问题及现象
在openxml中文件不包含空白单元格的条目,这就是跳过空白单元格的原因。
所以如果当我们打开一个excel,读取一个表格数据,发现如果有空单元格,openxml会跳过导致读取的数据发生错位。
比如这个是原始的excel表格数据。
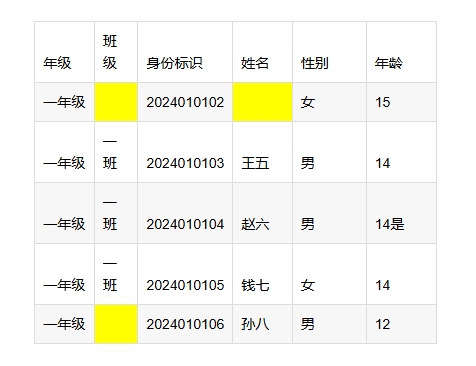
当有空格读取后,第一行和最后一行的数据就会错位了,如下:
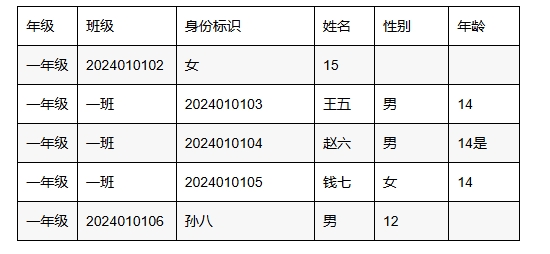
解决的办法就是:
假设:
documentformat.openxml.spreadsheet.row row,
cell cell = row.elements<cell>().firstordefault(c => c.cellreference == $"列行");
//例如:c.cellreference =="a12"
当cell是空的时候,表示该单元格是空值。
因此对于从行中提取单元格不能使用“foreach (cell cell in row)”,这样取出来的cell是非空的单元格,也就是如果你有10列,有两列是空单元格,那么就只能取出来8列,这就导致了取出数据的错位。
而应该使用循环,也就是知道了表格的列数了,然后使用for去循环,例如:
for (int columnindex = 0; columnindex < dt.columns.count; columnindex++)
{
//查找指定的行列单元格是否存在。
cell cell = row.elements<cell>().firstordefault(c => c.cellreference == $"{columnreference[columnindex]}{row.rowindex}");//例如:c.cellreference =="a12"
string cellval = null; //定义获取的单元格的值,默认为空
if (cell != null)
{//不为空使用定义的getcellvalue()函数获取cell中的值
cellval = getcellvalue(cell, workbookpart);
}
....
}以下为封装的openxml处理的完整代码
调用readsheetwithheader()函数,readsheetwithheader会调用封装的openxml类outexcel对象,从而把指定的excel文件的sheet表读取到datatable的数据集合中。
/// <summary>
/// 将指定的excel文件中的指定索引的sheet读取到表对象中
/// </summary>
/// <param name="filenm">excel文件路径</param>
/// <param name="sheetindex">sheet索引</param>
/// <returns>返回datatable对象</returns>
public datatable readsheetwithheader(string filenm, int sheetindex)
{
filestream fs = new filestream(filenm, filemode.open, fileaccess.read, fileshare.read);
datatable dt = new outexcel().readexcel(sheetindex, fs);
return dt;
}封装openxml类outexcel
using documentformat.openxml;
using documentformat.openxml.packaging;
using documentformat.openxml.spreadsheet;
using system;
using system.collections.generic;
using system.data;
using system.io;
using system.linq;
using system.text;
using system.threading.tasks;
namespace openexcelmng
{
public class outexcel
{
/// <summary>
/// 按照给定的excel流组织成datatable
/// </summary>
/// <param name="sheetname">须要读取的sheet的名称</param>
/// <param name="stream">excel文件流</param>
/// <returns>组织好的datatable</returns>
public datatable readexcel(string sheetname, stream stream)
{
using (spreadsheetdocument document = spreadsheetdocument.open(stream, false))
{ //打开stream
workbookpart workbookpart = document.workbookpart;
ienumerable<sheet> sheets = workbookpart.workbook.descendants<sheet>().where(s => s.name == sheetname);
if (sheets.count() == 0)
{//找出合适前提的sheet,没有则返回
return null;
}
worksheetpart worksheetpart = (worksheetpart)document.workbookpart.getpartbyid(sheets.first().id);
//获取excel中共享数据
sharedstringtable stringtable = document.workbookpart.sharedstringtablepart.sharedstringtable;
ienumerable<row> rows = worksheetpart.worksheet.descendants<row>();//获得excel中得数据行
datatable dt = new datatable("excel");
//因为须要将数据导入到datatable中,所以我们假定excel的第一行是列名,从第二行开端是行数据
foreach (row row in rows)
{
if (row.rowindex == 1)
{//excel第一行动列名
getdatacolumn(row, stringtable, ref dt);
}
else
{
getdatarow(row, stringtable, workbookpart, ref dt);//excel第二行同时为datatable的第一行数据
}
}
return dt;
}
}
/// <summary>
/// 按照给定的excel流组织成datatable
/// </summary>
/// <param name="sheetindex">须要读取的sheet的索引</param>
/// <param name="sheetindex">excel文件流</param>
/// <returns>组织好的datatable</returns>
public datatable readexcel(int sheetindex, stream stream)
{
using (spreadsheetdocument document = spreadsheetdocument.open(stream, false))
{//打开stream
workbookpart workbookpart = document.workbookpart;
ilist<sheet> sheets = workbookpart.workbook.descendants<sheet>().tolist();
if (sheets.count() == 0)
{//找出合适前提的sheet,没有则返回
return null;
}
worksheetpart worksheetpart = (worksheetpart)document.workbookpart.getpartbyid(sheets[sheetindex].id);
//获取excel中共享数据
sharedstringtable stringtable = document.workbookpart.sharedstringtablepart.sharedstringtable;
ienumerable<row> rows = worksheetpart.worksheet.descendants<row>();//获得excel中得数据行
datatable dt = new datatable("excel");
//因为须要将数据导入到datatable中,所以我们假定excel的第一行是列名,从第二行开端是行数据
foreach (row row in rows)
{
if (row.rowindex == 1)
{//excel第一行动列名
getdatacolumn(row, stringtable, ref dt);
}
else
{
getdatarow(row, stringtable, workbookpart, ref dt);//excel第二行同时为datatable的第一行数据
}
}
return dt;
}
}
/// <summary>
/// 构建datatable的列
/// </summary>
/// <param name="row">openxml定义的row对象</param>
/// <param name="stringtablepart"></param>
/// <param name="dt">须要返回的datatable对象</param>
/// <returns></returns>
public void getdatacolumn(row row, sharedstringtable stringtable, ref datatable dt)
{
datacolumn col = new datacolumn();
dictionary<string, int> columncount = new dictionary<string, int>();
foreach (cell cell in row)
{
string cellval = getvalue(cell, stringtable);
col = new datacolumn(cellval);
if (iscontainscolumn(dt, col.columnname))
{
if (!columncount.containskey(col.columnname))
columncount.add(col.columnname, 0);
col.columnname = col.columnname + (columncount[col.columnname]++);
}
dt.columns.add(col);
}
}
/// <summary>
/// 构建datatable的每一行数据,并返回该datatable
/// </summary>
/// <param name="row"></param>
/// <param name="stringtable"></param>
/// <param name="workbookpart">用于处理获取cell中的信息,如果cell存在,不是空单元格</param>
/// <param name="dt">把行数据写入到datatabl中</param>
private void getdatarow(documentformat.openxml.spreadsheet.row row,
documentformat.openxml.spreadsheet.sharedstringtable stringtable, //不再使用
documentformat.openxml.packaging.workbookpart workbookpart, //用于处理获取cell中的信息,如果cell存在,不是空单元格
ref system.data.datatable dt) //把行数据写入到datatabl中。
{
// 读取算法:按行一一读取单位格,若是整行均是空数据
// 则忽视改行(因为本人的工作内容不须要空行)-_-
datarow dr = dt.newrow();
int i = 0;
int nullrowcount = i;
dictionary<int, string> columnreference = new dictionary<int, string>();
columnreference.add(0, "a");
columnreference.add(1, "b");
columnreference.add(2, "c");
columnreference.add(3, "d");
columnreference.add(4, "e");
columnreference.add(5, "f");
columnreference.add(6, "g");
columnreference.add(7, "h");
for (int columnindex = 0; columnindex < dt.columns.count; columnindex++)
{
cell cell = row.elements<cell>().firstordefault(c => c.cellreference == $"{columnreference[columnindex]}{row.rowindex}");//例如:c.cellreference =="a12"
string cellval = null;
if (cell != null)
{
cellval = getcellvalue(cell, workbookpart);
}
if (string.isnullorempty(cellval))
{
nullrowcount++;
}
dr[i] = cellval;
i++;
}
if (nullrowcount != i)
{
dt.rows.add(dr);
}
}
/// <summary>
/// 获取单位格的值
/// </summary>
/// <param name="cell">单元格</param>
/// <param name="workbookpart"></param>
/// <param name="type">1 不去空格 2 前后空格 3 所有空格 </param>
/// <returns></returns>
public static string getcellvalue(cell cell, workbookpart workbookpart, int type = 2)
{
//合并单元格不做处理
if (cell.cellvalue == null)
return string.empty;
string cellinnertext = cell.cellvalue.innerxml;
//纯字符串
if (cell.datatype != null && (cell.datatype.value == cellvalues.sharedstring || cell.datatype.value == cellvalues.string || cell.datatype.value == cellvalues.number))
{
//获取spreadsheetdocument中共享的数据
sharedstringtable stringtable = workbookpart.sharedstringtablepart.sharedstringtable;
//如果共享字符串表丢失,则说明出了问题。
if (!stringtable.any())
return string.empty;
string text = stringtable.elementat(int.parse(cellinnertext)).innertext;
if (type == 2)
return text.trim();
else if (type == 3)
return text.replace(" ", "");
else
return text;
}
//bool类型
else if (cell.datatype != null && cell.datatype.value == cellvalues.boolean)
{
return (cellinnertext != "0").tostring().toupper();
}
//数字格式代码(numfmtid)小于164是内置的:https://www.it1352.com/736329.html
else
{
//为空为数值
if (cell.styleindex == null)
return cellinnertext;
stylesheet stylesheet = workbookpart.workbookstylespart.stylesheet;
cellformat cellformat = (cellformat)stylesheet.cellformats.childelements[(int)cell.styleindex.value];
uint formatid = cellformat.numberformatid.value;
double doubletime;//ole 自动化日期值
datetime datetime;//yyyy/mm/dd hh:mm:ss
switch (formatid)
{
case 0://常规
return cellinnertext;
case 9://百分比【0%】
case 10://百分比【0.00%】
case 11://科学计数【1.00e+02】
case 12://分数【1/2】
return cellinnertext;
case 14:
doubletime = double.parse(cellinnertext);
datetime = datetime.fromoadate(doubletime);
return datetime.tostring("yyyy/mm/dd");
//case 15:
//case 16:
case 17:
doubletime = double.parse(cellinnertext);
datetime = datetime.fromoadate(doubletime);
return datetime.tostring("yyyy/mm");
//case 18:
//case 19:
case 20:
doubletime = double.parse(cellinnertext);
datetime = datetime.fromoadate(doubletime);
return datetime.tostring("h:mm");
case 21:
doubletime = double.parse(cellinnertext);
datetime = datetime.fromoadate(doubletime);
return datetime.tostring("hh:mm:ss");
case 22:
doubletime = double.parse(cellinnertext);
datetime = datetime.fromoadate(doubletime);
return datetime.tostring("yyyy/mm/dd hh:mm");
//case 45:
//case 46:
case 47:
doubletime = double.parse(cellinnertext);
datetime = datetime.fromoadate(doubletime);
return datetime.tostring("yyyy/mm/dd");
case 58://【中国】11月11日
doubletime = double.parse(cellinnertext);
datetime = datetime.fromoadate(doubletime);
return datetime.tostring("mm/dd");
case 176://【中国】2020年11月11日
doubletime = double.parse(cellinnertext);
datetime = datetime.fromoadate(doubletime);
return datetime.tostring("yyyy/mm/dd");
case 177://【中国】11:22:00
doubletime = double.parse(cellinnertext);
datetime = datetime.fromoadate(doubletime);
return datetime.tostring("hh:mm:ss");
default:
return cellinnertext;
}
}
}
/// <summary>
/// 获取单位格的值
/// </summary>
/// <param name="cell"></param>
/// <param name="stringtablepart"></param>
/// <returns></returns>
private string getvalue(cell cell, sharedstringtable stringtable)
{
//因为excel的数据存储在sharedstringtable中,须要获取数据在sharedstringtable 中的索引
string value = string.empty;
try
{
if (cell.childelements.count == 0)
return value;
value = double.parse(cell.cellvalue.innertext).tostring();
if (cell.datatype != null)
{
switch (cell.datatype.value)
{
case cellvalues.sharedstring:
value = stringtable.childelements[int32.parse(value)].innertext; break;
}
}
}
catch (exception ex)
{
value = "n/a";
}
return value;
}
/// <summary>
/// 判断网格是否存在列
/// </summary>
/// <param name="dt">网格</param>
/// <param name="columnname">列名</param>
/// <returns></returns>
public bool iscontainscolumn(datatable dt, string columnname)
{
if (dt == null || columnname == null)
{
return false;
}
return dt.columns.contains(columnname);
}
public static void converttodatetime(ref datatable dt, string columnnm, string dtformat)
{
int findloca_old = dt.columns.indexof(columnnm);
datacolumn newcolumn = new datacolumn(system.guid.newguid().tostring(), typeof(string));
string newcolumnnm = newcolumn.columnname;
dt.columns.add(newcolumn);
newcolumn.setordinal(findloca_old + 1);
foreach (datarow row in dt.rows)
{
try
{
double val = convert.todouble(row[columnnm]);
row[newcolumnnm] = datetime.fromoadate(val).tostring(dtformat);
}
catch (exception ex)
{
;
}
}
dt.columns.removeat(findloca_old);
newcolumn.columnname = columnnm;
}
}
}到此这篇关于c#调用openxml读取excel行数据的文章就介绍到这了,更多相关c# openxml读取excel行数据内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论