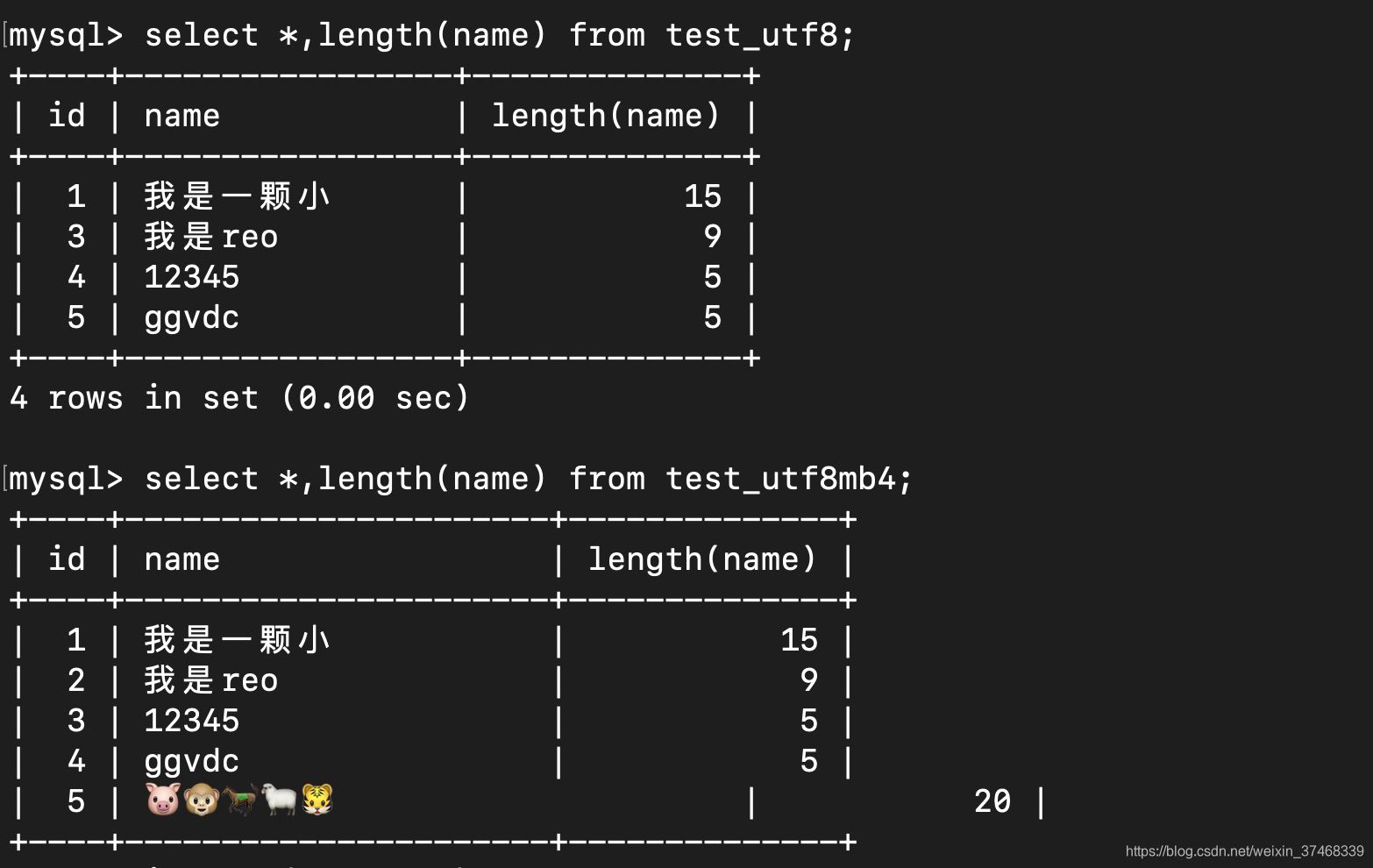
该图验证了上面3、4、5点理论;
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。

发表评论