1. 引言
在当今数字化时代,数据已成为企业的核心资产。随着业务的不断扩展和技术的快速发展,企业常常需要同时运用多种数据库系统来满足不同的业务需求。在这种背景下,neo4j作为领先的图数据库,以其高效的关系数据处理能力而备受青睐;而postgresql作为功能强大的关系型数据库,则以其稳定性和可扩展性而闻名。然而,如何在这两种截然不同的数据库系统之间实现高效、可靠的数据同步,成为了许多企业面临的一大挑战。
本文旨在为读者提供一个全面的指南,详细阐述如何在neo4j和postgresql之间构建高效的数据同步机制。我们将深入探讨数据同步的重要性,分析两种数据库系统的特点,并提供从策略设计到技术实现的完整解决方案。无论您是数据库管理员、系统架构师,还是对数据集成感兴趣的技术爱好者,本文都将为您提供宝贵的见解和实用的技巧。
通过阅读本文,您将了解到:
- postgressql、neo4j基本概念简介
- 如何设计一个既满足业务需求又技术可行的同步策略
- 实现数据同步的具体技术步骤和最佳实践
- 如何应对同步过程中可能遇到的挑战,并进行性能优化
让我们开始这段探索数据同步世界的旅程,一同揭示neo4j和postgresql协同工作的无限可能!
2. neo4j与postgresql的基础知识
2.1. neo4j基本概念与架构

neo4j 是一种高性能的图数据库,它使用图结构存储复杂的网络关系,以节点、关系和属性的形式存储和查询数据。neo4j的主要特点包括:
- 如何设计一个既满足业务需求又技术可行的同步策略
- 实现数据同步的具体技术步骤和最佳实践
- 如何应对同步过程中可能遇到的挑战,并进行性能优化
2.2. postgresql基本概念与架构

postgresql 是一种功能强大的开源关系型数据库系统,以其稳定性、可扩展性和丰富的特性集而著名。其核心特点包括:
- sql兼容:遵循sql标准,支持复杂的查询和多种数据类型。
- 扩展性:支持自定义类型、函数和插件,用户可以根据需要扩展数据库功能。
- mvcc(多版本并发控制):提供高级别的并发性和性能,同时保持读写操作的一致性。
- 高可靠性:支持点对点复制和热备份,确保数据安全和高可用。
2.3. 数据处理上的不同与互补
neo4j和postgresql在数据处理上有本质的不同,这些差异为它们在特定应用场景中的互补提供了基础:
- 处理复杂关系:neo4j在处理高度连接的数据和深层关系网络方面具有优势,适合社交网络分析、推荐系统等场景。而postgresql在处理大规模的结构化数据和事务性要求高的应用中更为有效。
- 查询性能:对于深度连接查询和图遍历,neo4j表现出色;而postgresql在执行大规模聚合查询和多表连接时更具优势。
- 数据完整性与安全:postgresql提供广泛的数据完整性和安全特性,这在需要严格数据验证和法规遵从的业务中非常重要。neo4j也提供事务支持,但以不同方式实现。
通过理解这些基本概念和架构的不同,可以更好地设计出符合特定业务需求的数据同步策略,有效地利用两种数据库系统的优势。
3. 数据同步方案设计
3.1. neo4j与postgressql对比说明
在我们开始讨论如何同步neo4j和postgresql之间的数据之前,先来看看它们在数据模型上的异同。为了方便理解,我把两者对应的概念列成了一个表格:
| 关系型数据库(postgressql) | neo4j |
|---|---|
| 表 | 图 |
| 行 | 节点 |
| 列 | 属性 |
| 约束 | 关系 |
这张表看起来很简单,但如果我们深入分析,每一行其实都揭示了两种数据库背后完全不同的思维方式。
1. 表 vs 图
在postgresql里,数据是存储在表格中的,每张表有固定的结构和字段,比如用户表可能包含用户id、姓名、邮箱等信息。
neo4j则完全不同,它把数据存储在图里。图中包含的是节点和关系,比如一个用户是另一用户的朋友就可以通过节点(用户)和关系(朋友)轻松表达。
简单理解:
表是二维的,一行行数据排列得整整齐齐。图是网络状的,数据之间的连接是它的核心。
2. 行 vs 节点
postgresql中的每一行表示一条具体的记录,比如某个用户的详细信息。
而在neo4j中,这种记录会被表达成一个节点,节点可以理解为图里的一个点,每个点都有属于它自己的属性。
举个例子:
postgresql的用户表中,一行记录可能是:{id: 1, name: '张三', email: 'zhangsan@example.com'}
到了neo4j里,这一行会变成一个用户节点:(id: 1, name: '张三', email: 'zhangsan@example.com')
3. 列 vs 属性
在postgresql中,表的每一列都是字段,比如姓名、邮箱这些。
而在neo4j中,节点或关系都有属性,这些属性其实就是postgresql里的列。
换句话说: 列就是属性,属性就是列。同步时,只需要确保列名和属性名一致,就能一一对应。
4. 约束 vs 关系
这一点是postgresql和neo4j最根本的差异。
postgresql中的约束,比如外键,用来表示两张表之间的关联关系。
而在neo4j里,关系本身就是一等公民,图数据库的设计核心就在于节点之间的关系。
例如:
在postgresql中,如果你有用户表和好友关系表:
- 用户表存用户信息。
- 好友关系表存两个用户的id,表示谁和谁是好友。
在neo4j中,你不需要分成两张表,因为好友关系可以直接存在于图中:
(张三)-[:朋友]->(李四)
关系甚至可以有属性,比如加好友的时间、关系强度等,这一点是图数据库的天然优势。
通过这几个对应关系,我们可以看出postgresql更注重结构化的数据存储,而neo4j更适合表现复杂的数据关系。在设计数据同步方案时,我们的目标就是把postgresql里的表、行、列和约束,巧妙地转换成neo4j里的图、节点、属性和关系,为下一步的全量同步和增量同步打好基础。简单点说,这就是把二维的表,变成更立体的图,顺便让数据之间的关系更加直观。
3.2. 数据同步技术方案设计
在neo4j与postgresql之间实现数据同步,通常有两种方式:全量同步和增量同步。全量同步通常用于初次数据迁移,而增量同步适用于实时或近实时的增量更新。增量同步和全量同步实现的方式很多,本章仅仅基于java实现展开。
3.2.1 全量同步
全量同步是一种将postgresql中的所有数据一次性迁移到neo4j的方式,适用于初次数据迁移或定期的全量刷新。
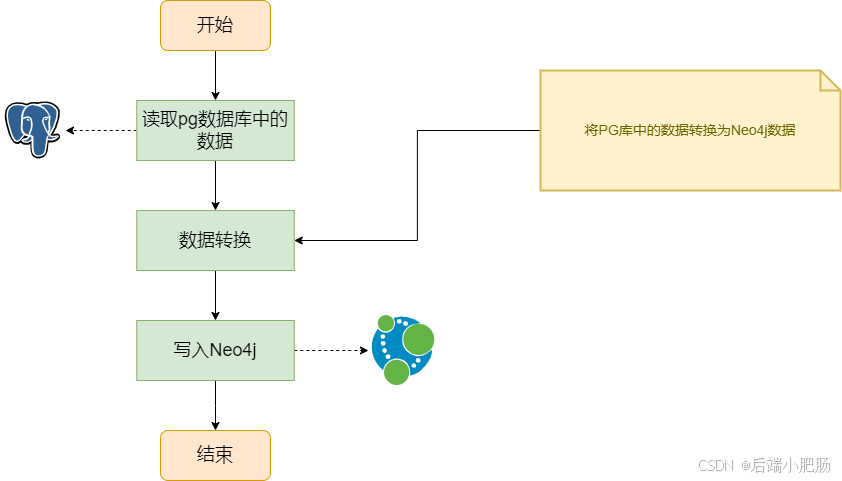
实现步骤:
数据抽取:
- 使用java通过jdbc从postgresql数据库中抽取数据。
- 根据postgresql的表结构,将每一行数据映射为neo4j中的一个节点,每个列映射为节点的属性。
数据转换:
- 在数据抽取后,进行格式转换,将postgresql的行数据转换为符合neo4j图数据库结构的数据模型。
- 为每个数据项(如节点、关系)生成唯一标识,以保证在neo4j中的一致性和准确性。
批量插入:
- 使用neo4j的批量插入功能,通过cypher语句将转换后的数据批量写入neo4j数据库。
- 在插入过程中,采用事务管理来提高插入效率,确保数据一致性。
数据验证:
- 全量同步完成后,进行数据校验,确保postgresql与neo4j之间的数据一致性,检查是否有数据遗漏或错误。
3.2.2. 增量同步
增量同步是一种实时或周期性同步数据变更的方式,适用于数据更新频繁、需要实时反映变动的场景。
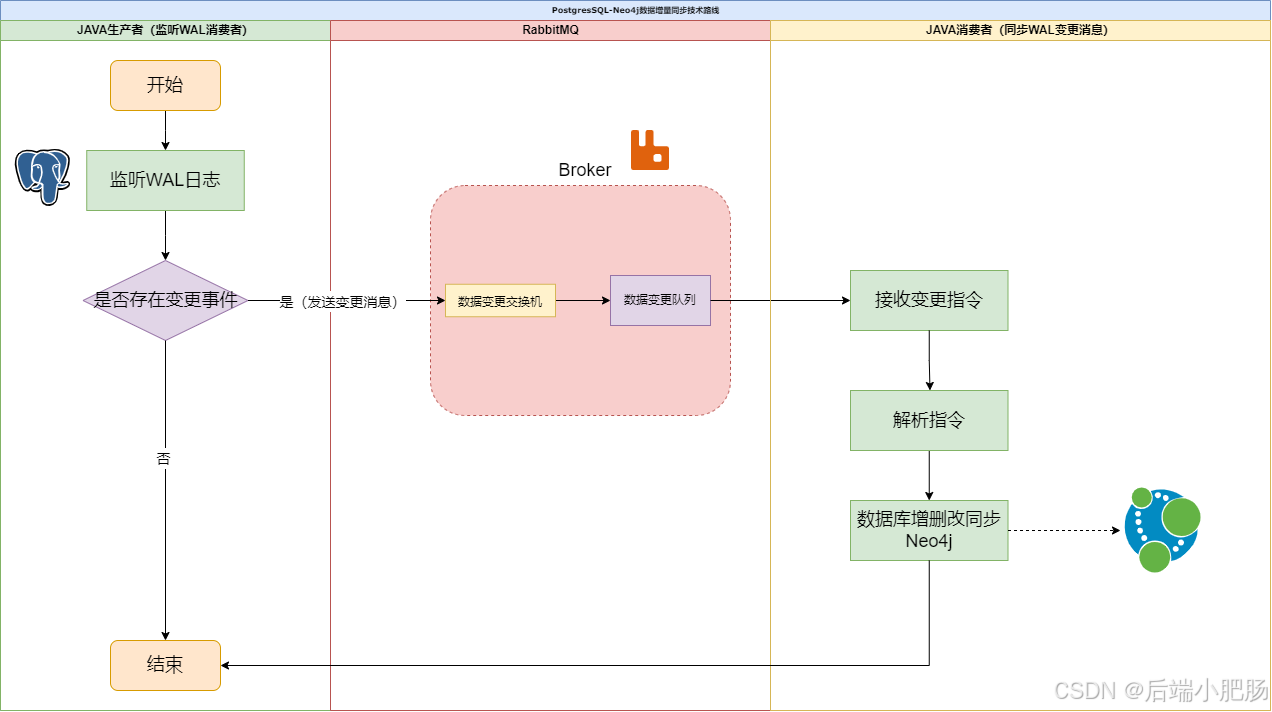
实现步骤:
- 数据变更捕获:利用postgresql的wal日志(write-ahead logging)机制来捕获数据的增量变更。
- 消息队列传输:
- 将捕获到的增量变更数据通过消息队列(如rabbitmq)传输到neo4j的同步系统。
- 每个消息中包含了变更的操作类型(如插入、更新、删除)以及相关数据。
- 数据应用:
- 在neo4j中,根据消息的内容执行相应的cypher查询,更新图数据库中的数据。
- 通过java程序处理从rabbitmq接收到的增量数据,动态更新neo4j中的节点和关系。
- 容错处理与监控:
- 设计增量同步的容错机制,确保在增量同步过程中不会丢失数据或发生重复同步。
4. 技术实现
4.1. postgressql表结构设计
在本节pg库到neo4j数据库同步技术实践中,我设计了4张数据表,分别是教师表(xfc_teacher)、学生表(xfc_student)、班级表(xfc_class)、班级和老师关联中间表(xfc_brid_teacher_and_class)。其表关系如下:

4.2. neo4j 数据模型设计
根据提供的关系型数据库表结构,我们设计了如下的 neo4j 图数据库数据模型:
- 节点(nodes):
- teacher (老师节点)
- 属性:
id(老师的唯一标识)name(老师名字)subject(老师教授的科目)说明: 表示每位老师的基本信息。 - class (班级节点)
- 属性:
id(班级的唯一标识)name(班级名称)说明: 表示每个班级的基本信息。
- 属性:
- student (学生节点)
- 属性:
id(学生的唯一标识) name(学生名字)age(学生年龄)
- 属性:
- 说明: 表示每位学生的基本信息。
- 关系(relationships):
- teaches (教授)
- 起点节点类型:
teacher - 终点节点类型:
class - 属性: 无说明: 表示某位老师教授某个班级的关系。
- has_student (包含学生)
- 起点节点类型:
class - 终点节点类型:
student - 属性: 无
- 说明: 表示某个班级包含某位学生的关系。
- 起点节点类型:
示意模型
老师和班级:
(:teacher {id: "t1", name: "张老师", subject: "数学"})-[:teaches]->(:class {id: "c1", name: "一年级"})班级和学生:
(:class {id: "c1", name: "一年级"})-[:has_student]->(:student {id: "s1", name: "李明", age: 12})对应的 postgresql 数据表和 neo4j 模型的映射
| postgresql 表 | neo4j 节点或关系 | 属性映射 |
|---|---|---|
xfc_teacher | teacher 节点 | id, name, subject |
xfc_class | class 节点 | id, name |
xfc_student | student 节点 | id, name, age |
xfc_brid_teacher_and_class | teaches 关系 | teacher_id -> id, class_id -> id |
xfc_student.class_id (外键) | has_student 关系 | class_id -> id |
通过这种图模型设计,我们将关系型数据库中的结构化表格数据转换为更直观的图数据结构,为后续的数据同步和分析奠定基础。
4.3. 全量同步代码
代码我都放到git仓库了,需要的自己去取。xfc-fdw-cloud: 公共解决方案
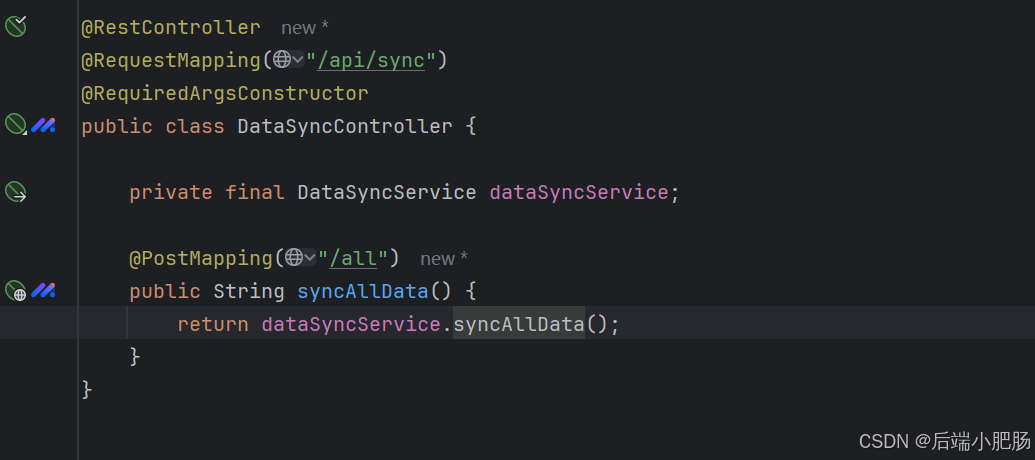
1. 全量同步接口:
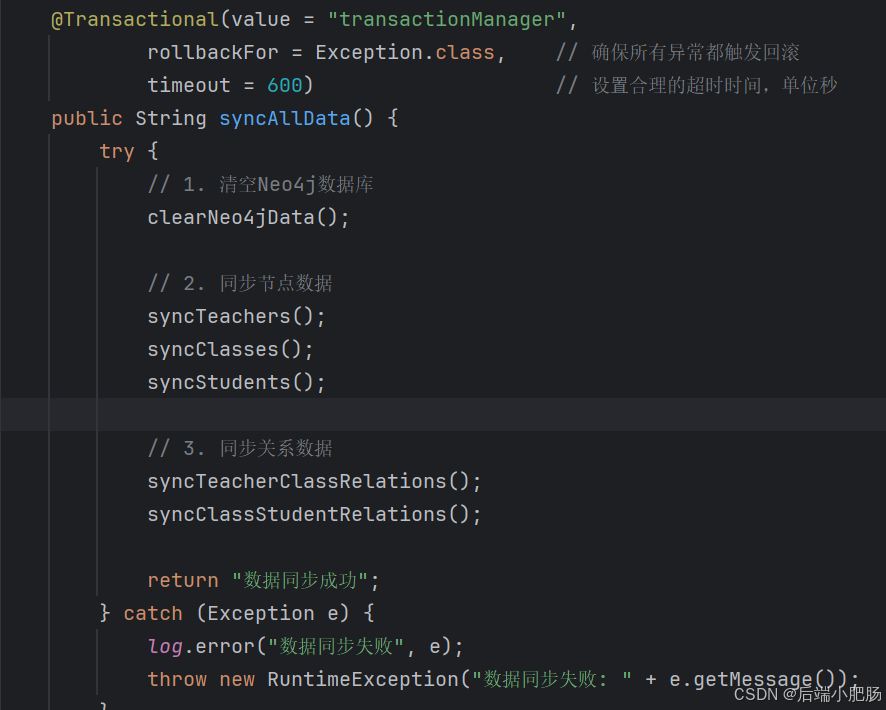
2. 全量同步方法:
3. 多源事务管理配置类:
@configuration
public class transactionconfig {
@autowired
private datasource datasource;
@autowired
private driver neo4jdriver;
@bean("postgrestransactionmanager")
public platformtransactionmanager postgrestransactionmanager() {
return new datasourcetransactionmanager(datasource);
}
@bean("neo4jtransactionmanager")
public platformtransactionmanager neo4jtransactionmanager() {
return new neo4jtransactionmanager(neo4jdriver);
}
@bean("transactionmanager")
public platformtransactionmanager chainedtransactionmanager(
@qualifier("postgrestransactionmanager") platformtransactionmanager postgrestransactionmanager,
@qualifier("neo4jtransactionmanager") platformtransactionmanager neo4jtransactionmanager) {
return new chainedtransactionmanager(
postgrestransactionmanager,
neo4jtransactionmanager
);
}
}这段代码是一个spring配置类,通过定义多个事务管理器(分别用于postgresql和neo4j)以及一个链式事务管理器(chainedtransactionmanager),实现对多数据源的分布式事务管理,确保事务在多个数据库之间的一致性和原子性。
我就不讲解了,很简单。
4.4. 增量同步代码
1. 编写changelogprocessor
代码太长了,我这里就不粘贴了,只粘贴主干代码,要看全都代码可以去仓库。
public void processchangelog(string changelog) {
try {
string operation = extractoperation(changelog);
string table = extracttable(changelog);
string id = extractid(changelog);
log.debug("processing change: operation={}, table={}, id={}", operation, table, id);
switch (table) {
case "public.xfc_teacher":
processteacherchange(operation, id, changelog);
break;
case "public.xfc_class":
processclasschange(operation, id, changelog);
break;
case "public.xfc_student":
processstudentchange(operation, id, changelog);
break;
case "public.xfc_brid_teacher_and_class":
processteacherclassrelation(operation, changelog);
break;
default:
log.warn("未知的表操作: {}", table);
}
} catch (exception e) {
log.error("处理变更日志时发生错误: {}", changelog, e);
}
}processchangelog 函数是一个变更日志处理器,主要功能是接收并处理 postgresql 数据库的变更日志(比如插入、更新、删除操作),然后将这些变更同步到 neo4j 图数据库中
2. 编写databasechangeservice
public class databasechangeservice {
private final jdbctemplate jdbctemplate;
private final changelogprocessor changelogprocessor;
private static final string slot_name = "neo4j_replication_slot";
private static final long poll_interval = 1000; // 1秒
private static final int max_retries = 3;
private volatile boolean running = true;
@postconstruct
public void startlistening() {
new thread(this::initializereplicationslot, "replicationlistener").start();
}
private void initializereplicationslot() {
try {
if (!isslotexists(slot_name)) {
createreplicationslot(slot_name);
log.info("created new replication slot: {}", slot_name);
} else {
log.info("using existing replication slot: {}", slot_name);
}
listentoreplicationslot();
} catch (exception e) {
log.error("初始化复制槽时发生错误", e);
}
}
private boolean isslotexists(string slotname) {
string query = "select count(*) from pg_replication_slots where slot_name = ?";
integer count = jdbctemplate.queryforobject(query, integer.class, slotname);
return count != null && count > 0;
}
private void createreplicationslot(string slotname) {
string query = "select pg_create_logical_replication_slot(?, 'test_decoding')";
jdbctemplate.update(query, slotname);
}
public void listentoreplicationslot() {
string query = "select data from pg_logical_slot_get_changes(?, null, null)";
int retrycount = 0;
while (running) {
try {
list<string> changes = jdbctemplate.queryforlist(query, string.class, slot_name);
for (string change : changes) {
try {
changelogprocessor.processchangelog(change);
} catch (exception e) {
log.error("处理变更时发生错误: {}", change, e);
}
}
retrycount = 0; // 重置重试计数
thread.sleep(poll_interval);
} catch (interruptedexception e) {
log.info("复制监听器被中断");
thread.currentthread().interrupt();
break;
} catch (exception e) {
log.error("监听复制槽时发生错误", e);
retrycount++;
if (retrycount >= max_retries) {
log.error("达到最大重试次数,停止监听");
break;
}
try {
thread.sleep(poll_interval * retrycount); // 指数退避
} catch (interruptedexception ie) {
thread.currentthread().interrupt();
break;
}
}
}
}
public void stop() {
running = false;
}
}databasechangeservice 是一个数据库变更监听服务,它通过 postgresql 的逻辑复制功能(使用复制槽 replication slot)来捕获数据库的变更事件(如插入、更新、删除),当检测到变更时,会通过 changelogprocessor 处理这些变更并将其同步到 neo4j 图数据库中,从而实现 postgresql 到 neo4j 的实时数据同步。这个服务在启动时会自动创建并监听复制槽,并通过循环轮询的方式持续获取变更日志,同时包含了错误处理和重试机制以确保同步的可靠性。
5. 结论
本文详细介绍了如何在 neo4j 与 postgresql 两种数据库之间实现高效数据同步,从基础概念到全量与增量同步的实现策略,结合具体代码与实践案例,为开发者提供了全面的指导。通过充分利用 neo4j 的关系处理优势与 postgresql 的结构化数据支持,这种同步机制能够满足复杂业务需求,为数据整合和分析提供坚实基础。希望本文能为技术从业者提供清晰的思路,助力多数据库协作的实现与优化。
到此这篇关于如何在neo4j与postgresql间实现高效数据同步的文章就介绍到这了,更多相关postgresql数据同步内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论