一、前言
作为一个 crud 工程师,查询必然少不了,分页查询更是常见,市面上也有很多成熟的分页插件,都各有优缺点,这里整理一下,基于 mybatisplus 的分页插件进一步封装分页的公共方法。
二、对象封装
其实分页插件已经提供了很强大的功能,但是在业务开发的时候不够精简,返回了很多我们并不关注的数据,在这个基础上进一步封装,使其更贴合我们的业务开发。
2.1 分页结果对象封装
首先我们定义一个通用的分页结果对象,pagevo 包含我们关注的主要几个数据值,总条数,总页数,数据集。这里为了兼容各种数据类型,这里的数据集的类型通过泛型指定
@data
@noargsconstructor
@allargsconstructor
public class pagevo<v> implements serializable {
private static final long serialversionuid = 1l;
@schema(description = "总条数")
private long total;
@schema(description = "总页数")
private long pages;
@schema(description = "数据")
private list<v> records;
}
2.2 分页查询对象封装
为了兼容查询对象的不同类型,这里使用泛型定义查询对象类型,后面我们只需要根据使用场景定义对应的 query 对象就可以了
@data
public class pagequery<t> implements serializable {
private static final long serialversionuid = 1l;
@schema(description = "当前页码", defaultvalue = "1")
private integer pagenum = 1;
@schema(description = "每页显示条数", defaultvalue = "10")
private integer pagesize = 10;
@schema(description = "排序对象,支持多字段排序")
private list<orderitem> orderitems;
@schema(description = "查询对象")
private t search;
}
2.3 结合 query 对象使用案例
第一步:
比如我们现在要完成用户列表的分页查询,那么首先我们需要定义对应的查询对象 **userquery, **这里简单展示通过用户名和昵称进行查询。
@data
public class userquery implements serializable {
private static final long serialversionuid = 1l;
@schema(description = "用户名")
private string username;
@schema(description = "昵称")
private string nickname;
}
第二步:
定义我们返回时需要的结果对象,我这里就叫 **userlistvo **我习惯将列表的 **vo **对象命名为 **xxxlistvo,**详情对象命名为 xxxdetailvo
@data
public class userlistvo implements serializable {
private static final long serialversionuid = 1l;
@schema(description = "主键id")
private long userid;
@schema(description = "用户名")
private string username;
@schema(description = "昵称")
private string nickname;
@schema(description = "创建时间")
private localdatetime createtime;
@schema(description = "更新时间")
private localdatetime updatetime;
}
第三步:
在 controller 层编写接口
@operation(summary = "分页查询")
@postmapping("/page")
public r<pagevo<userlistvo>> findpage(@requestbody pagequery<userquery> userquery) {
pagevo<userlistvo> page = userservice.findpage(userquery);
return r.ok(page);
}
可以看到这里我们通过前面定义的公共对象,以及具体的业务对象,经过简单的组装完成了,请求参数 **userquery **以及返会结果的封装,并且我们可以很清楚的知道对应的类型,想要扩展也很容易实现,以后所有的分页查询基本上都是类似的格式,不同的在于我们根据不同使用场景封装对应的业务返回 xxxvo 以及查询对象 xxxquery
第四步:
具体的分页查询实现,即 findpage 方法的实现
@override
public pagevo<userlistvo> findpage(pagequery<userquery> userquery) {
// 将查询对象 转换为 mybatis plus 的 page 对象
page<adminuser> page = page.of(userquery.getpagenum(), userquery.getpagesize());
userquery search = userquery.getsearch();
// 查询
lambdaquery()
.eq(strutil.isnotblank(search.getusername()), adminuser::getusername, search.getusername())
.or()
.like(strutil.isnotblank(search.getnickname()), adminuser::getnickname, search.getnickname())
.page(page);
// 将 mybatis plus 的 page 对象 转换为 pagevo
list<adminuser> records = page.getrecords();
list<userlistvo> userlistvos = beanutil.copytolist(records, userlistvo.class);
return new pagevo<>(page.gettotal(), page.getpages(), userlistvos);
}
测试一下
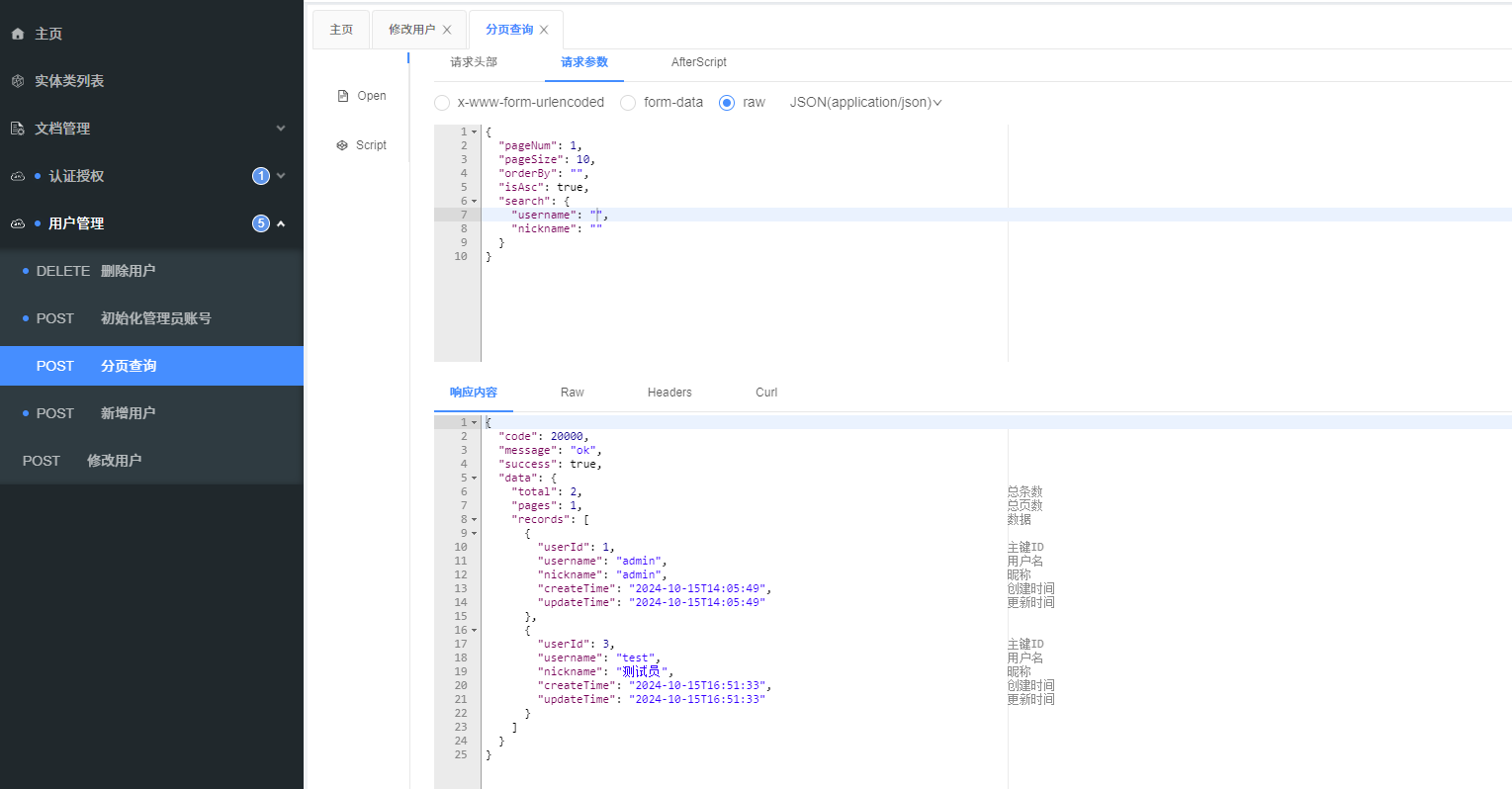
到这里基本上已经完成了,但是细心的会发现我们没有处理排序字段,而且这种对象来回转换的方法非常繁琐。
三、进一步封装对象转换
对象转换处理:
基于上面的接口实现进一步完善,首先第一点,查询对象 转换为 mybatis plus 的 page 对象,我们先来完成这个封装。
你可以单独写到一个工具类里,这里我直接写在 pagequery 对象中,这里方便我拿取参数,省的传参了,而且这样也更符合面向对象编程,这种转换能力应该属于 pagequery 对象。
/**
* 将当前对象转换为 mybatisplus 分页对象
*
* @param <po> po类型
* @return page<po>
*/
public <po> page<po> tomppage() {
return page.of(pagenum, pagesize);
}
那相同的 vo的转换能力应该由 pagevo提供,所以 vo转换写在 pagevo 里
/**
* 将 mybatisplus 分页结果转换为 pagedto
*
* @param page mybatisplus 分页结果
* @param targetclass 目标类型字节码
* @param <v> 目标数据类型
* @param <p> 原始数据类型
* @return 分页结果 pagedto
*/
public static <v, p> pagevo<v> of(page<p> page, class<v> targetclass) {
list<p> records = page.getrecords();
if (records.isempty()) {
return empty(page);
}
// 将原始数据转换为目标数据 这里我使用了 hutool 的 beanutil,可以根据需要自行替换
list<v> vs = beanutil.copytolist(records, targetclass);
return new pagevo<>(page.gettotal(), page.getpages(), vs);
}
/**
* 返回空的分页结果
*
* @param page mybatisplus 分页结果
* @param <v> 目标数据类型
* @param <p> 原始数据类型
* @return 分页结果 pagedto
*/
public static <v, p> pagevo<v> empty(page<p> page) {
return new pagevo<>(page.getpages(), page.getpages(), collections.emptylist());
}
这样我们之前的分页查询就可以写成这样
@override
public pagevo<userlistvo> findpage(pagequery<userquery> userquery) {
// 将查询对象 转换为 mybatis plus 的 page 对象
page<adminuser> page = userquery.tomppage();
userquery search = userquery.getsearch();
// 查询
lambdaquery()
.eq(strutil.isnotblank(search.getusername()), adminuser::getusername, search.getusername())
.or()
.like(strutil.isnotblank(search.getnickname()), adminuser::getnickname, search.getnickname())
.page(page);
// 将 mybatis plus 的 page 对象 转换为 pagevo
return pagevo.of(page, userlistvo.class);
}
排序处理:
在我们处理将当前对象转换为 mybatisplus分页对象的时候,只处理了 pagenum 和 pagesize , 接下来我们处理一下排序的情况。
/**
* 将当前对象转换为 mybatisplus 分页对象
*
* @param <po> po类型
* @return page<po>
*/
public <po> page<po> tomppage() {
page<po> page = page.of(pagenum, pagesize);
if (orderitems != null && !orderitems.isempty()) {
page.addorder(orderitems);
} else {
// 如果不传默认根据创建时间倒序
page.addorder(orderitem.desc("create_time"));
}
return page;
}
测试一下
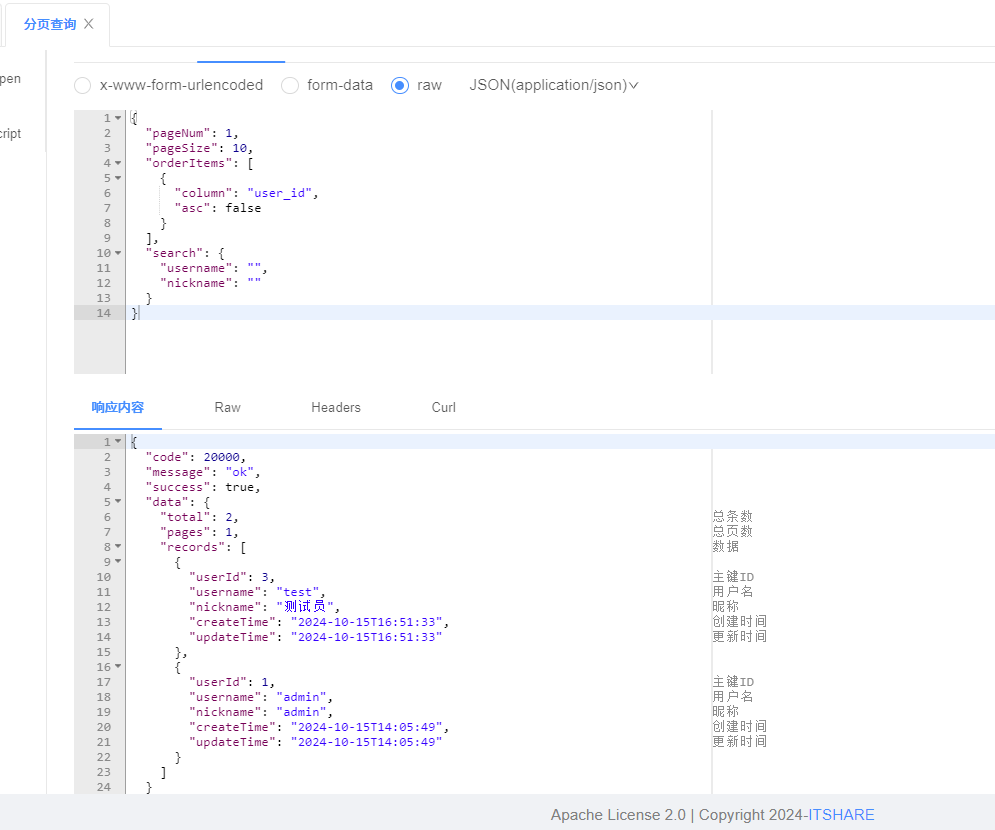
==> preparing: select user_id, username, password, nickname, create_time, update_time, is_deleted from itshare_admin_user where is_deleted = 0 order by user_id desc limit ?
控制台输出的 sql 也如我们预期一样
多条件测试
==> preparing: select user_id, username, password, nickname, create_time, update_time, is_deleted from itshare_admin_user where is_deleted = 0 order by user_id desc, create_time asc limit ?
四、总结
这样我们基本上完成了项目中分页场景下的代码封装,后续分页场景,我们只需要定义好 xxxquery 对象,以及 xxxvo 对象即可完成分页查询,大大简化了编码过程,提高了编码效率。其实就目前我们依然有很多具有共性的代码,比如对条件 sql 的编写,我们能不能根据对象类型以及前端配合传参动态去实现,这样我们就可以完全解放双手,定义两个对象就搞定一个分页接口的查询了。
到此这篇关于mybatisplus 封装分页方法示例的文章就介绍到这了,更多相关mybatisplus 分页内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论